 夜雨聆风
夜雨聆风





GraphRAG:让AI真正“读懂”文章,不再丢三落四
你是不是也遇到过这样的场景:让AI从一个长文章里找答案,结果它要么答非所问,要么漏掉关键信息?
这背后,其实是传统RAG(检索增强生成)的一个“先天缺陷”。
01 传统RAG的困境:切大还是切小?
在传统RAG中,我们通常会把文章切成一堆“文本块”,然后转成向量存进数据库。
查询时,系统根据问题匹配最相关的块。
举个例子,文章里有这样几句话:
-
王喜欢吃西瓜。
-
王也喜欢吃桃子。
-
西瓜很甜。
如果用户问:“王喜欢吃什么?”
系统很轻松就能找到前两句话。
但如果问:“这篇文章里,‘西瓜’出现了几次?”
问题就来了—“西瓜”分散在不同的句子中,没有哪一句话能独立回答这个问题。
RAG很可能漏掉或查不准。
为什么会这样?
因为RAG是基于整段文本做匹配的。
问题“西瓜出现了几次”和“王喜欢吃什么”之间的语义关联很弱,导致包含“西瓜”的句子可能被忽略。
那如果把文本切成更小的单位,比如按词切呢?
这样每个“西瓜”都能命中,但当你再问“王喜欢吃什么”时,系统就傻了——因为信息之间的语义联系被切断了。
这就是传统RAG的核心矛盾:
-
切太大,容易漏细节
-
切太小,容易丢语义
-
这个矛盾,正是RAG不准确的根源之一。
02 知识图谱:一个更聪明的解法
有没有办法既不丢细节,又能保留语义结构?
有,答案就是——知识图谱。
GraphRAG就是用知识图谱来改造传统RAG的。
什么是知识图谱?
还是那句话:“王喜欢吃西瓜。”
如果用知识图谱表示,就变成:
-
实体1:王(类型:人物)
-
实体2:西瓜(类型:水果)
-
关系:喜欢吃
实体和关系还可以带属性,比如“西瓜很甜”中的“甜”也可以作为一个实体。
这种结构叫做LPG(标记属性图)。
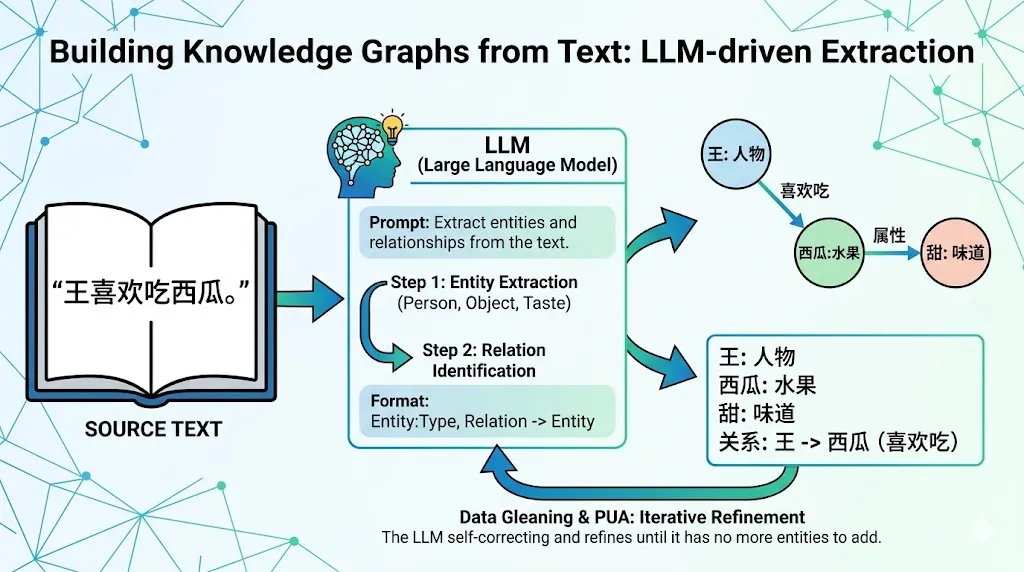
大模型让建图变得简单
在过去,构建知识图谱非常复杂。但现在,有了大模型,我们可以直接用提示词让它自动抽取实体和关系。
比如,我们给AI一段提示:
“目标:为‘王喜欢吃西瓜’生成知识图谱。
-
第一步:识别实体(人物、物品、味道)。
-
第二步:识别关系(如‘喜欢吃’)。
-
输出格式:实体:类型,关系用箭头表示。”
AI会返回类似:
-
王:人物
-
西瓜:水果
-
王 -> 西瓜 : 喜欢吃
而且,GraphRAG还会让AI为每个实体和关系生成一段自然语言描述。
更妙的是,它会反复问AI:“你漏了没?还有要加的吗?”
直到AI自己说:“没了。”
这个过程叫 Data Gleaning(数据清洗),程序员们戏称为大模型PUA。
03 合并与简化:从碎片到整体
GraphRAG会对文章中的每一个段落分别生成知识图谱,然后:
1. 合并同名实体(比如所有“王”合并成一个节点)
2. 合并描述信息,并让AI重新生成更流畅的摘要
3. 维护图谱与原文的双向对应关系(知道哪个实体来自哪段原文)
这样,我们就得到了一篇文章级的完整知识图谱。
但如果文章很长,这个图会变得非常大。
所以GraphRAG还会做一步简化:
-
用莱顿社区检测算法把“关系密集”的节点合并成一个子图
-
再让AI为每个子图生成更高层次的摘要
例如,合并“王喜欢吃西瓜”和“王喜欢吃桃子”两个子图后,AI可能会推断出:
王喜欢吃水果,尤其是西瓜和桃子。
这句话甚至从未出现在原文中—这就是知识图谱超越纯文本匹配的地方:它开始真正理解和推理。
这个过程可以不断重复,最终形成多层级的图谱结构:
-
上层:抽象、概括
-
下层:具体、贴近原文
04 查询:灵活又强大
有了这个图谱,查询就变得非常灵活。
GraphRAG会把图谱中的每个节点、每条边、每段描述都向量化,存入数据库。
同时也保留原始文本块的向量。
用户提问时,比如“王喜欢吃什么?”:
系统可以从图谱底层开始,找到最相关的实体
然后利用“图谱↔原文”的映射,反向拉出相关原文
再把所有相关信息(摘要、原文、邻居节点等)打包发给大模型
这种策略叫 Local Search(局部搜索),特别擅长处理细节丰富、定位精准的问题。
还有一种叫 Global Search(全局搜索),从图谱高层开始往下查,适合回答抽象、全局的问题,比如:“这篇文章的核心思想是什么?”
05 总结:GraphRAG的浪漫与代价
GraphRAG的整个流程——从建图、合并、简化到查询——几乎每一步都离不开大模型。
它本质上是一种让大模型“渗透”全过程的设计。
你可以说它奢侈、烧Token,但不能说它不认真。
有趣的是,这个过程很像我们的学习过程:
-
最初,脑子里全是零散的知识点
-
慢慢积累、思考,点连成线,线织成网
-
最终形成自己的“知识图谱”
-
甚至还能发现一些原本不存在的联系
参考资料:
GraphRAG论文 & 微软开源代码

claude code 保姆级安装教程、常用指令及skills精选推荐
万字长文解读:爆火GitHub的Hermes Agent,凭什么叫“AI界爱马仕”?彻底拆解Agent平权时代(附安装指南)
开源项目女娲.skill火了,乔布斯马斯克都被蒸馏,它厉害在哪?这种技术边界在哪?
END
感谢阅读