 夜雨聆风
夜雨聆风





OpenAI 要做手机了?在那之前,得先唤醒你手机里“装睡”的 NPU
最近,科技圈最大的八卦之一,莫过于“OpenAI 要亲自下场做手机了”。
不管是真是假,这背后其实折射出一个明确的趋势:AI 的终局,一定有一部分在端侧,在每个人形影不离的手机里。
但现实是骨感的。今天,即使你手里拿着最新款的旗舰机,跑起大模型来依然会觉得“卡、慢、烫”。
为什么?
因为你手机里最该干活的那个部件,其实一直在“摸鱼”。
01 | NPU 有算力,但为什么没被大模型用起来?
今天的旗舰手机芯片(比如高通骁龙 8 Elite),都标配了极其强大的 NPU(神经网络处理器)。它天生就是为了跑 AI 而生的,能效比(每瓦特算力)远超 CPU 和 GPU。
但尴尬的是,大多数端侧推理方案,根本没有把它真正用好。
要么完全不用,硬扛着让 CPU 去算;要么只是象征性地把部分算子扔过去,大部分潜能根本没发挥出来。
原因很简单:NPU 的编程模型和传统的 CPU/GPU 完全是两套逻辑,适配工作量极大。市面上主流的开源推理框架(比如 llama.cpp),对 NPU 的支持非常有限。
这就像买了一台顶级跑车,却一直挂着一档在开。
02 | 破局:OmniInfer-Native 的解法,让大模型跑在“正确的硬件”上
怎么解决这个问题?OmniInfer-Native 决定啃下这块硬骨头。
它没有走“能跑就算赢”的糊弄路线,而是在安卓高通平台上,对 NPU 做了深度定制化优化。这不是简单地“挂上去”,而是根据不同模型任务的特性,精确安排每个组件跑在最合适的硬件上。
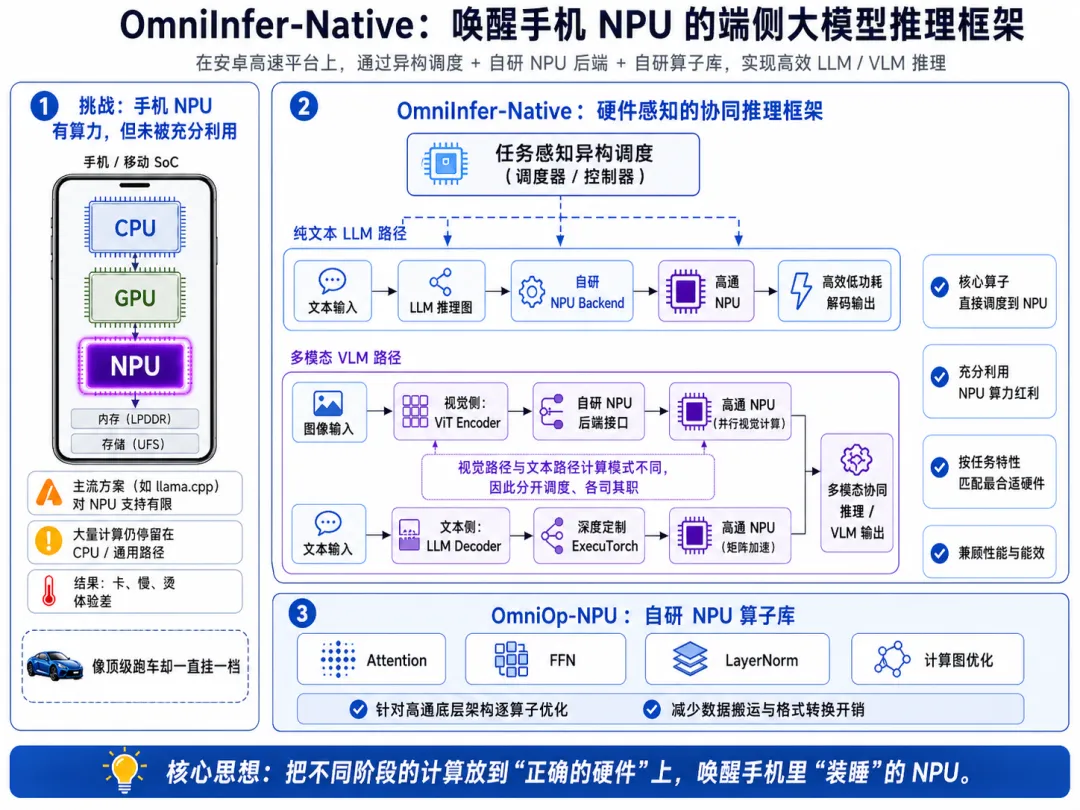
1、对于纯文本对话(LLM):直接打通 NPU 任督二脉
对于日常的纯文字 LLM 推理,OmniInfer-Native 在框架中加入了自研的 NPU Backend。我们将推理过程中的核心算子直接调度到高通 NPU 上执行。算得快,还不费电,充分利用了 NPU 的算力红利。
2、对于多模态模型(VLM):精巧的“分工协作”架构
现在的大模型不光能看字,还能看图。但这更麻烦了——看图(视觉路径)和看字(文本路径)的计算模式完全不一样。
怎么解?OmniInfer-Native 为此设计了一套精巧的混合架构:
-
视觉侧(ViT 编码器):看图,本质上是一次性的大规模并行计算。OmniInfer-Native 使用了自研的 NPU 后端接口来处理这一块。不仅处理速度快,还能随时灵活适配各种新出的视觉模型架构。
-
文本侧(LLM 解码器):文字是自回归的,一个词一个词往外蹦。在这里,OmniInfer-Native 使用了经过深度定制优化的 ExecuTorch推理框架,把高通 NPU 的矩阵加速能力压榨到极限。
为什么要强行分开?因为它们对硬件资源的消耗方式截然不同。分开调度,各司其职,才能双双达到最高效率。
03 | 磨刀不误砍柴工:自研算子库 OmniOp-NPU
光有架构图上的分工还不够,底层还得有趁手的兵器。
为了实现上述的极致加速,我们直接手搓了一套自研的 NPU 算子库 —— OmniOp-NPU。
我们没有直接套用通用的算子库,而是针对高通底层架构特性,一个算子一个算子地去死磕(覆盖了 Attention、FFN、LayerNorm 等核心算子)。从算子级别到计算图级别,把那些拖慢速度的数据搬运和格式转换“中间商”全部干掉。
04 | 结果说话:14.94倍的提速是什么体验?
不谈玄学理论,直接看实测结果。
在高通骁龙 8 Elite SoC 平台上,我们使用主流的 Qwen2.5-VL 多模态模型进行了严格的对比测试:
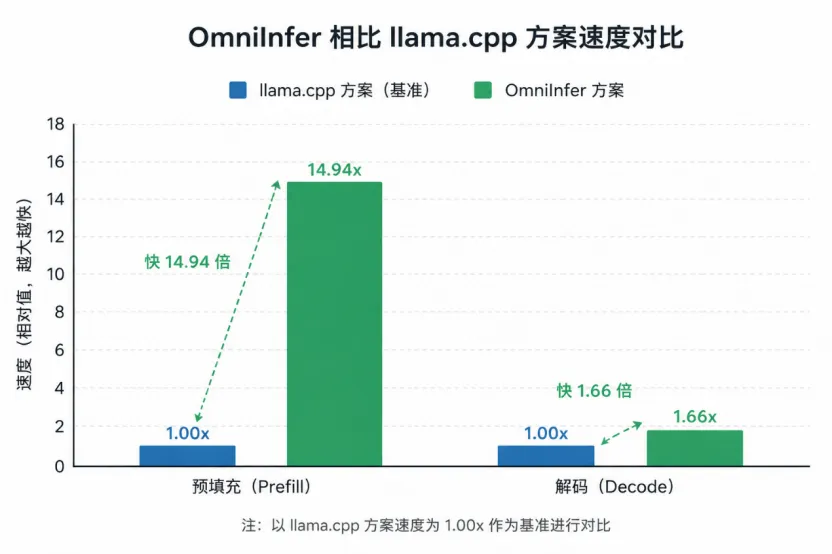
相比传统的 llama.cpp 方案:
-
解码(Decode)速度提升了1.66 倍。
-
预填充(Prefill)速度提升了极其夸张的 14.94 倍!
14.94 倍到底意味着什么?
它意味着用户体验的根本性改变。
过去,你发一张图片给手机里的 VLM 模型,可能要干等 3 秒钟,它才慢吞吞地开始吐出第一个字。现在,只需要0.2 秒。几乎是你刚点完发送,模型就已经看懂了图片并开始流畅作答。
这才是真正可用的端侧多模态对话体验。而这一切提速,仅仅是因为我们把计算放到了“正确的硬件”上。
OmniInfer对话能力测试demo:
OmniInfer性能测试demo:
总结
端侧大模型推理,正在从“能不能跑”走向“跑得爽不爽”的深水区。
不论 OpenAI 未来究竟造不造手机,端侧 AI 走向原生、走向高效利用专用芯片(NPU)都是必然趋势。
我们不需要总是盲目等待下一代更庞大、更昂贵的硬件,而是要把现有的设备用到极致。唤醒你手机里闲置的 NPU,让它真正跑满大模型,这就是 OmniInfer-Native 正在做的事。
如果你也对本地 AI、Agent 或端侧推理感兴趣,我们也在持续建设端侧 AI 开发者社区,欢迎加入交流。


公司核心团队成员来自清华大学、北京大学、上海交通大学、浙江大学、密歇根大学安娜堡分校、加州大学圣地亚哥分校,以及腾讯、阿里、字节、华为、微软等顶尖高校与互联网企业。团队长期聚焦端侧模型轻量化与高效推理、端侧模型系统优化与计算加速、多端协作与端云协同推理等关键方向,持续推进系统性的技术攻关与工程实践,在相关领域形成了扎实的技术积累与较强的行业影响力。近年来,团队先后主持多项国家自然科学基金重点项目、专项重点项目、优秀青年科学基金项目及国家重点研发计划课题等国家级科研任务,并与华为、荣耀、蚂蚁、字节跳动等头部企业建立了紧密的学术与技术合作关系。
Website:https://omnimind.com.cn
Github:https://github.com/omnimind-ai
Email:info@omnimind.com.cn