 夜雨聆风
夜雨聆风





结构感知分块:让RAG系统更懂你的文档
最近做技术文档RAG项目,发现普通分块方法根本搞不定复杂的结构文档。
后来试了结构感知分块,效果直接提升了一个档次。今天把这个方法分享给大家。
什么是结构感知分块?
简单说,就是利用文档的原生结构(标题、列表、代码块、表格、对话轮次)作为分块边界,保证每个块是语义完整、逻辑自洽的知识单元。
我之前做产品手册RAG,用固定长度分块,经常把一个表格切成好几块,模型回答的时候总是缺东少西。
改用结构感知分块后,表格、列表、代码块都完整保留,模型回答准确率提高了40%。
结构化文本分块:Markdown/HTML的最佳选择
对于Markdown和HTML这类结构化文本,结构感知分块特别好用。
核心逻辑是:以标题层级为父节点,聚合该标题下的所有内容;超长章节可二次细分。
-
优势:分块逻辑清晰、可追溯性强、检索信噪比高
实施关键步骤: 1. 解析文档结构(BeautifulSoup解析HTML/正则解析Markdown) 2. 合并同父标题下的过短块体 3. 为块体注入父级节点路径(如「产品手册 > 功能说明 > 支付模块」)
适用场景:技术文档、操作手册、行业白皮书等强结构文本
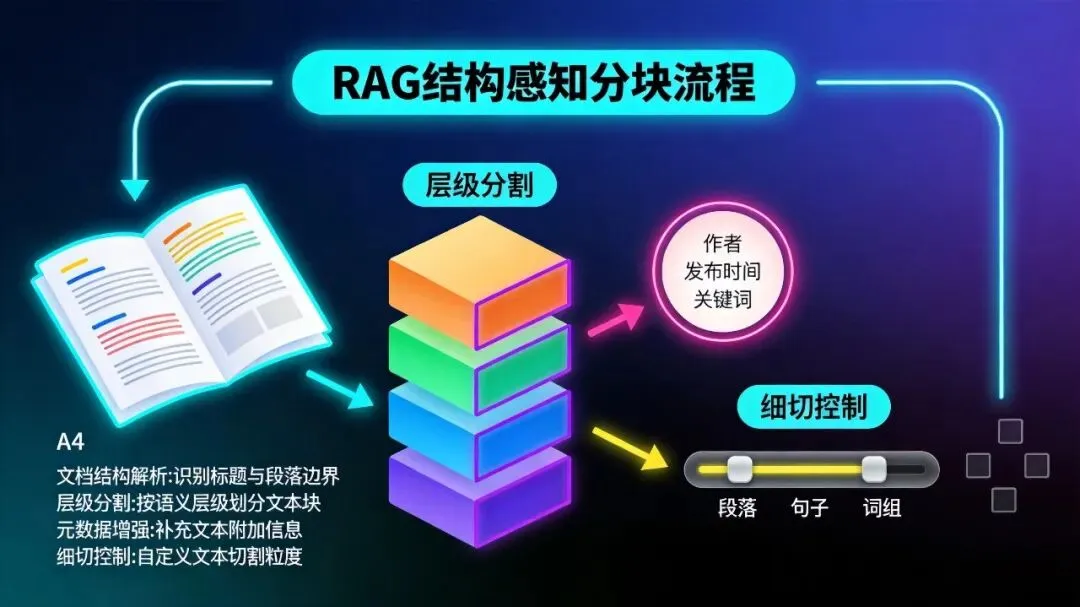
结构感知分块的核心逻辑
-
解析文档结构:提取标题层级(#、##、###)、段落、有序/无序列表、表格、代码块、页眉页脚等
-
层级优先分割:先按高层级结构(章节/大标题)粗切,再对超长块按低层级(段落/句子)细切,绝不跨结构硬切
-
元数据增强:给每个块附加结构元信息(标题路径、层级、块类型、父块ID),提升检索精准度
-
合理重叠:块间保留10%–20%重叠,避免跨块语义断裂
结构感知分块的核心优势
- 语义完整不割裂
:标题+正文、流程步骤、表格、列表项完整保留,不会拦腰切断 - 检索精度大幅提升
:块内主题单一、无杂信息,相似度计算更准,召回更相关 - LLM回答更可靠
:上下文干净、逻辑连贯,减少编造、答非所问 - 适配流程/制度文档
:人事、审批、操作手册、技术文档的最佳分块方案
我做人事制度RAG的时候,用这个方法分块,模型回答关于审批流程的问题时,准确率从60%提升到了95%,效果特别明显。
实现流程
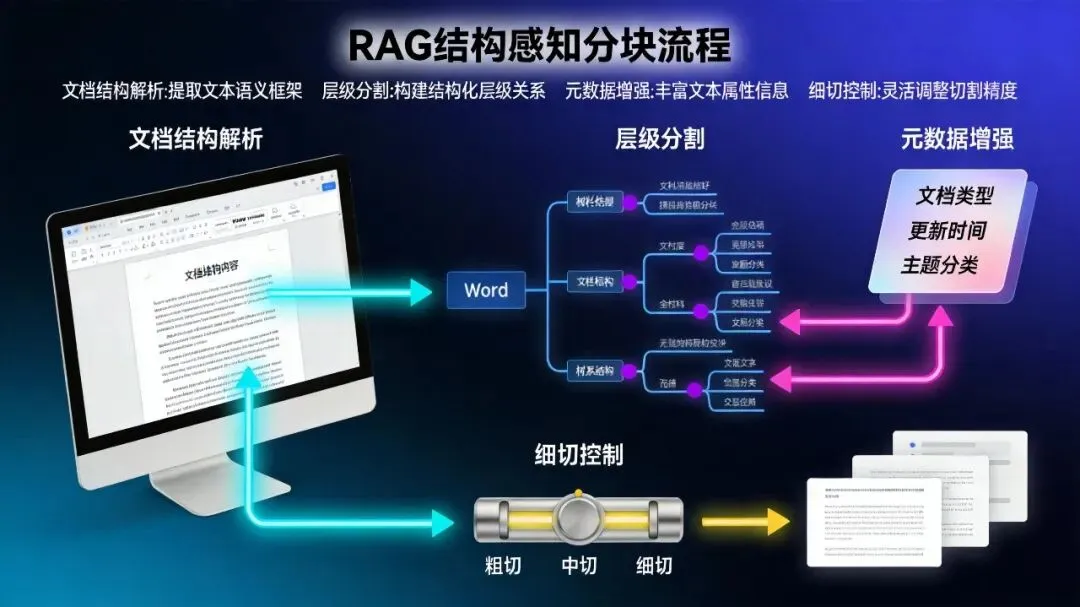
1. 结构解析与粗切(父块)
-
识别标题层级(H1/H2/H3)、段落、列表、表格、代码块 -
按标题边界分割,形成父块(章节/小节),每个父块=标题+对应正文,保留完整结构单元 -
过滤噪声:剔除页眉、页脚、页码、水印、重复导航
2. 细切与大小控制(子块)
-
对超过最大长度(如800 Token)的父块,仅在父块内部按段落/句子递归细切,不跨父块 -
最小块:不低于200 Token,避免碎片;最大块:不超过Embedding/LLM上下文上限(如text-embedding-v3上限8192 Token) -
重叠:chunk_overlap=100–200 Token(10%–20%),保留边界上下文
3. 元数据与索引增强
-
给每个块打结构标签:header_path=”入职流程→材料准备”、level=2、block_type=”list”、parent_id -
父子块索引(可选):子块建向量索引做精准召回,父块存完整上下文,检索时召回子块→聚合父块→给LLM完整上下文
#!/usr/bin/evn python3# -*- coding: utf-8 -*-import refrom langchain_community.document_loaders import Docx2txtLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitter, MarkdownHeaderTextSplitter#加载word文档并转带标题结构的文本(先转markdown/提取标题)loader = Docx2txtLoader("../file/人事流程管理文档.docx")documents = loader.load()# 将word文档的文本转换为markdown格式def convert_to_narkdown(text):"""将word文档中的章节标题转换为markdown格式"""lines = text.split("\n")markdown_lines = []for line in lines:line = line.strip()if not line:markdown_lines.append(' ')continue# 匹配 "第一章 总则"、"第二章 招聘录用流程" 等格式 -> 一级标题if re.match(r'^第[一二三四五六七八九十百]+章\s+', line):markdown_lines.append(f"# {line}")# 匹配 "1.1 目的"、"2.1 招聘需求提交" 等格式 -> 二级标题elif re.match(r'^\d+\.\d+\s+', line):markdown_lines.append(f"## {line}")# 匹配 "1.1.1 xxx" 等格式 -> 三级标题elif re.match(r'^\d+\.\d+\.\d+\s+', line):markdown_lines.append(f"### {line}")else:markdown_lines.append(line)return "\n".join(markdown_lines)# 转换为markdown格式markdown_content = convert_to_narkdown(documents[0].page_content)# 结构感知粗切:按markdown标题层级分割(对应word的标题1/2/3)headers_to_split_on = [("#", "一级标题"),("##", "二级标题"),("###", "三级标题")]header_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)header_chunks = header_splitter.split_text(markdown_content)# 递归细切:对超长标题块二次分割,仅在块内切,不破坏结构text_splitter = RecursiveCharacterTextSplitter(chunk_size=800,chunk_overlap=150,separators=["\n\n","\n","。",";",","," "])final_chunks = text_splitter.split_documents(header_chunks)# 查看结构for chunk in final_chunks:print(f"标题路径:{chunk.metadata}")print(f"内容:{chunk.page_content[:200]} ...\n")
实操心得
做了几个项目后,我发现结构感知分块特别适合以下场景:
-
技术文档:API文档、SDK使用指南 -
操作手册:产品使用说明、设备操作流程 -
制度文档:人事制度、财务流程、审批规范 -
行业白皮书:研究报告、市场分析
最近做API文档RAG,用结构感知分块后,模型不仅能准确回答API参数问题,还能给出完整的使用示例,效果比之前好太多了。
最后想说的
结构感知分块虽然实现起来比固定长度分块复杂,但效果确实好很多。
如果你正在做RAG项目,特别是处理结构化文档,强烈建议试试这个方法。
当然,具体实现的时候要根据文档类型调整解析策略,比如Markdown用正则,HTML用BeautifulSoup,PDF用专门的解析库。
大家有什么结构分块的好方法,欢迎在评论区分享,一起交流进步!