 夜雨聆风
夜雨聆风





OpenClaw 语音:从唤醒、理解生成到打电话与加入会议
2026 年 OpenClaw 把一个真实运行的语音 agent 摊开在 GitHub 上:6 个语音模块、13 家 TTS provider、完整电话路径、realtime + consult 双层实时架构。本期把它逐层拆开。
§ 0. 只看语音栈,不展开 IM 与编排
打开 OpenClaw 仓库,6 个跟语音有关的模块单独成栈,这篇只拆这一栈。IM 桥接、agent 编排、provider 路由这次不展开。
2026 Q1 做语音 agent,模型层已经不是瓶颈——OpenAI Realtime / Gemini Live 稳定给到亚秒级双工,gpt-4o-mini-tts / Gemini TTS 能通过 prompt 直接控音色和情绪。真正卡的是工程缝合层:S2S 模型的 barge-in 容易被咳嗽 / 附和词误触;长耗时 tool call 塞进 realtime session 会阻塞音频通道;PSTN 入口的 8 kHz μ-law 重采样要做到毫秒级、不能依赖 ffmpeg 启动;多端唤醒词要强一致、不能各端各存;13 家 TTS provider 能力不齐(voice clone、deterministic seed、native Opus),得在 channel 抽象层抹平。OpenClaw 这条仓库给的工程答案是 realtime + consult 双层 + Gateway 中枢 + provider capability advertising。开源里把这套都跑通的项目本来不多。
先看它能干嘛,再读代码。
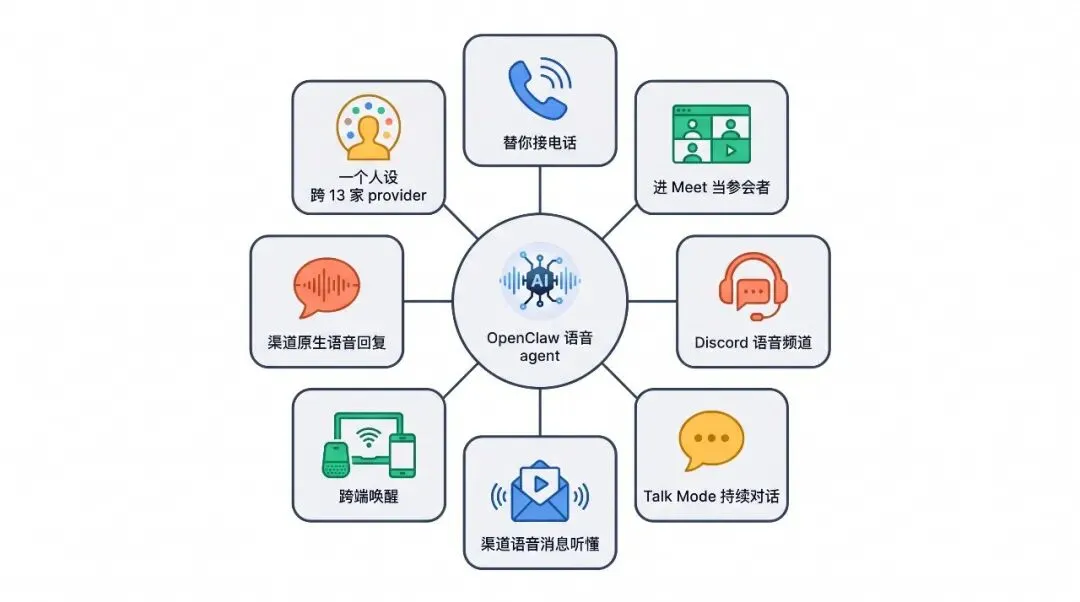
§ 1. OpenClaw 语音能做什么
下面 8 件事都在 main 分支默认运行、release notes 可查。
1.1 替你接电话
绑定 Twilio / Telnyx / Plivo 之后,agent 真接 PSTN 电话:白名单决定谁能打进来,outbound 主动呼出做通知或多轮交流。Twilio 路径下 inbound 还可以直接挂 OpenAI Realtime API 或 Gemini Live API 做亚秒级双工对话;Telnyx / Plivo 当前走各自 provider-native 的 listening / TTS / webhook 流程。是 carrier 真发到电信网络的呼叫,不是合成场景。
真实用例:候选人电话筛面试;客户结果回访;你忙着不能接的来电它先问清楚再短信摘要给你;老人电话提醒服药。
1.2 进 Google Meet 当参会者
OpenClaw 2026-04-25 上线的新能力:用个人 Google 账号授权后,agent 作为参会者加入 Meet。它听全程发言、记笔记、按你给的指令插话、会后导出 transcript / 行动项 / 出席统计。
真实用例:你不在的会议它代你听;多语言会议里它做实时翻译;技术评审里它对着代码仓库给即时反馈。
1.3 在 Discord 语音频道里随叫随到
/vc 命令让 agent 加入服务器的语音频道,整个频道的人都能直接跟它语音聊——查文档、查时区、查赛事、做翻译,配合 OpenClaw 自己的工具链。
真实用例:游戏战队语音里随时问 wiki;多语言开源社区的实时翻译机器人;活动主持的 co-host。
1.4 持续语音对话,会被打断、会等思考、会自然填充
按一下进 Talk Mode,听-想-说循环:模型边听边想边说,被你打断会立刻停止当前播放、把”被打断”这件事记进下一轮 prompt;等待深度查询时它会自然说”嗯让我看看”——避免出现 5 秒无声等待。
真实用例:开车时的助理;做饭跟着菜谱讲解;睡前读书伴侣;运动时的播报教练。
1.5 任意渠道的语音消息都能听懂
微信 / Telegram / WhatsApp / Slack / Feishu / iMessage / QQ / Matrix / IRC / Mattermost / Nostr 等 20+ 渠道里发的语音消息和录音,自动转录后进 prompt。群里 @ 机器人的语音消息也能正确识别 mention,靠的是一段 preflight transcription——先做一次便宜转录确认是不是叫了我。
真实用例:跨多个工作群的统一语音问答;老人在家庭群发语音它能跟回;HR 群里候选人发语音简历它结构化处理。
1.6 跨设备喊一声,所有端都听得见
打开 macOS app、iOS app 同时挂着,对哪台喊”openclaw”哪台立刻进 listening 状态。唤醒词不是各端各存——iPhone 改成”computer”,Mac 立刻同步。
真实用例:家里多端协同(厨房 iPhone / 书房 Mac);办公桌上离哪台麦克风近就用哪台;家人共享一台 Mac,按角色把唤醒词路由到不同 agent。
1.7 回复自动播报为渠道原生语音消息
13 家 TTS provider(OpenAI / ElevenLabs / Azure Speech / Google Gemini / Volcengine / MiniMax / Xiaomi MiMo / xAI / Inworld / Local CLI / Microsoft / OpenRouter / Vydra)任选。回复在 Feishu / WhatsApp / Telegram / Matrix 上自动变成渠道原生的语音消息(voice note),不是文件附件,而是带 PTT 标记、能在锁屏上预览波形的那种。
真实用例:voice-only 习惯的人无需切换打字;老人收到的回复直接能听;走路或开车时手机播给你听;同时还允许 LLM 在文本里塞
[[tts:voiceId=... emotion=...]]当场切声音、调情绪。
1.8 一个人设,跨 13 家 provider 说出同一个声音
定义一个人设(persona,比如 alfred: dry, warm British butler narrator),可以同时绑定 Google Gemini TTS 与 OpenAI TTS 的音色(voice)、以及 ElevenLabs 的 voiceId + seed。provider 切换,人设不变——某天 ElevenLabs 故障切到 Azure Speech,听众感觉不到区别。
真实用例:长篇内容(小说连载、播客)保持音色统一;多模态生产线;品牌专属配音不依赖单一供应商。
这 8 件事难度差不少:浅的就是”听懂消息 + 朗读回复”,深的做到”加入会议 / 接电话 / 实时双工”。OpenClaw 从浅做到深用了 5 个月,§10.3 拿 release timeline 给你拆。
下面从实现层把这些能力逐个拆开。
§ 2. 六模块全景
先把地图摆出来。把 OpenClaw 的语音相关代码 / 文档摊开,会出现六个模块,职责完全不重叠:
|
|
|
|
|
|
|---|---|---|---|---|
| Voice Wake |
|
|
|
docs/nodes/voicewake.md |
| Talk Mode |
|
|
|
docs/nodes/talk.md |
| Audio Understanding |
|
{{Transcript}} 模板变量 |
|
docs/nodes/audio.md |
| TTS |
|
|
|
docs/tools/tts.md |
| Realtime Voice |
|
|
|
src/realtime-voice/* |
| Voice Call |
|
|
|
docs/plugins/voice-call.md |
整体大图:
streaming
realtime
openclaw_agent_consult
留意两个细节,避免后面读起来打架:
-
• Realtime Voice 和 Voice Call 不是同一个东西:前者是”模型直接说话”的双工链,后者是”模型说的话被搬到电话语音流上”的传输层;二者可以组合,也可以独立。 -
• 六个模块共享一个 Gateway 中枢:唤醒词、TTS persona、voice routing 这种”用户级状态”不在各端各存一份,而是由 Gateway 集中持有、广播给所有节点。
下面顺着”Gateway 中枢 → 输入识别 → 状态机 → realtime + consult 双层 → 输出播报 → 电话路径”这条路逐个拆。
§ 3. Gateway 中枢:唯一的真相源
OpenClaw 的语音不是平铺在某个 app 里,而是一个多节点系统:
-
• macOS app 是一个节点 -
• iOS / Android 是各自的节点 -
• WebChat 是一个节点 -
• 电话进来的呼叫也是一个节点
这些节点之间有一个东西必须强一致:唤醒词。在 Mac 上喊”openclaw”,iPhone 上也得是”openclaw”;改一处,所有端都要立刻跟上。
OpenClaw 的解法很干净,看 docs/nodes/voicewake.md:
Wake words are a single global list owned by the Gateway. There are no per-node custom wake words.
具体协议:
voicewake.get → { triggers: string[] }voicewake.set → { triggers: string[] }voicewake.changed → 广播给所有 WS 客户端 + 所有节点存储路径:~/.openclaw/settings/voicewake.json,shape 极简:
{ "triggers": ["openclaw", "claude", "computer"], "updatedAtMs": 1730000000000 }更进一步,还有 trigger → target 路由表(voicewake.routing.set),你可以让”robot wake”这个唤醒词直接路由到某个特定 agent / sessionKey,而别的唤醒词走”current”会话。
这个设计的关键不在于技术多新颖,而是把控制平面与数据平面做了彻底解耦:
voicewake.changed broadcast
voicewake.changed broadcast
voicewake.changed broadcast
voicewake.changed broadcast
control RPC
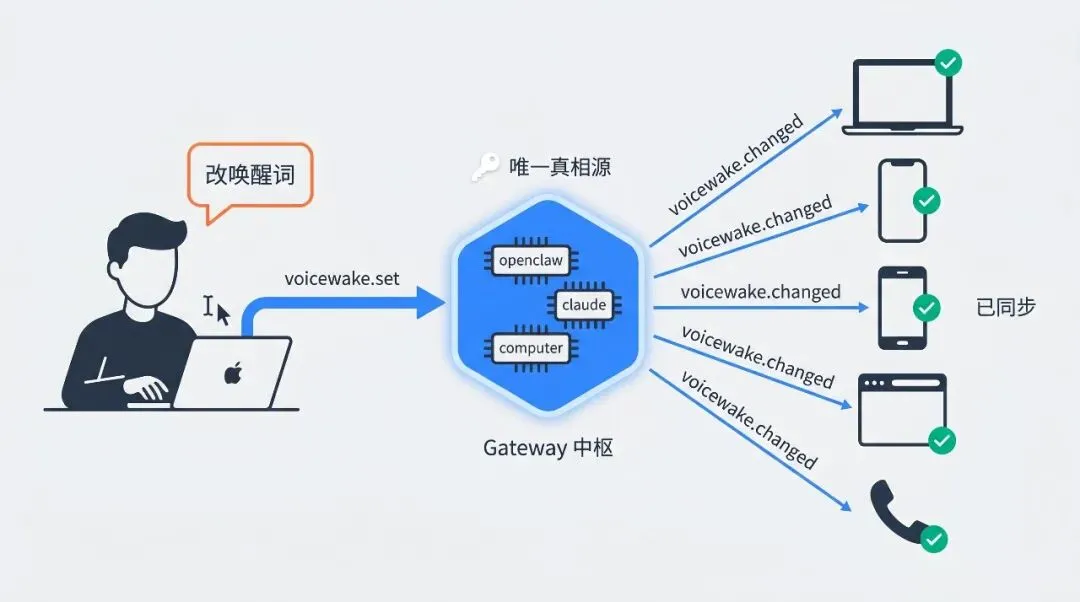
任何节点的 UI 都可以改唤醒词,但真值只在 Gateway。这是工业级语音 agent 的第一个工程基线:不要让多端各自存配置,否则会一直在解一类 sync 不一致问题。
§ 4. 输入路径:Audio Understanding 的 fallback 链
要把用户发来的语音消息转成模型能理解的文本,OpenClaw 的做法远不止”调一家 ASR API”那么简单。
docs/nodes/audio.md 里的 auto-detect 顺序——按代码注释翻译:
-
1. active reply model(如果当前 LLM provider 自身支持音频理解,比如 Gemini / GPT-4o) -
2. 本地 CLI: sherpa-onnx-offline→whisper-cli→whisper(Python) -
3. Gemini CLI 兜底 -
4. Provider auth fallback:OpenAI → Groq → xAI → Deepgram → Google → SenseAudio → ElevenLabs → Mistral
yes
no
yes
no
yes
no
yes
no
yes
no
里面有几处工程细节值得点出:
① preflight transcription群聊场景里,OpenClaw 要先看消息有没有 @机器人。语音消息没有文本,怎么办?先做一次廉价转录,拿转录结果去匹配 mention 模式,命中再走完整 pipeline。这一步很多产品没做,导致群里的语音 @ 直接被忽略。
② maxBytes 与 timeout 在每一跳前再检查这些限制不在 pipeline 启动时统一算一次,而是每个 provider/CLI 各自维护自己的 size cap 和 timeout。一家失败,自动跳下一家。
③ tools.media.audio.maxChars 默认 unset即给完整转录,不主动截断。agent 要的是全量文本,截断让 LLM 上下文残缺反而更糟。
输入侧的设计是把所有路径并联,让 fallback 自然发生,不让任何一家供应商成为单点故障。在 voice 这种”任何一跳不可用用户就听不到回答”的链路上,这是必需的。
§ 5. 状态机:Talk Mode 的 Listening → Thinking → Speaking
Talk 模式是 OpenClaw 最贴近”打电话感”的能力——按一下,进入持续语音对话,模型边听边想边说。
实现的核心是一个清晰的状态机,从 docs/nodes/talk.md:
-
1. Listen — 持续抓麦克风 -
2. Send transcript — 在一个 silence window 内(macOS / Android 700 ms,iOS 900 ms)没新输入就把当前 transcript 发出去 -
3. Wait for reply — 状态进入 Thinking -
4. Speak — 通过 talk.speakprovider 朗读 -
5. Interrupt on speech — 用户开始说话立即停掉播放,并把”我被打断了”这件事记录给下一次 prompt
收到部分 transcript
silence window 触发
用户退出 Talk
模型 reply 到达
模型出错 / 超时
用户退出
播放完成
用户开始说话 (barge-in)
用户退出
Listening
Thinking
Speaking
interruptOnSpeech: true (默认)播放被打断 → 标记interruption timestamp附加到下一轮 prompt
四个工程亮点:
5.1 模型主动控制声音的 JSON 指令
模型每次回答的第一行可以塞一段 JSON:
{ "voice": "alfred", "once":true }支持的键:voice/voiceId、model、speed/rate、stability、similarity、style、speakerBoost、seed、lang、output_format、latency_tier。
这条 JSON 在 TTS 之前会被剥掉,不会被朗读。once: true 表示”只对这一句生效”;不带 once 就成为新默认值。
这等于把”声音风格”这个维度交给了 LLM,让它在长对话里自己换音色。LLM 是 conductor,指挥 voice provider,而不是反过来。
5.2 macOS 的 push-to-talk 和 wake-word 共存
docs/platforms/mac/voice-overlay.md 里写了一个我觉得很有教育意义的细节:
If the overlay is already visible from wake-word and the user presses the hotkey, the hotkey session adopts the existing text instead of resetting it.
具体到代码层,每次 capture 都有一个 token;token 不匹配的回调会被丢弃。wake-word 的悬浮窗已经显示部分识别文字了,用户突然按住快捷键继续说,它会把之前的文字接上去而不是重置。
5.3 silenceTimeoutMs 不是一个数
平台默认值不一样:macOS / Android 700 ms,iOS 900 ms。原因是 iOS 的 SFSpeechRecognizer 推送中间结果的频率天然慢一些,拿 700 ms 卡它会经常误触发”用户说完了”。
OpenClaw 把这个差异写进了文档。
5.4 Android 的前台服务
Android 上 Talk 模式跑的时候是用前台服务(foreground-service type: microphone)抓音频,否则系统会在后台杀掉麦克风进程。这是平台事实,没有什么巧妙办法。
§ 6. agent_consult 机制:让 realtime 模型调用完整 agent
OpenAI Realtime API(如 gpt-realtime / gpt-realtime-1.5)、Gemini Live API(如 gemini-3.1-flash-live-preview)这类 speech-to-speech 实时模型(下称 S2S 模型)的特点是:自己就是一个能说会听的小模型,端到端延迟很低,原生也已具备一定 tool use / function calling 能力。但它并不等同于 OpenClaw 主 agent 的完整 runtime——OpenClaw 那一套 read / web_search / memory / 自定义 skill 工具链需要通过 agent_consult 接入,不是 S2S 模型本体直接拥有。
OpenClaw 的解法非常直接:让 realtime 模型当前台,OpenClaw 主 agent 当幕后顾问,realtime 模型通过一个工具调用把幕后 agent 请进来。这正是仓库里 openclaw_agent_consult 这个工具名 + system prompt 里 “behind-the-scenes consultant for a live voice agent” 的字面意思。
这个工具叫 openclaw_agent_consult。看 src/realtime-voice/agent-consult-tool.ts:
export const REALTIME_VOICE_AGENT_CONSULT_TOOL: RealtimeVoiceTool = { type: "function", name: "openclaw_agent_consult", description: "Ask the full OpenClaw agent for deeper reasoning, current information, " + "or tool-backed help before speaking.", parameters: { type: "object", properties: { question: { type: "string", description: "..." }, context: { type: "string", description: "Optional relevant context or transcript summary." }, responseStyle: { type: "string", description: "Optional style hint for the spoken answer." }, }, required: ["question"], },};策略有三档,控制幕后 agent 能用多少工具:
|
|
|
|---|---|
safe-read-only |
read、web_search、web_fetch、x_search、memory_search、memory_get |
owner |
toolsAllow=undefined);owner-only 工具仍由正常 agent 权限判定 |
none |
|
幕后 agent 实现在 agent-consult-runtime.ts:
// 摘自 consultRealtimeVoiceAgent()const result = await params.agentRuntime.runEmbeddedPiAgent({ sessionId, sessionKey: params.sessionKey, agentId, prompt: buildRealtimeVoiceAgentConsultPrompt({...}), thinkLevel: params.thinkLevel ?? "high", toolsAllow: params.toolsAllow, extraSystemPrompt: "You are a behind-the-scenes consultant for a live voice agent. " + "Be accurate, brief, and speakable.",});注意三件事:
-
1. thinkLevel——consult runtime 的兜底默认是"high",让幕后 agent 可以狠想;具体入口可覆盖(例如电话路径会先走resolveThinkingDefault(...)再传入) -
2. extraSystemPrompt里专门强调 speakable——因为答案要被朗读出去,所以约束幕后 agent 不能用 markdown 格式、不能输出 tool log -
3. 复用 sessionKey——consult 后台 agent 复用同一条后台 session(共享 sessionKey/sessionId),让多次 consult 记忆连续;它与 realtime provider 自己的会话是协同关系,不是同一个 session
整个机制可以用一张图描述:
简单回答
工具 / 当前信息 / 深度思考
openclaw_agent_consult
concise + speakable
朗读幕后答案
这个架构的精妙在于两层模型分别承担它们最擅长的事:
-
• realtime 模型只负责低延迟的语音交互、turn-taking、语调情绪 -
• 幕后 agent只负责”答得对”——查资料、读文件、长链推理
这是 think-while-speaking 的工程化近似实现:模型自己端内不能边推理边发声,就外置一个慢思考的幕后 agent,realtime 模型边说”嗯,让我想一下”边等幕后 agent 结果。
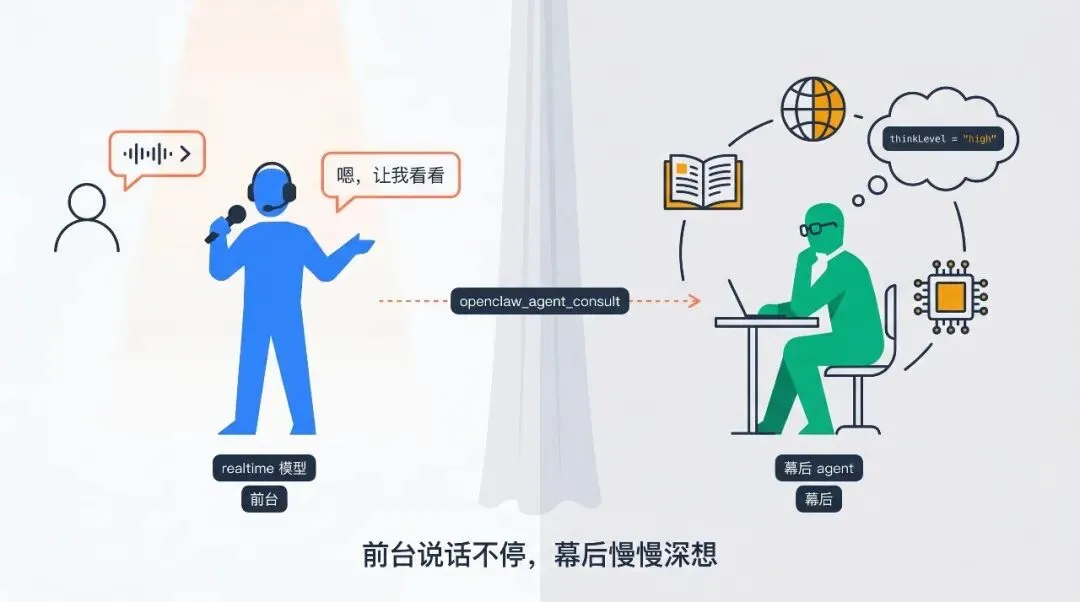
更细节的一点:这个 consult 过程对 realtime 模型是异步的。realtime 模型可以在等待幕后 agent 期间继续接收用户说话、说”我在查”、甚至完成不需要工具的小闲聊。具体实现是 realtime bridge 收到 tool call 后先异步执行 consult,再通过 submitToolResult(...) 把答案回填给 realtime session,期间音频 channel 保持开着。
§ 7. 输出层:13 provider TTS + Persona + Directive
docs/tools/tts.md 是 OpenClaw 文档里最长的一篇——输出层是接口层,要面对各家供应商各自的脾气。
7.1 Provider 矩阵
OpenClaw 接的 13 家:
Azure / ElevenLabs / Google Gemini / Gradium / Inworld / Local CLI /Microsoft / MiniMax / OpenAI / OpenRouter / Volcengine / Vydra / xAI / Xiaomi MiMo数过去 14 个名字,文档头说”13 speech providers”——统计口径可能因 Vydra 是共享 image/video/speech 工具而少算了一个,是 OpenClaw 文档自己的小不一致。
不是所有 provider 都有相同能力。文档里列了一张矩阵:能不能 voice clone、能不能 deterministic seed、native voice note 支持哪些 codec……这一层抽象在工程上叫 provider capability advertising,channel 端按 capability 决定要不要请求 Opus 或退到 MP3。
7.2 Persona 解析顺序
Persona 是”稳定的人设”。配置文件长这样:
personas: { alfred: { label: "Alfred", description: "Dry, warm British butler narrator.", provider: "google", fallbackPolicy: "preserve-persona", prompt: { profile: "A brilliant British butler. Dry, witty, warm...", scene: "A quiet late-night study...", style: "Refined, understated, lightly amused.", accent: "British English.", pacing: "Measured, with short dramatic pauses.", constraints: ["Do not read configuration values aloud."], }, providers: { google: { voiceName: "Algieba", promptTemplate: "audio-profile-v1" }, openai: { model: "gpt-4o-mini-tts", voice: "cedar" }, elevenlabs: { voiceId: "...", seed: 42, voiceSettings: {...} }, }, },}值得注意的是:persona 的 prompt 字段是 provider-neutral 的,由各家供应商自行决定如何解析——
-
• Google 把它包成 audio-profile-v1模板送进 Gemini TTS 的 prompt 结构 -
• OpenAI 把它映射到 instructions字段 -
• ElevenLabs 完全忽略,只用 personas.<id>.providers.elevenlabs里的 voiceId/seed
fallbackPolicy 有三档:preserve-persona(默认,prompt 字段透传给可能用得上的 provider)、provider-defaults(这家用不上就直接走默认,别勉强)、fail(这家配不上 persona 就跳过它)。
7.3 模型可控的 TTS Directive
这是最有意思的设计。模型回答里允许夹这种东西:
Here you go.[[tts:voiceId=pMsXgVXv3BLzUgSXRplE model=eleven_v3 speed=1.1]][[tts:text]](laughs) Read the song once more.[[/tts:text]]streaming block 在送给 channel 前会剥掉 directive,跨 block 也能正确剥离。这是把声音和情绪的控制权交还给模型,让 LLM 在文学/情绪需要的时候自己切声音、调情绪。
权限上做了对应收敛:默认 [[tts:provider=...]] 会被忽略,必须 modelOverrides.allowProvider: true 才允许 LLM 切换 provider。
7.4 解析优先级
最后给个解析顺序,工程上你早晚要用:
1. messages.tts ← 全局2. agents.list[].tts ← 当前 agent 的 override3. channels.<channel>.tts ← 渠道 override4. channels.<channel>.accounts.<id>.tts ← 渠道账号 override5. local /tts 偏好 ← 本机用户偏好6. inline [[tts:...]] directive ← 本次 reply 的临时指令后面每一层都会 deep-merge 在前一层之上:层级越靠近用户优先级越高。
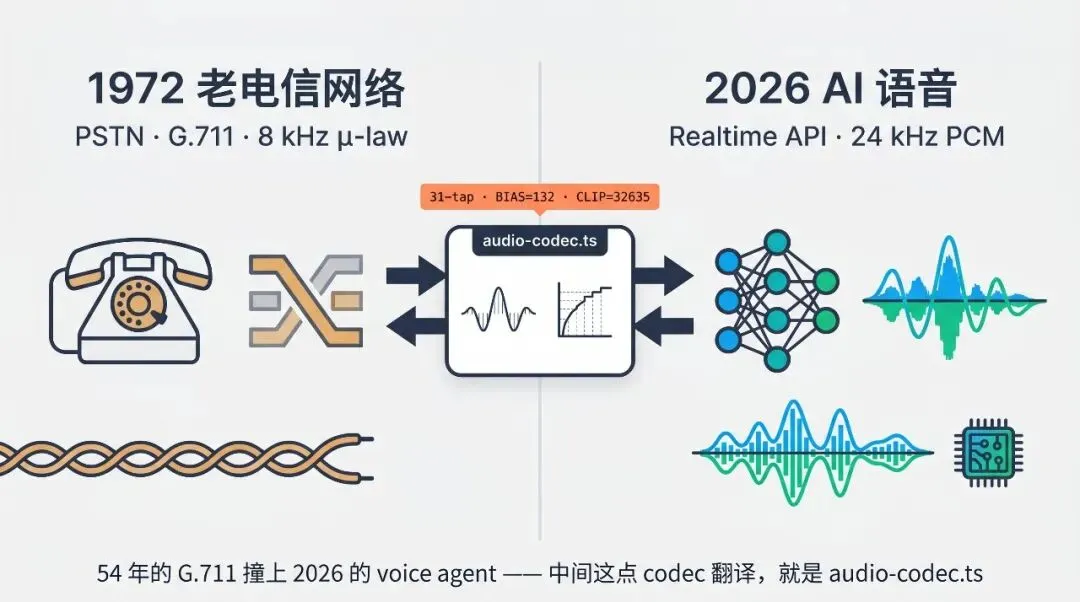
§ 8. 电话路径:μ-law 8 kHz 与重采样
PSTN/SIP 的标准采样率是 8 kHz μ-law——1972 年的 G.711 标准,全球电信网都在这个老标准上。
所以语音 agent 接 Twilio / Telnyx / Plivo 的时候,模型那边吐 24 kHz 或 48 kHz PCM,电话那边只认 8 kHz μ-law。中间这一段重采样 + codec 转换,OpenClaw 自己写在 src/realtime-voice/audio-codec.ts 里。
我把核心算法摘出来读:
const TELEPHONY_SAMPLE_RATE = 8000;const RESAMPLE_FILTER_TAPS = 31;const RESAMPLE_CUTOFF_GUARD = 0.94;// windowed-sinc resamplefunction sampleBandlimited(input, inputSamples, srcPos, cutoffCyclesPerSample) { const half = Math.floor(RESAMPLE_FILTER_TAPS / 2); const center = Math.floor(srcPos); let weighted = 0, weightSum = 0; for (let tap = -half; tap <= half; tap += 1) { const sampleIndex = center + tap; if (sampleIndex < 0 || sampleIndex >= inputSamples) continue; const distance = sampleIndex - srcPos; const lowPass = 2 * cutoff * sinc(2 * cutoff * distance); const window = 0.5 - 0.5 * Math.cos((2 * Math.PI * tapIndex) / (TAPS - 1)); const coeff = lowPass * window; weighted += input.readInt16LE(sampleIndex * 2) * coeff; weightSum += coeff; } return weighted / weightSum;}// μ-law 编码:G.711 标准function linearToMulaw(sample) { const BIAS = 132, CLIP = 32635; const sign = sample < 0 ? 0x80 : 0; if (sample < 0) sample = -sample; if (sample > CLIP) sample = CLIP; sample += BIAS; let exponent = 7; for (let m = 0x4000; (sample & m) === 0 && exponent > 0; exponent--) m >>= 1; const mantissa = (sample >> (exponent + 3)) & 0x0f; return ~(sign | (exponent << 4) | mantissa) & 0xff;}几个工程判断:
-
• 31-tap windowed-sinc——31 个抽头是个工程妥协,比 nearest 高得多但比 256-tap 便宜很多,足够电话语音 SNR -
• RESAMPLE_CUTOFF_GUARD = 0.94——为了防止 aliasing 给的 6% 余量 -
• G.711 μ-law 是手写位运算实现的——没有依赖 ffmpeg,直接编进二进制,因为电话路径里 ffmpeg 启动开销也是延迟来源
电话路径里 Twilio realtime 的形态长这样(Telnyx / Plivo 走各自 provider-native 的 transcription / TwiML / speak action,实现细节不同但同样收敛到 Agent → TTS 这条链):
streaming
realtime
文档里有一句关键:
realtime.enabledcannot be combined withstreaming.enabled. Pick one audio mode per call.
为什么?这两种模式代表了对延迟与质量的不同权衡:
-
• streaming走 ASR provider 转录,模型用文本回答,TTS 朗读 → 经典 STT→LLM→TTS pipeline,延迟 1.5-3 秒 -
• realtime走 S2S 模型双工 → 理想链路下 TTFA(用户说完到首帧可听音频)300-700 ms,实际强依赖网络 / VAD / 地域;只能在支持 realtime 的 provider(OpenAI Realtime API / Gemini Live API)下用
这是配置层的模式选择,但也受 provider 能力边界约束——目前 realtime 电话模式仅对 Twilio 开放。
§ 9. 延迟估计:每段时间花在哪
下面是各路径的延迟估算。前提说在前面:OpenClaw 自己没有 publish 端到端 benchmark,下面的数字是基于上游 provider 公开延迟做的口径推算——是合理量级,不是测出来的真值。
9.1 经典 STT → LLM → TTS pipeline(Talk Mode 默认)
用户停说话 │ ├─ silence window (OpenClaw 默认 700~900 ms) ───┐ │ │ ├─ STT 收尾 (50~200 ms) │ │ │ ├─ LLM 首 token (50~800 ms, 详见下文) ├─ 总延迟 1~3.5 s │ │ ├─ LLM 完整 reply (300~1500 ms, 长度决定) │ │ │ ├─ TTS 首包 (90~300 ms) │ │ │ └─ 网络抖动 + 播放 buffer (100~500 ms) ──────────┘两段值得展开:
silence window——OpenClaw 写死 macOS / Android 700 ms、iOS 900 ms(在 silenceTimeoutMs 未设置时的代码默认值),是保守兜底。2026 年主流 voice agent 框架更多用 Semantic VAD(语义级停顿预测)——不再单纯卡静音时长,而是用一个轻量模型判断用户语义是否完整,经验上能压到数百毫秒级。OpenClaw 的 700~900 ms 更像”不想引入额外模型时的安全默认值”,不是 2026 年的体验上限。
LLM 首 token——一般模型在数百毫秒到 1 秒区间。2026 年的极致路径是 Groq / Cerebras / SambaNova 这种专用推理硬件,短上下文下常规文本模型 TTFT 可见百毫秒级。600 ms 更像”普通云端 + 长 prefill 上下文”的容忍上限,而非追求值。
把这两段一起拉紧,经典 pipeline 的端到端首响最快可以做到 1 s 出头,不用走 S2S 模型也行。代价是语义级 VAD 模型 + 推理硬件成本。
9.2 Realtime + consult 双层
用户停说话 │ ├─ realtime 模型 turn-end 检测 (~150 ms) │ ├─ ① 简单回答路径 │ └─ realtime 模型直接说话 (TTFA ~200~400 ms,仅在理想链路) │ └─ ② 工具/深度推理路径 ├─ realtime 模型触发 openclaw_agent_consult ├─ realtime 模型可同时说"让我查一下" (覆盖掉纯静音等待感) ├─ 幕后 agent runEmbeddedPiAgent (1~10 s 视工具复杂度) └─ 幕后 agent result → realtime 模型朗读 (~200 ms)consult 模式的妙处:①路径首句延迟低到 < 500 ms,②路径用”我在查”这种填充话术盖住幕后 agent 的几秒思考,给用户的体感更接近”和真人一样停顿了一下”——前提是轻工具调用 + warm prompt cache + 理想链路;重工具或冷启动下,realtime 模型仍要被迫多重复”还在查……”。
9.3 电话路径
电话比 Talk 多一段编解码,但 8 kHz μ-law 帧很小(每 20 ms 一帧 160 字节),重采样开销在毫秒级,可以忽略不计。主延迟瓶颈在运营商侧的 RTP 抖动——好的 SIP trunk 抖动 30 ms 左右,差的能到 150 ms。
用户说话 │ ├─ 运营商 RTP 单程 (20~80 ms, 取决于地理 + trunk 质量) │ ├─ Webhook 接收 + μ-law→PCM (~5 ms) │ ├─ STT/realtime model (跟 Talk 一样) │ ├─ TTS reply │ ├─ PCM→μ-law + RTP 单程 (20~80 ms) │ └─ 用户听到 = Talk 延迟 + 40~160 ms RTP RTT电话场景的延迟容忍度比 IM 高一些(电话本来就习惯 200–300 ms 的回声),但可控性差,要靠运营商 + 区域选择。
9.4 总结
不同路径的实战延迟带(TTFA:用户说完到首帧可听音频;强依赖网络 / VAD / 地域 / WebRTC 直连):
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
§ 10. 趋势分析:语音能力下一步要什么
OpenClaw 是个有意思的”工业切片”——2026 年第一季度,一个严肃语音 agent 必须接受的工程现实是:
-
• 模型层 API 还没有标准化(OpenAI Realtime API / Gemini Live API 各家协议不同) -
• 各 provider 能力不齐(voice clone、seed、native opus……) -
• 端 / 云 / 电话三种 transport 必须全做 -
• 唤醒词、TTS 偏好这种”用户级状态”必须中心化
站在 OpenClaw 的代码视角,趋势可以落到三件具体的事:
10.1 consult 双层会被广泛复制
openclaw_agent_consult 这一手 OpenClaw 不是发明者,但他们把它做成了通用工具协议——任何支持双向音频与 tool use / function calling 的 live API 都可以适配这类 consult 模式。我预测未来一年 voice agent 框架(LiveKit Agents、Pipecat、Vocode)都会内置类似的”realtime + consult 双层”模板,因为:
-
1. 端到端 S2S 模型已具备基础工具调用,但对长耗时、重状态、跨服务的工具链,外挂 consult / runtime 仍更稳 -
2. 把完整工具调用塞进 S2S 模型训练成本太高,不如外置 -
3. consult 模式对延迟体验近乎无损(”让我查一下”完美填充等待)
10.2 Gateway 中枢会成为商业护城河
为什么 OpenClaw 把唤醒词放 Gateway,而不是各端自存?多端一致性是产品的硬体感。同样的逻辑会扩散到:persona 同步、TTS 偏好同步、voice routing 表。
谁先做出好用的”语音 agent 中枢”,谁就在平台层占住关键位置。Twilio / Vapi / LiveKit 都在朝这个方向走,但目前没有一家覆盖了 OpenClaw 这种”个人 agent + 多渠道 + 多端”的完整剧本。
10.3 工程参考:OpenClaw 语音能力的 5 个月演化
不喊口号,直接读 OpenClaw releases。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Talk Mode
|
|
|
|
|
Voice Call plugin
|
|
|
|
|
|
|
|
|
|
/vc 语音频道 + 自动加入 |
|
|
|
|
Realtime voice + openclaw_agent_consult
|
|
|
|
|
Google Meet plugin
|
|
|
|
|
|
|
5 个月——从”可选转录”推到”Realtime S2S 模型 + 参会者”。voice agent 行业已经进入工程标准化阶段:框架已经成型,每两周一个能力点上线。
把这条 timeline 和上面两节趋势对照:
-
• §10.1(consult 双层会被复制)——OpenClaw 自己也是 4 个月才合到 consult 这一手,但他们把它做成了通用工具协议。任何外人 fork 一周就能挂上自己的 S2S 模型。 -
• §10.2(Gateway 中枢成为护城河)——Voice Wake 在 v2.0.0-beta1 第一次出现就是 Gateway 集中持有 + 多端广播。4 个月之后,它仍然是 Gateway 中枢架构最干净的开源参考。
这条 timeline 也回答了一个开放问题:做 voice agent 要不要”等模型”?OpenClaw 的答案是不等——它在 2026-01-03 用 ElevenLabs + Apple Speech + 渠道转录拼出 Talk Mode,4 个月后再把它替换成 speech-to-speech 实时模型。OpenClaw 的做法是先把架构搭好,模型层换 provider 不重写架构。
10.4 开源 LLM-based ASR / TTS 跟上了 cloud API,社区接入是滞后项
2025–2026 一波开源 LLM-based 模型——ASR 侧 Voxtral、Qwen3-ASR、Kimi-Audio、Step-Audio R1.1,TTS 侧 MiMo、Step-Audio TTS、Cosy-Voice、Spark-TTS——精度、口语自然度、多语种、emotion / style 控制在很多场景已经能对标甚至超过 cloud API。理论上足够把 voice agent 从”必须挂 cloud”推到”本机跑得不错”。
工程现实是:OpenClaw 的本地 CLI 一档(sherpa-onnx / whisper-cli / whisper)和 TTS 的 Local CLI provider 用的还是能力一般的老开源模型。社区还没把这些新模型统一适配进 OpenClaw 的工具协议——比接一个 cloud API 难得多。一是推理栈还在快速变化(vLLM / MLX-VLM / SGLang 多种并存);二是更关键的:要对模型本体做深度推理部署优化,在端侧 / 中小规格 GPU 上把资源占用压下来同时不丢推理精度。谁先把这层补上,OpenClaw 这种 agent 就能从”挂 cloud”推到”本机跑得不错”。
§ 11. 对模型能力的进一步要求
如果我是 voice provider 或 LLM 厂商,看完 OpenClaw 的代码会得到这些具体功能需求。
11.1 对 speech-to-speech 实时模型(S2S Model / Realtime API)的要求
|
|
|
|
|---|---|---|
| 首包(TTFA)< 300 ms |
|
|
| 稳定 function call |
gpt-realtime 标注 Structured Outputs: No) |
agent_consult 把”输出结构化”委托给文本 LLM,绕过 S2S 模型这一短板 |
| 语义级智能打断(Semantic Barge-in) | 新痛点 |
|
| 可中断后状态可恢复 |
|
|
| 细粒度声音控制 |
|
[[tts:...]] directive 设计依赖于”模型能在文本里嵌入声音指令”——这一层未来会变成 SSML 的现代版 |
| persona-prompt 标准化 |
|
|
| deterministic seed |
|
seed: 42 让批量内容声音一致——这种 use case 会越来越多,不能再当奢侈功能 |
| native voice note codec |
|
|
| think-while-speak |
|
|
最关键的两条是 Semantic Barge-in 和可中断后状态恢复——这是 2026 consult 模式真正还没解决的部分。
11.2 对 LLM(幕后 agent)的要求
OpenClaw 幕后 agent 的 prompt 里专门写:
“You are a behind-the-scenes consultant for a live voice agent. Be accurate, brief, and speakable.”
这一句就直接点明了对 LLM 的核心需求:
|
|
|
|
|---|---|---|
| speakable output |
|
|
| brevity 约束 |
|
|
| 结构化思考但口播表达 |
|
|
| 结合实时工具结果再总结 |
|
|
| think_level 可控 |
|
thinkLevel = "high" 写死给 consult,要求 LLM 支持显式推理预算 |
| session continuity |
|
|
| 超长记忆冷启动延迟 | 新痛点 |
|
| 幕后 agent 首 token ≤ 500 ms |
|
|
特别提一句:幕后 agent 的延迟需求其实比 realtime 模型还严苛。realtime 模型说”嗯让我看看”用户能等的窗口本来就小(1.5 s 内最自然),幕后如果 2 s 还没出第一个 token,realtime 模型就要被迫重复”还在查……”,对话节奏明显塌陷。
这也是为什么 OpenClaw 在 consult runtime 里加了
fallbackText: "I need a moment to verify that before answering."——这是工程层面对”模型可能慢”做的防御。
11.3 对延迟的工程要求总结
把 OpenClaw 的实测和 2026 Q2 的主流基准拼起来,得到一份可落地的延迟预算:
组件级: STT 首词 ≤ 200 ms LLM 首 token ≤ 150 ms (Groq/Cerebras 路径) / ≤ 600 ms (常规云端) TTS 首帧 ≤ 300 ms链路级 (TTFA: 用户说完 → 首帧可听音频): Talk Mode TTFA ≤ 2 s (Semantic VAD + 极致推理可压到 1 s) Realtime TTFA ≤ 500 ms (理想链路;强依赖网络/VAD/地域) 电话场景额外 RTT ≤ 200 ms体验级: silence window 300~500 ms (Semantic VAD) / 700~900 ms (传统兜底) barge-in 检测 ≤ 100 ms 中断后下轮 prompt ≤ 1 s 幕后 agent 首 token ≤ 500 ms (prompt cache 普及后的合理目标)任何一条没达标都会让对话体验断层。
§ 12. 结语
OpenClaw 把一份完整的工业级语音栈开源在了一个仓库里。在这份代码里你能看到:
-
• 唤醒词怎么从 Gateway 一路同步到端 -
• 一段语音消息怎么经过 4 层 fallback 落到文本 -
• Talk 状态机的边界条件(push-to-talk 接管 wake-word 这种小细节) -
• consult 双层怎么用一个 90 行的 tool 定义和 100 行的 runtime 黏起来 -
• 13 个 TTS provider 的差异怎么用 persona + capability 抹平 -
• 8 kHz μ-law 重采样怎么用 31 tap windowed-sinc 实现
仓库:openclaw/openclaw。
延伸阅读:
• OpenClaw GitHub • Talk mode 文档 • Voice call 插件文档 • TTS 文档