 夜雨聆风
夜雨聆风





OpenAI 大神 Karpathy 开源:用 Obsidian 实现 LLM Wiki 知识库管理方法
OpenAI 创始成员、前 Tesla AI 总监 Andrej Karpathy,最近开源了一份很有启发的文档:《LLM Wiki》。
它不只是讲“怎么把文档喂给模型问答”,而是在讲一件更重要的事:如何让 LLM 持续帮你维护一个会“越用越聪明”的知识库。
原文地址:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
一、这套方法到底好在哪里?
先看大家最熟悉的做法:RAG。
传统 RAG 的问题
多数场景里,RAG 是“临时检索 + 临时回答”:
-
你提一个问题,模型去原始资料里找片段; -
临时拼一个答案出来; -
下一次再问,基本又要从头来一次。
这会带来一个核心问题:知识不积累。
如果一个问题需要综合 5 篇文档、3 次历史结论,模型每次都重复劳动,效率和稳定性都会下降。
Karpathy 的核心思路
他提出的是:让 LLM 增量维护一个持久化 Wiki(本质是一套 Markdown 知识库)。
新资料进来后,LLM 不只是“索引一下”,而是会:
-
提炼关键点; -
更新已有页面; -
增加交叉引用; -
标记冲突信息; -
把新结论整合进全局认知。 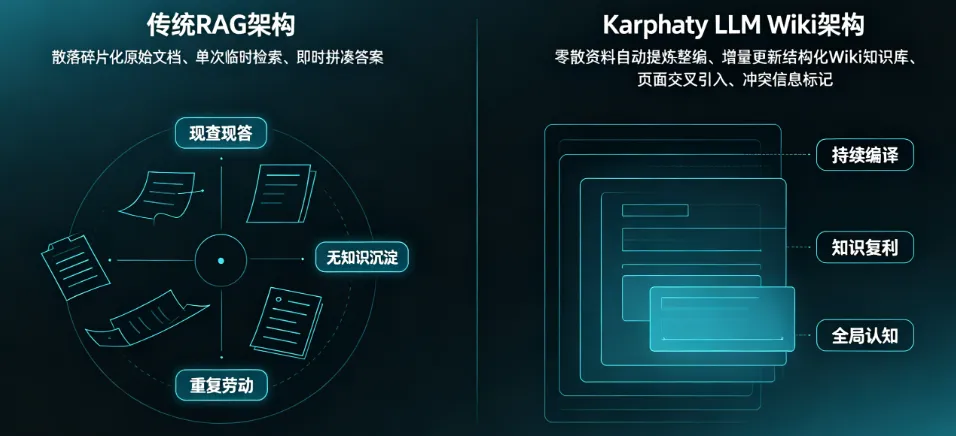
一句话概括:RAG 是每次现查,LLM Wiki 是持续编译,实现知识的真正复利与累积。
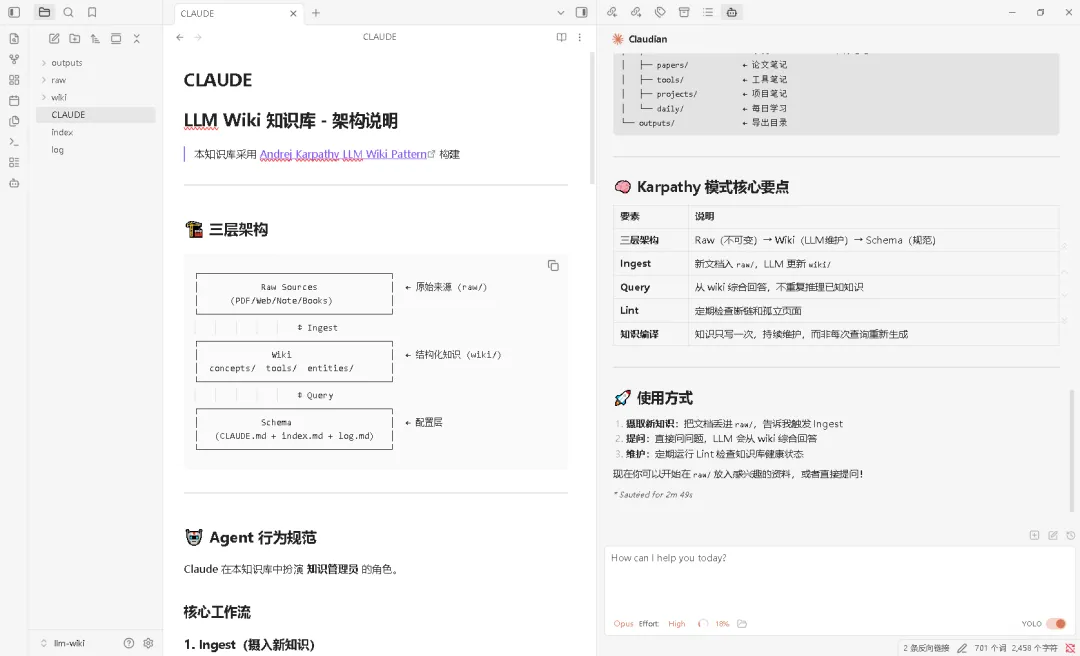
二、LLM Wiki 的三层架构
Karpathy 把结构讲得很清楚,只有三层:
1)Raw Sources(原始资料层)
-
文章、论文、会议记录、图片、数据文件等; -
只读、不改; -
这是最终事实依据(source of truth)。
2)Wiki(知识层)
-
一组由 LLM 维护的 Markdown 页面; -
包括概念页、实体页、对比页、综述页、结论页; -
你负责阅读,LLM 负责写和维护。
3)Schema(规则层)
-
用 CLAUDE.md定义规则; -
规定页面结构、命名规范、更新流程、查询流程; -
让模型从“聊天助手”变成“知识库维护员”。

你可以把它理解成:Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。
三、为什么 Obsidian 是这个方案的最佳搭档?
因为它几乎天然适配这套方法:
-
Markdown 原生:LLM 读写成本低; -
双链与图谱:可直观看到知识网络结构; -
本地优先:隐私和可控性更好; -
插件生态:Dataview、Marp、Web Clipper 都能接入; -
Git 友好:知识库可版本化、可回滚、可协作。
Karpathy 还给了几个实操建议:
-
用 Web Clipper 抓文章到本地; -
把图片下载到本地目录,避免外链失效; -
用固定格式维护 log.md,便于自动化解析; -
小规模先靠 index.md,规模变大再考虑专门搜索工具。
四、创建知识库
下面给出一套 30 分钟可完成的最小可用搭建流程。
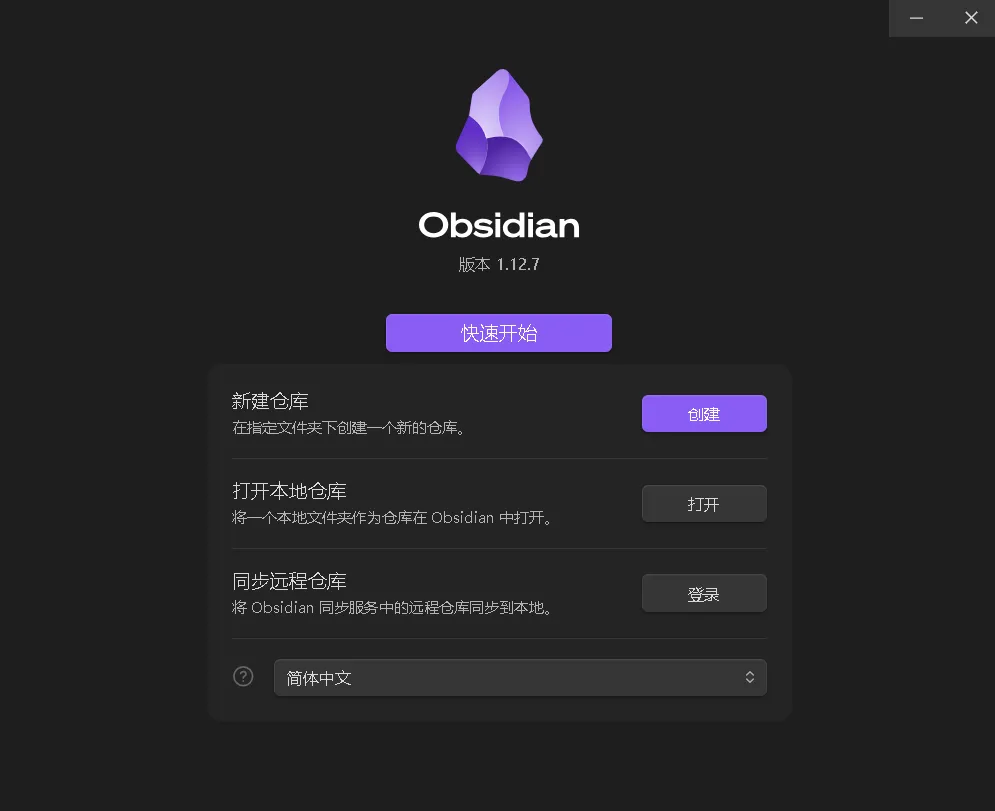
第一步:准备 Obsidian 环境
Obsidian 是一款本地知识管理笔记软件,适合搭建私有化、可版本化的知识库。
下载地址:https://obsidian.md/zh/
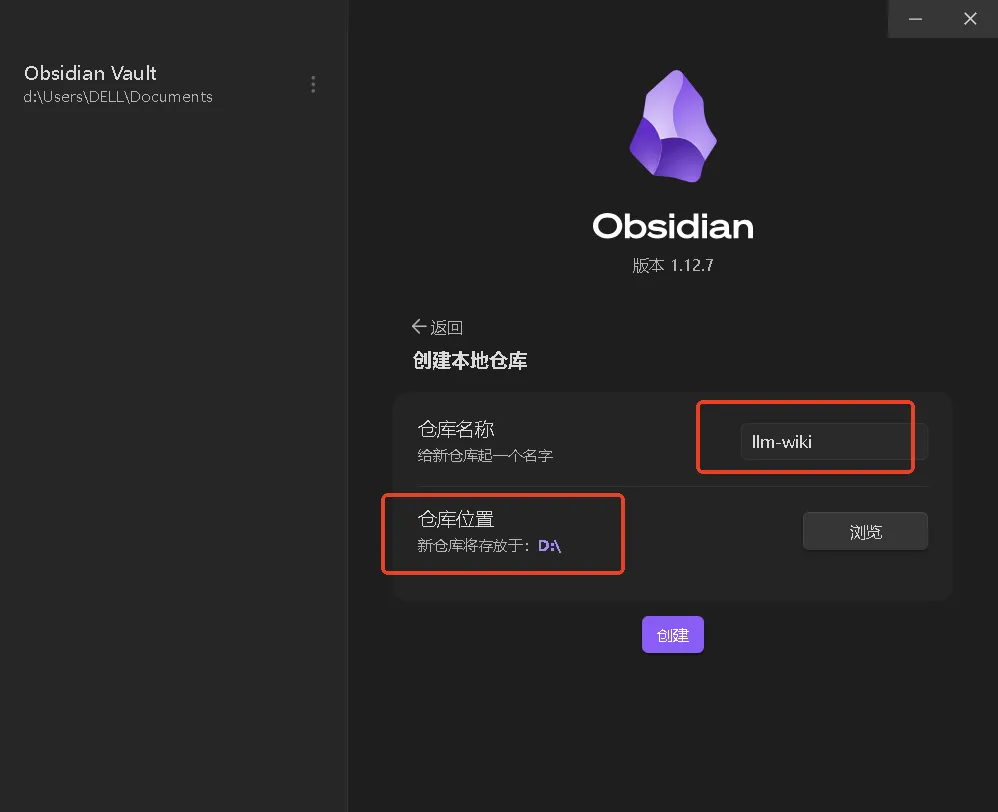
第二步:创建 Obsidian 仓库
第三步:下载 Claudian 插件
项目地址:https://github.com/YishenTu/claudian/releases/tag/1.3.72
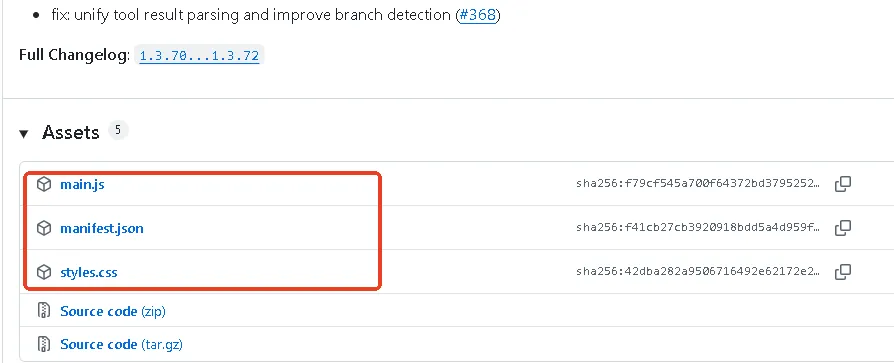
下载 main.js、manifest.json、styles.css 三个文件。
在仓库目录下创建 /.obsidian/plugins 文件夹:
# 我的仓库路径是 D:\llm-wikimkdir D:\llm-wiki\.obsidian\plugins若 claudian 目录不存在,请先手工创建,再将上述三个文件复制到 Vault/.obsidian/plugins/claudian/:
robocopy "C:\Users\DELL\Downloads\claudian" "D:\llm-wiki\.obsidian\plugins\claudian" /E# 或者xcopy "C:\Users\DELL\Downloads\claudian" "D:\llm-wiki\.obsidian\plugins\claudian" /E /I /H /Y第四步:信任仓库并启用插件
重新打开 Obsidian,会提示是否信任该仓库作者,点击“信任仓库作者并启用插件”。
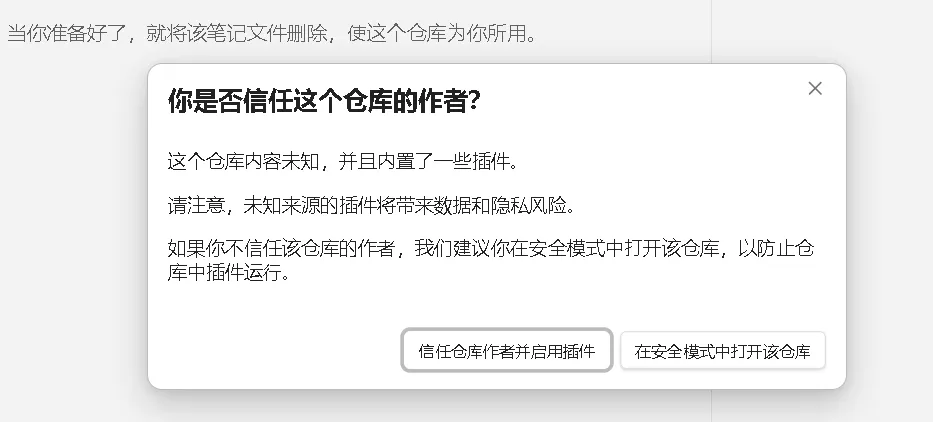
系统会自动打开第三方插件页,把 Claudian 的开关打开。
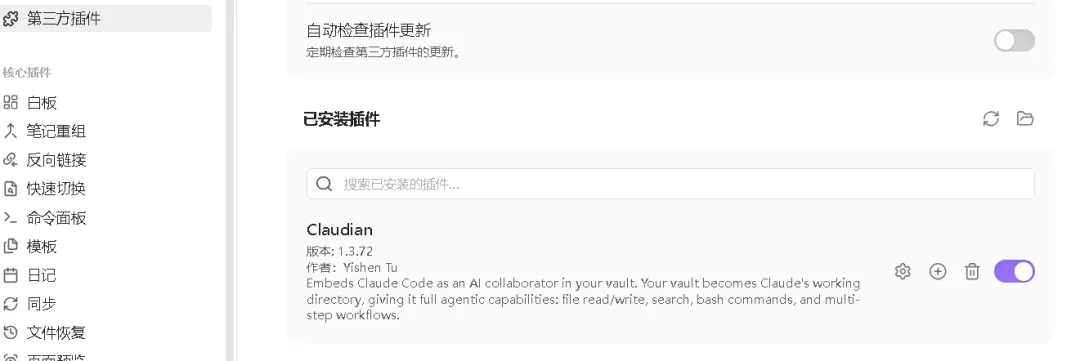
若没有自动弹出,可手工进入“设置 -> 第三方插件”开启。
第五步:初始化知识库结构
左侧可以看到机器人图标,点击 🤖,右侧会出现 Claudian 对话框。
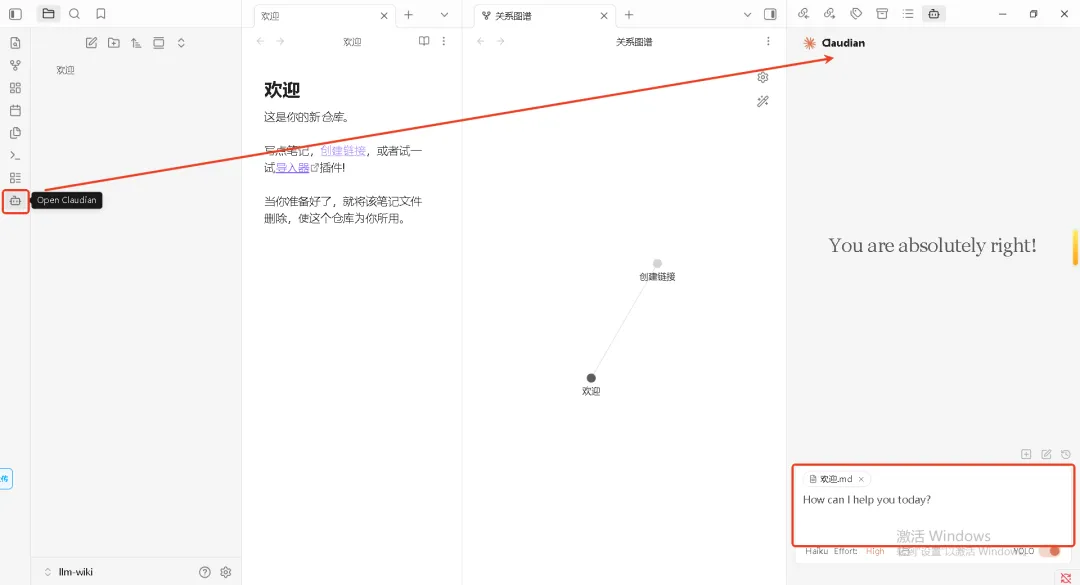
在对话框输入:
请学习 Andrej Karpathy 的思路:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f帮我搭建知识库,可按以下目录创建:llm-wiki/├── CLAUDE.md ← 架构配置 + Agent 规范(Schema 层核心)├── index.md ← 全局导航索引├── log.md ← 操作日志(记录所有 ingest/query/lint)├── raw/ ← 原始来源目录├── wiki/ ← 结构化知识目录└── outputs/ ← 导出目录
执行完成后,目录生成成功,并创建好了 CLAUDE.md:
五、跑通第一轮知识沉淀
知识库创建成功后,先不要急着连续提问,建议先完整跑通一次资料摄入流程。这里用 deepseek-v4.pdf 做最小实战。
第一步:放入原始资料
把文件放到 raw/inbox/ 目录:
raw/inbox/deepseek-v4.pdf原则:raw/ 只读,不直接修改,后续整理都写入 wiki/。
第二步:给 Claudian 下 Ingest 指令
在 Obsidian 的 Claudian 对话框输入:
请按 CLAUDE.md 规则处理这份资料:raw/inbox/deepseek-v4.pdf要求:1)在 wiki/sources/ 新建 deepseek-v4 摘要页(核心观点 / 关键术语 / 能力边界 / 风险点)2)更新 wiki/index.md(加入该资料入口与关联主题)3)新增或更新至少 2 个相关页面(如 wiki/concepts/、wiki/entities/),并加入双向链接4)在 log.md 追加一条 ingest 记录(日期 + 资料名 + 变更文件列表)5)所有结论尽量附来源定位(页码或原文片段)
第三步:人工做 3 分钟验收
重点检查四件事:
-
wiki/sources/是否生成资料摘要页; -
wiki/index.md是否新增可导航入口; -
相关 concept/entity 页面是否出现双向链接; -
log.md是否记录本次变更与时间。
如果以上四项都满足,说明你的“知识摄入流水线”已跑通。
第四步:立刻做一次 Query 验证复用
继续提问,验证沉淀是否可复用:
基于当前 wiki 回答:deepseek-v4 的核心创新点是什么?与常见大模型方案相比的优势与边界是什么?要求:1)先列出读取的 wiki 页面2)回答按“创新点 / 优势 / 边界 / 实践建议”结构输出3)引用对应 wiki 页面路径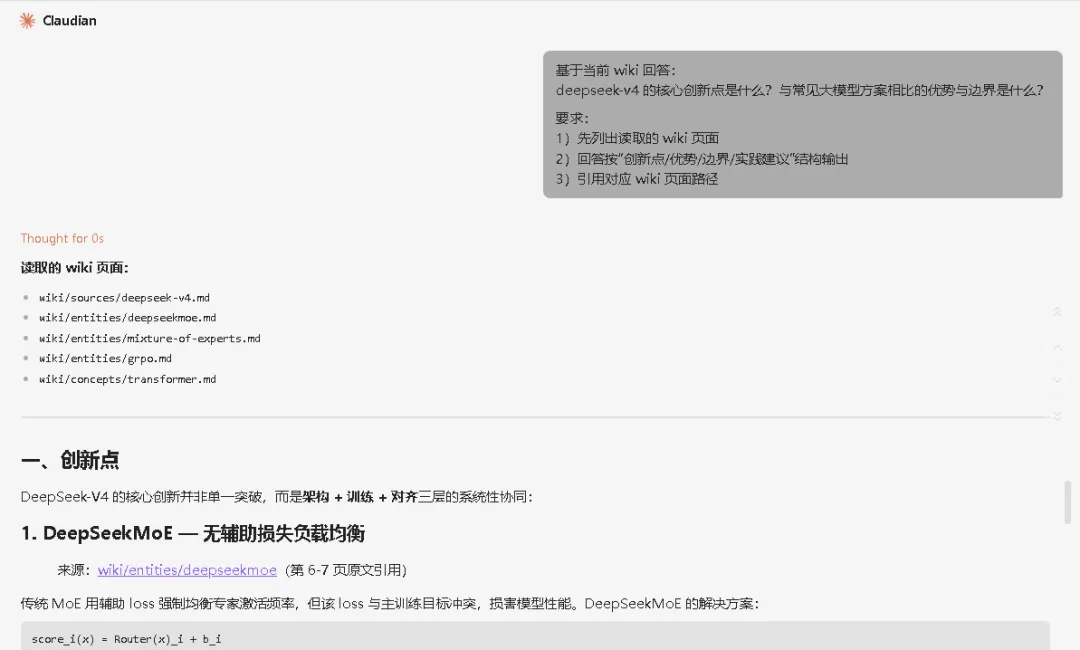
当你能稳定完成“摄入 -> 沉淀 -> 复用”,知识库就开始进入复利状态。
结语
这次 Karpathy 开源的价值,不只是一个“提示词模板”。
它真正给行业的启发是:LLM 不只是回答问题的工具,还可以成为知识系统的维护引擎。
当“维护成本”被大幅压低,个人和团队终于有机会真正拥有一个长期可生长的知识库。
这可能才是 AI 时代知识管理最值得关注的方向之一。