夜雨聆风
夜雨聆风





NPU: 端测AI系统AMD AIE(AI Engine)架构全解析及完整软件生态
AMD · XDNA · AIE · 2026
从硬件 tile 微架构到完整软件生态栈——深度解析 XDNA/XDNA 2 的设计哲学与开发工具链
目录
- 1. 背景溯源:从 Xilinx 到 XDNA
- 2. AIE 硬件架构:Tile 阵列与微架构
- 3. 代际演进与 TOPS 性能
- 4. 完整软件生态栈
- 5. 底层编程:MLIR-AIE / IRON / Peano
- 6. 高层部署:Ryzen AI 软件平台
- 7. LLM 推理专项流程
- 8. 驱动层:xdna-driver 架构
- 9. 生态现状与挑战
1. 背景溯源:从 Xilinx 到 XDNA
技术渊源
AMD 于 2022 年完成对 Xilinx 的收购,将其 Versal 自适应 SoC 中成熟的 AI Engine(AIE)IP 引入 x86 PC 处理器生态。XDNA 即 AMD 基于此 IP 重新设计并集成的 NPU 微架构品牌。
定位
XDNA NPU 是 Ryzen AI 芯片内专用 AI 推理单元,与 Zen CPU 核和 RDNA GPU 共存于同一 die 上,专门处理 AI 推理模型,承担 Windows Studio Effects、LLM 推理等任务,从而释放 CPU/GPU 资源。
- • 首发时间:2023 年 5 月
- • 行业地位:首个 x86 Windows 处理器上的专用 AI 引擎
关键区别:与 GPU 的 SIMT 大规模线程并发模型不同,AIE 采用**空间数据流(Spatial Dataflow)**架构——数据在固定拓扑的 tile 网格中流动,延迟完全确定,无调度开销,特别适合推理场景下的低延迟、低功耗需求。
2. AIE 硬件架构:Tile 阵列与微架构
XDNA NPU 的核心是一个二维可扩展 tile 阵列。不同型号通过配置 tile 数量来匹配功耗与性能目标。
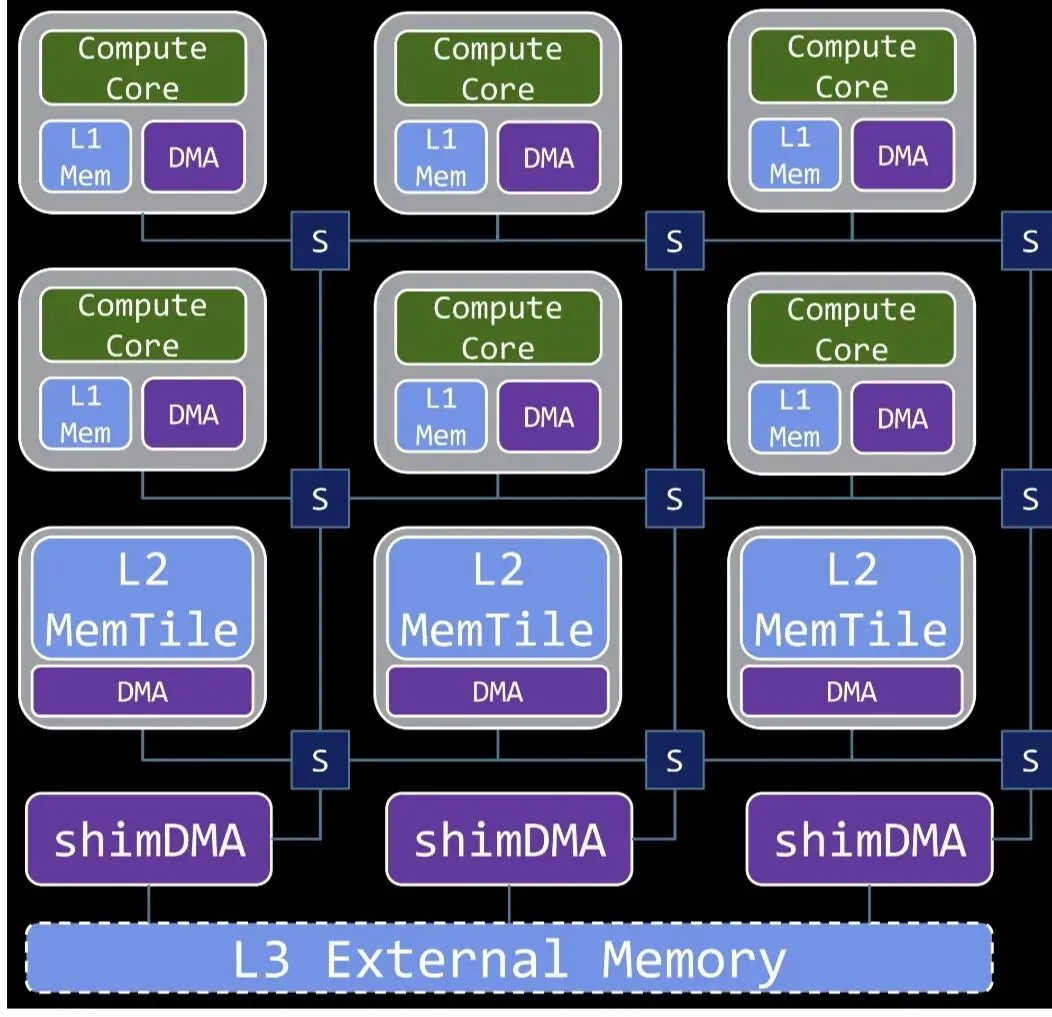
XDNA 2 Tile 阵列(32 AI Engine Tiles)
┌──────────┬──────────┬──────────┬──────────┐
│ AIE Core │ AIE Core │ AIE Core │ AIE Core │ ← 计算 Tile(VLIW+SIMD)
│ #0 │ #1 │ #2 │ #3 │
├──────────┼──────────┼──────────┼──────────┤
│ AIE Core │ AIE Core │ AIE Core │ AIE Core │
│ #4 │ #5 │ #6 │ #7 │
├──────────┼──────────┼──────────┼──────────┤
│ Mem Tile │ Mem Tile │ Mem Tile │ Mem Tile │ ← 内存 Tile(本地 SRAM)
│ A │ B │ C │ D │
├──────────┼──────────┼──────────┼──────────┤
│ AIE Core │ AIE Core │ AIE Core │ AIE Core │
│ #8 │ #9 │ #10 │ #11 │
├──────────┼──────────┼──────────┼──────────┤
│ Shim DMA │ Shim DMA │ Shim DMA │ Shim DMA │ ← Shim Tile(DMA/主机接口)
│ 0 │ 1 │ 2 │ 3 │
└──────────┴──────────┴──────────┴──────────┘计算 Tile 内部结构
| 组件 | 说明 |
|---|---|
| VLIW + SIMD 向量处理器 | 针对矩阵乘法、卷积等高吞吐量 ML 算子优化 |
| 标量 RISC 控制处理器 | 负责指令序列与控制流管理 |
| 片上 SRAM | 存储权重/激活值,减少外部 DRAM 访问 |
| 程序存储器 | 进一步降低延迟与功耗 |
互联与数据移动
- • Stream Switch:可配置流开关,路由 tile 间数据
- • DMA 引擎:可编程 DMA,确定性高带宽传输
- • NoC(片上网络):XDNA 2 内嵌 NoC 互联
- • 确定性延迟:空间数据流保证推理时序完全可预测
XDNA 2 核心增强
- • 向量宽度翻倍/4 倍,支持更大 micro-kernel tile 尺寸
- • 片上内存增加 60%(相比 XDNA 1)
- • 新增 Block Float 16(BF16) 支持
- • INT8 理论峰值达 165+ TOPS(Ryzen AI Max+)
空间数据流 vs GPU SIMT
| AIE 空间数据流 | GPU SIMT | |
|---|---|---|
| 调度方式 | 静态拓扑,DMA 驱动 | 动态线程调度 |
| 延迟特性 | 确定性,可预测 | 不确定,受调度影响 |
| 适用场景 | 低延迟推理,边缘 AI | 高吞吐量训练/推理 |
| 功效比 | 优秀 | 一般(适合大规模并行) |
3. 代际演进与 TOPS 性能
| 代际 | 产品平台 | AIE Tiles | 精度支持 | NPU TOPS | 发布时间 |
|---|---|---|---|---|---|
| XDNA 1 | Ryzen 7040 “Phoenix” | ~20 | INT8 | ~10 TOPS | 2023 |
| XDNA 1.x | Ryzen 8040 “Hawk Point” | ~20 | INT8 | ~16 TOPS | 2024 Q1 |
| XDNA 2 | Ryzen AI 300 “Strix Point” | 32 | INT8 / BF16 | 50–55 TOPS | 2024 Q3 |
| XDNA 2 | Ryzen AI 400(CES 2026) | 32 | INT8 / BF16 | 60 TOPS | 2026 Q1 |
| XDNA 2 | Ryzen AI Max+ 395 “Strix Halo” | 32+ | INT8 / BF16 | 50 TOPS NPU | 2025 |
注:TOPS 为理论峰值。AMD Ryzen AI 400 的实测 AI 推理性能较 Intel Core Ultra 9 288V 快约 7–8%,尽管后者 NPU 原始 TOPS 更高,说明架构效率与软件优化同样关键。NPU 相比 CPU 核的 AI 推理性能功效比约为 35x。
4. 完整软件生态栈
AMD AIE 软件生态分为两大通道:高层推理部署通道(面向应用开发者)和底层研究开发通道(面向性能工程师与编译器研究者)。
软件栈全景(自顶向下)
┌─────────────────────────────────────────────────────────┐
│ 应用层 │
│ PyTorch / TensorFlow / ONNX 模型 · Hugging Face │
│ 无需修改训练流程 │
├─────────────────────────────────────────────────────────┤
│ 量化层 │
│ AMD Quark · Vitis AI Quantizer · Microsoft Olive │
│ FP32 → INT8 / BF16 PTQ/QAT │
├─────────────────────────────────────────────────────────┤
│ 推理运行时 │
│ ONNX Runtime + Vitis AI EP · OnnxRuntime GenAI │
│ llama.cpp · Windows ML │
│ 自动图分区:NPU + CPU 协同 │
├─────────────────────────────────────────────────────────┤
│ 编译器层 │
│ Vitis AI Compiler · MLIR-AIE · LLVM-AIE (Peano) │
│ Triton-XDNA │
│ 图编译 → xclbin · 算子融合/向量化 │
├─────────────────────────────────────────────────────────┤
│ XRT 运行时 │
│ Xilinx Runtime (XRT) · XDNA SHIM Plugin │
│ xrt::device / xrt::kernel / xrt::bo │
│ 平台无关 API · xclbin 加载执行 │
├─────────────────────────────────────────────────────────┤
│ 内核驱动 │
│ amdxdna.ko (DRM Accel) · GEM 内存管理 │
│ Mailbox 固件通信 · Linux / Windows │
│ NPU1–6 多代支持 │
├─────────────────────────────────────────────────────────┤
│ NPU 固件 + 硬件 │
│ npu.sbin / npu.dev.sbin · AIE2 / AIE4 / VE2 │
│ Phoenix / Strix / Krackan / Strix Halo │
└─────────────────────────────────────────────────────────┘关键设计:Vitis AI Execution Provider 会自动对 ONNX 模型进行图分区(Graph Partitioning)——将 NPU 可高效执行的子图卸载到 NPU,其余算子在 CPU 上执行,整个过程对应用完全透明。
5. 底层编程:MLIR-AIE / IRON / Peano
面向性能工程师和编译器研究者,AMD 提供开源的底层编程工具链,允许直接控制 AIE 阵列的 tile 分配、数据移动和内存管理。
MLIR-AIE
基于 LLVM MLIR 的开源编译工具链,提供多层次中间表示(IR)以针对 AIE 设备。支持 Ryzen AI NPU 和 Versal 自适应 SoC。
- • 仓库:
github.com/Xilinx/mlir-aie - • 提供多级抽象,从 Python API 到低层 MLIR 表示
IRON API
MLIR-AIE 之上的 Python 接口,全称 Interface Representation for hands-ON AIE programming,面向需要精细控制 NPU 的工程师,支持计算 tile、内存分区、数据移动的显式管理。
编译流程
IRON Python
↓
MLIR AIE 方言
↓
MLIR-AIR(可选高层入口)
↓
LLVM-AIE / Peano
↓
aie.xclbin(设备二进制)Triton-XDNA 通过 triton-shared → Linalg → MLIR Transform dialect → MLIR-AIR/AIE,实现从标准 Triton kernel 到 XRT 兼容二进制的端到端编译。

Peano(LLVM-AIE)
LLVM 的 AIE 后端扩展,将 AIE 处理器添加为目标架构,使 clang 等编译器前端可以为 AIE 核生成代码。开发者可用 C++ 向量内联函数(Intrinsics)编写单核代码。
AIE API 头文件库
C++ 向量内联函数库,封装了 AIE 核的基础类型(向量、累加器)、算术操作、内存访问、矩阵乘法、FFT 等专用函数,供 Peano 编译。
IRON Python API 示例(矩阵乘法 tile 分配)
# IRON close-to-metal NPU 编程示例
from aie.iron import Kernel, ObjectFifo, Program, Runtime
from aie.iron.device import NPU1Col1
# 定义计算核函数(C++ 编译后链接)
matmul_fn = Kernel(
"matmul_int8",
"matmul.cc.o",
[T.memref(64, 64, T.i8()), T.memref(64, 64, T.i8()),
T.memref(64, 64, T.i32())]
)
# 定义 ObjectFifo:tile 间数据流通道
of_in_A = ObjectFifo("inA", shim_tile, compute_tile, 2, T.memref(64, 64, T.i8()))
of_in_B = ObjectFifo("inB", shim_tile, compute_tile, 2, T.memref(64, 64, T.i8()))
of_out_C = ObjectFifo("outC", compute_tile, shim_tile, 2, T.memref(64, 64, T.i32()))
# 双缓冲最小化内存延迟,DMA 自动调度数据移动6. 高层部署:Ryzen AI 软件平台
面向应用开发者,AMD 提供无需了解底层 tile 细节的高级部署流程,从预训练模型到 NPU 推理只需三步。
三步部署流程
① 准备模型
PyTorch / TensorFlow 预训练模型,转换为 ONNX 格式,无需修改训练流程。
② 量化
使用 AMD Quark 或 Vitis AI Quantizer 进行 PTQ(训练后量化),将模型从 FP32 量化为 INT8 或 BF16。
- • AMD Quark:推荐工具,支持 PyTorch 和 ONNX,提供 XINT8(对称 INT8 + Min-MSE 校准)、A8W8、A16W8 等量化配置
- • Vitis AI Quantizer:针对 ONNX 的量化工具,提供 PTQ 流程
- • Microsoft Olive:第三方量化工具,支持 QDQ 操作也可使用
③ 部署
通过 ONNX Runtime + Vitis AI EP 部署。首次运行编译模型并缓存,后续加载预编译二进制秒级启动。
ONNX Runtime + Vitis AI EP 部署示例
import onnxruntime
from pathlib import Path
# 配置 Vitis AI Execution Provider
vai_ep_options = {
'cache_dir': str(Path(__file__).parent.resolve()),
'cache_key': 'compiled_resnet50_int8',
'enable_cache_file_io_in_mem': 0,
'target': 'X2' # STX/KRK (Strix/Krackan) NPU
}
# 创建推理 session,VAI EP 自动完成图分区
session = onnxruntime.InferenceSession(
"resnet50_int8.onnx",
providers=['VitisAIExecutionProvider'],
provider_options=[vai_ep_options]
)
# 首次运行:编译 → 缓存 xclbin;后续:直接加载缓存
outputs = session.run(None, {'input': input_data})Lemonade SDK
多厂商开源 LLM 服务工具,集成于 Ryzen AI 软件栈,支持 OGA 和 llama.cpp 后端,提供 Python API 和 REST Server 接口,用于快速上手 LLM 在 NPU 上的部署。
7. LLM 推理专项流程
Ryzen AI 1.7.1 软件栈为 LLM 推理提供三种开发接口,均基于 OGA(OnnxRuntime GenAI)或 llama.cpp 构建。
三种开发接口
| 接口 | 说明 | 适用场景 |
|---|---|---|
| Lemonade Python API | 最简单的上手方式,几行代码即可在 NPU 上运行 LLM | 快速原型验证 |
| Lemonade Server(REST) | REST API 服务器,与 OpenAI API 兼容 | 集成到现有应用 |
| OGA C++ Headers | 通过 OnnxRuntime GenAI C++ API 或 llama.cpp 直接调用 | 原生应用开发 |
Hybrid CPU + NPU 推理
LLM 推理通常采用 CPU + NPU 混合执行策略:
- • Prefill 阶段(计算密集型,长上下文处理):可在 CPU 或 iGPU 上执行
- • Decode 阶段(带宽敏感型,逐 token 生成):利用 NPU 低功耗优势
Vitis AI EP 的图分区机制自动处理这一拆分。
支持的模型类型
- • Whisper、Zipformer(语音转文字)
- • Stable Diffusion 1.5 / 2.1 / XL / 3.0(图像生成)
- • Compact LLMs(小型语言模型)
- • Vision Transformers(视觉 Transformer)
- • CNNs(卷积神经网络)
8. 驱动层:xdna-driver 架构
xdna-driver 开源仓库包含内核模块、XRT SHIM 库、固件二进制和完整构建系统,支持 NPU1–6 多代硬件。
内核驱动(amdxdna.ko)
基于 DRM Accel 框架的内核模块,通过 amdxdna_dev_ops 函数指针抽象层同时支持多代架构(AIE2 / AIE4 / VE2)。
- • GEM 内存管理:管理设备内存分配
- • HMM 集成:
mmu_interval_notifier追踪用户内存失效 - • 多架构支持:AIE2(PCIe)、VE2(OpenFirmware/Device Tree)
固件通信(Mailbox 子系统)
驱动与 NPU 固件之间通过环形缓冲区(Ring Buffer)Mailbox 子系统进行双向通信,支持电源模式管理:
DEFAULT → LOW → MEDIUM → HIGH → TURBO支持的 NPU 设备
| 设备 | 平台 | PCI Device ID |
|---|---|---|
| NPU1 | Phoenix | 0x1502 |
| NPU3 | Strix | 0x17f1 / f2 / f3 |
| NPU4/5/6 | Strix Point / Krackan / Halo | 0x17f0 |
| VE2 | 嵌入式平台 | OpenFirmware/DT |
Linux 内核集成状态
amdxdna 驱动已通过 CONFIG_DRM_ACCEL_AMDXDNA 进入主线 Linux 内核。固件文件位于 /lib/firmware/amdnpu/,可通过 linux-firmware 包安装。
注:主线内核附带的固件与最新 MLIR-AIE 栈存在兼容性问题,开发者若需使用最新 AIE 栈,建议使用
xdna-driver仓库附带的开发版固件(npu.dev.sbin)。
9. 生态现状与挑战
✅ 优势
- • 空间数据流架构,确定性延迟,功效比优秀(AI 推理约为 CPU 核的 35x)
- • MLIR-AIE / IRON 开源工具链,社区持续活跃
- • XDNA 驱动已进入 Linux 内核主线
- • Windows ML / Copilot+ PC 生态深度整合
- • Triton-XDNA 降低高性能核编写门槛
- • XRT 统一运行时,跨 Versal / Ryzen AI 可移植
- • 60 TOPS 超过 Microsoft 40 TOPS Copilot+ 认证要求
- • BF16 精度原生支持,利好 LLM 推理场景
△ 挑战
- • NPU 编程生态仍比 CUDA 碎片化,代码样例少,专用 API 门槛高
- • Vitis AI EP 部分开源代码不完整(历史遗留问题)
- • 向量化内核覆盖率仍低,均值约 10%
- • 编译耗时较长(首次推理需分钟级编译)
- • 跨 NPU 代际移植需要硬件针对性调优
- • Linux 上最新 AIE 栈需要替换主线固件
- • TOPS 理论值与实际性能差距较大
开源资源导航
| 资源 | 说明 |
|---|---|
| github.com/Xilinx/mlir-aie | MLIR-AIE / IRON 工具链 |
| github.com/amd/xdna-driver | 内核驱动(开源) |
| github.com/amd/Triton-XDNA | Triton 前端编译器 |
| ryzenai.docs.amd.com | Ryzen AI 官方文档 |
| github.com/amd/RyzenAI-SW | 示例代码与参考实现 |
发展方向
AMD 正推动 AIE 生态向更开放方向发展:
- • Triton-XDNA 降低高性能内核开发门槛,对 INT8/BF16 矩阵乘法性能已达手写实现水平
- • NPUEval 基准测试集(102 个算子)推动编译器代码生成标准化
- • LLM 驱动的自动内核生成通过迭代编译反馈,功能通过率从 29% 提升至 71%,正成为重要研究方向
AMD AIE Architecture Reference · 基于公开技术文档整理 · 2026
XDNA™ MLIR-AIE IRON XRT Vitis AI Ryzen AI 为 AMD 及相关方商标