 夜雨聆风
夜雨聆风





OpenClaw 能成为我的个人 AI 助手吗?从 Agent 架构说起
当我书写的时候,我感到平静。
概述
很久没写文章了,其实上上上周写过一篇年度总结,但是当我自己去阅读的时候,我认为这篇年度总结的文风始终不太流畅,索性就不发了。从春节开始到三月份,”养龙虾”这个词开始在技术圈里面频繁出现,这里的”龙虾”指的是OpenClaw,一个号称运行在个人设备上的AI assistant。
我到现在还没有动手去碰龙虾,因为我更关心一个问题: “它到底能帮我做什么”? 带着好奇心,我开始在搜索引擎上去搜索龙虾,也就是openclaw。
在github上看到了这个软件的自我描述: OpenClaw is a personal AI assistant you run on your own devices。 也就是说OpenClaw是一个个人AI助手,助手是什么呢? 在我的想法里面就是帮我做一些日常工作,比如订车票、在盒马上选购商品、在外卖软件上选外卖,在淘宝上帮我购物、当我到达某个地点之后帮我打卡,这好像是我需要一个助手来帮我做的事情。
如果OpenClaw要完成这些任务,它必须要获得某种”可执行通道”,这个通道可能是平台开放API,也可能是浏览器自动化、移动端自动化、插件、或者是其他形式的工具调用。对于订票、购物、支付这类涉及个人账号和资金安全的场景,它还必须处理授权、风控和二次确认问题。我的初步猜想是OpenClaw是通过API来完成这些操作的,因此我让我GPT-2-Image画出了下面的架构图,注意目前只是我的猜想,不代表OpenClaw的真实实现。
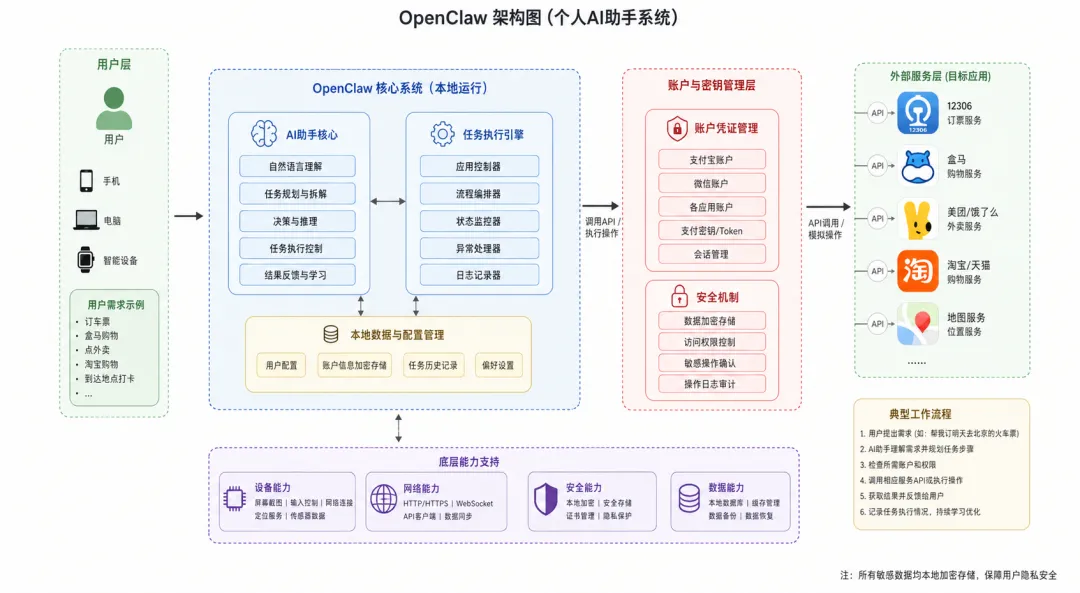
图 1:我最初想象中的 OpenClaw 个人助手架构。该图用于辅助理解,不代表官方实现。
我想最基础的能力总是系统对外暴露的API能力,以前是用户在app通过点击滑动来完成操作,这些操作会让APP调用api来完成对应的服务,现在这个过程变成了你在聊天软件发出自然指令,然后OpenClaw来完成对应api的调用。
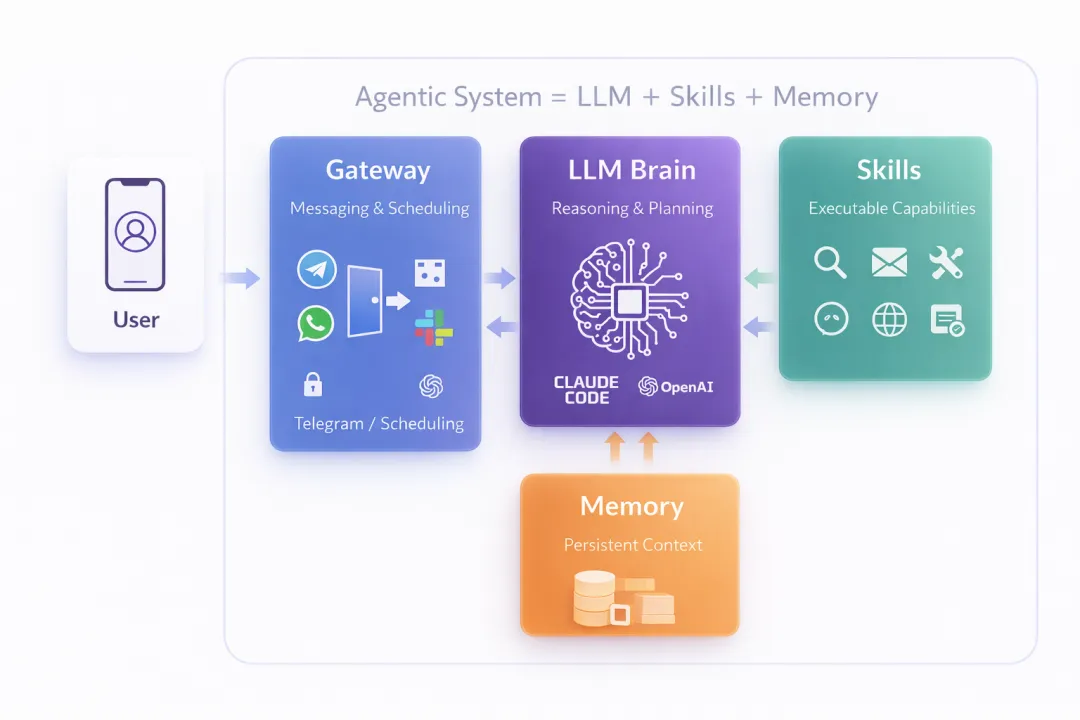
于是带着我的疑问,我打开了OpenClaw的官网,在官网找到了一份OpenClaw的架构图, 这个架构图原本是视频里面出来的,但是后面呢,在官网找不到了。从视频里面截的图比较丑,只能是用GPT-Image-2进行还原, 还原的倒是更漂亮了一些。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果把OpenClaw看成一个个人助手系统,那么Gateway 负责接收请求,Agent负责理解和调度,memory负责保存上下文,Skill负责执行具体的动作。真正能不能完成任务,则取决于Skills背后是否有可用的API、工具或自动化能力。
什么是agent?
agent意为: a person who acts for or represents another. 代表他人行事的人,也就是代理。但显然代理这个词在OpenClaw的语境下有不同的含义, 这里加上了AI , 所以就是AI agent对应的应该是智能体这个概念。我们先不讲agent应该满足哪些特点。我们观察经典的AI agent 在这些例子里面,来推导agent 应当具备什么样的特点。
agent 预设了上下文
一个典型的例子是coding agent,coding agent的特点是你输入自然语言,然后agent会将其转换为对应的代码。举一个很简单的例子,我们打开codex,输入这样一句话:”请帮我写一个hello world”,然后codex的反应是:
最简单的 Python 版:
print(“Hello, world!”)
如果你要 C、JavaScript、Java 或 C++ 版本,我也可以直接写给你
这也就是说在codex这里默认将我们输入的话都当做和代码相关,因为就请帮我写一个hello world 这句话来说,是充满歧义的。是用什么写,文字还是代码? 当我们在对话的时候,其实默认包含了上下文信息,这对于模型来说是不清晰的。 所以我们可以认定codex预设了上下文信息,当前处于编程的语境中,输入的指令中的写,其实的语义是用编程语言去输出,又因为我们没有指定编程语言,所以codex选择了最常见的python去书写。
所以AI agent 的第一个特点是有默认的预设工作语境,codex的工作语境是编写代码。如果我们在网页中找一个大模型输入:”请帮我写一个hello world”, 这句话。我猜想网页端的大模型会让我们明确写是什么意思,又或者是在它的语料库里面写hello world 关联的语料都是编程代码相关的,我们可以认为网页端的大模型也会认为这是和编程相关,只是会让我们明确语言,或者不折不扣的执行我们的指令,只是说如果想指定语言请明确。
测试了GPT-5.4 和 Kimi-2.5 都是用编程语言来写hello world,Hello world 在很多互联网的资料里面都高度和编程相关,我们不妨换一个提示词,这里我们切换为,你好请帮我写一个good morning,我想这句话并没有相关的语料,于是推测大模型会让我们明确方向,还是什么? 因为写这个动作是不明确的。果然我们切换了提示词,GPT-5.4就是向我们输出了Good morning,写在这里被模型定义为输出good morning 这个字符。
但如果我们预设值提示词,你是一个编程助手,后面任何的输入,要向着编程这个方向去匹配,会怎么样呢? 我预测会将用编程语言去实现,也就是理解为在代码中输出它。在GPT 5.4中也确实如我预测这样。
所以到这里总结一下,agent的第一层能力不是调用工具,而是知道自己”应该在什么情境下理解问题”。
agent 具备执行能力
在上面的观察中,我们观察到agent首先被预设了上下文信息,也就是明确了角色,它应该做什么。我们不妨接着思考,仅仅是明确角色和上下文是不够的。以codex为例,我们输入帮我们写一个贪吃蛇,那么codex就会帮我们写一个贪吃蛇游戏,这也就意味着agent具备执行能力。所以推理和行动是agent具备的两个能力,推理是大模型的基本能力,那么行动呢? 我想应该是通过代码来执行。
我们不妨观察其他比较成熟的agent来判断我们的推测是否正确,这是我的第一个想法,但是成熟的agent人家未必愿意把自己的源码开源,再有就算是开源了,读起来也很复杂。那这里是不是换一个思路呢? 去看一些成熟的agent框架,比如langchain是怎么定义开发agent这件事的, 我们不仅要停留在自己的想象中,还需要在开发中体会agent这个概念。
来自langchain的示例
Hello World
from langchain.agents import create_agent# 语句块一:定义工具defget_weather(city: str) -> str:"""Get weather for a given city."""returnf"It's always sunny in {city}!"# 语句块二:创建 Agentagent = create_agent( model="openai:gpt-5.4", tools=[get_weather], system_prompt="You are a helpful assistant",)# 语句块三:调用 Agentresult = agent.invoke( {"messages": [ {"role": "user","content": "What's the weather in San Francisco?" } ] })print(result["messages"][-1].content_blocks)上面的代码定义了一个简单的agent,这个例子虽然简单但已经包含了Agent的基本结构。
-
语句块一 定义了一个普通Python函数get_weather。它并不查询真实天气,只是根据传入的城市返回固定字符串。
-
语句块二通过create_agent创建agent。这里的关键是把模型、工具列表和系统提示词组合起来。传入tools[get_weather]之后,Agent就知道自己在需要时调用这个函数。
-
语句三通过 agent.invoke发送用户问题。Agent会理解问题中的城市是San Francisco,判断这个问题需要get_weather,然后把工具执行结果组织成最终回答。
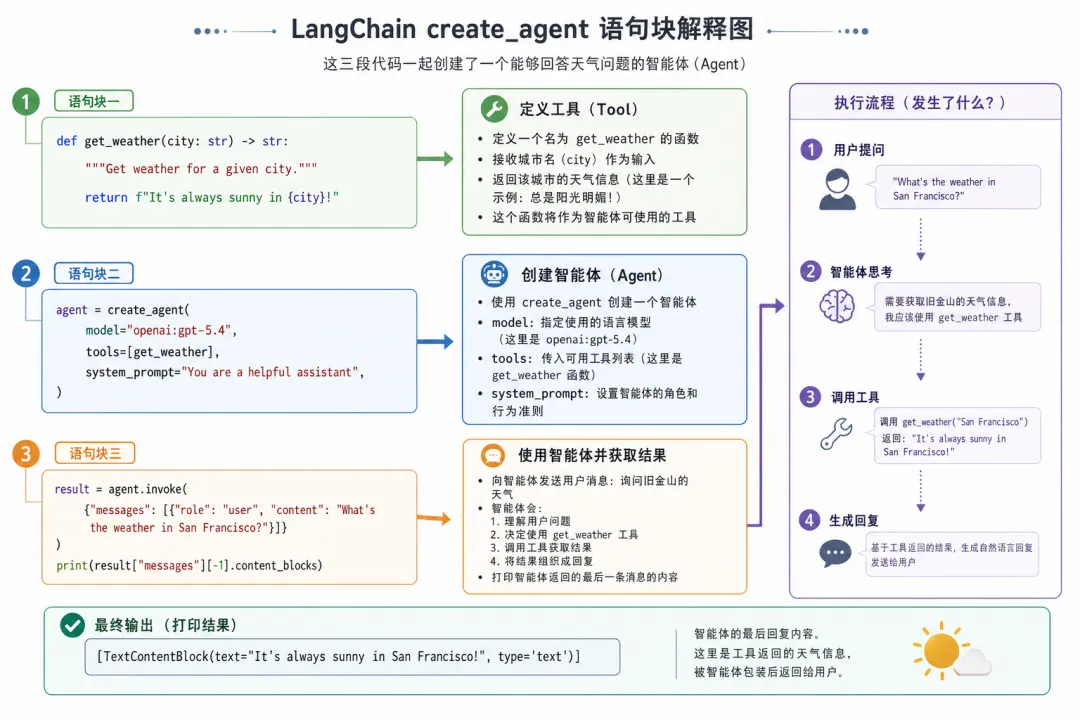
当我们向agent询问天气的时候,agent根据需求会调用工具,但是这个工具需要在特定的环境中执行,然后传递给大模型。 LangChain在这里承担的是Agent Runtime的角色:它负责把模型输出的工具调用意图,转换成真实的Python函数调用; 再把函数返回值包装成模型可以继续处理的消息。也就是说模型并不是真正自己执行了get_weather。模型只是决定”我需要调用get_weather”,参数是 San Francisco, 真正执行函数的是LangChain所在的Python运行环境。
这里我还尝试过一个 researcher agent,用工具读取 在线文本,再让模型统计行号和生成概要。这个例子更复杂,涉及工具调用、记忆和长文本处理,我会在后续文章单独展开。本文先只用它说明一点:Agent 的能力边界取决于它被提供了哪些工具。
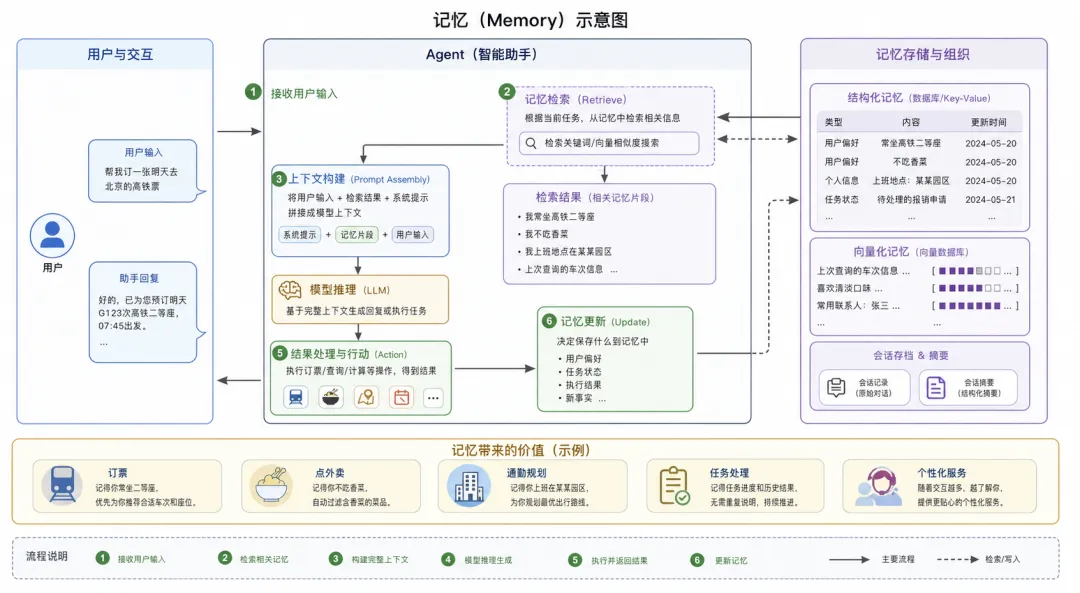
什么是Memory
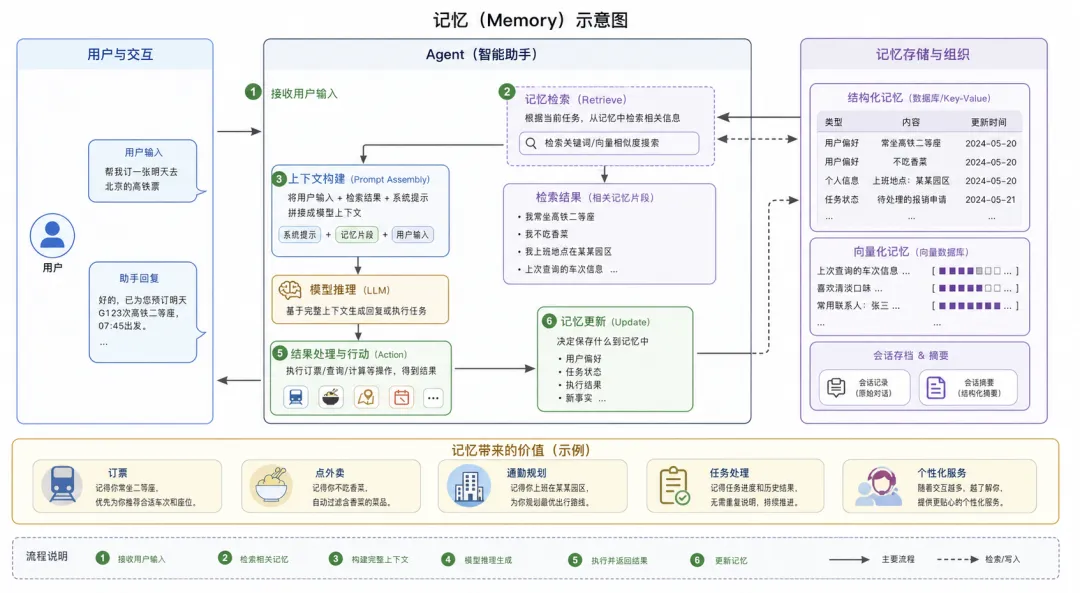
Memory可以理解为Agent的上下文存储。普通聊天模型只能看到当前上下文窗口里的内容,而带有Memory的系统可以把历史对话、用户偏好、任务状态或执行结果保存下来,在后续任务中重新使用。比如一个个人助手如果记得”我常做高铁二等座” 、”我不吃香菜”、”我上班地点在某某园区”, 它在订票、点外卖、规划通勤的时候就会像一个真正的助手。
为了实现这一点,Memory不能仅仅依赖于模型本身的上下文窗口。它通常依赖数据库、会话存档、摘要、向量检索等机制。系统决定要保存什么、什么时候检索、如何把检索到的信息重新注入给模型。
什么是skills?
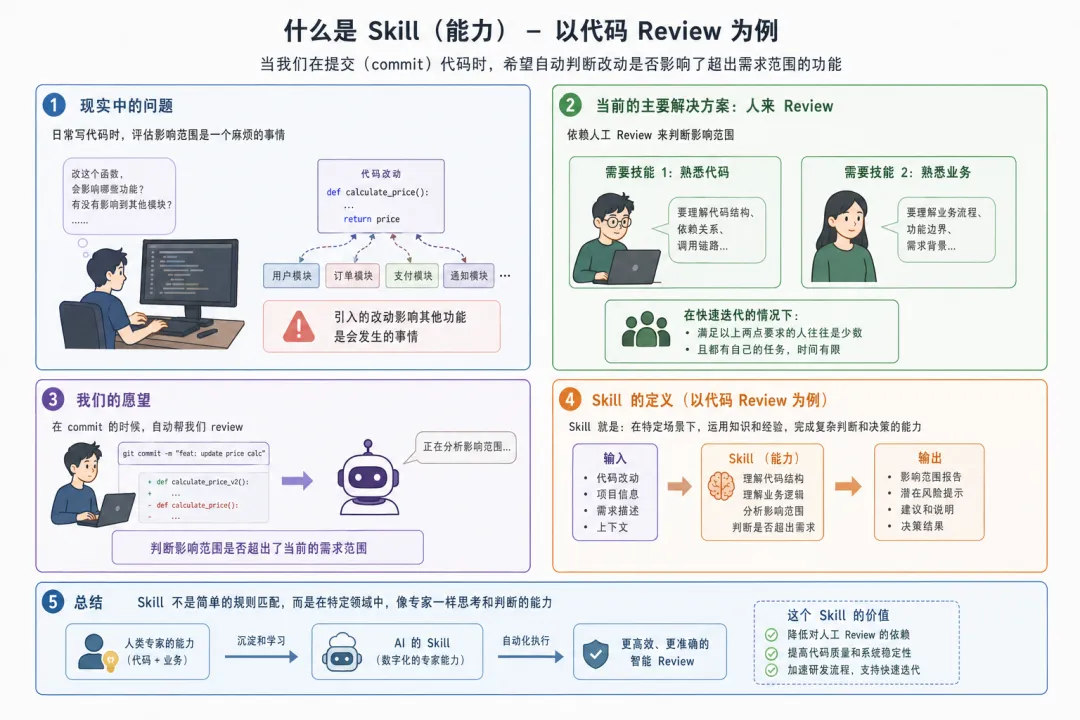
我们还是从具体例子里体会概念,而不是先拿着概念去套例子,这更符合我们的认知过程。日常写代码时,评估一次改动的影响范围,是一件很麻烦的事情。很多时候,一个需求表面上只是改一个字段、一个状态或一个判断条件,但它背后可能牵扯到多个入口、多个页面和多条调用链。
现在主要的解决方式还是靠人来 Review。但这对 Reviewer 的要求很高:一方面要熟悉代码结构、依赖关系和调用链路;另一方面还要熟悉业务流程、功能边界和需求背景。在快速迭代的情况下,同时满足这两个条件的人往往很少,而且这些人通常也有自己的开发任务。
所以我会希望有这样一种能力:当我提交 commit 的时候,系统能自动帮我分析这次改动,判断它是否影响了当前需求范围之外的功能,并给出风险提示。这其实就可以看作一个 Skill。以“代码 Review Skill”为例,它的输入可能包括:
-
本次代码 diff; -
commit message; -
当前需求描述; -
项目结构信息; -
相关历史提交; -
相关业务上下文。
它的执行过程可能包括:
-
读取本次代码改动; -
分析改动涉及的函数、文件和模块; -
检索相关调用链路; -
结合需求描述判断本次改动的预期范围; -
对比实际影响范围和需求范围; -
生成 Review 结论和风险提示。
它的输出则可能是:
-
本次改动影响了哪些模块; -
是否存在超出需求范围的影响; -
哪些地方需要人工重点关注; -
是否建议补充测试用例; -
最终是否建议通过。
如果只是临时让模型看一段 diff,然后给出几句建议,这更像一次普通的模型问答。但如果我们把上面这套流程固定下来,让它能够稳定读取 diff、检索代码、理解需求、分析调用链,并按照统一格式输出 Review 结果,那么它就不再只是一次临时问答,而是一个可复用的能力单元。这个能力单元,就可以称为 Skill。
因此,Skill 可以理解为 Agent 系统中对高频任务的封装。它通常不是模型内置的能力,而是由提示词、工具、参数、执行逻辑、上下文信息和返回格式等共同组成的外部能力模块。模型要做的,是在合适的上下文中识别并调用这个 Skill。
不同系统对 Tool 和 Skill 的定义并不完全一致。在 LangChain 中,更常见的说法是 Tool,也就是模型可以调用的函数或接口。在 OpenClaw 这类个人助手系统中,Skill 往往表示更高一层的能力封装。可以粗略地理解为:Tool 更原子,Skill 更面向任务。一个 Skill 内部可能包含一个或多个 Tool。
比如在代码 Review 这个例子中:
-
Tool:读取 diff、检索代码、查询调用链、运行测试、生成报告 -
Skill:完成一次代码 Review,并判断改动是否超出需求范围
所以,Skill 可以看作 Agent 连接现实世界的能力单元。模型负责理解用户要做什么,Skill 负责定义这件事如何被执行。
回到 OpenClaw,它能不能成为个人 AI 助手,很大程度上取决于它是否有足够丰富、稳定和安全的 Skills。没有 Skills,Agent 只能停留在理解和回答;有了 Skills,它才有机会真正替用户完成订票、购物、点外卖、代码 Review 这类现实任务。
这里我们不对 Skill 展开做过多介绍,后面可以专门开一篇文章讨论 Skill 的设计。本篇主要是从宏观上理解 OpenClaw 作为个人 Agentic System 的运行机制。
总结一下
经过上面的拆解,我对 OpenClaw 的理解是:它不是一个单纯的聊天机器人,而是一个试图把大模型、工具、记忆和外部服务连接起来的个人 智能体系统。
在这个系统里,Gateway 负责接收和转发用户请求,Agent 负责理解意图和调度任务,Memory 负责保存上下文、用户偏好和任务状态,Skills 则提供真正可执行的能力。真正能不能完成任务,既取决于模型基座是否足够强,也取决于 Skills 背后是否有可靠的 API、工具、自动化入口和授权机制。
尤其是订票、购物、点外卖、打卡这类现实任务,难点并不只是“模型能不能理解我说的话”,还包括外部平台是否开放接口、账号授权是否安全、自动化操作是否稳定,以及涉及支付和敏感操作时能否提供用户确认、权限控制和风控保护。
所以,我更倾向于把 OpenClaw 理解为这样一个系统:
OpenClaw = LLM + Gateway + Memory + Skills + 平台开放能力 + 自动化能力这里还需要注意,“Agent”不是一个严格统一的术语,在不同的产品里面有不同的定位和能力。
在 LangChain 的例子里,Agent 更像是一个被明确了角色、工具边界和执行方式的 LLM 系统。开发者通过模型、提示词、工具列表和执行循环组织起来的LLM系统。它的重点是:模型如何选择工具、调用工具,并整合结果。
而在 OpenClaw 这样的产品架构图里,Agent 更像系统中的任务处理模块。它不一定等同于裸 LLM,而是以 LLM 为核心,负责读取 Memory、理解用户意图、选择合适的 Skill、调用外部能力,并整合执行结果。
因此,当 OpenClaw 的架构图里同时出现 Agent、Skills 和 Memory 时,我的理解是:
-
Agent 负责决策和调度; -
Skills 提供可执行能力; -
Memory 提供状态和上下文; -
Gateway 负责接收和转发请求; -
LLM 是 Agent 内部用于理解、推理和生成的核心模型。
回到最开始的问题:OpenClaw 能不能成为我的个人 AI 助手?
我的答案是:OpenClaw 有成为个人 AI 助手的系统雏形,但它最终能不能成立,至少取决于三件事:模型基座是否可靠,Skills 体系是否完善,以及外部平台是否愿意暴露可调用的能力。
模型基座决定了它能不能理解用户真实意图,能不能处理模糊表达,能不能结合 Memory 做上下文判断,能不能把一个现实任务拆解成可执行步骤,并在执行过程中根据反馈调整策略。Skills 体系则决定了它能不能把这些理解和规划真正落到现实世界里。订票、购物、点外卖、打卡这些任务,最终都需要可靠的 API、工具、自动化入口、授权机制和安全确认。
平台开放能力决定了 Skill 在触发真实操作时,走的是不是平台认可的路径。API 本质上是一种契约:平台规定调用方式、权限边界和返回结果,外部系统按照这套规则调用,平台就提供相应能力。问题在于,平台未必愿意把所有能力都开放出来。一方面,开放 API 可能削弱平台客户端本身的流量入口;另一方面,账号、支付、风控和用户数据也会带来安全责任。
这也意味着,我前面设想的很多个人助手场景,在同一家公司或同一生态内部更容易成立。比如通过千问点外卖,本质上是因为饿了么和千问之间存在平台层面的信任和能力开放。
但如果一个个人助手并不是通过平台认可的 API 或授权机制来操作,而是绕过平台规则去模拟用户行为,那么它和平台之间的交互就会进入灰色地带。轻则操作不稳定,重则可能违反平台政策,带来账号限制甚至封号风险。
所以,OpenClaw 的关键不只是“模型有多聪明”,也不只是“Skills 有多少”,还在于外部平台是否愿意开放可调用的能力。
只有当模型能够可靠地理解和调度任务,平台愿意提供清晰的 API 或授权机制,Skills 又能在合法、稳定、安全的边界内连接真实服务时,OpenClaw 才真正接近一个能替我处理现实事务的个人 AI 助手。
参考资料
[1] OpenClaw的官方文档 https://docs.openclaw.ai/start/getting-started