 夜雨聆风
夜雨聆风





OpenAI、Anthropic 罕见同步更新提示词指南!你精心打磨的 prompt,可能已经变成「技术债」
OpenAI 和 Anthropic 几乎同一时间发布了各自最新模型的提示词最佳实践文档。两份指南指向同一个结论:过去那套靠堆流程、堆限制、堆补丁来”驯服”模型的 prompt 写法,正在迅速过时。一条在 X 上获得超 2.5 万次浏览的帖子把两家文档并排解读,瞬间点燃了开发者社区的焦虑。
一条推文,戳中了整个行业的痛点
4 月 30 日凌晨,X 用户 Alex Prompter 发了一条长帖,开头就是一句直击灵魂的话:
“Your old prompts don’t work anymore.”
「你的旧提示词不好使了。」
他把 OpenAI 刚发的 GPT-5.5 使用指南和 Anthropic 的 Claude Opus 4.7 最佳实践并排放在一起,得出了一个让人坐不住的观察——两家都在告诉开发者:别再照搬旧 prompt 了,但原因恰好相反。

▲ Alex Prompter 的帖子迅速获得 251 赞、435 收藏、超 2.5 万次浏览
这条帖子迅速在开发者圈子发酵。有人赞同,有人反对,但所有人都承认一件事:提示词的写法,确实在经历一场范式转换。
OpenAI 说得最直白:别把旧 prompt 搬过来
OpenAI 在 GPT-5.5 的官方文档里写了一段非常罕见的话。注意,这可不是某个博主的个人观点——就是官方开发者文档里的白纸黑字:
“To get the most out of GPT-5.5, treat it as a new model family to tune for, not a drop-in replacement for gpt-5.2 or gpt-5.4.”
「想要充分发挥 GPT-5.5 的能力,就要把它当成一个全新的模型家族来调,别当成 gpt-5.2 或 gpt-5.4 的无缝替换品。」

▲ OpenAI 开发者文档明确要求:把 GPT-5.5 当新模型重新调
后面还有一句更狠的:
“Begin migration with a fresh baseline instead of carrying over every instruction from an older prompt stack.”
「迁移时从全新 baseline 开始,别把旧 prompt stack 里的每条指令都原封不动搬过来。」
什么叫 fresh baseline?就是从零开始重写你的提示词。
而在另一份 GPT-5.5 Prompting Guide 里,OpenAI 直接解释了为什么旧 prompt 会”失灵”:
“Legacy prompts often over-specify the process because earlier models needed more help staying on track. With GPT-5.5, that can add noise, narrow the model’s search space, or lead to overly mechanical answers.”
「旧提示词往往把过程规定得过细——因为早期模型确实需要更多”扶着走”。但到了 GPT-5.5,这些过程指令反而会变成噪音,压缩模型的搜索空间,甚至让回答变得机械。」
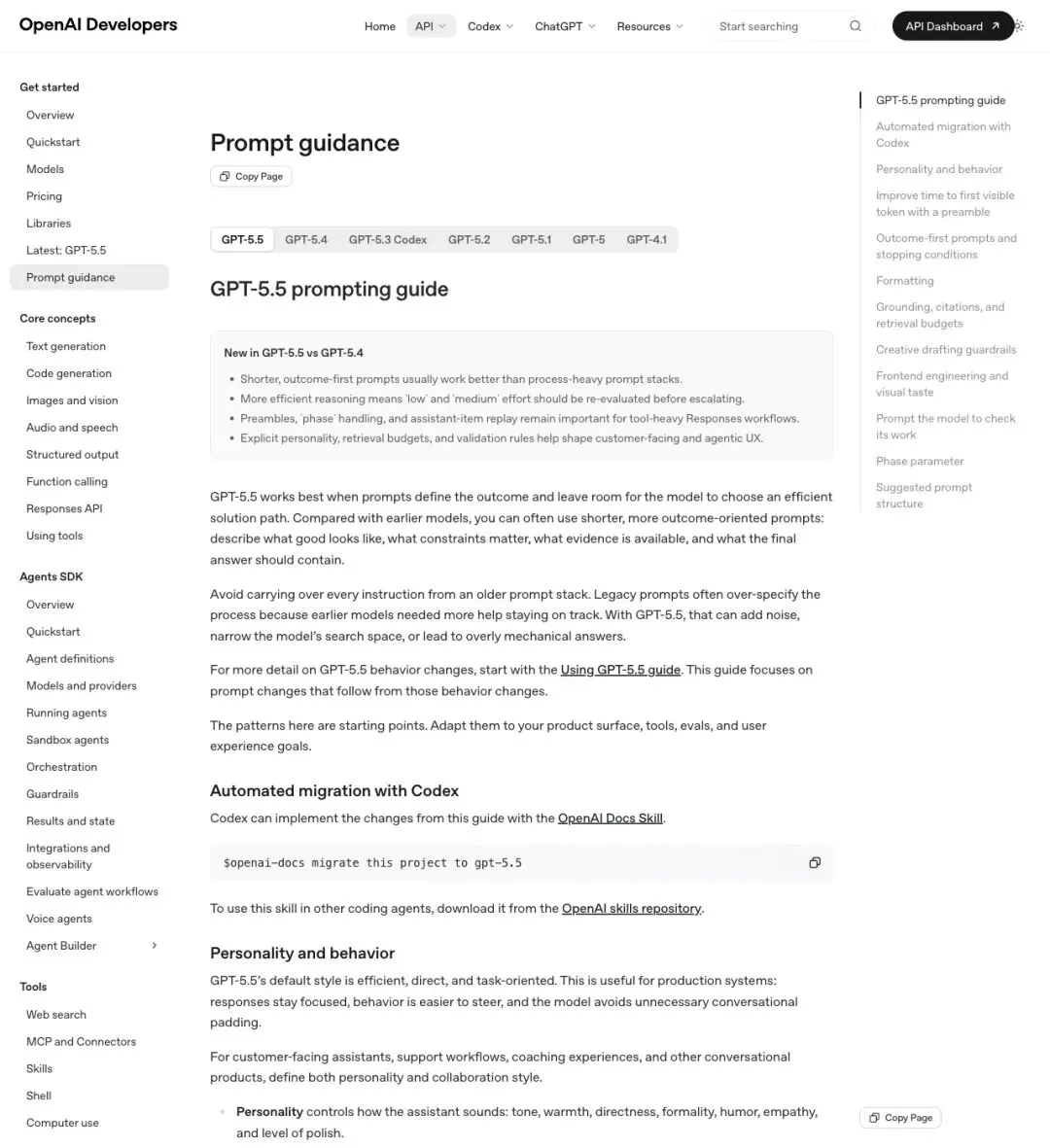
▲ OpenAI 新版 Prompt guidance:更短、以结果为先的 prompt 通常效果更好
换句话说:你以前为了防幻觉、防跑偏而写的那些”脚手架式”指令,在新模型眼里全变成了干扰。
OpenAI 给出的新方向只有一个词:outcome-first(结果优先)。
“Shorter, outcome-first prompts usually work better than process-heavy prompt stacks.”
「更短的、以结果为先的提示词,通常比那种流程很重的 prompt stack 更有效。」
Anthropic 这边:没那么激进,但同样在改规则
Anthropic 的表述比 OpenAI 克制得多,但方向是一致的。
在 Claude Opus 4.7 的 Prompting Best Practices 文档里,Anthropic 首先承认了一个关键事实:
“Claude Opus 4.7 performs well out of the box on existing Claude Opus 4.6 prompts.”
「Opus 4.7 在现有 4.6 prompt 上表现不错。」
但紧接着就是一个”但是”:
“The patterns below cover the behaviors that most often require tuning.”
「但下面这些行为,最常需要重新调整。」
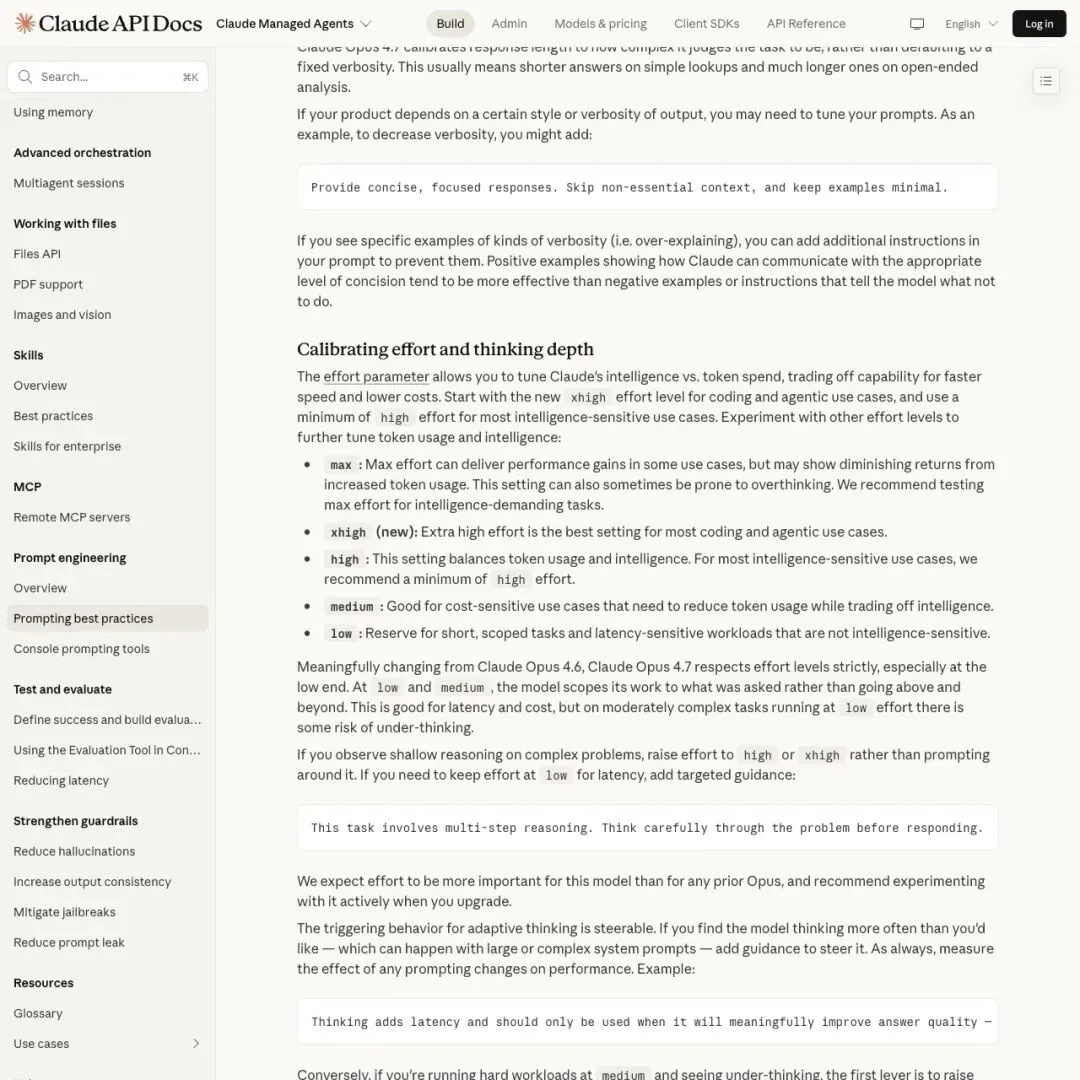
▲ Anthropic 文档:Opus 4.7 变化最大的是回答长度、思考深度和 effort 校准
变化最核心的一条:
“Claude Opus 4.7 calibrates response length to how complex it judges the task to be, rather than defaulting to a fixed verbosity.”
「Opus 4.7 会按它自己判断的任务复杂度来校准回答长度,不再默认固定的冗长程度。」
这意味着什么?过去你写”请详细回答”或者”至少 500 字”能管用的控制方式,现在可能完全不灵了。模型自己会决定该写多长。
如果你的产品依赖特定的输出风格或字数,Anthropic 的建议是:用正向示例去校准,告诉模型”应该怎么做”,而非堆一堆”不要这样做”的负向约束。
▲ Anthropic 强调:做 prompt engineering 之前,先定义 success criteria
另一个重大变化在于effort(思考深度)的校准逻辑。Opus 4.7 在低 effort 模式下会严格控制思考范围——如果你发现它”想得太浅”,Anthropic 的建议很直接:别硬堆更多提示词指令,直接调高 effort 参数。
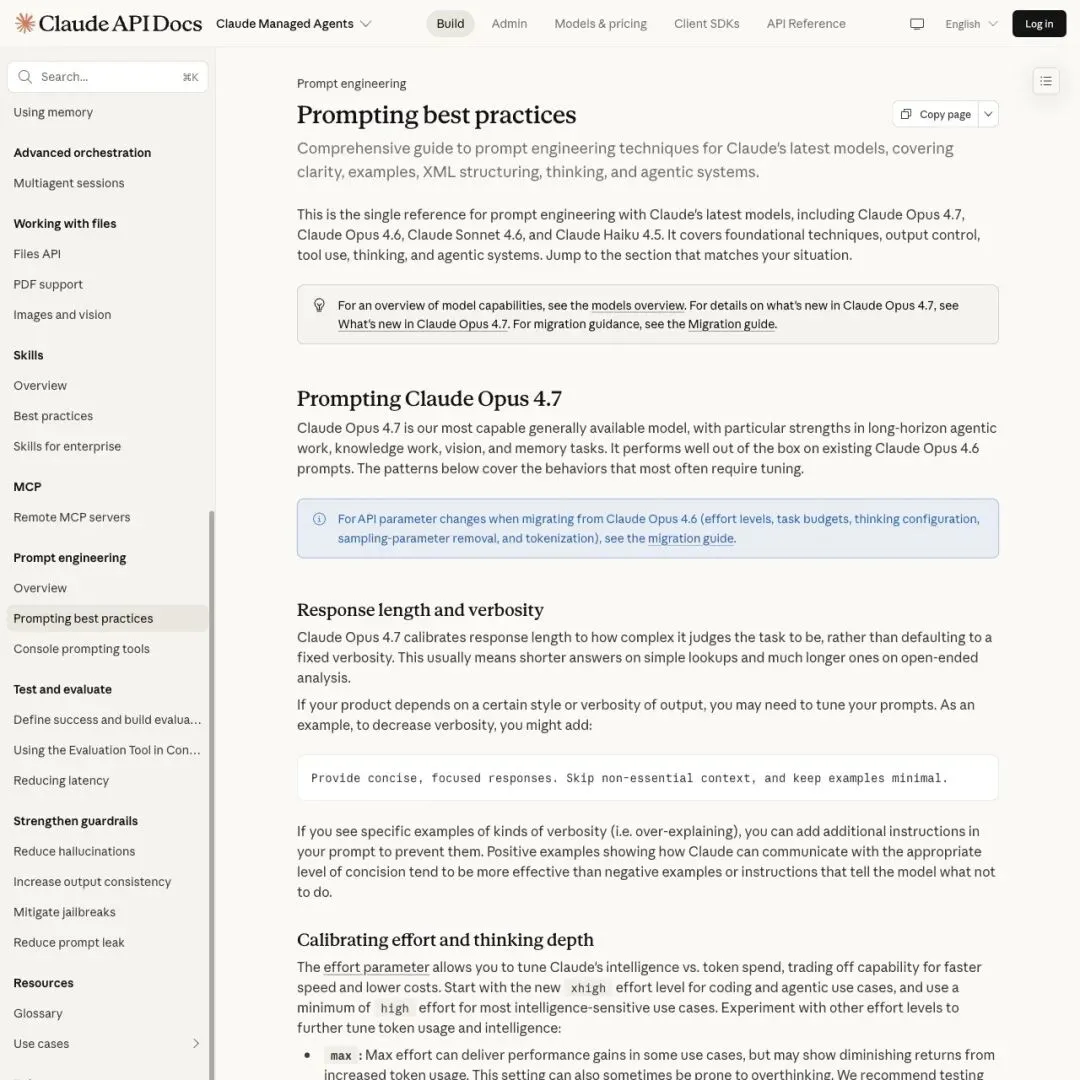
▲ 如果模型思考太浅,Anthropic 建议调高 effort,而非硬写更多提示词
两家看起来”相反”,但底层逻辑是一样的
Alex Prompter 的帖子里有一个很有传播力的总结:
GPT-5.5 变得更自主了——你只需要告诉它”要什么结果”,过程它自己找。 Claude Opus 4.7 变得更精确了——你需要更明确地告诉它”到底要什么”,因为它不再替你脑补。
表面上看,一个在说”少说步骤”,一个在说”说清楚要求”。方向好像完全相反?
其实剥开传播层的简化,两家底层的方法论正在快速趋同:
第一,先定义 success criteria(成功标准),再开始写 prompt。OpenAI 说的是 “expected outcome, success criteria, evidence rules”;Anthropic 要求在做 prompt engineering 之前先有”a clear definition of the success criteria”和”ways to empirically test against those criteria”。
第二,别把旧 prompt stack 当资产,把它当技术债来审视。OpenAI 明确要求 fresh baseline;Anthropic 则通过改变 verbosity / effort / thinking 的默认行为,倒逼开发者重新调整。
第三,prompt 从”流程控制”走向”结果定义 + 评测校准”。堆流程、堆限制、堆补丁的时代正在结束。
Simon Willison 一语中的
知名开发者博主 Simon Willison 在 4 月 25 日就注意到了 OpenAI 的文档更新,并写了一篇博文专门讨论。他抓住了最关键的一句:
“Interesting to see OpenAI recommend starting from scratch rather than trusting that existing prompts optimized for previous models will continue to work effectively with GPT-5.5.”
「有意思的是,OpenAI 在建议开发者从零开始,而非相信那些针对旧模型优化过的 prompt 能在 GPT-5.5 上继续有效。」
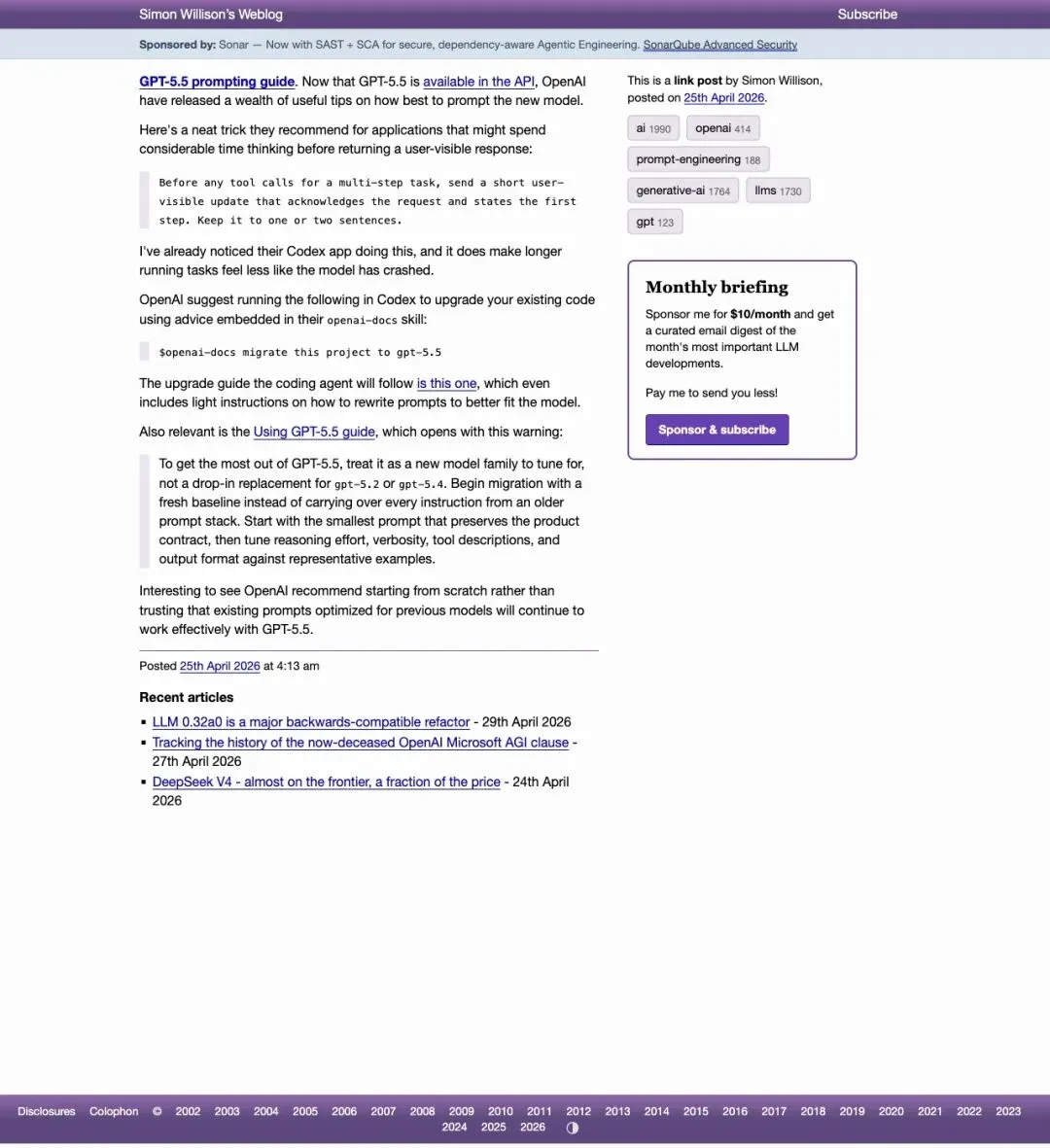
▲ Simon Willison:OpenAI 在建议你从零开始
HN 社区的真实体感:旧 prompt 确实是”一堆 hack”
Hacker News 上关于这个话题的讨论帖里,一条评论说出了很多开发者的心声:
“Most of my 5.4 prompts are piles of hacks to stop the model from hallucinating or going off topic.”
「我给 5.4 写的 prompt,大部分就是一堆为了防幻觉、防跑偏的 hack。」
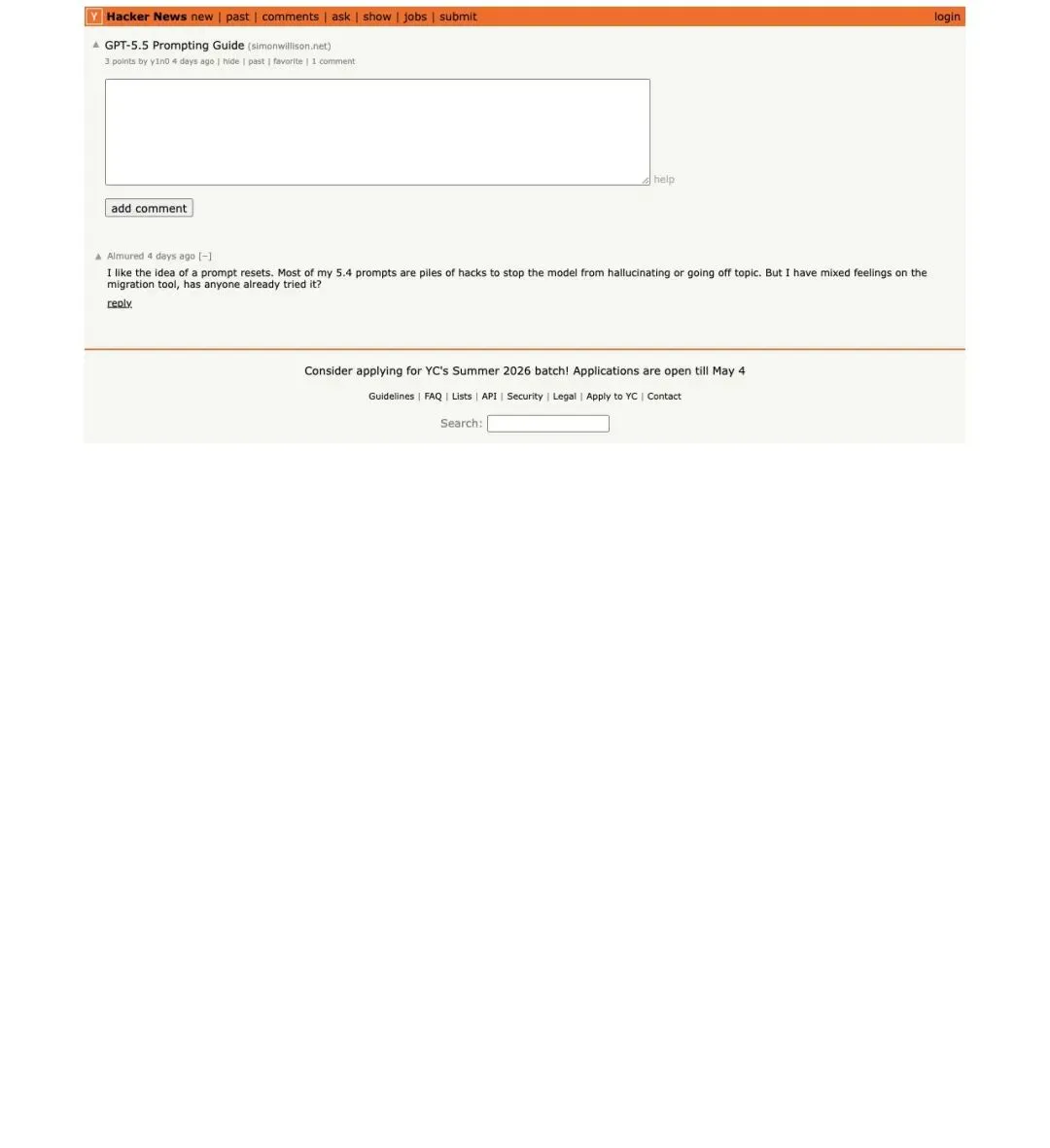
▲ HN 用户坦言:旧 prompt 本质上就是一堆防御性 hack
这正好印证了 OpenAI 文档里的判断:那些曾经有用的”脚手架”,在新模型面前已经变成了包袱。
反对声音同样值得听
当然,X 上也有人提出了不同看法。
工程师 Anton Kuratnik 直接反驳了”Claude 4.7 更字面化”的说法:
“100% BS… Major reason I stopped using 4.7 is because it does what you ask and then 50 things you didn’t.”
「完全胡扯……我不用 4.7 的主要原因恰恰是:它做了你要求的事,然后又多做了 50 件你没要求的。」
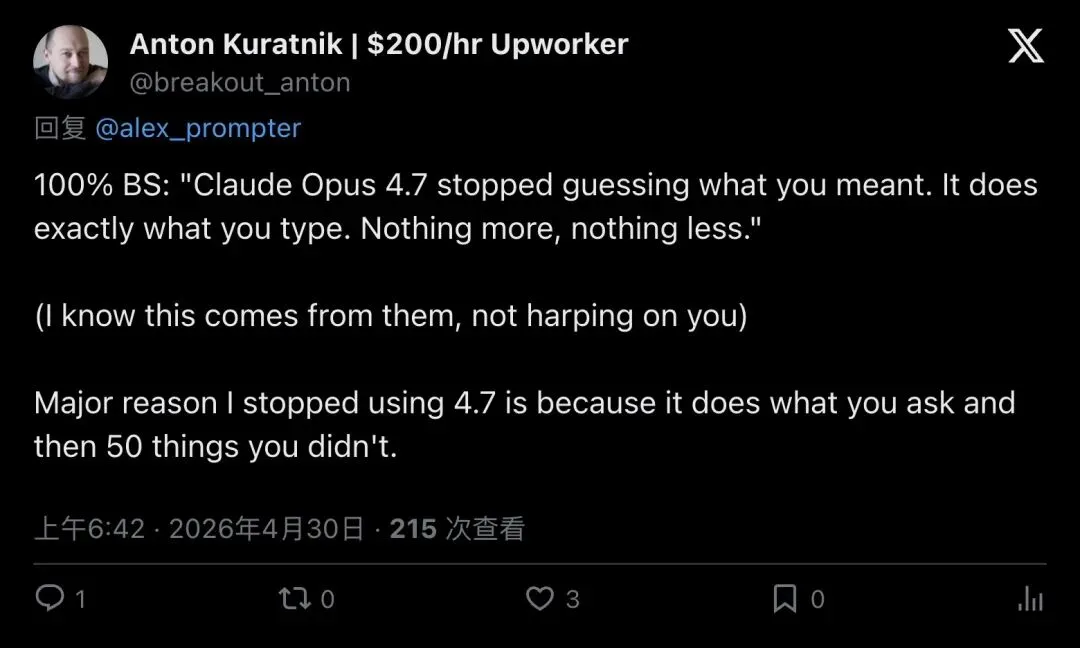
▲ Anton 的痛点和 Alex 的总结恰好相反:他觉得 Opus 4.7 管得太宽
Wolfram Ravenwolf 则从产品体验的角度提出了一个更根本的问题:
“If the user or prompt has to adapt to the AI instead of the other way around, that’s bad. If a minor model version update makes that a necessity (4.6→4.7 / 5.4→5.5), that’s even worse.”
「如果用户和提示词要反过来适应 AI,那就很糟糕。如果一次小版本升级就逼着用户必须适配(4.6→4.7 / 5.4→5.5),那就更糟糕了。」

▲ Wolfram 的质疑:每次升级都逼用户重写 prompt,这本身就是糟糕的产品设计
这个批评很有道理。模型能力在进步,但如果每一代升级都意味着开发者要推翻重来,那 prompt 就永远无法成为稳定的基础设施。
真正在过时的,到底是什么?
把所有声音放在一起,一个更清晰的结论开始浮现:
过时的,不是”提示词”这件事本身。提示词依然重要,甚至比以前更重要——因为模型变强了,精准定义需求的能力差距反而被放大了。
真正在过时的,是那套”驯服式”的 prompt 写法:靠堆流程步骤来防跑偏,靠堆负向约束来防幻觉,靠堆角色扮演来维持风格,靠一层又一层的补丁来修修补补。
OpenAI 把新范式叫outcome-first prompting——先说清结果、约束和成功标准,让模型自己选路径。
Anthropic 的方法论更像eval-driven prompting——先建立评测体系,再用正向示例和参数调校来精确控制行为。
殊途同归。
一位 X 用户 lossybrain 的总结也许最贴切:好的 prompting architecture 能兼容不同模型的 worldview;如果你的 prompt 只在一个模型版本上能用,那问题大概出在你的系统设计上,跟模型关系不大。
给开发者的行动清单
如果你还在用几个月前给 GPT-5.4 或 Claude 4.6 调好的 prompt stack,现在是时候审视一下了:
1.做一次 prompt 审计:标记哪些指令是为了”扶着模型走路”写的——它们很可能已经变成噪音 2.建立 fresh baseline:从最短的、只保留核心产品约束的 prompt 开始重新调 3.定义 success criteria:先明确”什么是好结果”,再来调 prompt 4.用评测驱动迭代:拿真实样本测,别靠直觉判断 prompt 好不好用 5.分离关注点:把”风格控制”和”任务控制”拆开,分别用不同的机制处理
提示词工程,正在从”黑魔法”变成”工程学”。
这一轮升级也许会让很多精心打磨的 prompt 突然失灵。但换个角度看——如果你的 prompt 只在特定模型版本上才能用,那它从来就不是资产,一直都是技术债。
— END —