 夜雨聆风
夜雨聆风





DuckDB 插件开发实战:Mac 版 Everything–表函数三板斧——Bind、Init、Execute 与扩展入口
表函数三板斧——Bind、Init、Execute 与扩展入口
—— 让 SQL 能查外部数据源
本文是《DuckDB 插件开发实战:Mac 版 Everything》系列的第 3 篇。上一篇从零走了一遍 apfs 插件的构建过程,这篇来拆解 DuckDB 表函数的核心模型——三个回调函数是怎么配合的,以及扩展入口文件怎么把它们组装起来。
版本基线:本文所有代码、行数、类名、宏呈现的形式都基于
duckdb-apfs仓库duckdb/submodule 锁定的 DuckDB v1.5.2、STANDARD_VECTOR_SIZE = 2048(duckdb/src/include/duckdb/common/vector_size.hpp:16)。本文引用的apfs_extension.cpp = 180 行、apfs_fts_scanner.cpp = 184 行、LoadInternal = 27 行、apfs_extension.hpp = 22 行均为作者环境实测,读者环境会有细微差异。仅基本功能实现,实际运行体验仍与Windows版本有不小差距,源码见参考资料。
标量函数 vs 表函数
DuckDB 扩展能注册两种函数:
-- 标量函数:输入一行,输出一个值
SELECT apfs_has_changes('/tmp', TIMESTAMP'2026-04-01');
-- → true
-- 表函数:输出一张表,可以在 FROM 里用
SELECT*FROM apfs_scan('/tmp', 'fts');
-- → 多行多列结果|
|
|
|
|
|
|
ScalarFunction |
|
SELECT func() |
|
|
TableFunction |
|
SELECT * FROM func() |
apfs 扩展注册了 2 个表函数(apfs_scan、apfs_search)和 1 个标量函数(apfs_has_changes)。这篇重点讲表函数——因为它是”把外部数据源接入 SQL”的核心。
表函数的三个回调
每个 DuckDB 表函数由三个 C++ 回调函数组成:
Bind:告诉 DuckDB “我要返回什么”
// src/apfs_extension.cpp
static unique_ptr<FunctionData> ApfsScanBindInternal(
ClientContext &context,
TableFunctionBindInput &input,
vector<LogicalType> &return_types,
vector<string> &names,
const string &mode_str)
{
// 1. 读取参数
auto path = input.inputs[0].GetValue<string>();
// 2. 定义输出列(11 列)
DefineApfsColumns(return_types, names);
// 3. 返回 BindData(传给后续阶段)
if (mode == "spotlight") {
auto bind_data = make_uniq<ApfsSpotlightScanBindData>();
bind_data->root_path = path;
return std::move(bind_data);
} else {
auto bind_data = make_uniq<ApfsFtsScanBindData>();
bind_data->root_path = path;
return std::move(bind_data);
}
}Bind 做三件事:
-
1. 解析参数——从 input.inputs[]读取用户传的 path 和 mode -
2. 定义输出列——往 return_types和names里塞列定义 -
3. 返回 BindData——一个自定义结构体,把参数传给 Init 和 Execute
BindData 就是一个继承自 TableFunctionData 的结构体,你想存什么就存什么:
// src/include/apfs_fts_scanner.hpp
structApfsFtsScanBindData : public TableFunctionData {
string root_path; // 就一个字段:要扫描的路径
};Init:准备好扫描资源
// src/apfs_fts_scanner.cpp
unique_ptr<GlobalTableFunctionState> ApfsFtsScanInit(
ClientContext &context,
TableFunctionInitInput &input)
{
auto &bind_data = input.bind_data->Cast<ApfsFtsScanBindData>();
auto state = make_uniq<ApfsFtsScanGlobalState>();
// 验证路径存在
structstat path_stat;
if (stat(bind_data.root_path.c_str(), &path_stat) != 0) {
throwIOException("path '%s' does not exist", bind_data.root_path);
}
// 打开 fts 遍历句柄
char *path_argv[2];
path_argv[0] = const_cast<char *>(bind_data.root_path.c_str());
path_argv[1] = nullptr;
FTS *fts = fts_open(path_argv, FTS_LOGICAL | FTS_NOCHDIR, nullptr);
state->fts_handle = fts;
return std::move(state);
}Init 做一件事:打开数据源。对 fts 模式就是 fts_open(),对 spotlight 模式就是 MDQueryCreate() + MDQueryExecute()。
GlobalState 也是一个自定义结构体,保存扫描过程中的状态:
structApfsFtsScanGlobalState : public GlobalTableFunctionState {
void *fts_handle = nullptr; // fts 句柄
bool finished = false; // 是否扫描完毕
~ApfsFtsScanGlobalState() {
if (fts_handle) { fts_close(static_cast<FTS *>(fts_handle)); }
}
};注意析构函数里关闭了 fts_handle——资源在 GlobalState 的生命周期内管理,DuckDB 会自动销毁它。
Execute:批量填充数据
// src/apfs_fts_scanner.cpp
voidApfsFtsScanFunction(
ClientContext &context,
TableFunctionInput &data,
DataChunk &output)
{
auto &state = data.global_state->Cast<ApfsFtsScanGlobalState>();
if (state.finished) {
output.SetCardinality(0); // 返回 0 行 → DuckDB 停止调用
return;
}
auto fts = static_cast<FTS *>(state.fts_handle);
idx_t count = 0;
// 一次填充最多 STANDARD_VECTOR_SIZE(2048)行
while (count < STANDARD_VECTOR_SIZE) {
FTSENT *entry = fts_read(fts);
if (!entry) { state.finished = true; break; }
if (entry->fts_info == FTS_DP) continue; // 跳过后序目录
if (entry->fts_info == FTS_ERR) continue; // 跳过错误项
// 填充 11 列
output.SetValue(0, count, Value(SanitizeUtf8(entry->fts_path)));
output.SetValue(1, count, Value(SanitizeUtf8(entry->fts_name)));
output.SetValue(2, count, Value(ApfsGetFileExtension(name)));
output.SetValue(3, count, Value::BIGINT(st->st_size));
// ... 其余 7 列类似
count++;
}
output.SetCardinality(count); // 告诉 DuckDB 这次返回了几行
}Execute 的核心逻辑:
-
1. 循环读取数据源(fts_read / MDQueryGetResultAtIndex) -
2. 填充 DataChunk—— output.SetValue(col, row, value) -
3. 每批最多 2048 行( STANDARD_VECTOR_SIZE,DuckDB 向量化执行的标准批次大小) -
4. 返回 0 行表示结束——DuckDB 不再调用 Execute
DataChunk 怎么填
DataChunk 是 DuckDB 向量化执行引擎的基本数据单位——一批最多 2048 行、多列的数据块。
apfs 扩展用的是最简单的逐行设值方式:
output.SetValue(列号, 行号, 值);|
|
|
|
|
|
|
Value(string) |
|
|
|
Value(string) |
|
|
|
Value(string) |
|
|
|
Value::BIGINT(int64) |
|
|
|
Value(string) |
|
|
|
Value::TIMESTAMP(timestamp_t) |
|
|
|
Value::TIMESTAMP(timestamp_t) |
|
|
|
Value::TIMESTAMP(timestamp_t) |
|
|
|
Value(string) |
|
|
|
Value(string) |
|
|
|
Value::INTEGER(int32) |
SetValue 是最直观但不是最高性能的写法(每次调用有类型检查开销)。对于 apfs 这种 I/O bound 的场景够用了。高性能扩展会用 FlatVector::GetData<T>() 直接写底层 buffer。
注册表函数:把三个回调组装起来
// src/apfs_extension.cpp
staticvoidLoadInternal(ExtensionLoader &loader){
// apfs_scan: 用 TableFunctionSet 注册两个重载
TableFunctionSet scan_set("apfs_scan");
TableFunction scan_one_arg("apfs_scan",
{LogicalType::VARCHAR}, // 参数类型列表
ApfsScanFunction, // Execute 回调
ApfsScanBindOneArg, // Bind 回调
ApfsScanInit); // Init 回调
scan_one_arg.named_parameters["since"] = LogicalType::TIMESTAMP;
scan_set.AddFunction(scan_one_arg);
// 第二个重载:apfs_scan(path, mode)
TableFunction scan_two_args("apfs_scan",
{LogicalType::VARCHAR, LogicalType::VARCHAR},
ApfsScanFunction, ApfsScanBindTwoArgs, ApfsScanInit);
scan_two_args.named_parameters["since"] = LogicalType::TIMESTAMP;
scan_set.AddFunction(scan_two_args);
loader.RegisterFunction(scan_set);
}TableFunction 构造函数的参数顺序:名字 → 参数类型 → Execute → Bind → Init。
named_parameters 是可选参数——用户可以写 apfs_scan('/', 'spotlight', since=TIMESTAMP '2026-04-01'),在 Bind 阶段通过 input.named_parameters.find("since") 读取。
Extension 基类
每个 DuckDB 扩展都要继承 Extension 基类(src/include/apfs_extension.hpp,22 行):
classApfsExtension : public Extension {
public:
voidLoad(ExtensionLoader &loader)override; // 注册所有函数
std::string Name()override; // 返回 "apfs"
std::string Version()constoverride; // 返回版本号
};|
|
|
|
Load() |
|
|
Name() |
|
"apfs" |
Version() |
|
EXT_VERSION_APFS |
ScalarFunction 的注册方式
标量函数不需要 Bind/Init/Execute 三板斧,只要一个执行函数:
ScalarFunction CreateApfsHasChangesFunction(){
ScalarFunction func("apfs_has_changes",
{LogicalType::VARCHAR, LogicalType::TIMESTAMP}, // 参数
LogicalType::BOOLEAN, // 返回类型
ApfsHasChangesFunction); // 执行函数
func.stability = FunctionStability::VOLATILE;
return func;
}FunctionStability::VOLATILE 告诉优化器”这个函数每次调用结果可能不同”——因为文件系统在变化。如果不设这个,DuckDB 可能会缓存结果。
统一入口 + dynamic_cast 分发
apfs_scan 的两种模式共享同一个 Init 和 Execute。怎么区分走哪个引擎?
// Bind 阶段:根据 mode 参数创建不同类型的 BindData
static unique_ptr<FunctionData> ApfsScanBindInternal(..., const string &mode_str){
if (mode == "spotlight") {
returnmake_uniq<ApfsSpotlightScanBindData>();
} else {
returnmake_uniq<ApfsFtsScanBindData>();
}
}
// Execute 阶段:通过 dynamic_cast 判断类型并分发
staticvoidApfsScanFunction(...){
auto &bind_data = data.bind_data->Cast<TableFunctionData>();
if (dynamic_cast<const ApfsSpotlightScanBindData *>(&bind_data)) {
ApfsSpotlightScanFunction(context, data, output);
} else {
ApfsFtsScanFunction(context, data, output);
}
}模式选择发生在 Bind,分发发生在 Init 和 Execute。 BindData 的类型就是”标签”。
C 入口点
文件最后 6 行,动态加载的关键:
extern"C" {
DUCKDB_CPP_EXTENSION_ENTRY(apfs, loader) {
duckdb::LoadInternal(loader);
}
}DUCKDB_CPP_EXTENSION_ENTRY(apfs, loader) 宏展开为 void apfs_duckdb_cpp_init(duckdb::ExtensionLoader &loader) 函数。动态加载时 DuckDB 执行 dlsym(handle, "apfs_duckdb_cpp_init") 找到这个符号并调用。静态链接时通过编译期注册表直接调用,不需要 dlsym。
扩展加载的完整流程
11 列 Schema 的集中定义
三个函数共享相同的列定义,集中在一个辅助函数里:
staticvoidDefineApfsColumns(vector<LogicalType> &return_types, vector<string> &names){
names.emplace_back("path"); return_types.emplace_back(LogicalType::VARCHAR);
names.emplace_back("name"); return_types.emplace_back(LogicalType::VARCHAR);
names.emplace_back("extension"); return_types.emplace_back(LogicalType::VARCHAR);
names.emplace_back("size"); return_types.emplace_back(LogicalType::BIGINT);
names.emplace_back("file_type"); return_types.emplace_back(LogicalType::VARCHAR);
names.emplace_back("modified_at"); return_types.emplace_back(LogicalType::TIMESTAMP);
names.emplace_back("created_at"); return_types.emplace_back(LogicalType::TIMESTAMP);
names.emplace_back("accessed_at"); return_types.emplace_back(LogicalType::TIMESTAMP);
names.emplace_back("permissions"); return_types.emplace_back(LogicalType::VARCHAR);
names.emplace_back("owner"); return_types.emplace_back(LogicalType::VARCHAR);
names.emplace_back("depth"); return_types.emplace_back(LogicalType::INTEGER);
}集中定义有两个好处:修改一处全部生效,三个函数保证 schema 一致。
生命周期总结
mermaid-diagram-2026-05-02-000729.png
你不需要管内存释放——把资源放在 GlobalState 的成员变量里,析构函数自动清理。这是 DuckDB 扩展开发最优雅的地方之一。
总结
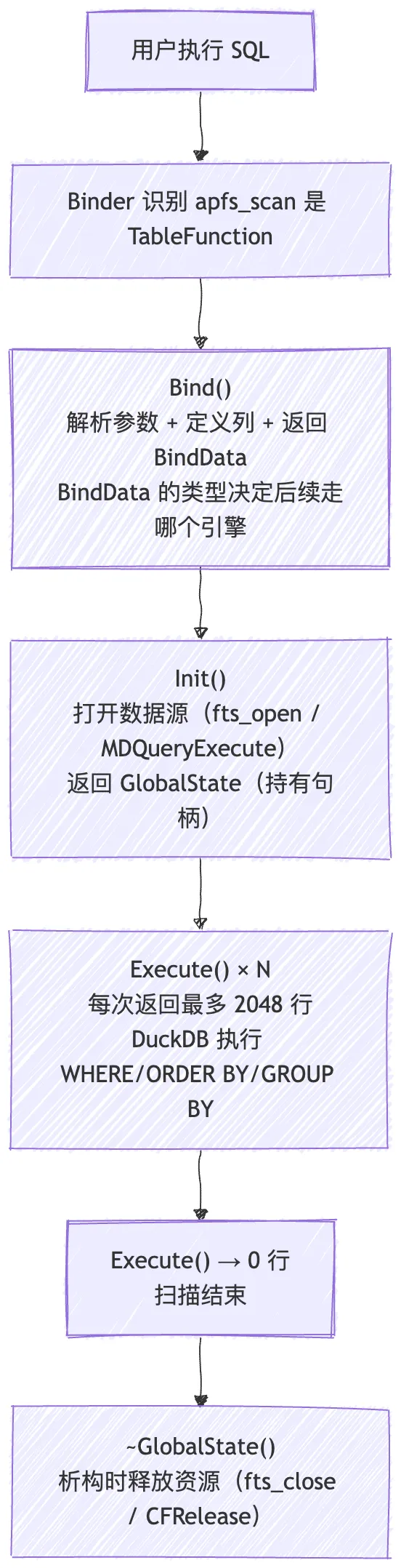
-
1. 表函数 = Bind + Init + Execute 三个回调 -
2. Bind 解析参数 + 定义输出列,返回 BindData -
3. Init 打开数据源,返回 GlobalState -
4. Execute 循环填充 DataChunk(每批最多 2048 行),返回 0 行表示结束 -
5. 资源管理靠 GlobalState 析构函数——RAII 风格,不用手动释放 -
6. 扩展入口文件 apfs_extension.cpp共 180 行,其中LoadInternal完整 27 行,是所有函数的注册中心 -
7. DUCKDB_CPP_EXTENSION_ENTRY是动态加载的 C 入口点
下一篇深入两个引擎的实现细节:fts(3) 怎么遍历文件系统,Spotlight 怎么查索引。
参考资料
-
• mac-everything -
• duckdb-apfs -
• DuckDB 官方文档 – Table Functions -
• duckdb-apfs 源码: src/apfs_extension.cpp(180 行,Bind/Init/Execute 注册和分发) -
• duckdb-apfs 源码: src/apfs_fts_scanner.cpp(fts 模式的完整 Bind/Init/Execute) -
• duckdb-apfs 源码: src/include/apfs_fts_scanner.hpp(BindData 和 GlobalState 定义) -
• duckdb-apfs 源码: src/include/apfs_extension.hpp(22 行,Extension 子类定义)