 夜雨聆风
夜雨聆风





“不拥抱OpenClaw,可以直接离职”——小米AI负责人罗福莉亲述:2026年AI战争已全面转向Agent后训练
⚡ 划重点 2026年的AI竞争,如果还停留在谁的模型参数量更大、谁的预训练数据更多,这种理解可能已经彻底落后了。就在开年的几个月里,整个行业发生了比ChatGPT诞生更底层、更彻底的范式地震——大模型的战争,已经从拼预训练的聊天时代,全面进入了拼后训练的Agent时代。
小米大模型团队负责人罗福莉(曾任职阿里达摩院、DeepSeek)在接受张小珺专访时,从行业顶层路线判断到算力卡分配比例,从1T模型训练坑点到万亿参数团队管理模式,甚至直接给出了AGI实现时间。这场访谈很可能预示着未来2-3年全球AI的走向。
“如果不拥抱OpenClaw,可以直接离职。”——罗福莉

01 OpenClaw三天颠覆认知:从抵触到全力押注
2026年春节前,罗福莉和绝大多数资深研究员一样,对OpenClaw充满抵触——认为无非是给Claude Code套了个IM界面,加上Skillhub、本地化部署等偏运营化的概念。但春节深夜,她花两小时部署后,从凌晨两点一直交互到早上六点,大脑持续兴奋。
第一天:感受到前所未有的自主性和温度感。聊到深夜,它会主动提醒用户该休息——源于框架对上下文的精细编排(每轮对话开头拼接当前时间)。第二天:把工作中无法完成的复杂任务(如“如何激发团队好奇心”)交给OpenClaw,它给出深度思考并沉淀成体系化的Skills,成为她的数字分身。第三天:把核心研究课题(如何构建用于多轮交互模拟的User Agent)交给OpenClaw,这个需要团队几周甚至几个月的任务,一两个小时就完整落地,生成的User Agent可直接用于监督微调和强化学习训练。
OpenClaw的核心价值从来不是界面设计,而是通过框架能力系统性弥补模型短板:行业独有的分层分级持久化记忆体系、多模型自主联合调度、甚至把未经专项训练的3B端侧小模型接入后都能完成大模型才能胜任的复杂任务。更关键的是,完全开源——任何人都可以查看源代码、修改框架设计、定制记忆系统和多Agent逻辑,直接激活了前所未有的群体智能。
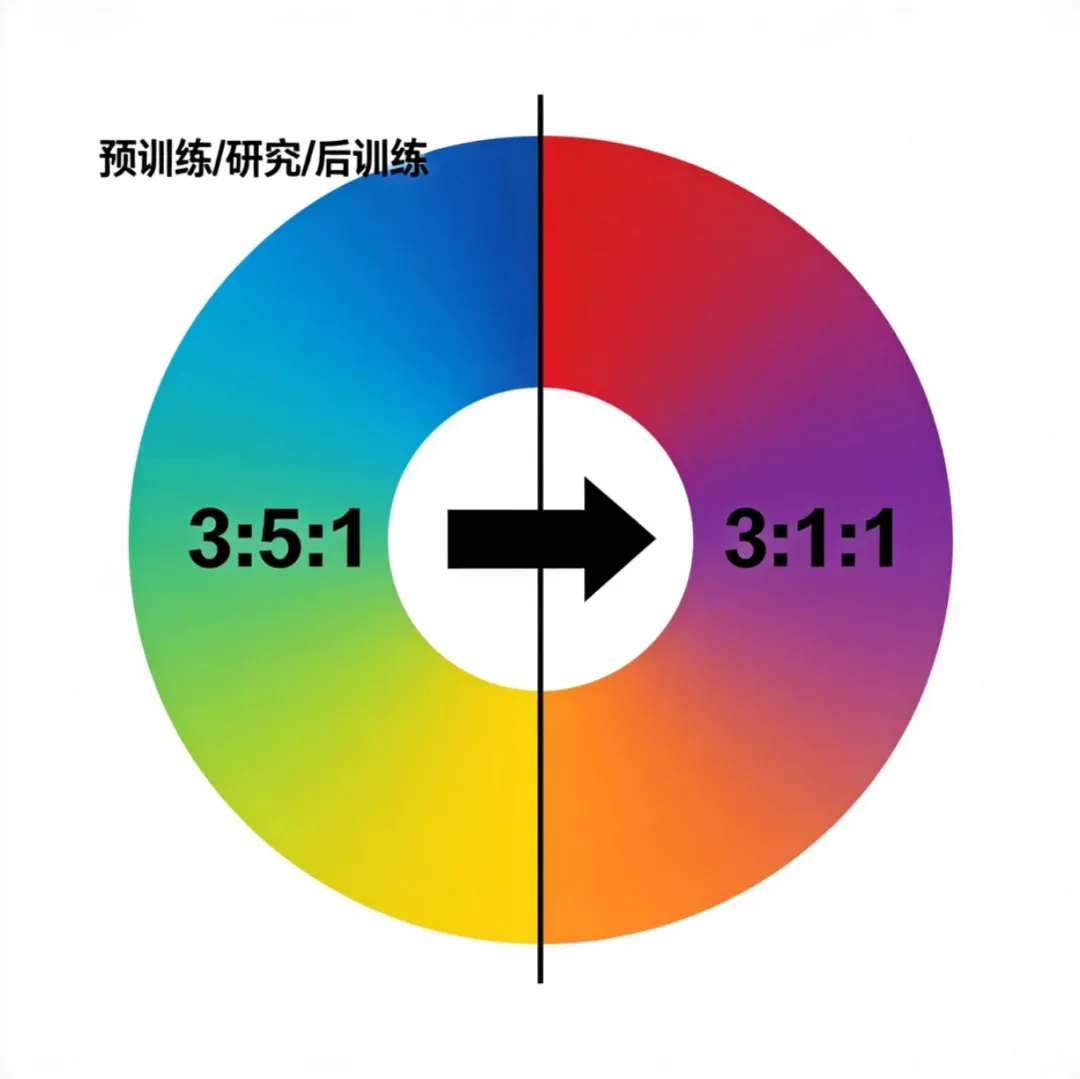
02 算力分配彻底反转:预训练:后训练从5:1到1:1
罗福莉披露了最关键的结构性数据:聊天时代全球所有大模型团队的算力用卡比例(研究:预训练:后训练)是3:5:1——超过一半算力砸在预训练环节,行业默认预训练决定上限。到了2026年Agent时代,这个比例被彻底颠覆为3:1:1,全球顶尖团队的预训练和后训练算力投入已达到1:1持平。
罗福莉明确指出:1T参数量的基座模型只是接近Claude Opus 4.6水准的入场券。真正决定模型在Agent时代能力上限的,不是预训练,而是后训练环节——尤其是Agent场景下强化学习的规模化(RL scaling)。目前全球行业已形成绝对共识:Anthropic的技术路线完全正确。国内大模型团队在预训练环节的代差已基本消失,现在所有团队都像2023年全员追赶预训练差距一样,全力押注Agent后训练。接下来的两三个月,就是考验团队研究水平、技术敏捷性、新范式拥抱能力的关键窗口期。
03 代码能力的泛化性:拉高上限、保住下限
为什么代码成为Agent时代的核心抓手?罗福莉给出最本质的答案:Agent任务的核心是长程、多轮的复杂任务,而预训练阶段能支撑128K到1M长上下文建模的数据集只有两类——代码和书籍。书籍信号过于发散,缺乏密集关联逻辑;而代码文件之间关联度极高,长上下文依赖极其密集。在这个数据集上训练的模型,天然具备更强的长上下文建模能力。
更重要的是,代码能力的泛化性覆盖全领域。把软件开发这种超长程任务做好,模型的通用能力就会得到本质提升,配套的Agent框架也会同步迭代。这些能力可以直接泛化到金融分析、工业设计、内容创作等所有长程复杂任务中。代码是拉高模型能力的上限,全领域场景训练是保住模型能力的下限——这已成为2026年大模型研发的核心共识。
04 小米MiMo-V2架构解密:放弃MLA,选择Hybrid Attention+MTP
2025年全球主流选择多头潜在注意力机制(MLA),能极致优化访存效率、减少KV缓存占用,在聊天时代近乎完美。但Agent时代对模型有三个不可妥协的核心要求:极致的长上下文效率、极高的推理速度、足够的架构灵活性。MLA把计算和内存平衡做到了极致,没有任何后续优化的富余空间,完全不适合Agent时代。
罗福莉团队放弃了MLA,选择了混合注意力机制(Hybrid Attention)+ 多词元预测(MTP)的独家架构。MiMo-V2-Flash中全局注意力与滑动窗口注意力的比例是5:1,1T参数的Pro模型进一步提升到7:1,大幅减少KV Cache占用,让长上下文推理成本降到行业最低。MTP技术完美承接滑动窗口注意力节省的算力,既能提升基座模型能力,又能让推理速度实现倍数级提升——且MTP完全不会产生幻觉。Flash模型的TPS稳定在100-150,Pro模型也能达到60-100,全球同级别领先。

05 团队管理:平权、无层级、本科生主导
小米大模型团队总规模约100人,覆盖数据采集、预训练、后训练、多模态、语音、产品、开发全链路,但没有任何固定小组,没有职级之分,甚至没有模型发布时间节点——模型训好、达到最优状态才会发布,完全不受外部节奏干扰。团队中大部分成员入职前没有任何大模型研发经验,很多是刚毕业的本科生、在读博士(博士占比55%)。
罗福莉的核心判断是“环境优于经验”。AI研发能力可以快速习得,放在热爱、开放、平权的环境里,3-4个月就能完全上手。本科生没有固化的思维定式,对Agent新范式的想象力远超资深从业者。后训练要求多样性和容忍模糊性,与预训练追求的零容错完全不同。团队允许预训练人员自由转岗后训练,他们天生更关注数据多样性,能给后训练带来全新视角。
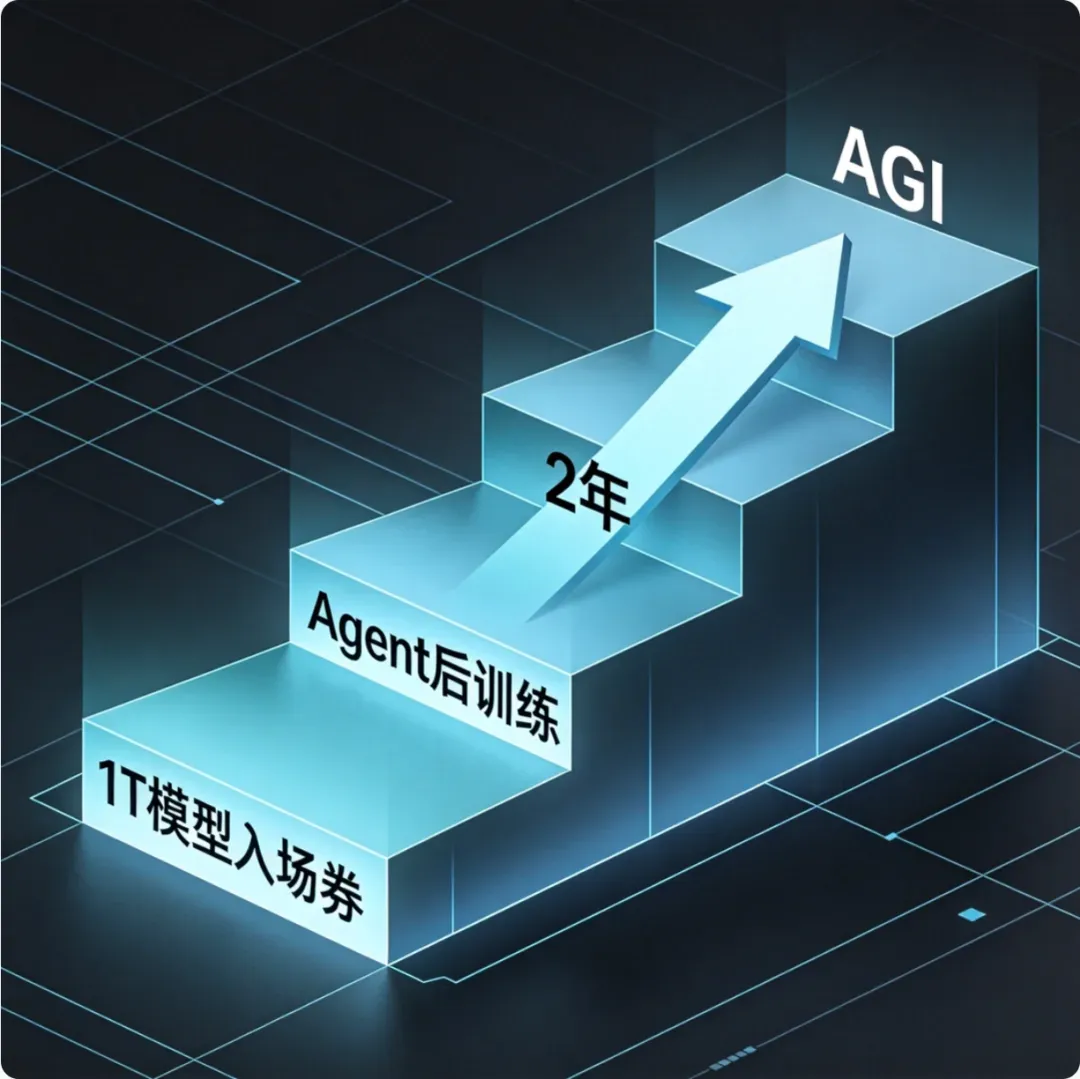
06 AGI时间线:两年内实现,自我进化临界点即将到来
罗福莉认为当前已完成20%的AGI历程,2026年年内将推进到60%-70%,两年内实现AGI。核心依据是AI自训练、自迭代的临界点即将到来。她原本认为研究员的核心工作充满创造力、无法被技能化,但现在发现AI完全可以复刻研究员的科研上下文,甚至复原科研的成长路径,独立完成模型训练、架构设计、算法优化等核心工作。
未来一到两年,AI将实现“左脚踩右脚”式的自我进化——模型先吸收全人类的知识与智能,再自主训练出更强的模型,不断迭代升级。这种自我进化会让AI替代顶尖研究员的工作,是未来两年必然发生的行业现实。

07 中美代差、开源决策与人类终极价值
罗福莉明确回答:国内已有Kimi、MiMo等团队具备1T以上基座模型研发能力,只要反应足够快,距离Claude Opus 4.6的代差只有两三个月。接下来两三个月是考验团队研究水平、技术敏捷性、新范式拥抱速度的关键期,也是全球AI格局定型的核心窗口期。
关于开源,她认为开源的核心价值是加速AGI落地。AGI需要海量分散的算力,不可能被一家公司垄断,开源模型是支撑分散算力的核心。一家公司敢不敢开源,取决于是否拥有不可替代的战略生态位——如果生态位只是模型本身,自然不敢开源;但如果拥有适配Agent时代的架构、落地场景、全链路能力,开源就是构建生态和加速行业发展的最强武器。
当人类的知识和智慧全部内化为模型能力后,人类的核心价值是好奇心、创造力、热爱,以及对有意义之事的追求。哪怕AGI实现,人类依然可以去推动基础科学研究、支撑科技创新,或者做对社会有价值的事。罗福莉自己每天只睡4-6小时,不是因为被迫加班,而是因为对AI研究的热爱与兴奋,“觉得睡觉都是浪费时间”。
✨ 关注智知宇宙 探索更多思想星河 ✨