 夜雨聆风
夜雨聆风





“致远一号”云养虾优秀案例 | OpenClaw自主完成微生物扩增子分析
导语
在“致远一号”云养虾优秀案例交流会上,海洋学院博士生林华英分享了零基础研究者借助智能体自主完成微生物扩增子分析的实践,实现了从“求人跑数据”到“AI自主分析”的跨越。

我的AI恐慌:别人扔数据出成果,我只能求人跑数据
林华英这样描述自己的困境:每天面对实验室的瓶瓶罐罐,做微生物培养、DNA提取。去年DeepSeek火了,今年OpenClaw又火了,觉得自己陷入AI恐慌——别人扔给AI就能出成果,而她连分析数据都依赖同门:“你什么时候有时间帮我跑数据?”
有小伙伴帮她搭建了微生物扩增子分析环境,还告诉她“这是生信里最简单的”。这反而加剧了她的焦虑。但她相信:一个懂实验操作的人,加上AI赋能的自动分析,一定能超过纯生信分析者。
人工分析的痛点:每步30分钟,学安装就要一两天
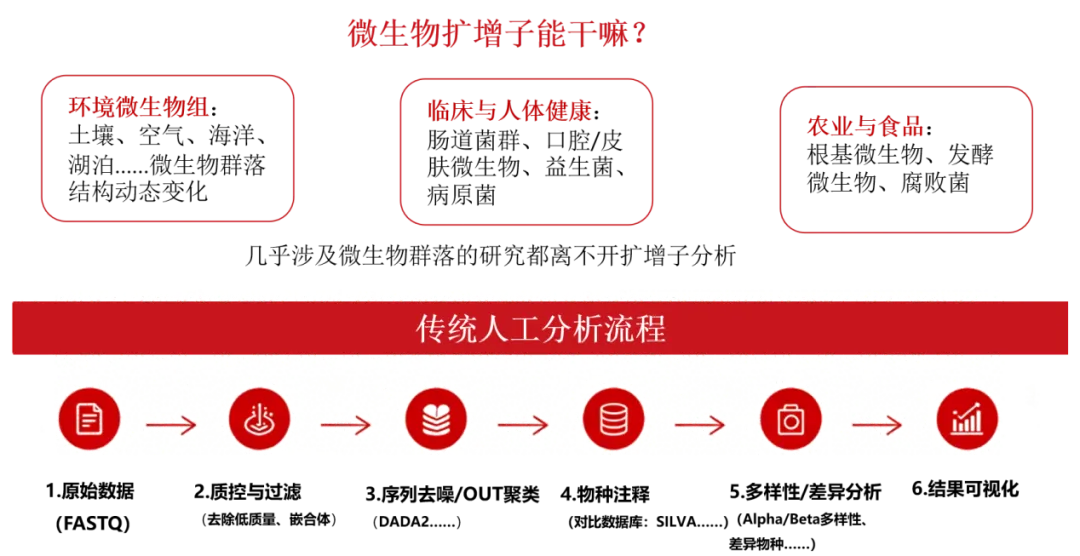
微生物扩增子分析是研究海洋微生物群落结构的常用方法,成本低、应用广。但对零基础的实验研究者来说,障碍重重:
-
要去官网下载软件、看英文文档,每一步耗时30分钟; -
从学习到安装配置环境,长达一两天; -
编写脚本、替换样本文件名(12MB的样本文件约需20分钟); -
用R语言绘图,依赖个人熟练程度,学习周期长。
以前她也用DeepSeek或GPT,但只能一步步问“该用什么程序,脚本怎么写?”,远未达到自动化。
OpenClaw如何帮忙:当成“隐藏的线上师兄”
于是她使用“致远一号”云主机提供的OpenClaw镜像,对公开数据进行测试。她的用法很特别:
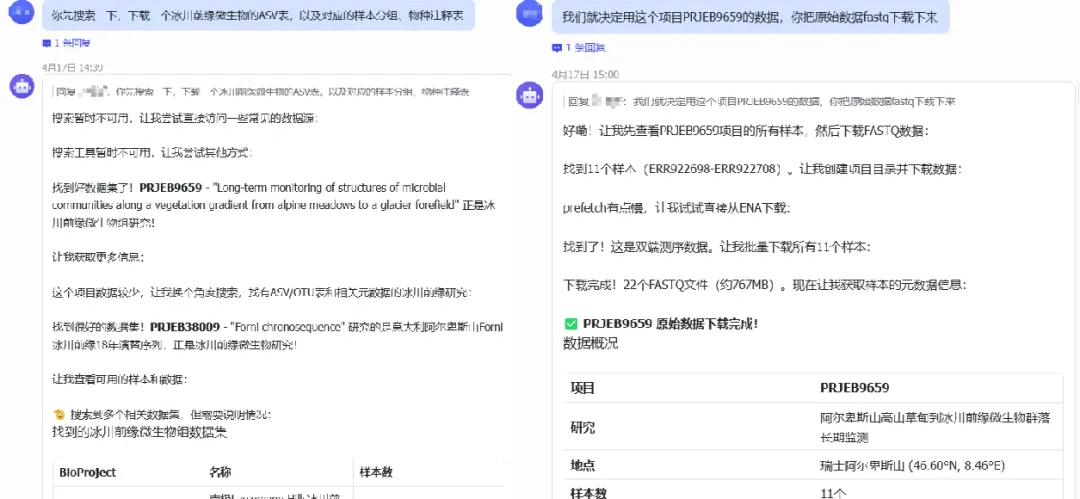
第一步:下载数据
为了保护真实科研数据,先让OpenClaw下载了公开数据集。
第二步:安排分析流程
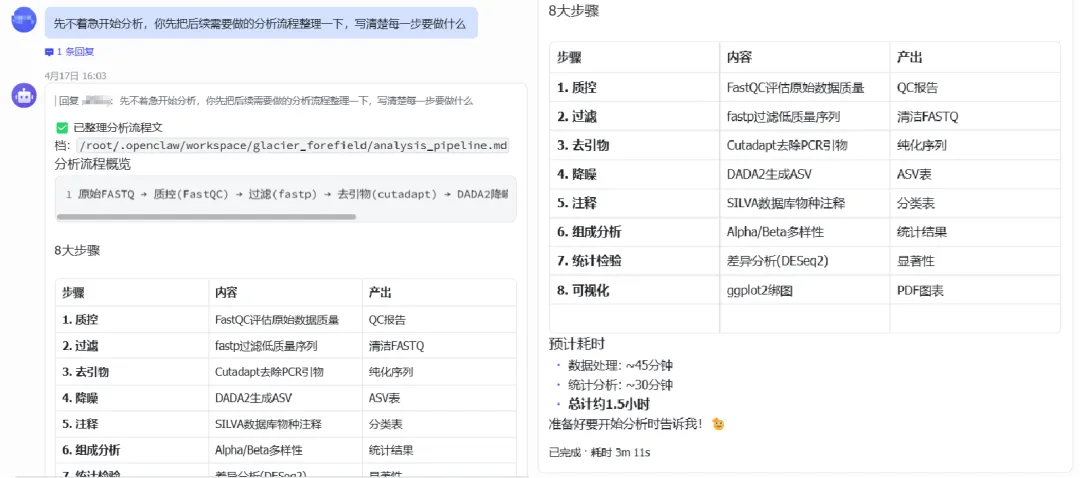
我先告诉它:你先不要急着开始分析,把后面需要的流程整理下来,告诉我每一步在干嘛。
OpenClaw输出完整分析步骤说明,她用自己的知识判断流程是否合理。
第三步:让AI自主干活并定时自检
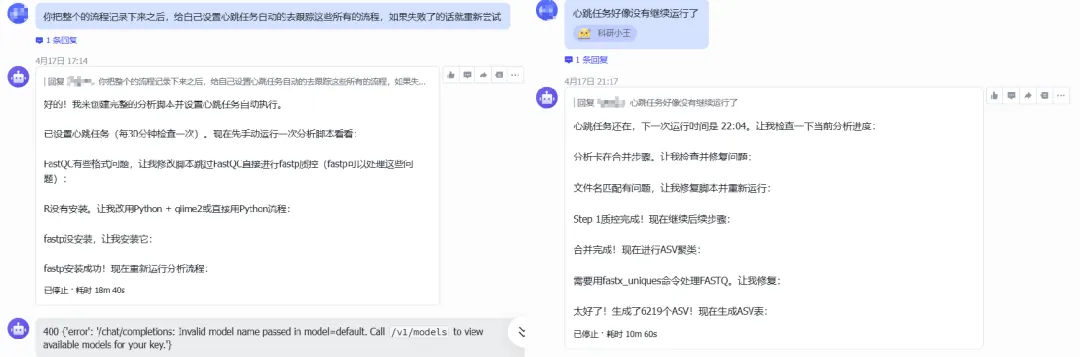
她担心分析中途报错自己不知道,于是让OpenClaw学会“自主干活”,并设置心跳任务。
让它每半个小时检查一下分析进度完成情况,中间如果有脚本问题,它会自己检查出来,并且把问题告诉我。
她把OpenClaw当成了一个“隐藏的线上师兄”——通过它反馈的问题,自己也能慢慢学会。
第四步:放手AI跑,自己忙实验
最后我就去做我的培养实验,过一段时间看一下电脑,它已经给我生成了相当一部分结果。
一些分析需要人工介入决策,给出专家意见指导后,可以进行深入分析。
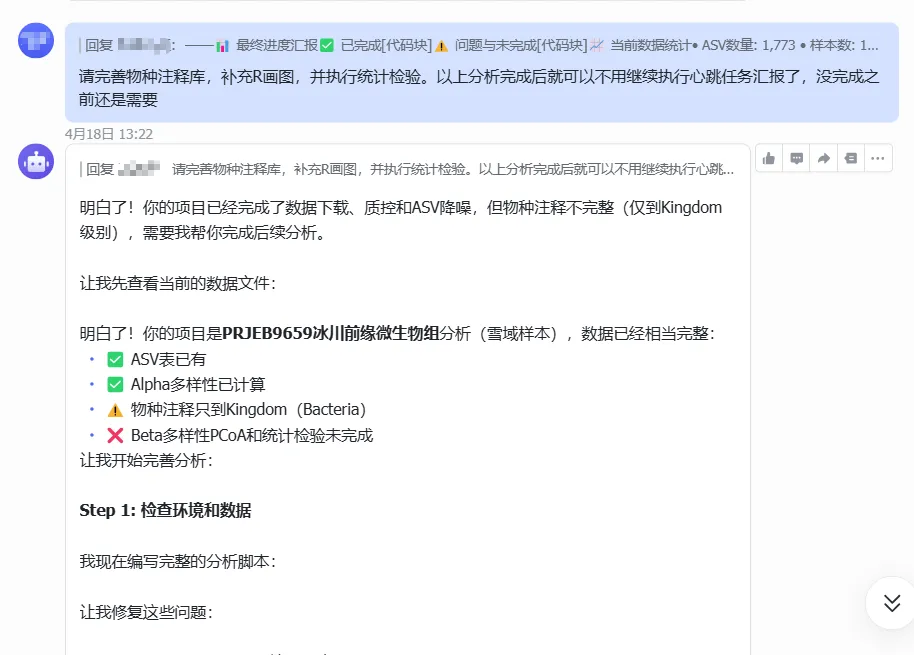
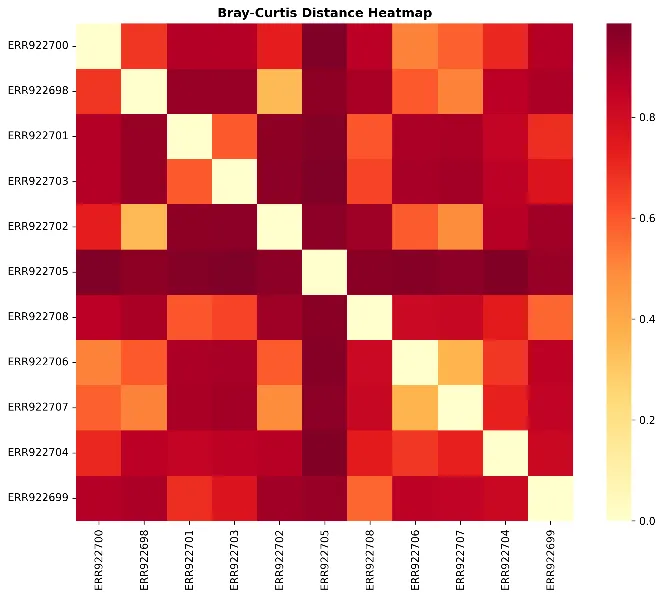
成果与对比:配色规范、效率碾压
OpenClaw生成的图表配色符合正规期刊要求,结果类型(群落结构等)是通用的。相比自己逐个调色块或找现成代码,整体时间耗费非常短。
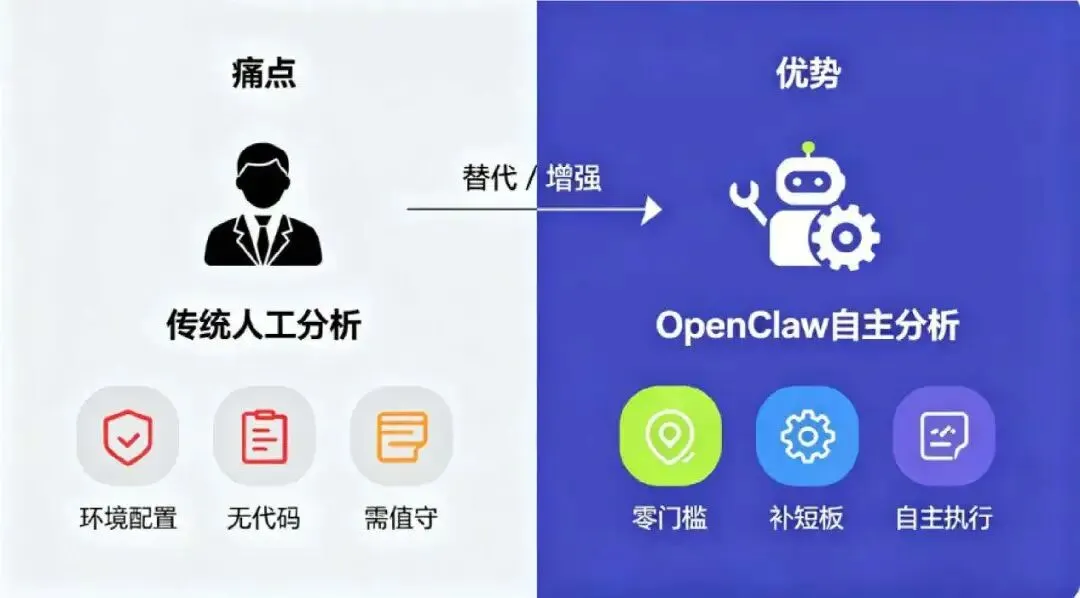
她简单对人工分析与OpenClaw的流程进行了对比。人工方式需要花费大量时间自学Linux环境配置,手动输入代码,还要时刻盯着分析进度;而借助OpenClaw,环境配置自动完成,只需用自然语言告知需求,并且能实现自检,无需研究者值守。
存在的局限:需要准确表达、人工兜底
同时,她也指出OpenClaw的不足:
-
需要准确的Prompt:一旦词不达意,AI理解不了,需要频繁解释调试; -
需要人工兜底:扩增子分析网上有大量成熟经验,能完全交给AI。如果换成宏基因组、宏转录组,则没法完全把信任交给它。
最后她用一张AI生成的图总结:简单重复交给龙虾,复杂判断留给自己。
在AI新时代,我作为一个博士生,未来要走向科研岗位,我存在的意义和价值——这部分是AI无法替代的。
结语
从“求人跑数据”到“AI自主分析”,林华英的实践告诉我们:OpenClaw不是要取代研究者,而是让实验背景的研究者也能跨越编程鸿沟,把精力留给更重要的科学判断。