 夜雨聆风
夜雨聆风





OpenClaw+Peekaboo,AI操作电脑这件事成了
做自动化的人应该都踩过同一个坑:脚本录好时跑得挺顺,第二天打开电脑,弹窗偏了几个像素,全崩了。
问题的根儿不在脚本写得不够好,而在于你把界面当成一张图去匹配。截图变一点、分辨率切一下、UI换个主题,底层匹配逻辑就全线溃败。这是像素级方案的先天缺陷,修修补补解决不了。
OpenClaw是一套智能体平台,核心能力是消息接口:用户在Telegram、Slack这类IM里发指令,它接住、理解、拆解成子任务,然后调度执行。
问题在于,它调度了一圈,最后发现没东西能真正替你动手操作屏幕。它能回消息告诉你“先点这个,再填那个”,但没法自己动。手和眼睛,它都没有。

Peekaboo v3就是被设计来充当这双“眼和手”的。两者的关系很清晰:OpenClaw管大脑,负责任务规划和调度;Peekaboo管执行,负责在本地macOS桌面上完成屏幕感知和键鼠操作。
用户发一条指令,OpenClaw拆成步骤丢给Peekaboo,Peekaboo干完活把结果回传,OpenClaw再决定下一步。两者合在一起,才能把“聊天框”变成“遥控器”。
Peekaboo在本地干活的方式,和传统的截图定位有本质区别。它不依赖截图去猜坐标,而是利用macOS系统级的辅助功能接口,先把当前的窗口、按钮、输入框等UI元素全部解析出来,构成一棵结构化的元素树。
然后给每个可交互元素打上数字标签,生成一张带标注框的截图。模型看到的不再是“某处有一片蓝色”,而是“标注#12是一个名为‘确认’的按钮,状态可点击”。
这一步把操作逻辑从坐标轴搬到了语义层。模型返回的指令不再是(x=342,y=518),而是点击#12。窗口拖到屏幕哪个角落、显示器分辨率怎么变,只要那个按钮还在,#12这个索引就不会丢。
打个比方。你用手机拍了一张电梯面板的照片发给朋友,让他照着照片去按按钮。朋友到了真实的电梯前,站位和角度跟你拍照时不一样,他得重新估摸每个按钮的位置。截图方案就是每次都重新估摸一遍。
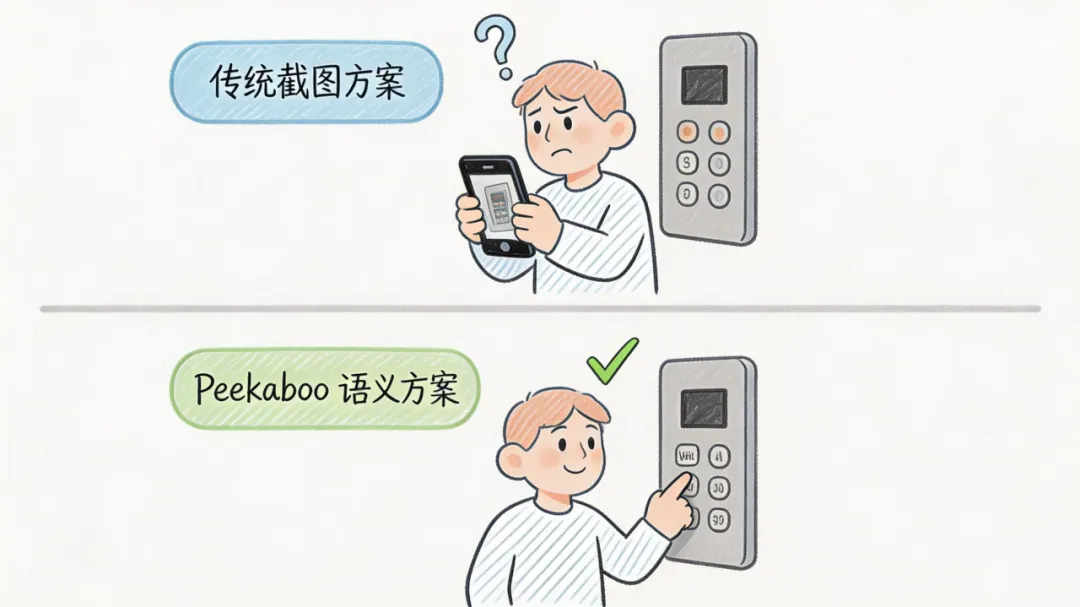
而Peekaboo的做法相当于告诉朋友:别管站位,认准按钮上写的字,直接按。这个“认字”的能力,来自它对UI元素树的解析——它不是在看一张图,而是在读一份界面说明书。
在国内,实在智能的技术路线在底层逻辑上与此相通。他们的ISSUT屏幕语义理解技术同样不靠像素匹配,而是解析UI元素的层级结构,把界面翻译成带语义标签的元素节点。两者都做了一件事:先把“屏幕上有什么”从像素问题变成数据结构问题,再去做操作。
区别在于定位和工程路径。Peekaboo是个人开发者维护的开源工具,设计上保持轻量,不绑定特定模型,你可以接GPT也可以接Claude,适合自己折腾和定制。实在智能则是把屏幕理解、自家TARS大模型和RPA执行引擎整合成一个端到端的企业平台,面向银行、政务这类对合规和稳定性要求苛刻的场景,提供的是全流程的标准化方案。
打个比方:Peekaboo像一套精密外科工具,你用哪把刀、配什么无影灯,自己说了算;实在智能是一家提供全流程手术方案的医疗机构,从诊断到执行到术后监测全包。两种路线没有高下之分,只是面向的用户和场景不同。
Peekaboo最近的版本迭代都集中在v3.1.x,没加花哨的新功能,主要在修三件事:权限适配、模型兼容和操作延迟同步。
权限这块,macOS对屏幕录制和辅助功能权限的管控在近几个版本里不断收紧,工具需要在不同系统版本下处理好权限申请和降级策略。
模型兼容指的是,不同大模型对结构化元素描述的解析能力差异很大,需要反复调提示词和输出格式约束,才能让这套标注协议在一系列主流模型上都有稳定的表现。
延迟同步是最容易被忽视但最容易出问题的环节——点击一个按钮后,新页面需要渲染时间,如果上一帧和下一帧之间没有状态校验,工具就会在页面还没加载完时试图点击下一个目标,直接报错。
这些问题单个拎出来都不起眼,但它们决定了工具是只能跑一次Demo,还是能稳定运行一整天不出错。
整体来看,这条路还在早期。但方向清楚:大模型负责理解和规划,本地代理负责感知和执行,中间用一套稳定的元素描述协议来对接。
说到底是把AI操作电脑这件事,从“能不能操作”推进到“能不能操作得对”。
求点赞

求分享

求喜欢
