夜雨聆风
夜雨聆风





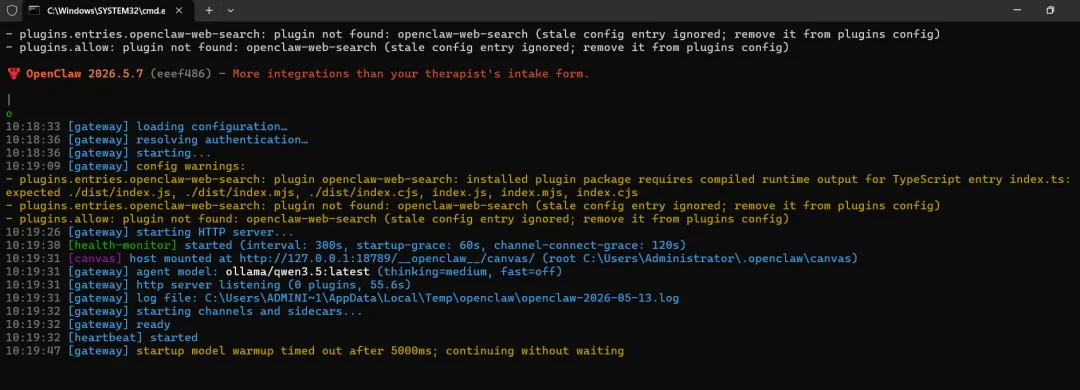
OpenClaw、Claude Code、Codex等AI自动化工具 Ollama都支持,但我我劝你为啥不要装!
Ollama 就像是一个“本地模型管家”,能帮你把各种强大的AI编程工具(如OpenClaw、Claude Code、Codex)都接上免费、私密的本地大模型。最关键的是,官方和社区在2026年都推出了一键启动的集成方式,配置已经变得非常简单。
下面是这些工具与Ollama集成的最新方法和核心特点。
🛠️ 三大编程工具与Ollama集成速览
| 编程工具 | 核心集成方式 | 主要用途与特点 | 关键配置 |
|---|---|---|---|
| OpenClaw | openclaw onboard 向导 |
自动化智能体,可执行系统级任务(文件操作、程序控制),适合7×24小时无人值守运行。 | API Base URL: http://127.0.0.1:11434/v1API Key: 任意非空字符串 模型ID: 你自定义的模型名 |
| Claude Code | ollama launch claude 或 环境变量 |
官方编码助手,集成后可在断网或不想消耗API额度时使用本地模型。 | 环境变量:ANTHROPIC_BASE_URL=http://localhost:11434ANTHROPIC_AUTH_TOKEN=ollama启动命令: claude --model <你的模型名> |
| Codex | codex --oss |
OpenAI的编码CLI工具,能读、写、执行代码,适合在终端中完成编码任务。 | 直接使用命令 codex --oss 即可,默认使用本地 gpt-oss:20b 模型。 |
🚀 给初学者的“一句话”启动指南
如果你对这些工具还不太熟悉,可以从阅读官方文档和从轻量级工具开始这两个方面着手:
-
OpenClaw + Ollama:这是目前资料最详尽的组合,非常适合入门。你可以参考阿里云开发者社区的文章或Apifox的教程,它们都提供了从安装到配置的完整步骤。尤其推荐使用
openclaw onboard命令,这个交互式向导会一步步引导你完成配置,非常省心。 -
Prism(新工具):如果你想体验更轻量、纯粹的编码辅助,可以试试Prism。它就是一个为Ollama量身定做的编码助手,安装后只需在终端输入
prism就能立刻开始使用,无需任何复杂配置。
💡 核心配置要点与技巧
无论使用哪个工具,有几个共同的“坑”可以提前避开:
-
API地址有讲究:配置
API Base URL时,务必注意不要添加/v1后缀。正确的地址格式是http://127.0.0.1:11434。添加/v1可能会破坏工具调用等高级功能。 -
API Key是“假”的:因为Ollama是本地服务,所以
API Key字段可以随意填写,比如填ollama或123都行,但不能留空。 -
模型上下文要够大:为了让AI能更好地理解你的整个项目,建议设置模型的上下文窗口为32,768 tokens或更大。这可以通过创建
Modelfile来实现。 -
注意代理冲突:如果你电脑开了代理,可能会遇到
Connection error。这时需要在终端先关闭代理(unset https_proxy http_proxy),再启动Claude Code等工具。
🔧 进阶玩法:让本地模型“动”起来
除了基础的对话和编码,Ollama还能让你的AI工具“操作”外部软件,实现真正的自动化:
-
通过MCP协议(模型上下文协议):这是目前最“时髦”的集成方式。通过像Composio这样的平台,你可以让你的AI助手(通过OpenClaw、Claude等)具备调用外部工具的能力。
-
能做到什么? 比如,你可以让AI“去我的Notion里整理明天的待办事项”,或者“从GitHub上拉取最新的代码”。AI会通过MCP服务器,自己去操作这些软件来完成你的指令。
-
如何实现? 你需要在OpenClaw或Codex中安装对应的插件,并通过Composio的仪表盘授权连接你的各种应用(如Notion、GitHub、Slack等)。
📊 模型选择参考
在开始之前,可以根据你的硬件配置选择合适的模型。以下是一个通用的参考建议:
| 你的内存 (RAM) | 推荐本地模型 (Drafter) |
|---|---|
| ≤ 12 GB | llama3.2:1b |
| 12 – 24 GB | llama3.2:3b |
| 24 – 48 GB | qwen2.5-coder:7b |
| ≥ 48 GB | qwen2.5-coder:14b |
此外,除了上面提到的模型,像 glm-4.7-flash、deepseek-r1:14b 等也都是近期社区里口碑不错的编码模型。
Ollama 的常用命令按功能分类如下:
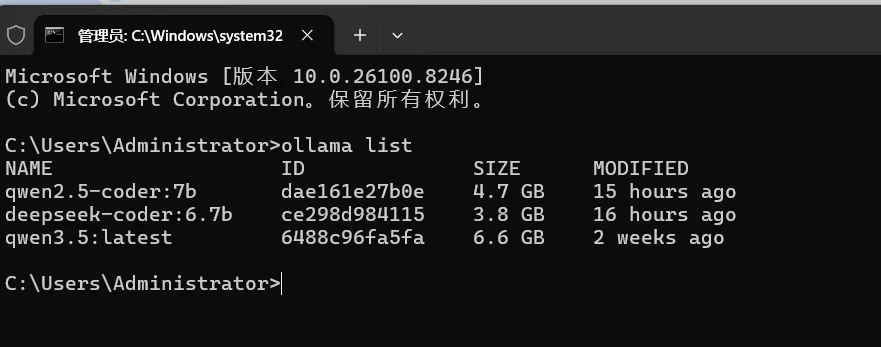
📦 Ollama模型管理
| 命令 | 说明 | 示例 |
|---|---|---|
ollama list |
列出本地已下载的所有模型 | ollama list |
ollama pull <模型名> |
下载模型到本地(再次执行即更新) | ollama pull qwen2.5-coder:7b |
ollama run <模型名> |
运行模型,进入交互式对话 | ollama run deepseek-coder:6.7b |
ollama rm <模型名> |
从本地删除指定模型 | ollama rm llama3.1:8b |
ollama cp <源> <目标> |
复制模型(用于创建自定义变体) | ollama cp my-model:latest my-model:backup |
ollama show <模型名> |
查看模型的详细信息(参数、模板等) | ollama show qwen2.5:7b |
ollama search <关键词> |
在官方仓库搜索可用模型 | ollama search qwen |
🚀 Ollama服务与运行
| 命令 | 说明 | 示例 |
|---|---|---|
ollama serve |
手动启动 Ollama 后台服务 | ollama serve |
ollama create <名称> -f <文件> |
从 Modelfile 创建新模型 | ollama create my-model -f ./Modelfile |
ollama push <模型名> |
将本地模型推送到仓库 | ollama push myuser/my-model:latest |
💬 交互式对话命令(ollama run 模式内)
| 命令 | 说明 |
|---|---|
/bye 或 Ctrl+D |
退出对话 |
/list |
列出当前会话中加载的模型信息 |
/save <名称> |
将当前对话状态保存为新模型 |
/set |
设置参数(如温度、上下文长度等) |
Ctrl+C |
中断当前生成 |
⚙️ Ollama环境与调试
| 命令 | 说明 |
|---|---|
ollama --version |
查看 Ollama 版本号 |
ollama --help |
查看帮助信息 |
ollama ps |
查看当前正在运行的模型进程 |
ollama stop <模型名> |
停止正在运行的模型 |
📝 Ollama常用组合示例
bash
# 查看本地有什么ollama list# 下载并运行ollama pull qwen2.5-coder:7bollama run qwen2.5-coder:7b# 清理空间ollama rm llama3.1:8b# 查看模型详情(决定要不要下载)ollama show llama3.1:8b