 夜雨聆风
夜雨聆风





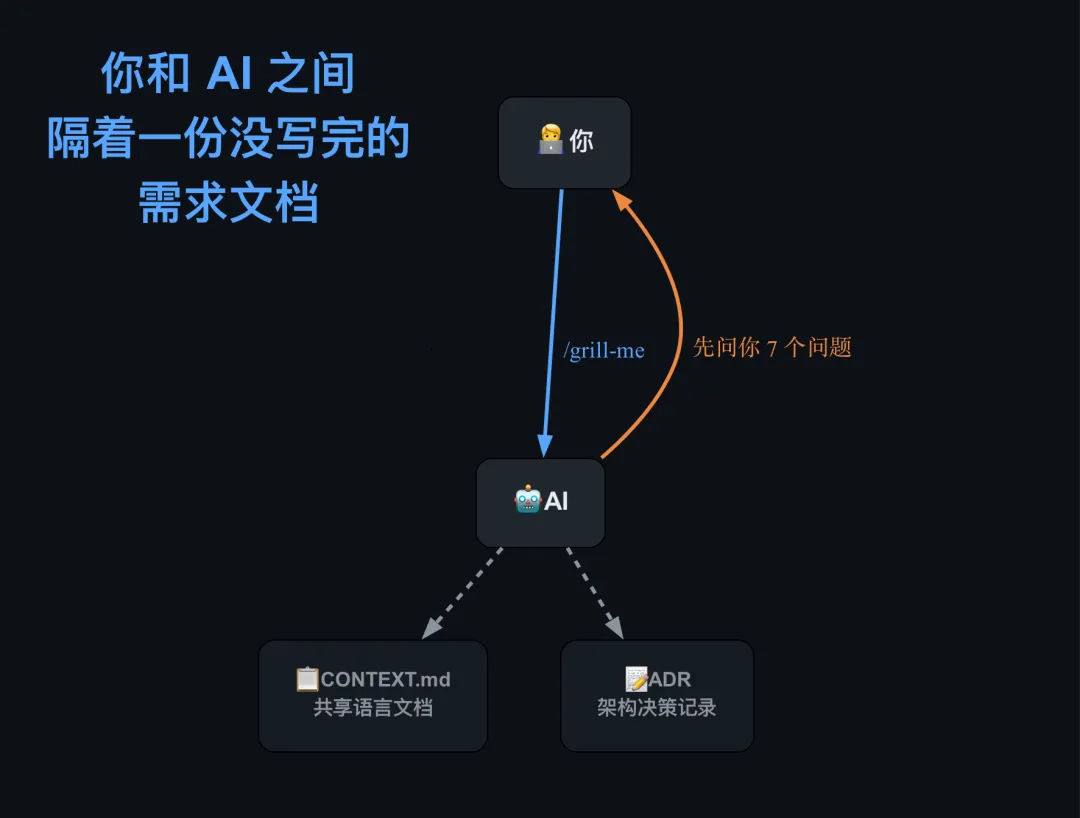
你和 AI 之间,隔着一份没写完的需求文档
blue桃之夭夭 · 2026年5月13日
你和 AI 之间,隔着一份没写完的需求文档
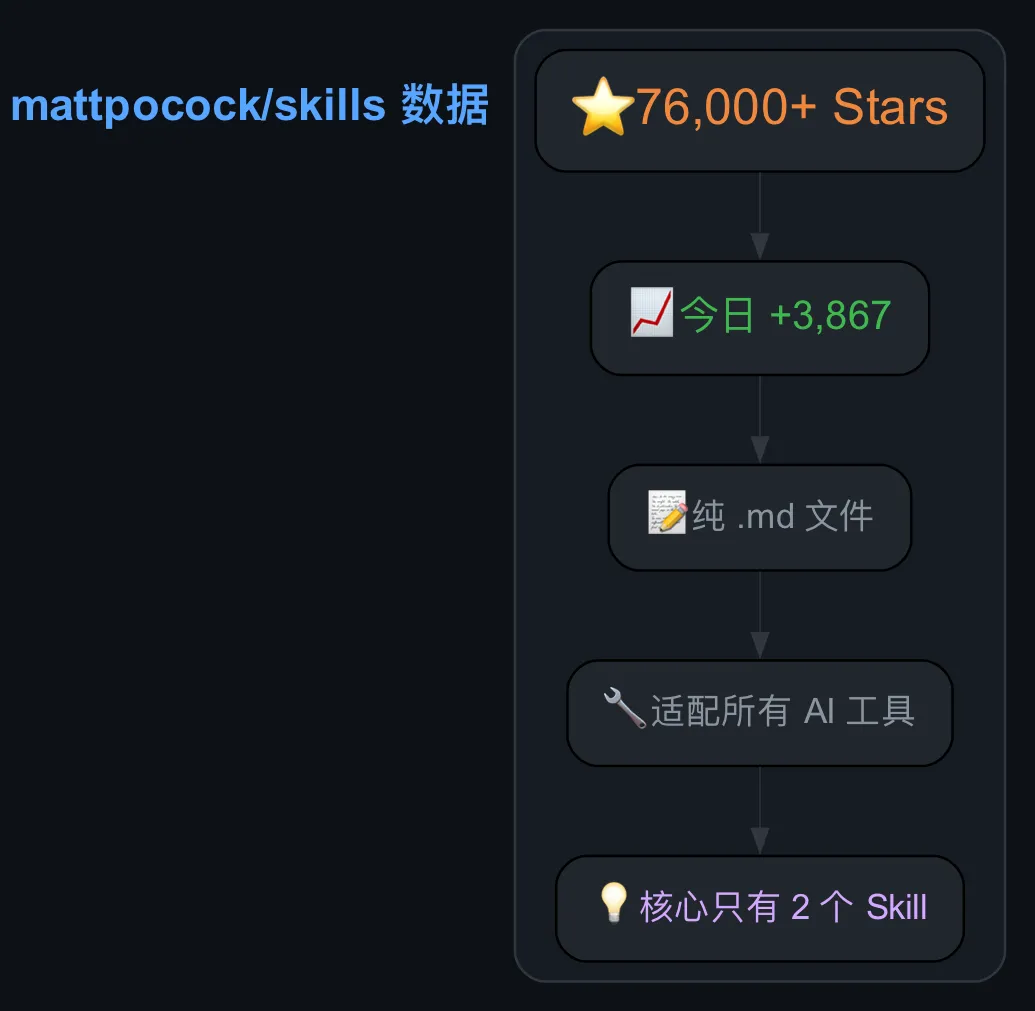
最近 GitHub Trending 榜上冒出一个仓库,两天涨了七万多 star。不是又一个大模型,不是又一个 Agent 框架,而是一堆 .md 文件。
仓库叫 mattpocock/skills,作者 Matt Pocock——如果你写 TypeScript,大概率看过他的《Total TypeScript》系列教程。这次他做的事情很有意思:他不是在教 AI 写代码,而是在教你怎么跟 AI 说话。
— · —
问题不是 AI 不够聪明,是你没说清楚
过去一年,AI 编程助手的能力突飞猛进。Claude 能写完整个 React 组件,Cursor 能跨文件重构,Copilot 能猜到你下一行要写什么。但你有没有发现一个诡异的现象——
AI 越强,你越容易被它带跑。
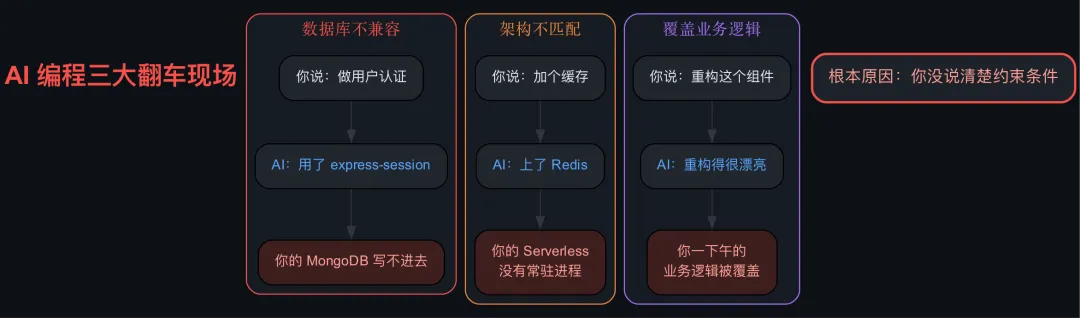
你让它做一个用户认证模块,它噼里啪啦写了一堆代码,看起来很专业,你点了”接受”。三天后发现它用的方案跟你的数据库架构根本不兼容。你问它为什么这么选,它说”这是最常见的做法”。
你让它给你的 API 加缓存,它直接上了 Redis。但你的项目是个 serverless 架构,根本没有常驻进程。你看着满屏的 redis.createConnection() 陷入了沉思。
你让它重构一个组件,它重构得很漂亮,但把你花了一下午写的业务逻辑覆盖了。你没有告诉它哪些文件不能动,它也不知道要问。
问题出在哪?不是 AI 不行,是你在一开始就没有把你的约束条件说清楚。你以为它懂了,它以为你懂了,两边在各自的世界里自嗨。
Matt Pocock 把这个叫做“沟通错位”(misalignment)。他观察了大量 AI 编程的失败案例后发现,绝大多数问题不是模型能力不足,而是人在下达指令时遗漏了关键上下文。模型能力的上限很高,但你给的输入质量决定了实际输出的下限。

— · —
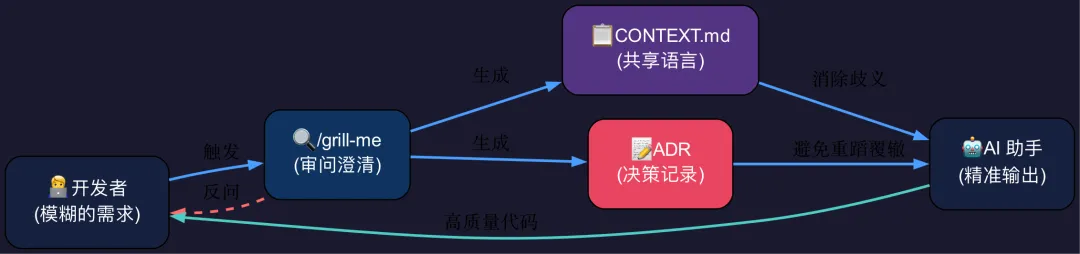
/grill-me:让 AI 先审问你
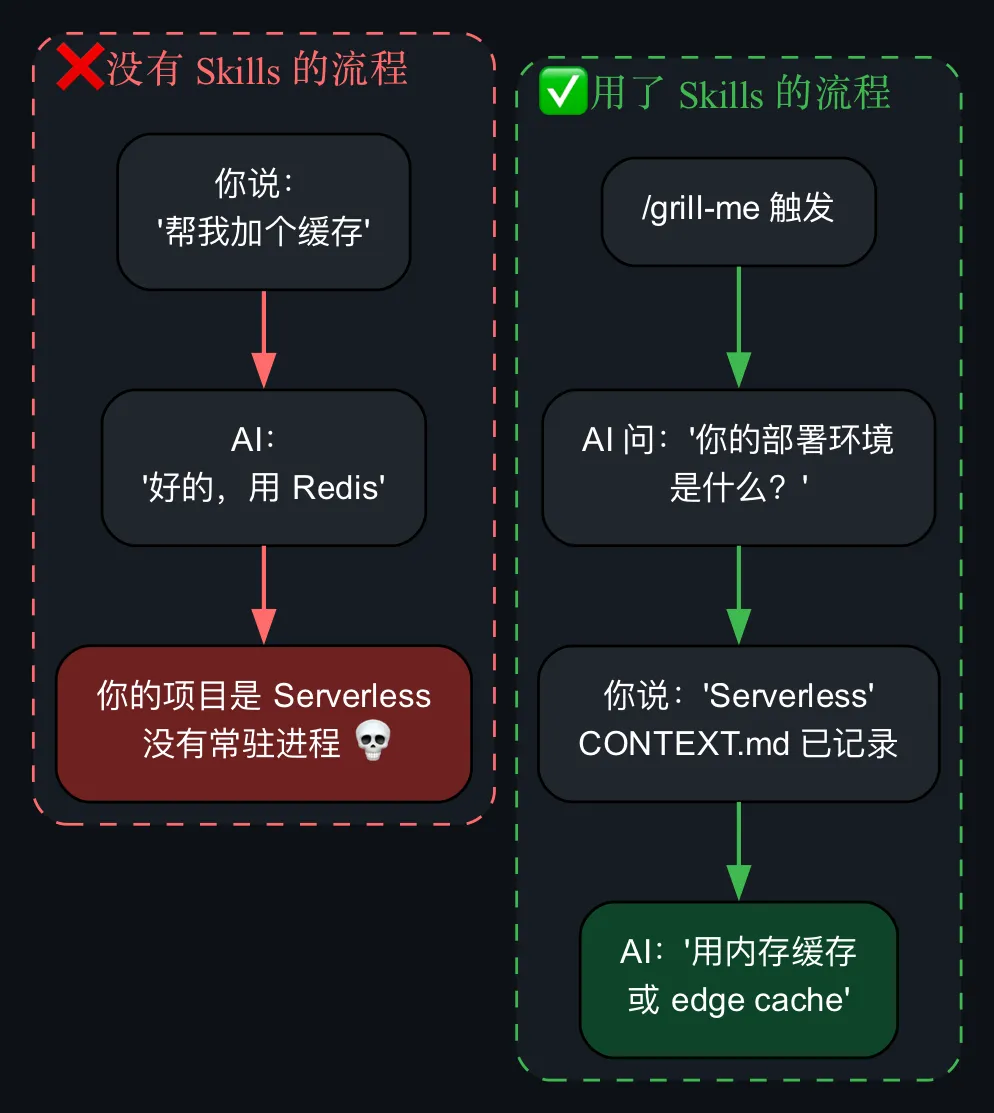
skills 仓库里最核心的一个 skill 叫 /grill-me。
用法很简单:当你准备让 AI 帮你干一件事之前,先跑 /grill-me。AI 不会立刻动手,而是会反过来审问你——
🎯 你的目标用户是谁?
🎯 你希望结果看起来是什么样的?
⚠️ 有什么硬性约束?
⚠️ 你之前试过什么,为什么没成功?
📋 你的技术栈是什么版本?
📋 有没有参考的实现或设计稿?
这些问题不是模板化的问卷,而是根据你给的上下文动态生成的。它在做的事情本质上是:在动手之前,把隐性需求变成显性需求。
我们做工程的人都知道,需求文档最大的敌人不是”没写”,而是”写了但写得模糊”。产品经理说”要一个流畅的用户体验”,开发理解成”页面切换加个 fade 动画”,产品经理实际想要的是”首屏加载不超过 1.5 秒”。AI 面对的也是同样的问题,只不过它连追问的机会都不会主动抓住——除非你告诉它要先问。
它还有一个变体叫 /grill-with-docs,专门用于代码场景。它在审问你的同时,会帮你自动生成两样东西:
📋 共享语言文档(CONTEXT.md)——项目的”方言词典”
📝 架构决策记录(ADR)——记录”为什么这样做”
— · —
共享语言:给 AI 一本你项目的”方言词典”
你有没有遇到过这种情况:你跟 AI 说”把用户信息存到 session 里”,它给你搞了个 express-session 的实现。但你的项目用的是 Next.js,你所谓的”session”其实是 NextAuth 的 JWT token。
这不是 AI 的错。同一个词,在不同项目里含义完全不同。
❌ 你说”组件”→ AI 不知道是 React 组件、Web Component、还是 npm 模块
❌ 你说”部署”→ AI 不知道是 Vercel、Docker、还是 EC2
❌ 你说”测试”→ AI 不知道是 Jest、Vitest、还是 Playwright
❌ 你说”用户”→ AI 不知道是 users 表、Firebase Auth、还是 UserEntity 类
每一个歧义都可能导致 AI 输出一段完全对不上你项目实际架构的代码。而且这种错误特别隐蔽——代码能跑,语法没问题,但跟你的项目格格不入。
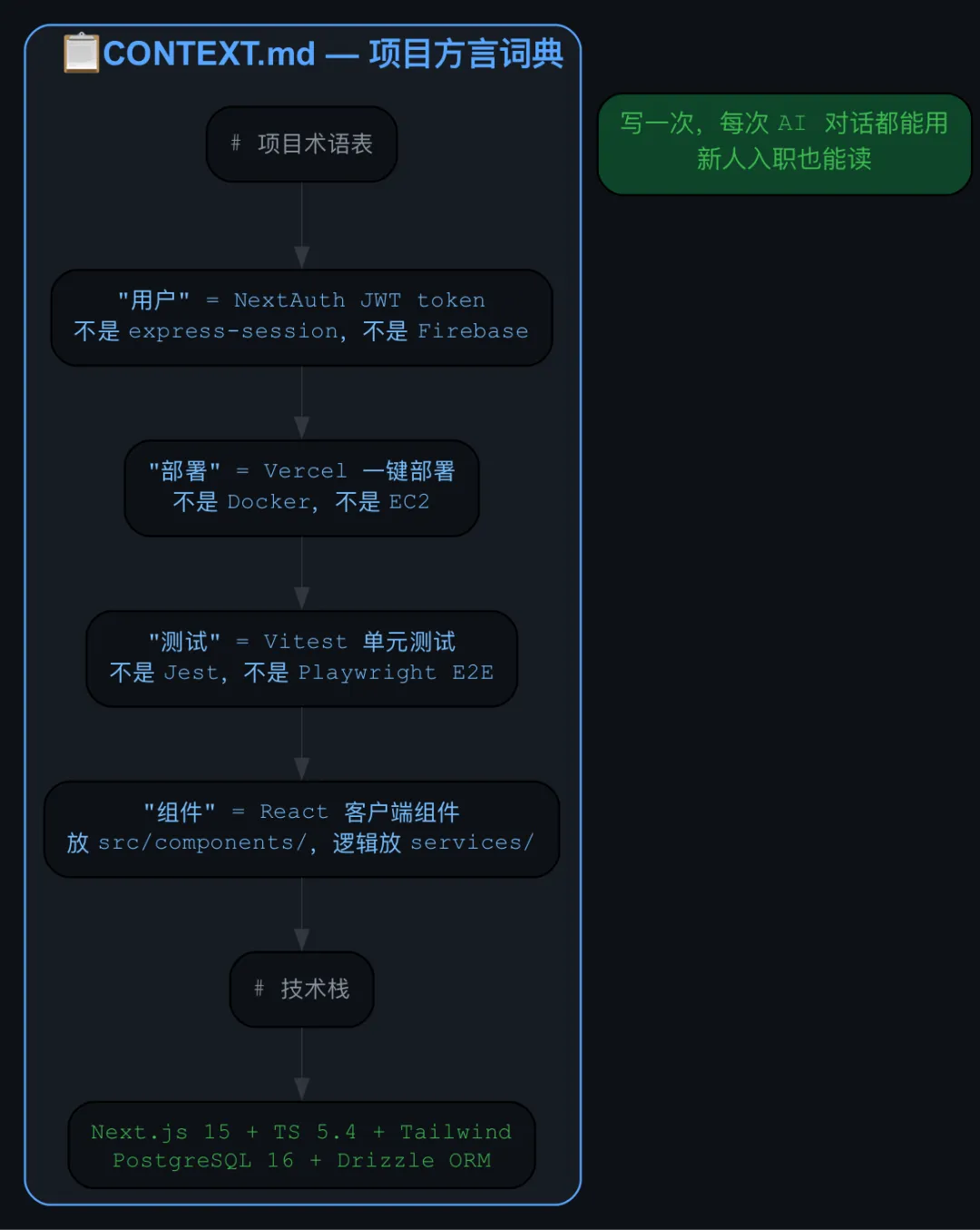
CONTEXT.md 的价值在于:它把项目里的歧义消灭在对话开始之前。你不需要写一本百科全书,只需要把那些”团队内部不需要解释,外部一定会误解”的概念写清楚。一份好的 CONTEXT.md 通常不超过 200 行,但它能让 AI 的输出质量提升一个量级。
— · —
ADR:让 AI 不再重复犯错
另一个关键产物是 ADR(Architecture Decision Record)——架构决策记录。
ADR-007:选择 PostgreSQL 而非 MongoDB
决策日期:2025-03-15
背景:需要存储复杂的关联数据,有多表查询需求
决策:使用 PostgreSQL
理由:数据模型是关系型的,MongoDB 的嵌套文档方案会导致大量冗余
当 AI 读到这份记录后,它就不会在你让它优化查询时建议你”换成 MongoDB 以获得更好的灵活性”。
更糟糕的是,你可能已经忘了当初为什么否决。三个月前你选了 Zustand 而不是 Redux,当时有充分的理由,但现在你只记得”好像当时有人说 Zustand 更轻量”。AI 建议你换回 Redux 时,你居然开始动摇了。
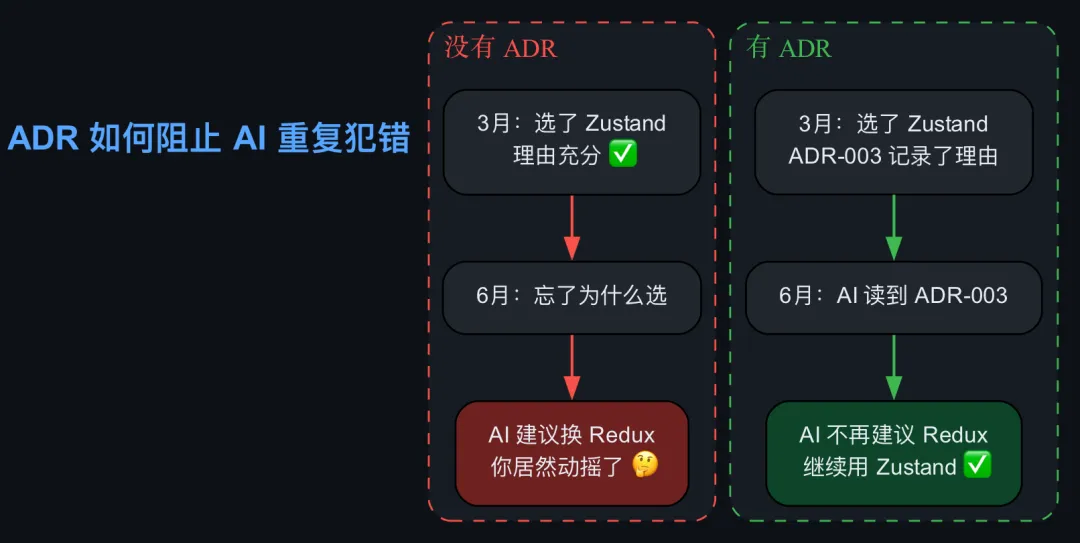
ADR 的本质是:把”为什么”固化下来,
让 AI(和未来的你)不用每次都从头推理。
— · —
安装和使用

说了这么多原理,实际操作其实很简单:
npx skills@latest add mattpocock/skills
这条命令会把 skill 文件下载到你项目的 .skills 目录下。这些 skill 不是插件、不是依赖,就是纯文本的指令文件,任何支持自定义指令的 AI 工具都能用——Cursor、Windsurf、Claude Code、Copilot,通吃。
💡 设计哲学
小、可组合、不绑定任何特定工具。没有复杂的配置,没有 vendor lock-in,没有任何黑魔法。就是一些写得很好的 markdown 文件,告诉 AI “在动手之前先做这些准备”。
仓库里还有其他一些 skill,比如帮你写 commit message 的、帮你做 code review 的,但核心价值就在 /grill-me 和 /grill-with-docs 这一对。它们解决的是 AI 编程最底层的问题:信息不对称。
— · —
为什么这比又一个 Agent 框架更重要

过去一年我们见过太多”革命性”的 AI 编程工具了。从 Copilot 到 Cursor,从 Devin 到 SWE-agent,从 Bolt 到 Lovable,每个都在比谁的模型更强、谁的上下文窗口更大、谁的 agent 更自主、谁的 UI 更炫。
但 Matt Pocock 做了一件反直觉的事:他把问题拉回到了人的这一侧。

skills 仓库的 7.6 万 star 不是因为它技术多牛,而是因为它戳中了一个大家心知肚明但没人愿意面对的事实:我们总在要求 AI 聪明一点、再聪明一点,却很少要求自己想清楚一点、再说清楚一点。
— · —
一点冷思考
当然,这套方案也不是万能的。
1. 取决于你的回答质量。如果你自己都不确定要什么,AI 审问你也是白审问。它能把模糊变清晰,但不能把无知变有知。
2. 需要长期维护。项目在变,架构在演进,CONTEXT.md 和 ADR 如果半年不更新,反而会误导 AI。
3. 更适合有工程经验的人。如果你是完全的新手,连”我需要什么”都说不出来,被 AI 问住反而是一件好事——至少你知道了自己不知道什么。
4. 安全性问题。任何人都可以发布 skill 文件,里面如果包含恶意指令,你可能根本不会注意到。从别处下载的 skill 一定要先审阅内容。
但这些问题不改变核心判断:这是目前最实用的 AI 编程提效方案之一。不是因为它多复杂,恰恰是因为它太简单了——简单到你一看就懂,一用就有效,然后会想”为什么我之前没想到”。
— · —
写在最后
AI 编程工具的竞争正在从”模型能力”转向”人机协作方式”。谁能让人类更高效地把脑中的想法翻译成 AI 能理解的指令,谁就赢了。
BLUE桃之夭夭
有时候,最好的工程
不是写更聪明的代码
而是写更清楚的文档。
这一点,对人和对 AI 都一样。
— END —