 夜雨聆风
夜雨聆风





Ctx2Skill:让大模型从文档中"自学成才"——一篇论文读懂上下文技能发现
2026年4月,来自清华大学、DeepLang AI、UIUC、复旦大学和香港中文大学的研究团队发表了一篇论文:“From Context to Skills: Can Language Models Learn from Context Skillfully?”,提出了 Ctx2Skill 框架——一个无需人工标注、无需外部反馈的自进化技能发现系统。
这篇文章,我带你深入拆解它的核心原理。

一、什么是”上下文学习”?为什么它很重要?
我们日常使用大模型时,大多数任务都落在参数知识的覆盖范围内——模型在预训练阶段就已经”见过”相关知识。数学题、编程题、常识问答,大体如此。
但现实世界中,大量任务要求的知识不在训练数据里:
-
医生需要阅读最新发布的临床指南来调整治疗方案 -
工程师需要阅读从未见过的产品文档来执行安装步骤 -
研究人员需要从实验数据中归纳规律、形成假设
论文将这种能力定义为 Context Learning(上下文学习)——让语言模型从给定的复杂上下文中直接学习新知识,并据此推理和解决任务。注意,这和我们常说的 In-Context Learning(ICL)不同:ICL 是让模型通过 few-shot 示例学习任务模式,而 Context Learning 要求模型从内容本身提炼规则和知识。
腾讯混元团队在 2026 年初发布的 CL-bench 基准测试揭示了这一问题的严峻性:即使是 GPT-5.1,在 CL-bench 上的整体解题率也只有 21.1%。大模型离”真正读懂陌生文档”还有很长的路要走。
二、核心思路:推理时技能增强
一个直观的想法是:能不能把长文档里的规则和流程”提炼”成一套技能(Skill),然后注入到模型的提示中?
这就是 推理时技能增强(Inference-time Skill Augmentation) 的思路——从上下文中提取可复用的程序性知识,编码成自然语言的 Skill 文件,在推理时前置到系统提示中。
这个思路已被 Anthropic 等团队的实践证明是有效的——编码 Agent、网页导航 Agent 等场景都有成功案例。
但问题来了:在上下文学习场景中,这个思路遇到了两个根本性挑战。
三、两大核心挑战
挑战 1:人工标注成本不可承受
现有的 Agent Skill 库(如 Anthropic 的官方 Skill 体系)主要靠人工编写。但在上下文学习场景中,上下文文档通常很长、技术密度高、领域专精。要求标注者完全内化一份复杂的多章节文档,然后编写出高质量的 Skill,既耗费认知资源又不经济——根本无法规模化。
挑战 2:没有外部反馈信号
在代码或数学推理等场景中,Skill 的质量可以通过执行结果或标准答案来评估。但上下文学习任务没有这种自动反馈——给定一份文档和一个问题,没有外部系统能告诉你”生成的 Skill 是否忠实、完整地捕获了文档知识”。
这两个挑战意味着:我们需要的不是人工标注,也不是依赖执行反馈,而是一种完全自监督的技能发现机制。
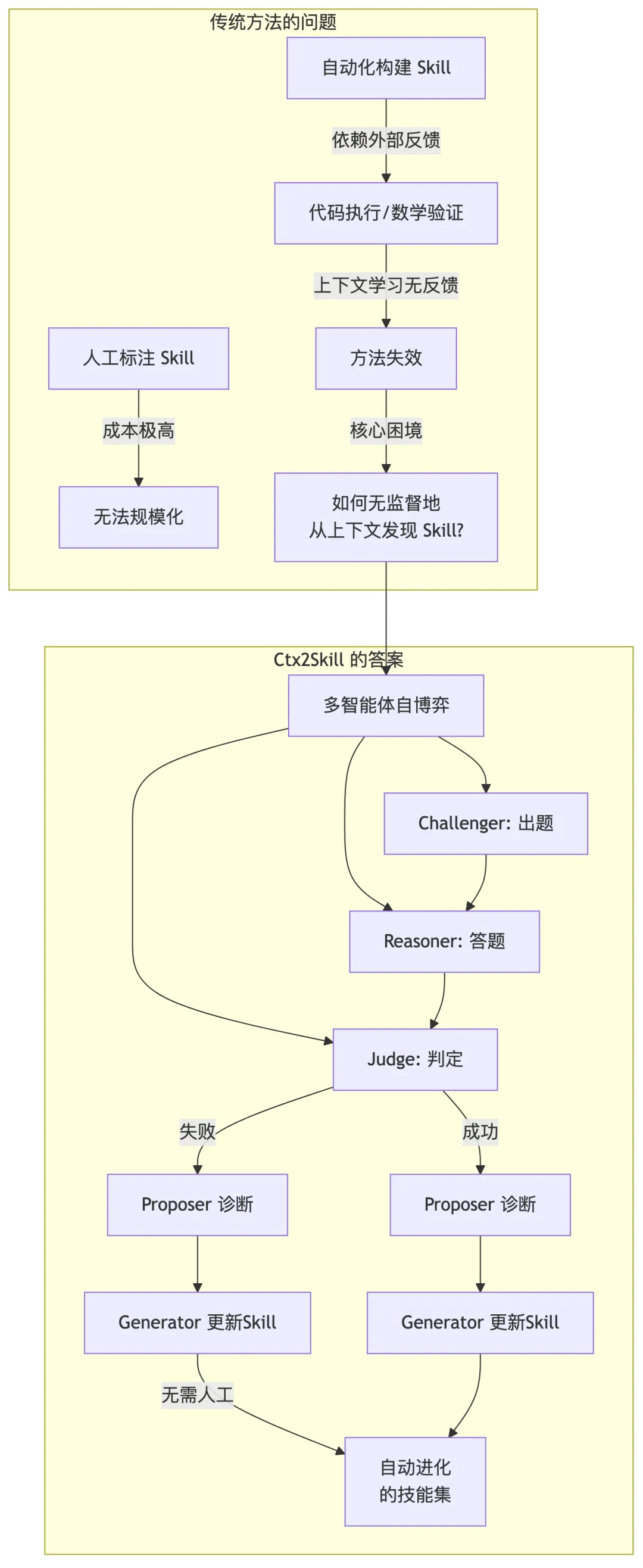
四、Ctx2Skill:多智能体自博弈框架
Ctx2Skill 的核心设计是一个多智能体自博弈循环(Multi-Agent Self-Play Loop)。它的灵感来自强化学习中的 Self-Play(比如 AlphaGo),但有一个关键区别——模型参数完全冻结,进化的不是权重,而是自然语言的 Skill。
4.1 五个角色
框架定义了五个智能体角色:
| 角色 | 功能 | 进化方向 |
|---|---|---|
| Challenger(挑战者) | 根据上下文生成任务和评分标准 | 生成越来越刁钻的任务 |
| Reasoner(推理者) | 在技能集指导下尝试解题 | 积累越来越多的上下文知识 |
| Judge(裁判) | 严格按评分标准判定通过/失败 | 不进化(保持中立) |
| Proposer(诊断者)× 2 | 分析失败/成功案例,诊断问题 | — |
| Generator(生成者)× 2 | 根据诊断结果更新技能集 | — |
4.2 自博弈循环流程
每一轮迭代的工作流程如下:
关键设计要点:
-
双方对抗进化:Challenger 和 Reasoner 各自维护独立的技能集,互相看不到对方的技能,保持严格的对抗关系 -
失败驱动更新:Reasoner 的失败案例被用来诊断”缺少了什么上下文知识”,进而更新 Reasoner 的技能集;Challenger 的成功案例被用来诊断”题目出得太简单”,进而强化 Challenger 的出题策略 -
诊断与生成分离:Proposer 负责”分析为什么失败/成功”,Generator 负责”把诊断结果转化为具体的 Skill 内容”。论文发现,将这两个角色分开能带来一致的性能提升 -
全部通过才算通过:Judge 采用严格的”全有或全无”评分——只有当答案满足所有评分标准时,任务才算通过

4.3 技能长什么样?
Ctx2Skill 生成的 Skill 是 Markdown 格式的自然语言文档,包含 YAML 头部和结构化正文。一个典型的 Reasoner Skill 可能长这样:
---
skill_name: cross-reference-constraints
skill_description: When the context specifies
inter-dependent constraints across sections
---
## Pre-Answer Checklist
1. Scan for all numerical constraints
mentioned in the context
2. Identify cross-section dependencies
3. List conflicting requirements
## Response Procedure
- Step 1: Extract all constraints into
a structured table
- Step 2: Verify mutual compatibility
- Step 3: If conflicts exist, prioritize
by recency of the context section
## Common Pitfalls
- Ignoring constraints in footnotes
- Treating "should" and "must" equally
这种格式的好处是:可读、可编辑、可审查,人类可以直接检查 Skill 是否正确地反映了文档知识。
五、Cross-Time Replay:防止对抗性崩塌
这是论文中最精巧的设计之一。
5.1 问题:对抗性崩塌(Adversarial Collapse)
随着迭代进行,Challenger 会生成越来越极端的任务,Reasoner 的技能也会越来越”过拟合”这些极端案例——结果是技能集积累了很多冗余条目,泛化能力反而下降。
更致命的是,这种现象在循环内部无法被检测到——每一轮的 Judge 只评估当前轮的新任务,不会告诉你”之前掌握的知识是否被后续的修改破坏了”。
如果直接使用最后一轮的 Reasoner 技能集,效果可能还不如中间轮次的。
5.2 解决方案:Cross-Time Replay
论文提出了一个优雅的解决方案:
在自博弈过程中,自动收集两组”代表性探针”:
-
Hard Probe Set:每轮迭代中,评分标准通过率最低的失败任务 -
Easy Probe Set:每轮迭代中,评分标准数量最少的成功任务
循环结束后,用所有历史技能集重新跑一遍探针,选出平衡性最好的。
具体来说,对第 i 轮的 Reasoner 技能集 S^R_i,计算:
-
rho_h(i) = Hard Probe Set 上的解题率(Laplace 平滑) -
rho_e(i) = Easy Probe Set 上的解题率(Laplace 平滑)
最终选择:i = argmax_i [rho_h(i) x rho_e(i)]*
乘法形式是关键设计——如果一个技能集解决了后期极端案例但退化了简单案例,rho_e 会惩罚它;反之亦然。Laplace 平滑则防止探针集为空时出现除零问题。

实验证实了这个机制的必要性:固定使用第1轮技能得分 15.9%,第5轮降到 14.7%(验证了对抗性崩塌),而 Cross-Time Replay 达到 16.5%,优于任何固定轮次。
六、实验结果:全面提升
6.1 CL-bench 主实验
CL-bench 包含 500 个复杂上下文、1899 个任务和 31607 条评分标准,覆盖四个类别:
| 类别 | 示例 |
|---|---|
| Domain Knowledge Reasoning | 领域知识推理(医学、法律等) |
| Rule System Application | 规则系统应用(评分标准、政策执行等) |
| Procedural Task Execution | 程序性任务执行(工作流、操作步骤等) |
| Empirical Discovery & Simulation | 经验发现与模拟(数据归纳、假设验证等) |
核心结果:
| 模型 | 无 Skill | + Ctx2Skill | 提升 |
|---|---|---|---|
| GPT-4.1 | 11.1% | 16.5% | +5.4% |
| GPT-5.1 | 21.1% | 25.8% | +4.7% |
| GPT-5.2 | 18.2% | 21.4% | +3.2% |
值得注意的是,GPT-4.1 + Ctx2Skill(16.5%)超越了无 Skill 的 Gemini 3 Pro(15.8%)——技能增强甚至可以弥合模型代际差距。
在四个任务类别上,Ctx2Skill 全部领先,提升最大的是 Procedural Task Execution(+7.2%) 和 Empirical Discovery(+5.5%),这两类恰好需要更深层的程序性和归纳推理能力。
6.2 技能质量评估
论文用 GPT-4.1 作为评判者,从五个维度评估生成技能的质量:
| 维度 | 含义 |
|---|---|
| Conciseness(简洁性) | 无冗余,Token 高效 |
| Faithfulness(忠实性) | 不编造事实,基于上下文 |
| Clarity(清晰性) | 结构清晰,语言精确 |
| Effectiveness(有效性) | 真正提升解题率 |
| Reusability(可复用性) | 跨任务泛化,不过度特化 |
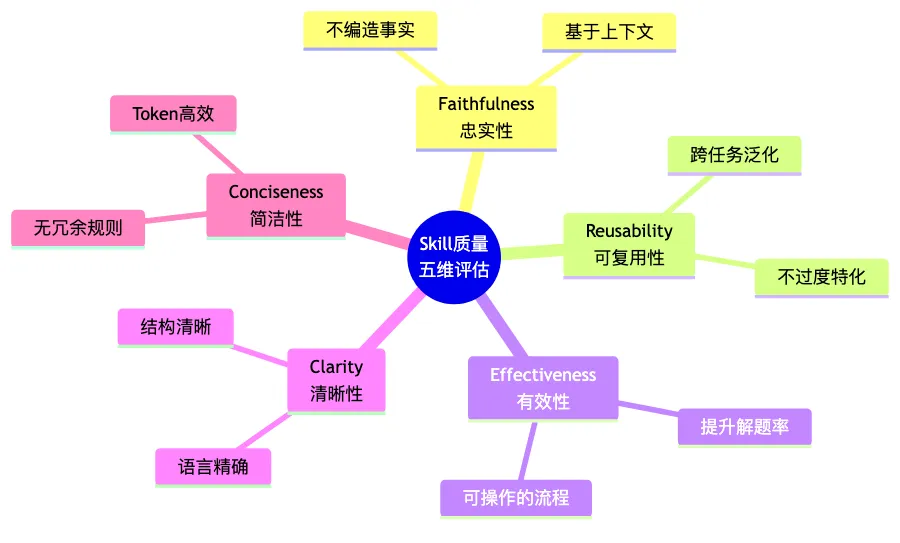
Ctx2Skill 在所有维度上均优于基线方法,平均分达到 93.6(GPT-5.1 基础),其中 忠实性(93.9) 和 清晰性(98.1) 的提升最为显著——这意味着自博弈循环不仅提升了解题率,还产出了人类可审查、高质量的知识编码。
6.3 消融实验
论文做了系统的消融实验,验证每个组件的必要性:
| 去掉的组件 | GPT-4.1 整体得分 | 降幅 |
|---|---|---|
| 完整 Ctx2Skill | 16.5% | — |
| 去掉 Challenger 技能进化 | 13.8% | -2.7% |
| 去掉 Cross-Time Replay | 14.7% | -1.8% |
| 去掉 Hard Probe Set | 15.2% | -1.3% |
| 去掉 Easy Probe Set | 15.7% | -0.8% |
| 合并 Proposer 和 Generator | 15.9% | -0.6% |
Challenger 技能进化是影响最大的组件——没有持续加强的对手,Reasoner 的技能发现能力大幅下降。这也验证了”对抗压力是技能进化的核心驱动力”这一设计哲学。
6.4 技能可迁移性
一个有趣的现象:强模型生成的技能可以迁移到弱模型。
-
GPT-5.1 生成的技能用在 GPT-4.1 上:16.1%(接近 GPT-4.1 自身技能的 16.5%) -
GPT-4.1 生成的技能用在 GPT-5.1 上:23.1%(但低于 GPT-5.1 自身技能的 25.8%)
这种不对称性说明:强模型能发现更深层的上下文知识,这些知识对弱模型也有帮助;但弱模型的认知局限使其无法产出强模型能充分利用的技能。

七、与其他方法的对比
| 方法 | 人工标注 | 外部反馈 | 参数更新 | 迭代优化 |
|---|---|---|---|---|
| 人工编写 Skill | 需要 | 不需要 | 不需要 | — |
| Prompting(单次提取) | 不需要 | 不需要 | 不需要 | 无 |
| AutoSkill4Doc | 不需要 | 交互轨迹 | 不需要 | 弱 |
| SkillX | 不需要 | 执行反馈 | 不需要 | 有限 |
| EvoSkill | 不需要 | 执行反馈 | 不需要 | 失败驱动 |
| SKILL0 | 不需要 | IRL | 需要 | RL |
| Ctx2Skill | 不需要 | 不需要 | 不需要 | 自博弈 |
Ctx2Skill 是目前唯一一个同时满足”零人工标注 + 零外部反馈 + 零参数更新”的技能发现方法。
八、设计哲学的深层思考
读完这篇论文,我感触最深的不只是技术细节,而是几个值得深思的设计哲学:
8.1 进化的对象是”知识”而非”参数”
传统强化学习通过梯度更新让模型”变强”,但 Ctx2Skill 走了一条不同的路——模型权重完全冻结,进化的是外部化的自然语言知识。
这带来了几个独特优势:
-
可解释性:每个 Skill 都是人类可读的文本 -
可编辑性:人类可以直接修改、审查技能 -
可移植性:Skill 可以插拔到任意 LLM -
无需训练:对闭源模型(如 GPT-5)同样适用
8.2 对抗是进化的燃料
论文发现,去掉 Challenger 技能进化会导致最大幅度的性能下降。这验证了一个直觉:持续的对抗压力是发现深层知识的关键。如果对手太弱,你永远不会被迫成长。
这与 AlphaGo 的 Self-Play 异曲同工,但 Ctx2Skill 把”对抗进化”从梯度空间搬到了文本空间。
8.3 早期轮次往往最好
Cross-Time Replay 的实验揭示了一个反直觉的现象:被选中的最佳技能集大多来自早期轮次(而非最后一轮)。这说明技能进化存在一个”甜蜜点”——太早则知识不够全面,太晚则过拟合极端案例。
这也给我们一个启示:迭代优化不一定是越多越好,关键是要有好的选择机制。
8.4 诊断和执行应该分离
Proposer(诊断者)和 Generator(生成者)的分离看起来像是多余的工程复杂度,但消融实验证明它确实有效。这类似于软件开发中”产品经理”和”程序员”的分工——先想清楚”改什么、为什么改”,再动手实现,比一个人边想边做效果更好。
九、局限性与未来方向
局限性
-
计算成本:每轮需要 5 个任务 × 多个智能体调用,单次上下文的技能生成成本不低(好在只需生成一次,后续推理复用) -
迭代轮次有限:受 API 预算限制,论文只跑了 5 轮迭代,可能还有提升空间 -
Judge 依赖:裁判本身使用 GPT-5.1,其判定质量直接影响技能进化方向
未来可能的方向
-
更高效的探针策略:当前每轮只添加 1 个 Hard Probe 和 1 个 Easy Probe,更丰富的探针策略可能带来更好的选择 -
跨上下文技能迁移:从多个相关文档中提取通用技能,构建”技能库” -
与 RAG 结合:Skill 提供推理框架,RAG 提供检索信息,二者互补 -
轻量级蒸馏:将自博弈发现的技能蒸馏到小模型中,降低部署成本
十、总结
Ctx2Skill 提出了一个优雅且实用的框架,解决了上下文学习场景中”如何无监督地发现技能”这一核心问题。它的核心贡献可以概括为三点:
-
多智能体自博弈:Challenger 和 Reasoner 通过失败驱动的文本编辑协同进化,无需人工标注或外部反馈 -
Cross-Time Replay 机制:通过代表性探针回溯评估,防止对抗性崩塌,选出最具泛化能力的技能集 -
即插即用的技能增强:生成的自然语言技能可以注入任意 LLM,弥合模型代际差距
在 CL-bench 上,Ctx2Skill 将 GPT-4.1 从 11.1% 提升到 16.5%,GPT-5.1 从 21.1% 提升到 25.8%——这不是微小的边际提升,而是在一个极具挑战性的基准上取得了实质性进步。
更重要的是,它为我们指明了一个方向:大模型的能力提升,不一定非要靠更大的参数、更多的训练数据——让模型学会从上下文中”自学成才”,可能是更务实、更可扩展的路径。
论文信息
-
标题:From Context to Skills: Can Language Models Learn from Context Skillfully? -
作者:Shuzheng Si, Haozhe Zhao, Yu Lei, Qingyi Wang, Dingwei Chen, Zhitong Wang, Zhenhailong Wang, Kangyang Luo, Zheng Wang, Gang Chen, Fanchao Qi, Minjia Zhang, Maosong Sun -
机构:清华大学、DeepLang AI、UIUC、复旦大学、香港中文大学