 夜雨聆风
夜雨聆风





维护了七年的抖音下载工具,AI帮我补齐了UI界面
一个维护了七年的抖音视频/图文采集下载工具,支持 10 种采集模式、批量下载、GUI 桌面应用,GitHub 1.6k Star。经历过易语言、requests、Playwright 浏览器自动化等多轮技术方案切换,最近靠 AI 补齐了 UI 短板。
这应该是我维护时间最长的一个开源项目了。
最早是用易语言写的,2019 年开始在吾爱破解论坛发布。2021 年用 Python 重写。
断断续续折腾了七年,v3 版本开始被人熟知,中间放弃维护了很久,直到 v5 版本再次被更多人看到——GitHub 上攒了 1.6k Star、280 Fork,基本就是这两个版本贡献的。
项目现在叫 DouyinCrawler(抖音爬虫),本质上是一个抖音公开数据的采集和下载工具。开源仓库在这:https://github.com/erma0/douyin
版本进化史
这个项目纯玩票性质,基本没什么规划,中间经历过好几次路线切换:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
Playwright 浏览器自动化 |
|
|
|
|
|
|
|
|
|
|
|
v1 & v2:易语言到 Python
2019 年用易语言写了第一版,纯协议直连,功能不太成熟,后来改成 node.dll 模拟浏览器拦截数据。2021 年用 Python 重写(Vue + pywebview + Aria2)。那时候抖音接口很简单,signature 可以固定,requests 直接请求就能拿到无水印地址。
v2 也尝试过写 Vue 界面,也尝试过低代码设计,但效果很勉强。
v2 → v3:搞不定加密,上浏览器
好景不长,抖音开始加接口签名。搞不定加密,那就让浏览器自己处理——v3 切到 Playwright,启动真实浏览器模拟操作,顺带还加了 FastAPI 接口。
v3 → v4:风控逼退,又切回来
浏览器自动化容易触发风控,动不动验证码。刚好那段时间抖音协议调整,一些接口不再需要加密参数了,于是又把 v2 翻出来修了修。
v4 → v5:协议稳定,转向 UI
后来从另一个开源仓库引入了签名逻辑,填补了需要签名接口的缺口。核心逆向 JS 不是我写的,我只是引用。目前本项目有 3 个接口需要签名:单个作品详情、音乐原声、粉丝列表,其余都是普通请求。
这个项目其实没有技术含量,毕竟没做过逆向,只是在持续维护和工程化。
v5 今年:AI 写 GUI
功能层面 v5 已经比较稳定了,但一直缺一个好用的图形界面。这部分我自己写不好——之前试过 Vue,效果勉强。今年开始让 AI 写,效果远超预期。
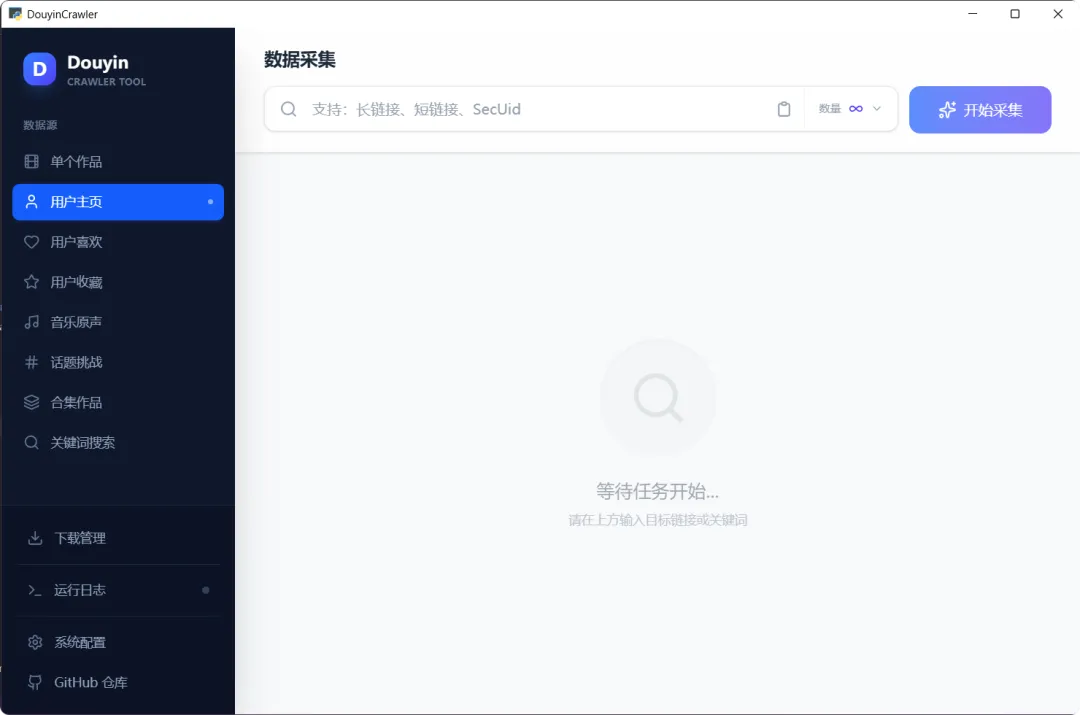
它能做什么?
简单说就是:粘贴一个抖音链接,把视频/图文全部拉下来。
采集模式
支持 10 种采集类型:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
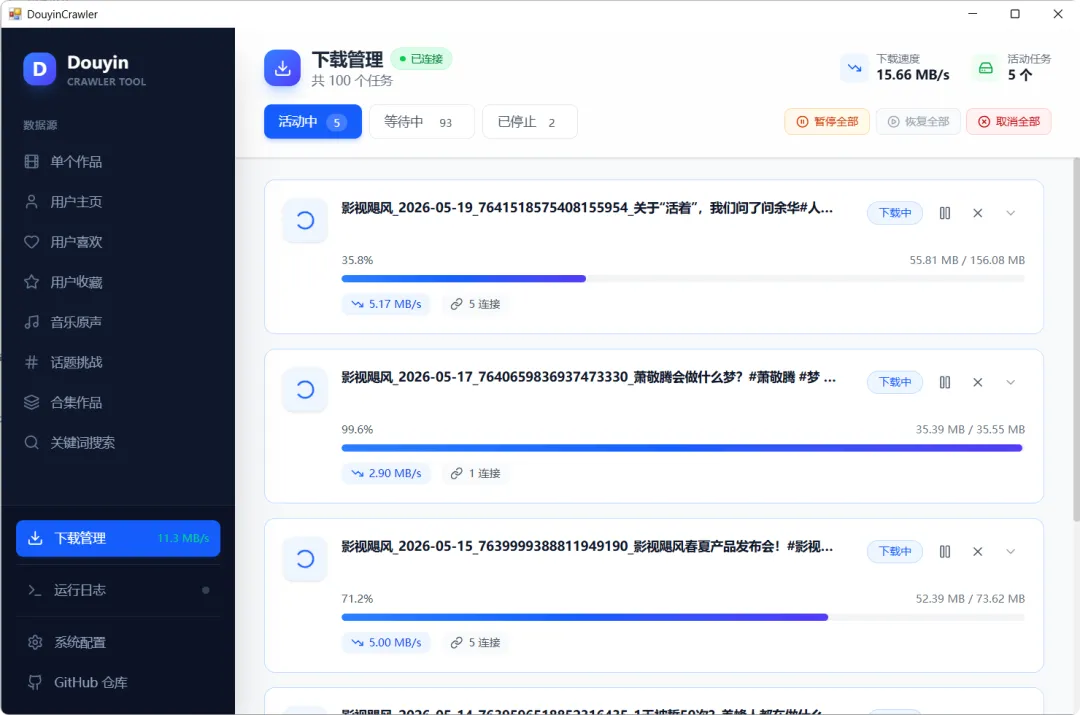
下载能力
集成 Aria2 批量下载,支持并发控制、重试机制、自定义文件名模板,可选同时下载标题文本和封面图。
三种运行模式
|
|
|
|---|---|
| GUI 桌面应用 |
|
| Web 服务 |
|
| CLI 命令行 |
|
界面:从勉强到能用
同类抖音下载工具大多是纯 CLI 命令行,少数有带 GUI 的。
这个项目今年用 AI 重写后,整个 UI 完全达到了可用程度:
架构:Python + FastAPI 做后端,React 18 + TypeScript + Vite 做前端,PyWebView 嵌入 WebView2 做桌面壳。前后端通过 RESTful API + SSE 实时推送通信。
交互:采集进度不再靠看日志,而是通过 SSE 实时推送——服务端每拿到一批新作品,前端立即更新卡片网格。列表用 react-window 虚拟滚动渲染,几千条结果不卡。点开作品卡片是内嵌视频播放器,下载完直接播。
体验细节:首次使用有欢迎向导引导配置 Cookie;搜索支持排序和时长筛选;下载进度面板实时显示 Aria2 状态;托盘通知、错误边界、暗色模式(通过 Tailwind 支持)这些细节虽然不算什么亮点,但堆在一起让工具「能用起来舒服了一些」。
这些功能在真正的专业前端眼里可能不值一提,但对我这个不懂前端的人来说,已经足够强大了。
技术实现
整体架构如下:
REST API
SSE 实时推送
HTTP + Cookie + 签名
JSON-RPC
sessionid / ttwid
采集流程
爬虫核心是个分页循环:通过 max_cursor 游标逐页请求,每页返回一批作品 + 下一页 cursor + has_more 标志,直到 has_more=false 或达到数量上限。
用户主页支持增量采集:首次保存结果 JSON,下次只拉上次 cursor 之后的作品。其余 9 种采集类型逻辑类似,差异主要在请求的 API 端点和参数。
请求层
抖音网页接口通过 HTTP API 返回 JSON。大部分接口带上 Cookie(核心是 sessionid 和 ttwid)就能直接请求,少数几个接口需要额外签名——这部分引用自其他开源项目的 JS 文件,Python 通过 exejs 调用 Node.js 运行时执行。
Cookie 的获取一直没优化好。经历过手动复制 → 自动读取浏览器 → 内置登录窗口三个阶段,目前最推荐手动获取(F12 复制),GUI 模式下也支持内置浏览器登录自动抓取,但效果好像不太行。
部署与构建
GUI 版通过 PyInstaller 打包成单个 exe,配合 GitHub Actions 自动构建发布到 Releases。打包过程中踩过 UPX 压缩导致 DLL 加载失败、strip 优化兼容问题等坑,后来都禁掉了。Nuitka 其实也能打包,本地验证过,只是 CI 里为了省时间没上。
以后还会做自动化方案吗?
可能会。协议方案目前够用,但浏览器自动化的优势是不依赖接口变更和 Cookie 时效。之前 v3 失败在风控,这几年反检测技术在进步,如果 camoufox / ruyipage / CloakBrowser / Obscura 等反检测方案能稳定绕过,可能会再试一版。
下载与运行
-
• GitHub Releases:https://github.com/erma0/douyin/releases(更新及时) -
• 网盘:https://www.lanzoub.com/b00jfit1i
Windows 用户
下载 DouyinCrawler.exe,解压即用。需安装 WebView2 运行时(Win10/11 自带,Win7 可手动安装)。
命令行爱好者
# 采集用户主页前 20 个作品
python -m backend.cli -u https://www.douyin.com/user/xxx -l 20
# 搜索并筛选
python -m backend.cli -u "风景" -t search --sort-type 2 --publish-time 7
# 批量链接
python -m backend.cli -u urls.txt -l 50最后
这个项目没什么高深技术——逆向是别人做的,协议是 HTTP 请求,UI界面是 AI 写的。
v5 的 UI 确实好用了不少,如果你也有一段想加界面但写不出来的老项目,试试让 AI 来写。
开源不易,如果觉得有用欢迎到 GitHub 点个 Star。有问题可以提 Issue,功能建议也欢迎交流。提的需求一般会及时跟进。