 夜雨聆风
夜雨聆风





Skill 文档也能训练?SkillOpt:把 Agent 的经验写进一份可优化说明书

本文解读一篇很适合 Agent 时代读的论文:
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
-
论文地址:https://arxiv.org/abs/2605.23904 -
项目页:https://microsoft.github.io/SkillOpt/ -
代码入口:https://aka.ms/skillopt
一句话总结:
现有 Agent Skill 要么靠人手写,要么让 LLM 一次性生成,SkillOpt 则把 skill 文档当成一份可训练的外部状态,用 rollout、反思、受限编辑、验证门控和拒绝缓冲,做了一套文本空间里的优化器。
先说结论。SkillOpt 做的不是微调模型,也不是让大模型一次性写一段 prompt,而是把 Agent 每天都在用、但经常被当成附属品的 Skill 文档 拎了出来:那些写着“怎么查资料、怎么调用工具、怎么校验结果、怎么组织输出”的小文档,过去通常被我们叫做提示词、说明书或者工作流规范。
这篇论文的判断更往前推了一步:如果 skill 文档会稳定影响 Agent 的行为,那它就不该只靠人手写,也不该让 LLM 一次生成后就放在那里。它应该像模型权重一样,在任务反馈里被反复训练、验证、接受或拒绝。模型参数先不动,先训练那份指导模型做事的说明书。
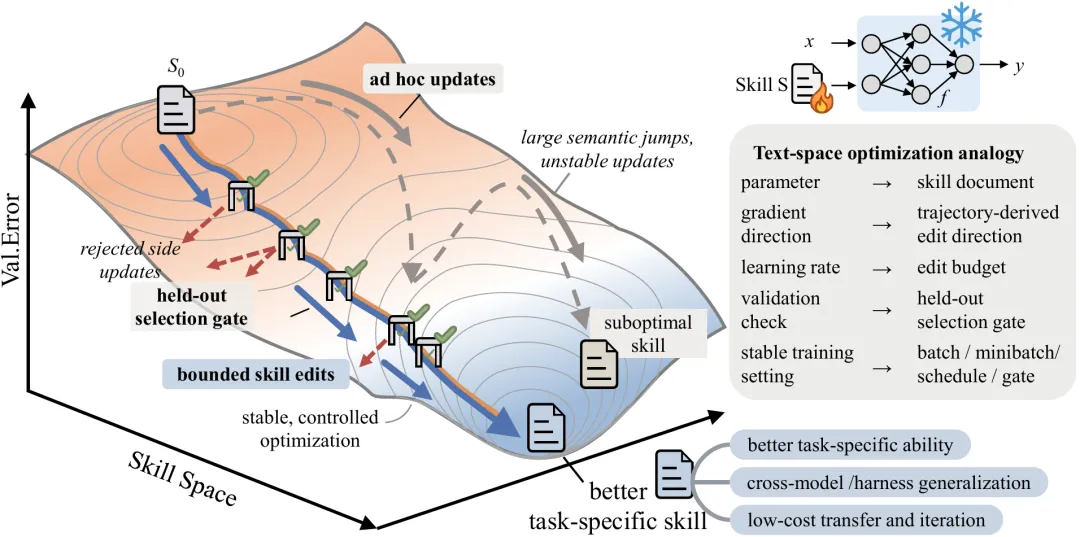
图 1 是项目页里的 teaser,它把 Agent 经验学习拆成了一个完整闭环:target model 先带着当前 skill 执行任务,optimizer model 再读取轨迹并提出编辑,最后由验证集决定这次编辑要不要进入新版本。这个过程很像传统深度学习里的训练,只不过优化对象从一堆浮点数,换成了一份自然语言文档。
为什么 skill 文档突然重要了?
因为现在的 Agent 已经不是只回答问题。它会搜索网页、读文件、写代码、跑命令、调用工具、填表格,甚至连续处理一串带状态的任务。在这类场景里,模型本身能力当然重要,但同一个模型,带不带一份好 skill,表现可能差得很远。
举个最简单的资料核验任务。没有 skill 时,Agent 可能先搜到一个结果,看到标题像,就开始总结;有 skill 时,它会被明确要求:
-
先找一手来源,不要只看转述; -
关键数字至少交叉验证一次; -
无法确认的地方必须降级措辞; -
输出时把事实、来源观点、模型推断分开。
这些规则不在模型权重里,更像是工作习惯。而 Agent 的很多失败,恰恰不是因为它不会说话,而是因为工作习惯不稳定:忘记检查、乱用工具、格式跑偏,或者看到局部线索就过早下结论。SkillOpt 要解决的问题就落在这里:能不能让一份 skill 文档自己迭代,越跑越像一个熟练工?
过去的 skill 是怎么来的?
论文把现有 skill 的来源分成了几类:一种是手写,优点是可控,缺点是靠人肉经验,覆盖不全,迁移很慢;一种是让 LLM 一次性生成,方便是方便,但没有反馈闭环,写出来看着完整,真正跑任务时未必可靠;还有一种是让 LLM 自我修改,听起来更聪明,问题是太自由,既可能一次性删掉有用规则,也可能为了修复一个局部失败,写出过拟合补丁。
SkillOpt 真正补上的,是中间缺失的「训练纪律」。它不让 skill 随便变,每次能改多少要有预算,改完好不好要过验证门,改错了也不直接丢掉,而是进入 rejected-edit buffer,成为后续优化的反面教材。几个机制拼在一起,skill 文档才从「一段提示词」变成了「可训练状态」。
核心思路:把文本空间当成优化空间
这篇论文最有意思的地方,是它认真模仿了深度学习训练范式。不是拿“训练”做个比喻就算了,而是真的给每个环节都找了文本空间里的对应物。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这张表就是理解 SkillOpt 的钥匙。论文不是简单说「让模型自己反思一下」,而是在强调:如果要优化 skill,就要承认文本空间也需要 learning rate、validation、负反馈和长期记忆。否则 skill 很容易变成一份越改越长、越改越乱的说明书。
它具体怎么跑?
整个流程可以拆成五步。第一步是 rollout,target model 带着当前 skill 执行一批任务,系统记录完整轨迹,包括消息、工具调用、观察结果、最终答案和评分。这一步很像前向传播:Agent 真实跑了一遍,留下可分析的证据。
第二步是 reflection,一个独立的 optimizer model 读取这些轨迹,尤其是成功样本和失败样本,找出可复用的行为规律。比如失败样本里反复出现「搜索到二手来源就停下」,optimizer 就可能提出一条新规则:涉及发布时间、性能数字、融资金额时,必须优先打开官方来源或论文原文。
第三步是 bounded edits。optimizer 不能随便重写整份 skill,只能提出增加、删除、替换这类结构化编辑,而且每一步有预算。这个限制很关键;没有编辑预算,skill 很容易被一次反思带偏。今天遇到一个表格任务,就把全部规则都改成表格任务专用;明天遇到一个搜索任务,又把规则全换掉。SkillOpt 用「文本学习率」限制每次更新幅度,保留版本之间的连续性。
第四步是 validation gate。候选 skill 不是生成出来就自动生效,它必须在 held-out validation 上严格超过当前最好版本,才会被接受,平局也不算赢。这个设计很保守,但很必要,因为 LLM 反思出来的规则经常听起来很对,跑起来未必有效。
第五步是 slow/meta update。系统会在 epoch 级别总结长期稳定的方向,把它写进受保护的 meta skill 或 slow update 结构里,避免短期编辑覆盖长期规律。
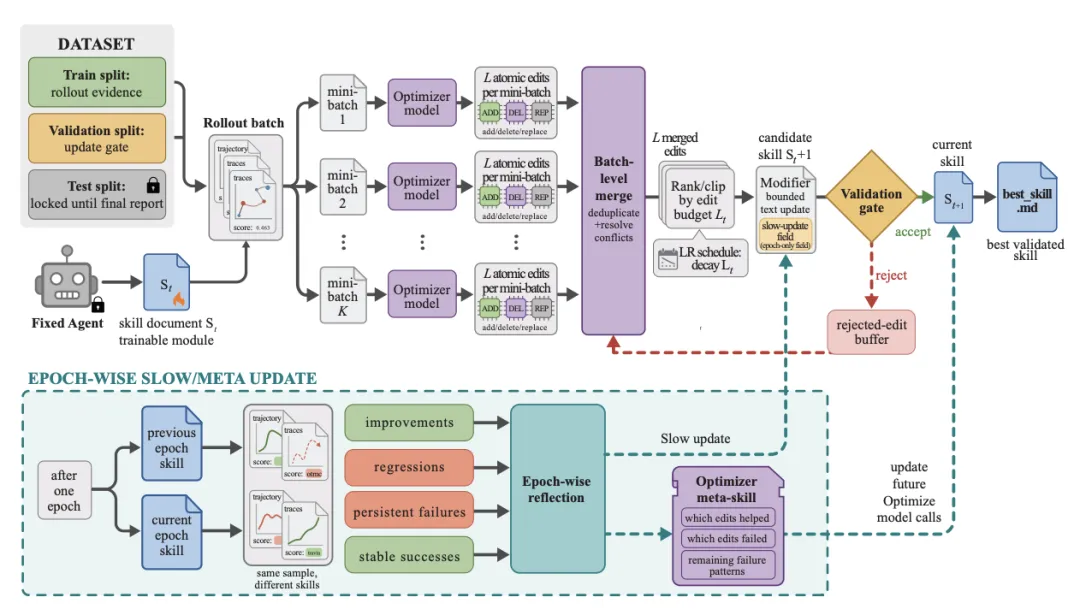
图 2 里最值得注意的一点,是部署阶段只保留最终 skill,optimizer model 只在离线训练时参与。也就是说,如果 SkillOpt 的收益成立,它不会在推理时额外多叫一个模型。这对 Agent 产品很重要,因为很多方法一到线上就会被成本和延迟打回原形。
实验结果:52 个格子全部最优或并列最优
从 arXiv 摘要和项目页来看,SkillOpt 的实验规模不小。论文声称覆盖:
-
6 个 benchmark; -
7 个 target model; -
3 种 execution harness:direct chat、Codex、Claude Code; -
对比 human、one-shot LLM、Trace2Skill、TextGrad、GEPA、EvoSkill 等方法。
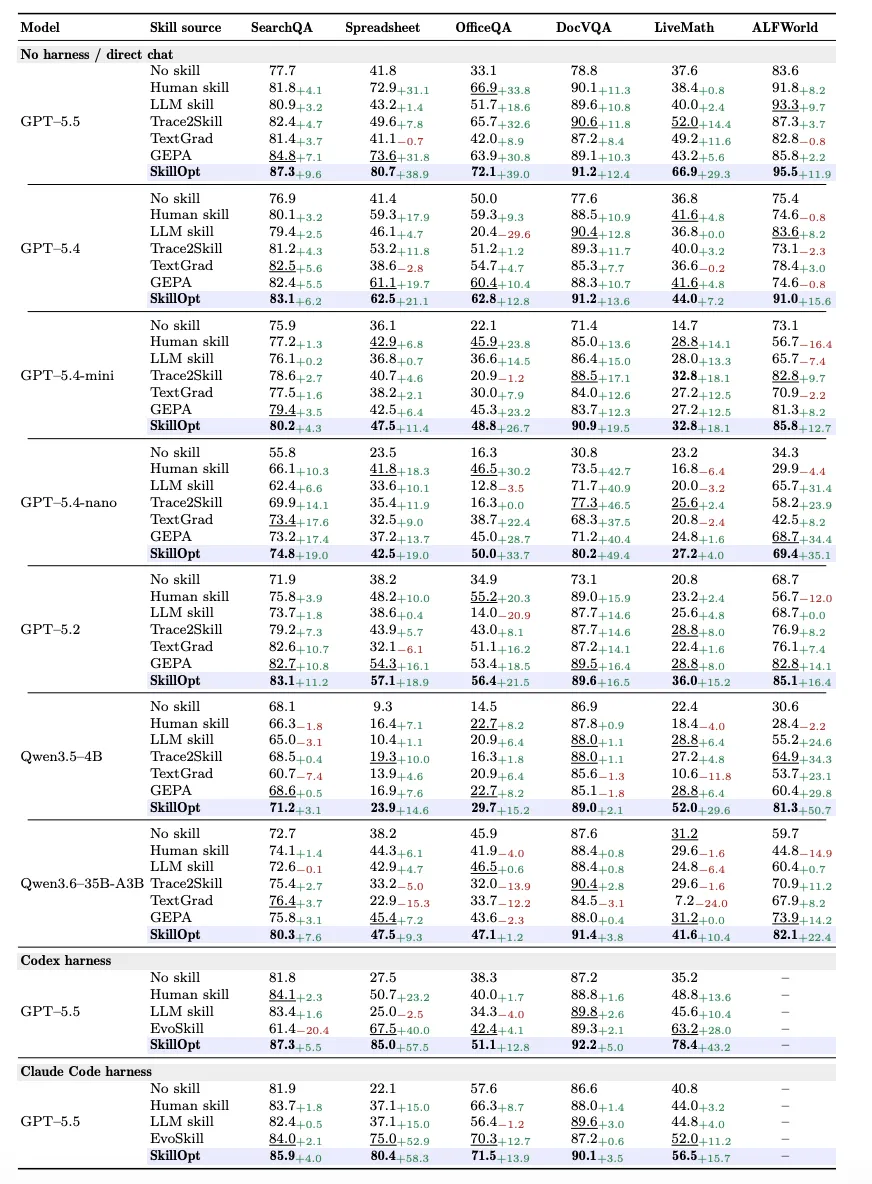
项目页把主结果写成了一个很抓人的数字:52 / 52。也就是在 52 个被评估的 model / benchmark / harness cell 里,SkillOpt 全部 best 或 tied-best。摘要里还给了 GPT-5.5 上的平均提升:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
更细一点看项目页主结果,提升不是只集中在一个 benchmark 上。
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这张表有两个细节值得单独拎出来。第一,Spreadsheet 任务的提升非常显眼:GPT-5.5 在 Codex 里提升 +57.5 points,在 Claude Code 里提升 +58.3 points。这说明 SkillOpt 不只是让模型“回答得更像样”,而是在工具型、操作型任务里把执行步骤管住了。第二,小模型也不是没用:Qwen3.5-4B 在 ALFWorld 上提升 +50.7 points,GPT-5.4-nano 在 DocVQA 上提升 +49.4 points。这里真正有意思的是,skill 文档像一个轻量外置策略层,能把一部分“做事习惯”迁移给能力较弱的目标模型。
再看和其他方法的对比。项目页给了 No skill、Human skill、LLM skill、Trace2Skill、TextGrad、GEPA 和 SkillOpt 的 benchmark 对比。为了读起来不炸表,这里只保留三列:无 skill、最强基线、SkillOpt。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
消融实验也能解释为什么它有效。
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
lr=4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这张消融表反而比 52/52 更能说明问题。它告诉我们,SkillOpt 不是靠“让 LLM 多反思几次”堆出来的,真正起作用的是几个很工程化的约束:
-
learning rate 防止一次性大改,把 skill 改崩; -
rejected buffer 让失败编辑成为负样本,避免反复走老路; -
meta skill 和 slow update 负责保留跨 epoch 的长期方向,尤其对 Spreadsheet 这种程序化任务非常关键。
如果这些结果能稳定复现,含义会很大。它说明 skill 文档不只是「给模型一点提示」,而可能是一种低成本的能力适配层。尤其在 Codex 和 Claude Code 这种 agentic loop 环境里,用户本来就会放 README、AGENTS、CLAUDE、skills、工具说明和工作流规范。SkillOpt 等于把这些文档从「人工维护」推向了「有反馈地训练」。
不过这里也要保留一点谨慎。52/52 很强,项目页上的实验表也很漂亮,但正式发布前还需要回论文正文看清楚几个口径:
-
每个 benchmark 的任务规模和评分方式是什么; -
skill 优化用了多少 rollout 成本; -
optimizer model 的调用成本有没有单独统计; -
对比方法的 prompt 和预算是否公平; -
这些 skill 是否会过拟合特定 benchmark。
这不是挑刺。这类方法最怕的就是「论文里训练得很漂亮,换个真实业务就失灵」。真正有价值的不是一个大数字,而是它的训练纪律能不能迁移到我们自己的 Agent 工作流里。
rejected-edit buffer
论文里有个细节很实用:被拒绝的编辑不会直接丢掉,而是进入 rejected-edit buffer。这点很像人类做工程。一次改动没通过测试,不代表它没有信息量;它至少告诉你,这个方向试过了,不行,这个规则听起来合理,但会伤害泛化,或者这个修复太局部,下次别重复。
如果没有 rejected-edit buffer,optimizer 很可能过几轮又提出类似修改;有了这个 buffer,失败就不只是失败,而是负样本。这对 Agent skill 尤其重要,因为自然语言规则的坏处经常不明显。比如你给 Agent 加一句:
遇到不确定问题时,多搜索几个来源。
这句话听起来没问题,但在某些任务里,它可能导致 Agent 过度搜索,浪费预算,甚至把简单问题复杂化。更好的规则可能是:
涉及时间、数字、发布主体、模型能力边界时,优先补充一手来源;纯格式转换任务不要额外搜索。
这就是 skill 优化真正要学的东西:不是把规则写多,而是把触发条件写准。
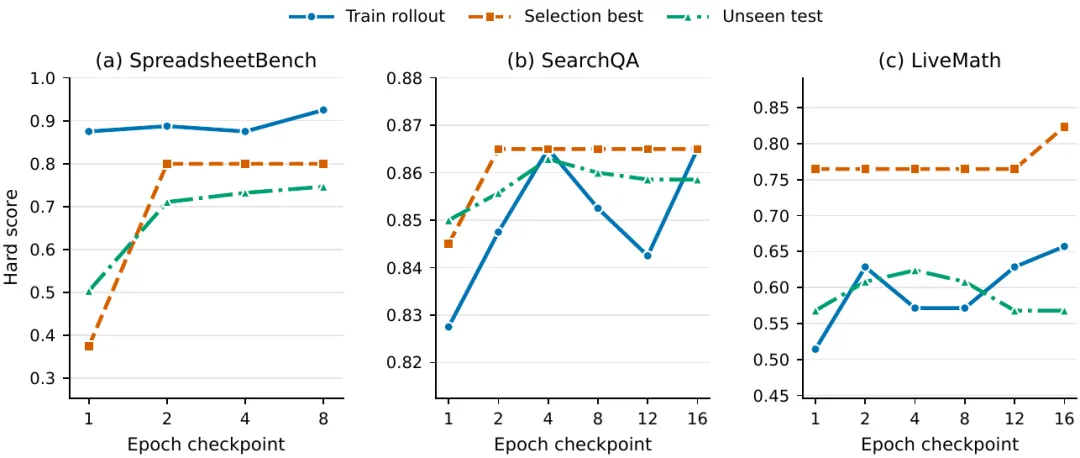
图 3展示的是 epoch checkpoint trends。它提醒我们一件事:skill 不是每次改都变好,训练轨迹里会有接受、拒绝和慢速更新。相比「模型自我进化」这种大词,这种能被验证、能被拒绝的流程更可信,也更接近真正的训练。
这篇论文对我们有什么启发?
我觉得至少有四点。第一,Agent 的能力不只在模型里,也在外部文档里。很多团队现在已经在维护各种工程说明:代码规范、工具调用规则、故障处理流程、日报格式、事实核验清单、写作风格要求。过去这些东西被看成「项目文档」,但从 Agent 的角度看,它们其实就是外部策略层。
第二,skill 文档应该进入评估闭环,而不是凭感觉改 prompt。更合理的做法是准备一批代表性任务,用当前 skill 跑一遍,记录失败,再让模型提出小幅编辑,最后只接受能在 held-out 任务上提升的版本。哪怕不完整复现 SkillOpt,也可以先把这个流程借过来。
第三,越是自然语言规则,越需要边界。「写得更详细」不等于更好。一份 300 到 2000 token 的 skill,可能比一份几万字的说明书更有用,因为 Agent 真正需要的是关键行为约束,而不是一堆互相打架的建议。
第四,好的 Agent 系统会越来越像一个小型训练系统。不是每次都训模型权重,而是训练提示词、训练工具说明、训练检索策略、训练输出规范、人工审核 checklist。这件事的门槛比微调低很多,但工程要求一点不低,你仍然需要数据集、评分器、验证集、版本管理、回滚机制和失败分析。
如果要在真实项目里落地,可以先做一个简化版
不用一上来复现整篇论文。一个可操作的最小版本可以是这样:
-
选一个具体 Agent 任务,比如资料核验、代码修改、论文解读或日报生成。 -
准备 30 到 50 个历史任务,分成 train 和 held-out。 -
写一份初始 skill.md,控制在 1000 token 左右。 -
让 Agent 带着当前 skill 跑 train 任务,记录失败轨迹。 -
让另一个模型只提出最多 3 条 add / delete / replace 编辑。 -
用 held-out 任务复测,只有指标严格提升才接受。 -
把被拒绝的编辑记录下来,下次反思时作为负反馈。
这已经有点 SkillOpt 的味道了。关键不是自动化多酷,而是别再凭感觉无限改 prompt。每一次编辑都应该能回答三个问题:
-
它修复了哪类失败? -
它会不会伤害已有能力? -
它在没见过的任务上有没有提升?
回答不了,就先别合进去。
最后
SkillOpt 这篇论文让我觉得有意思的地方,是它把一个很日常的东西重新定义了。skill 文档不再只是写在项目里的辅助说明,它可以是 Agent 的外部状态,可以被训练,可以有学习率、有验证集、有负反馈、有版本选择。
这条路未必会替代微调,也不会让 prompt 工程突然变成万能钥匙,但它确实指出了一个更现实的方向:在模型越来越强、工具越来越多、Agent 工作流越来越长之后,真正决定系统稳定性的,可能不是单次回答有多聪明,而是那套可复用的执行策略能不能持续进化。以前我们说「把经验写进文档」,SkillOpt 往前推了一步:把文档当成可以训练的经验。
这件事,值得每个做 Agent 的人认真看一眼。
参考链接:
-
arXiv:https://arxiv.org/abs/2605.23904 -
项目页:https://microsoft.github.io/SkillOpt/ -
代码入口:https://aka.ms/skillopt -
GitHub:https://github.com/microsoft/SkillOpt
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点 关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。

