 夜雨聆风
夜雨聆风





open claw + DeepSeek实战,用AI辅助开发图书管理系统!(保姆级教程)
一个完整的图书管理系统——Django后端、Vue 3前端、JWT认证、借阅流通、数据报表,前后端加起来近30个文件。
如果你只有Python基础,觉得搭一个完整的Web系统太艰难,这篇文章就是写给你的。我用open claw + DeepSeek辅助开发,把工期从两周压缩到两天,顺便把这个过程和方法完整记录下来。
先看看成果:
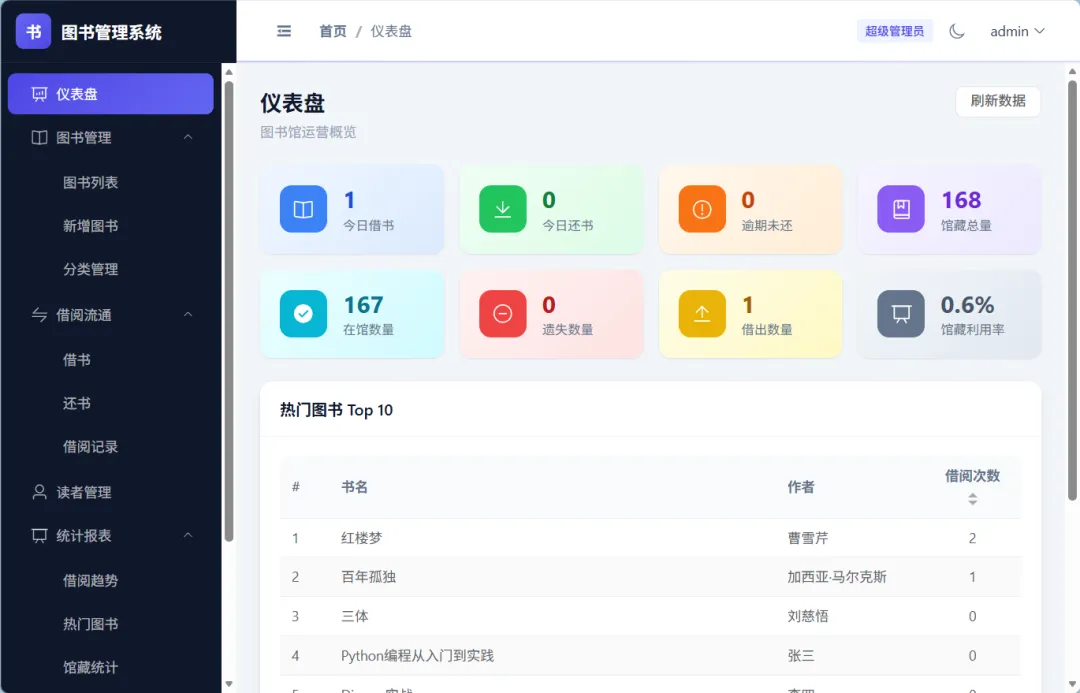
一、为什么还要写这篇文章?
先说明白:对于程序员来说,没有AI也能写这个系统,但有了AI,时间上就可能从两周变成了两天。
这篇文章不是”AI取代程序员”的焦虑贩卖,而是想告诉那些有Python基础但觉得全栈开发太遥远的朋友:你现在完全可以做出以前想都不敢想的东西!
图书管理系统是经典的入门级全栈项目——它包含了:
-
数据库建模(图书、读者、借阅记录、罚款……)
-
RESTful API 设计
-
前后端分离架构
-
用户认证与权限控制
-
数据可视化
-
搜索、分页、防抖等交互细节
但这些对于只有Python基础的人来说,每一步都是坎——Vue是什么?Webpack和Vite有什么区别?JWT Token怎么用?跨域问题怎么解决?
这篇文章会告诉你:你不需要先花三个月学完前端所有知识再动手。用AI辅助,你可以边做边学,而且做出来的东西是真正能用的。
二、技术选型:AI帮你做”选择题”
开发的第一步是选技术栈。我的做法很简单——直接问AI:
我的提示词: “我要做一个图书管理系统的Web应用,Python后端,网页前端。帮我推荐技术栈,要求成熟稳定、学习曲线平缓、适合一个人开发。“
AI给了几个方案,我选了最成熟的那套:
后端:Django + Django REST Framework
Python世界里最成熟的Web框架。ORM、Admin后台、认证系统、migrations……全内置。DRF让写API像写普通函数一样。
前端:Vue 3 + Element Plus
Vue 3的组合式API(Composition API)写起来更像在组织逻辑,对后端开发者很友好。Element Plus提供了企业级的UI组件库——表格、表单、弹窗、菜单、分页,全是现成的。
我的追问: “Vue 3有好几种写法,我应该用哪种?” AI: “推荐用
<script setup>语法糖+组合式API。对比选项式API,它更简洁,类型推导更好,而且逻辑组织更灵活。对后端开发者来说,写起来更像在写JavaScript逻辑,而不是在填配置对象。“
认证:JWT Token(SimpleJWT)
前后端分离项目的事实标准。
看,你不需要自己调研——让AI给你推荐,你只需要做选择题。
三、项目骨架:AI帮你”搭脚手架”
确定了技术栈后,下一步是项目结构。这是给AI的第一个”设计题”:
我的提示词: “帮我设计一个图书管理系统的项目目录结构,要求前后端分离,Django后端按业务模块拆分App,Vue 3前端也按功能模块组织。“
AI给出的骨架:
Library_System/├── backend/ # Django 后端│ ├── apps/│ │ ├── auth_/ # 认证模块(登录/登出/令牌刷新)│ │ ├── books/ # 图书模块(书目/副本/分类/标签)│ │ ├── circulation/ # 流通模块(借书/还书/续借)│ │ ├── readers/ # 读者模块│ │ ├── fines/ # 罚款模块│ │ ├── reservations/ # 预约模块│ │ ├── reports/ # 报表模块│ │ └── system/ # 系统配置模块│ └── library_system/ # Django 主配置├── frontend/ # Vue 3 前端│ └── src/│ ├── api/ # API请求封装│ ├── store/ # Pinia状态管理│ ├── router/ # 路由和导航守卫│ └── views/ # 页面组件└── .venv/ # Python虚拟环境一个关键的架构决策是按业务模块拆Django App。这样有两个好处:一来每个App的代码量不大,AI生成时上下文更精确;二来模块之间耦合度低,一个人维护也不容易改出bug。
Vite 配置:解决跨域问题
前后端分离开发中最常见的坑是跨域。前端跑在5173端口,后端在8000端口,浏览器会拦截跨域请求。我问AI:
我的提示词: “Vite前端开发服务器和Django后端在不同端口,怎么解决联调时的跨域问题?“
AI给的方案是用Vite的代理功能:
// frontend/vite.config.jsimport { defineConfig } from'vite'import vue from'@vitejs/plugin-vue'exportdefault defineConfig({ plugins: [vue()], server: { proxy: {'/api': { target: 'http://localhost:8000', // Django 后端地址 changeOrigin: true, // 解决跨域 }, }, }, resolve: { alias: {'@': '/src', // 路径简写,@/views 等价于 src/views }, },})这段配置的意思是:开发时所有以 /api 开头的请求都会由Vite转发到Django。前端axios请求直接写 /api/books/,浏览器就不会报跨域错误了。
我的追问: “部署到生产环境时跨域怎么处理?” AI: “生产环境有两种方案:1) 用Nginx反向代理,前端打包成静态文件由Nginx托管,同一路径下转发API到Django;2) Django配置django-cors-headers放开跨域。开发阶段用Vite代理最方便。“
四、数据模型:用自然语言”描述”数据库设计
做图书管理系统,第一步是把数据模型搞清楚。有了AI,你不需要画ER图再转代码,直接用自然语言描述:
我的提示词: “我要做一个图书管理系统,帮我设计数据模型。需求如下:
图书有书名、作者、ISBN、出版社、出版日期、定价 图书要有分类和标签 每本书可以有多个副本(馆藏),每个副本有唯一的条形码、存放位置 读者有姓名、学号/工号、卡号、院系、手机号 读者有不同类型(学生/教师),不同读者的借阅上限和期限不一样 借阅记录要记录谁借了哪本书、什么时候借的、应还日期 逾期会产生罚款 支持预约已借出的书”
AI直接生成了完整的模型代码。但我没有就此停住,而是逐个追问边界情况:
我的追问:如果删除一个分类,下面的书怎么办?
AI:用
on_delete=models.SET_NULL,删除分类时把书的分类置空,不会删除书本身。
我的追问:如果读者续借怎么办?
AI:在借阅记录上加
renewals字段记录续借次数,due_date重新计算。同时读者类型上配置max_renewals和renew_days控制续借上限。
我的追问:查借阅记录时最常见的查询条件是什么?
AI:按读者查当前借阅、按副本查历史记录。建议建联合索引
(reader,status)和
(book_copy, status)。
看,你不用自己踩一遍所有坑。AI见过足够多的项目,能提前告诉你最佳实践。
最终生成的三个核心模型:
图书信息模型(BookInfo)
classBookInfo(BaseModel): title = models.CharField(max_length=200, db_index=True) title_original = models.CharField(max_length=200, blank=True) isbn = models.CharField(max_length=20, unique=True, db_index=True) author = models.CharField(max_length=200, db_index=True) publisher = models.CharField(max_length=200, db_index=True) publish_date = models.DateField(null=True, blank=True) edition = models.IntegerField(default=1) pages = models.IntegerField(null=True, blank=True) price = models.DecimalField(max_digits=10, decimal_places=2, null=True, blank=True) category = models.ForeignKey(Category, on_delete=models.SET_NULL, null=True) tags = models.ManyToManyField(Tag, blank=True) description = models.TextField(blank=True)classMeta: verbose_name = '书目' indexes = [models.Index(fields=['title', 'author'])]注意 BaseModel——这个是AI建议的抽象基类,包含created_at、updated_at、is_active、deleted_at四个通用字段和soft_delete()方法。所有核心模型都继承它,不用每个模型重复写这些字段。
馆藏副本模型(BookCopy)
这里有个重要的概念:“一本书”和”书架上的那本书”不是一回事。《红楼梦》是一本书(BookInfo),但图书馆里可能有3本《红楼梦》,每本都有唯一的条形码——这就是副本(BookCopy)。
classBookCopy(BaseModel): STATUS_CHOICES = [ ('available', '在馆'), ('borrowed', '借出'), ('lost', '遗失'), ('damaged', '损坏'), ('repairing', '修复中'), ('retired', '下架'), ] book = models.ForeignKey(BookInfo, on_delete=models.CASCADE, related_name='copies') barcode = models.CharField(max_length=50, unique=True, db_index=True) location = models.CharField(max_length=100, db_index=True) shelf = models.CharField(max_length=50, blank=True) status = models.CharField(max_length=20, choices=STATUS_CHOICES, default='available') purchase_price = models.DecimalField(max_digits=10, decimal_places=2, null=True)借阅记录模型(BorrowRecord)
classBorrowRecord(BaseModel): STATUS_CHOICES = [ ('borrowing', '借阅中'), ('returned', '已归还'), ('overdue_returned', '逾期已还'), ] book_copy = models.ForeignKey(BookCopy, on_delete=models.CASCADE) reader = models.ForeignKey(ReaderProfile, on_delete=models.CASCADE) borrow_admin = models.ForeignKey(User, on_delete=models.SET_NULL, null=True) borrow_date = models.DateTimeField(auto_now_add=True) due_date = models.DateTimeField() return_date = models.DateTimeField(null=True, blank=True) renewals = models.IntegerField(default=0) status = models.CharField(max_length=20, choices=STATUS_CHOICES, default='borrowing')这些模型代码可能看起来和你自己写的差不多——但实际上大部分是在和AI的对话中逐步完善的,不是一次性生成的。
五、后端API:CRUD之外的业务逻辑
有了模型,用DRF写CRUD API几乎是机械式的:一个ModelViewSet加一个router.register()就搞定了。但图书管理系统的核心价值在借书这个业务操作。
借书接口的事务与并发控制
我先让AI生成了借书接口的基础版本:
我的提示词:帮我写一个借书接口,支持输入读者卡号和图书条码,创建借阅记录并更新副本状态。
AI生成了基本版本,然后我挨个追问边界情况:
我的追问:如果读者被拉黑了还能借书吗?
AI:应该检查
blacklist_until,如果在黑名单有效期内就拒绝借书。
我的追问:如果读者已经借满了呢?
AI:对比
current_borrow_count和
reader_type.max_borrow,超过就拒绝。
我的追问:如果两个管理员同时操作同一本书,会不会出现一书多借?
AI:用
select_for_update()对副本记录加行级锁,第二个操作会等待第一个完成。
我的追问:如果借阅记录创建成功了但副本状态没更新怎么办?
AI:用
@transaction.atomic把整个操作包在事务里,任何一个步骤失败都会回滚。
最终的代码:
@api_view(['POST'])@permission_classes([IsOperator])@transaction.atomicdefborrow_book(request):# 1. 查找读者(支持卡号和学号两种方式)try: reader = ReaderProfile.objects.get(is_active=True, card_number=reader_card)except ReaderProfile.DoesNotExist:return Response({'code': 404, 'message': '未找到该读者'})# 2. 读者是否被拉黑了?if reader.blacklist_until and reader.blacklist_until > timezone.now().date():return Response({'code': 409, 'message': '该读者已被列入黑名单'})# 3. 是否超过借阅上限?if reader.current_borrow_count >= reader_type.max_borrow:return Response({'code': 409, 'message': f'已达借阅上限({reader_type.max_borrow}本)'})# 4. 查找副本(带行级锁,防止并发) copy = BookCopy.objects.select_for_update().get(barcode=barcode)# 5. 副本状态检查if copy.status != 'available':return Response({'code': 409, 'message': '该副本不可借出'})# 6. 计算应还日期 max_days = reader_type.max_days if reader_type else30 due_date = timezone.now() + timedelta(days=max_days)# 7. 创建借阅记录 + 更新副本状态(原子操作) record = BorrowRecord.objects.create( book_copy=copy, reader=reader, borrow_admin=request.user, due_date=due_date, ) copy.status = 'borrowed' copy.save(update_fields=['status'])return Response({'message': '借书成功', 'record': {...}})这段代码从”能跑”到”健壮”,经历了4轮追问。AI辅助开发的真正价值,不在于一次生成多少代码,而在于你能通过追问,让代码在几分钟内迭代好几个版本。 你自己查资料、读文档、写demo,一个小时就过去了。
六、前端页面:用Element Plus”搭积木”
如果你只有Python基础,听到”前端”两个字可能会发怵。但实际上,有了Element Plus的组件库和AI辅助,你可以像搭积木一样拼出专业的管理后台。
Axios请求封装与Token自动刷新
我的提示词:用axios封装HTTP请求,要求:自动在请求头附加JWT Token;遇到401响应时自动刷新Token;刷新成功后重试失败的请求。
import axios from'axios'const request = axios.create({ baseURL: '/api', timeout: 10000,})// 请求拦截器:自动带上Tokenrequest.interceptors.request.use(config => {const authStore = useAuthStore()if (authStore.accessToken) { config.headers.Authorization = `Bearer ${authStore.accessToken}` }return config})// 响应拦截器:遇到401自动刷新Tokenrequest.interceptors.response.use(response => response.data,async error => {if (error.response?.status === 401 && !originalRequest._retry) {const newToken = await authStore.refreshAccessToken() originalRequest.headers.Authorization = `Bearer ${newToken}`return request(originalRequest) } })这里有个容易被忽视的细节:
我的追问:如果多个API请求同时返回401,会出现多个刷新Token的请求同时发出吗?
AI:会。应该加一个队列机制:第一个401负责刷新Token,后续的401排队等待。刷新完成后统一通知所有排队请求用新Token重试。
这个”refresher queue”模式AI直接生成了完整代码,不需要自己从头设计。
借书页面:连续扫码的交互设计
借书是管理员最频繁的操作,交互设计的目标很明确:尽量减少操作步骤。
我的提示词:帮我把这个Vue页面改成交互更流畅的版本:输入读者卡号查询读者,查到后自动聚焦到图书条码输入框,借书成功后不清除读者信息,自动聚焦到条码输入框准备扫下一本。
生成的模板:
<template><el-cardstyle="max-width: 600px; margin: 0 auto;"><template #header>借书操作</template><!-- 第一步:扫读者卡 --><el-inputv-model="readerCard"placeholder="扫描或输入读者卡号" @keyup.enter="queryReader" /><!-- 展示读者信息 --><el-cardv-if="reader"shadow="hover"><strong>{{ reader.name }}</strong> ({{ reader.reader_type_name }})<div>已借: {{ reader.current_borrow_count }}/{{ reader.reader_type?.max_borrow }}</div><el-button @click="resetReader">更换读者</el-button></el-card><!-- 第二步:扫图书条码 --><el-inputv-if="reader"v-model="barcode"ref="barcodeInput"placeholder="扫描图书条形码" @keyup.enter="queryBook" /><!-- 展示图书信息 --><el-cardv-if="copy"shadow="hover"><strong>{{ copy.book_title }}</strong><div>条形码: {{ copy.barcode }} | 位置: {{ copy.location }}</div></el-card><!-- 第三步:确认借书 --><el-buttonv-if="copy && reader"type="primary":disabled="copy.status !== 'available'" @click="confirmBorrow"> 确认借书</el-button></el-card></template>逻辑部分:
const reader = ref(null)const copy = ref(null)const barcodeInput = ref(null)async function queryReader() {const res = await readerApi.list({ search: readerCard.value }) reader.value = res.results?.[0] || nullif (reader.value) nextTick(() => barcodeInput.value?.focus())}async function confirmBorrow() {await circulationApi.borrow({ reader_card: readerCard.value, barcode: barcode.value }) copy.value = null barcode.value = '' nextTick(() => barcodeInput.value?.focus()) // 自动聚焦,准备扫下一本}一开始AI生成的版本每次借书后把所有信息清空,包括读者。我只说了一句”管理员每次都要重新扫读者卡太慢了”,AI就改成了现在的”保持读者、只清图书、自动聚焦”方案。
这就是AI辅助开发最有意思的地方:你不需要跟AI说具体怎么改代码,只需要描述体验上的问题,它自己就能理解并调整实现。
七、权限控制:前后端联动的角色体系
系统有四种角色:超级管理员、图书管理员、操作员、读者。不同角色看到不同的页面、操作不同的功能。
我的提示词:设计一套角色权限系统:超级管理员能做所有操作;图书管理员可以管理图书和读者;操作员只能进行借还书操作;读者只能查看自己的信息。前后端都要控制,不能只靠前端隐藏按钮。
后端权限
DRF的权限类直接控制API的访问级别:
# 借书接口只需要操作员以上权限@permission_classes([IsOperator])# 新增图书需要图书管理员权限@permission_classes([IsLibrarian])# 系统配置只能超级管理员@permission_classes([IsAdmin])前端状态管理
exportconst useAuthStore = defineStore('auth', () => {const accessToken = ref(localStorage.getItem('access_token') || '')const refreshToken = ref(localStorage.getItem('refresh_token') || '')const user = ref(null)// 角色判断(计算属性)const isAdmin = computed(() => user.value?.role === 'admin')const isLibrarian = computed(() => ['admin', 'librarian'].includes(user.value?.role))const isOperator = computed(() => ['admin', 'librarian', 'operator'].includes(user.value?.role))const isReader = computed(() => user.value?.role === 'reader')asyncfunctionlogin(username, password) {const data = await request.post('/auth/login/', { username, password }) accessToken.value = data.access refreshToken.value = data.refresh user.value = data.user localStorage.setItem('access_token', data.access) localStorage.setItem('refresh_token', data.refresh) }})菜单动态渲染
侧边栏菜单根据角色动态显示,使用 v-if 在模板级别控制:
<el-sub-menuindex="books-menu"v-if="authStore.isOperator"><template #title><el-icon><Reading /></el-icon><span>图书管理</span></template><el-menu-itemindex="/books">图书列表</el-menu-item><el-menu-itemindex="/books/new"v-if="authStore.isLibrarian">新增图书</el-menu-item><el-menu-itemindex="/categories"v-if="authStore.isLibrarian">分类管理</el-menu-item></el-sub-menu>操作员能看到”图书列表”但不能”新增图书”,图书管理员则两个都能看到。权限控制就在模板上用 v-if 实现,不需要维护两套配置。
路由守卫
但光靠隐藏菜单不够——用户可以直接在地址栏输入URL。路由守卫做第二道防线:
router.beforeEach((to, from, next) => {if (to.meta.roles && !to.meta.roles.includes(authStore.user?.role)) {returnnext('/dashboard') // 没权限就踢回首页 }next()})我的追问:如果Token过期了,用户刷新页面会怎样?
AI:路由守卫应该先检查用户信息是否已加载,如果没有就先调用
fetchMe()获取用户信息。同时Token刷新的逻辑应该在axios拦截器中处理,用户刷新页面时如果Token过期,fetchMe()返回401,拦截器自动完成刷新,整个过程对用户透明。
这个”自动恢复登录态”的体验,是很多全栈初学者容易忽略的细节。
八、数据可视化:仪表盘和统计报表
仪表盘是管理系统的门面。后端统计当天的借还数据、逾期情况、馆藏概况:
我的提示词:写一个仪表盘摘要接口,返回今日借书数、今日还书数、逾期数量、总馆藏、在馆数、借出数。
@api_view(['GET'])def dashboard_summary(request): today = timezone.now().date() today_start = timezone.make_aware(datetime.combine(today, time.min)) borrow_today = BorrowRecord.objects.filter(borrow_date__gte=today_start).count() return_today = BorrowRecord.objects.filter(return_date__gte=today_start).count() overdue_count = BorrowRecord.objects.filter( status='borrowing', due_date__lt=timezone.now()).count() total_copies = BookCopy.objects.filter(is_active=True).count() available = BookCopy.objects.filter(is_active=True, status='available').count() borrowed = BookCopy.objects.filter(is_active=True, status='borrowed').count()return Response({'borrow_today': borrow_today,'return_today': return_today,'overdue_count': overdue_count,'total_copies': total_copies,'available': available,'borrowed': borrowed, })前端仪表盘用CSS Grid做响应式布局,宽屏4个卡片并排,窄屏自动2列或1列。
我的追问:仪表盘页面怎么样布局比较专业?
AI:推荐用CSS Grid做响应式卡片布局,每个卡片放一个统计数字配合图标。Element Plus有
el-row/el-col栅格系统也可以用。每个卡片用不同的渐变背景色,视觉上更有层次感。
九、调试与优化:当你遇到问题,AI就是你的”结对编程伙伴”
没有人能一次写出完美的代码。关键是出了问题怎么快速定位和修复。
1. 页面空白:排查”filter is not a function”
某次刷新分类管理页面后,树形结构完全不显示。打开F12控制台,看到一个TypeError。
我的提示词:控制台报错:
TypeError: categories.value.filter is not a function。这是我的代码:const categoryTree=computed(() =>categories.value.filter(c=>!c.parent))categories.value=await categoryApi.list()
AI:问题在于
categoryApi.list()返回的是分页对象{count: 54, results:[...]},不是一个数组。你赋值给categories.value的是一个对象,对象没有.filter()方法。改为:categories.value=(await categoryApi.list()).results || []
修复前——categories.value 拿到的是 { count, results } 对象修复后——取出 results 数组
这种问题在你熟悉了DRF的响应格式后会觉得很简单,但第一次遇到时可能卡半小时。把错误信息直接扔给AI,它几秒钟就能告诉你原因和修复方案。
2. 搜索防抖
图书列表的搜索是实时查询的,但每次输入都发请求太浪费:
我的提示词:搜索输入框每次按键都发API请求,太频繁了。帮我加防抖,用户停止输入200毫秒后再搜索。
import { debounce } from'../../utils/format'const onSearch = debounce(fetchData, 200)functiononSearchInput() { page.value = 1// 搜索时重置到第一页 onSearch()}3. 捕获所有错误
AI初始生成的代码中,有些catch块是空的。这在开发时没问题——你开了控制台能看到错误。但用户操作失败后没有任何提示,体验极差。
我的提示词:检查整个项目,把所有空的 catch 块都加上用户可见的错误提示。
改完之后的结果:
catch (e) { ElMessage.error(e?.message || '操作失败') }这几行代码直接决定了用户对你的系统是”还挺好用”还是”动不动就没反应”。
十、批量生成测试数据
系统功能写完了,但页面上空空如也——没有数据就没法演示,也没法完整测试借书流程。
我的提示词:帮我写一个Python脚本,通过API批量创建50本真实图书和对应的馆藏副本。图书要覆盖所有分类,数据要真实——比如《红楼梦》作者曹雪芹,ISBN用真实的。还要创建8个测试读者,覆盖4种读者类型。
AI生成的脚本跑完后,系统数据:
图书: 54 本 | 馆藏副本: 168 册 | 分类: 7 个 | 标签: 7 个 | 读者: 8 位用这些数据,我完整走了一遍”创建读者→借书→还书→续借→预约”的全流程,所有接口和页面都验证通过。
十一、总结:AI辅助开发的正确姿势
回到最开始的问题:有Python基础的人如何做一个完整的Web系统?
我的答案很明确:你不需要先系统学完前端三大框架再动手。AI可以帮你跨越”我不会”到”我能做”之间的鸿沟,但前提是你要理解业务逻辑、能判断AI给出的代码是否合理、能通过追问让AI逐步完善方案。
这篇文章里反复出现的模式,就是我实际开发中的工作流:
用户需求 → 描述给AI → AI生成代码 → 审查代码 → 追问边界情况→ AI补充优化 → 遇到问题 → 把错误扔给AI → 修复 → 继续下一块AI辅助开发的几个要点:
-
把需求说清楚——描述越具体,AI生成的代码质量越高。不要只说”做个借书功能”,要说”输入读者卡号查到读者,输入图书条码查到图书,确认后创建借阅记录”
-
追问边界情况——基础版本只是起点。逐个问”如果……怎么办”,AI会帮你补上异常处理
-
能看懂代码——AI写的代码你得能审查,不需要从零写,但要能看出逻辑对不对
-
会开控制台——页面异常时打开F12,把报错信息复制给AI,修复速度比自己翻文档快10倍
这套方法的核心是:你不是在让AI替你写代码,而是在让AI帮你加速。从两周到两天,省下来的时间可以用来打磨业务逻辑、优化用户体验,或者——早点下班。
附录:全文AI提示词速查

觉得文章对你有启发?欢迎点赞、关注和分享。下次想看什么:想看AI辅助写小程序,还是Python自动化办公脚本?评论区告诉我!
OCR车牌识别系统!如何让AI自己做一个车牌识别系统?含完整源码和测试。
本文涉及的代码均来自实际可运行的项目。如果你对某个模块的实现有疑问,或者想知道某个具体功能是怎么用AI写出来的,欢迎交流。