 夜雨聆风
夜雨聆风





实测Opus 4.8,它终于学会了先查文档再动手

同一天Anthropic还官宣了650亿美元的新一轮融资,估值9650亿,首次超过了OpenAI。但这个后面再说,先聊模型,因为模型跟我每天的工作直接相关,钱跟我没关系。
我从4.6一路用过来的。4.7的时候其实挺失望,注释冗余、tool calling不稳定、创作排版一塌糊涂,很多场景下我宁可切回4.6。所以4.8出来的时候我的预期很低,42天能改多少东西嘛。
结果还真不一样了。
先说最让我惊喜的一个变化。
4.8在X-High模式下,会主动搜索。
以前不管是4.6还是4.7,你让它干一个涉及外部API的开发任务,它上来就写,写完发现接口参数不对,你得手动push它「你先去看看文档」,它才磨磨蹭蹭地去查。有时候push了还不听,自信地跟你说「根据我的了解,这个接口应该是这样的」。
嗯?你了解个屁啊,你的知识库截止日期都过了半年了。
4.8不一样了。它会根据代码里的细节,主动去查对应的接口文档,拿到具体的参数定义和返回格式以后再往下写。甚至有时候会主动搜一些观点和方案来参考,你没让它搜,它自己觉得需要就去了。
这个变化对我来说比什么跑分提升都重要。
因为我不是专业开发者,我是产品经理,用Claude Code做产品开发。我没有能力去review每一行代码到底用对了API没有,我能做的就是把需求描述清楚,然后信任模型去执行。以前这个信任经常被辜负,一个接口参数写反了我压根看不出来,等到整个功能跑不通了才发现,然后回头改,改完又引入新的问题,来来回回折腾半天。
4.8至少在「先调研再动手」这件事上,让我踏实了很多。它不会每次都查,但遇到不确定的东西,它有了自己先去确认一下的意识。这个意识很重要。
当然这个主动搜索只有X-High模式下才比较明显。默认High模式,还是会有点懒。所以我现在日常就开着Extra,重要任务切Max。
说到X-High模式,延迟确实会增加。简单问题多等一会儿有点烦。但复杂问题值得等,因为给出来的答案明显更完整、更少需要你反复追问和修改。以前那种「改完→报错→再改→又报错」的循环变少了。这个trade-off我接受,甚至觉得挺值。
再说开发能力的整体体感。
相比4.7,说实话没什么明显的感知差异。4.7已经是一个相当能写代码的模型了,在纯coding的维度上,4.8在4.7的基础上提升是渐进的,日常用起来很难说出「啊这里4.8比4.7强了」这种话。
但相比4.6,差异非常明显。4.6写代码的时候经常会遗漏边界情况,或者在多文件协同的场景下丢失上下文。你跟它说「改一下这个文件的逻辑」,它改了,但忘了另一个文件里有一处依赖也需要同步改。4.8在这方面好了很多,上下文的维持能力肉眼可见地提升了。
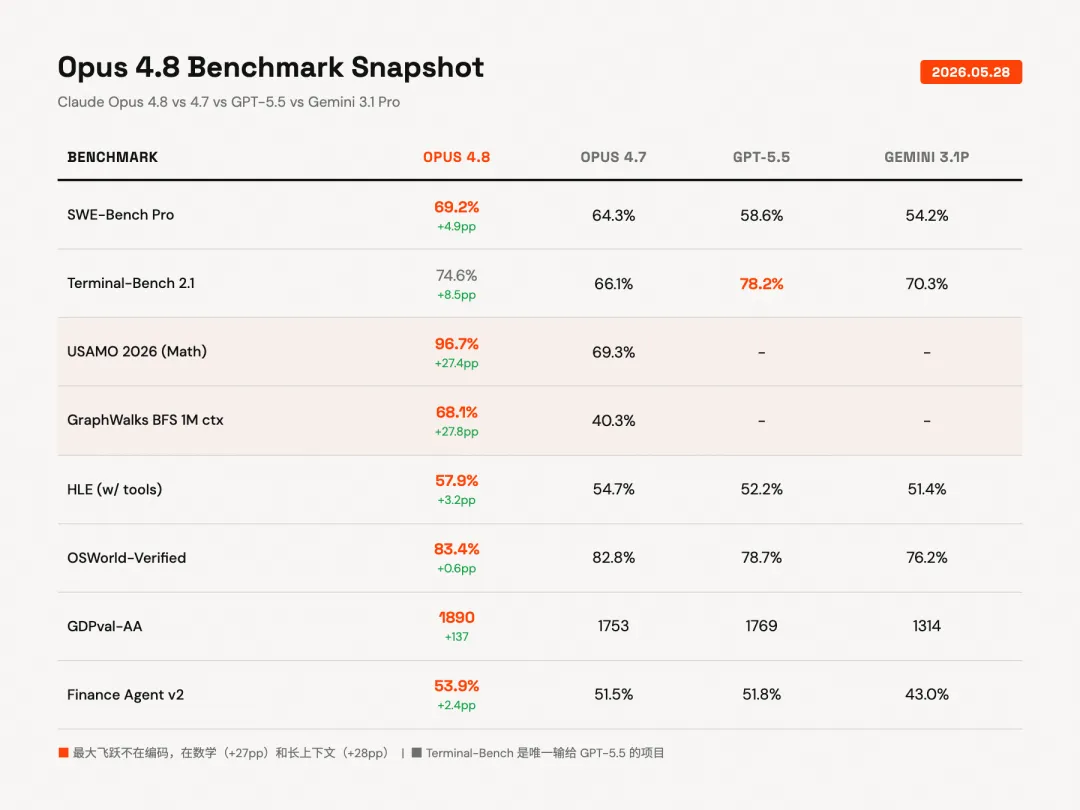
跑分的话简单提一嘴。SWE-Bench Pro从64.3%涨到69.2%,比GPT-5.5的58.6%高了10个百分点。但有个大部分人没注意到的东西,这次进步最大的其实不是编码。
USAMO 2026,美国数学奥林匹克测试,从69.3%跳到了96.7%。涨了27个百分点。
GraphWalks BFS,测模型在100万token超长文本里做图遍历的能力,从40.3%跳到68.1%。涨了将近28个百分点。
编码涨了不到5个百分点,数学和长上下文各涨了将近30个百分点。
这说明什么?4.8这次的底层优化方向可能不是「让编码更强」,而是「让推理更深、让上下文利用更充分」。编码的提升更像是这些底层能力改善之后自然带出来的。
我前面说的「主动查文档」,可能就跟这个底层推理能力的提升有关。它能更好地判断「这个地方我需要先确认一下」,而不是一股脑往前冲。
然后聊一个我比较在意的事,排版和阅读体验。
4.8在Claude Code里输出的内容堆得太密了。尤其是中文,段落之间留白不够,一屏下来密密麻麻的,读起来费劲。
这个问题怎么说呢,4.7的排版更糟糕,4.7那个创作排版真的是一言难尽,所以4.8比4.7是有进步的。但跟4.6比还是差一截。4.6的排版是真舒服,段落节奏和留白都很到位,读起来一口气顺下来不累。
写代码的时候这个问题不太明显,代码本身就是结构化的。但如果你用Claude Code做内容创作或者写文档,阅读体验的下降你一定能感觉到。
而且4.8整体偏啰嗦。第三方评测数据说,4.8的输出token量大概是其他模型中位数的3倍。这一点在创作场景下尤其致命。
还有一个事,4.6被下架了。Claude网页端只保留两代,4.8上来4.6就没了。如果你之前的Prompt和工作流都是在4.6上调好的。。。
做好重新调的准备吧。我自己的Skill基本都得重新适配一遍,想想就头疼。
额度方面倒是有个好消息。4.8刷新了订阅的Usage limits,不管是5小时还是按周算的限额都已经更新了,大家可以放心用。整体消耗没比4.6多太多,如果你是中度使用者,Max 5x套餐撑多个项目完全没问题。
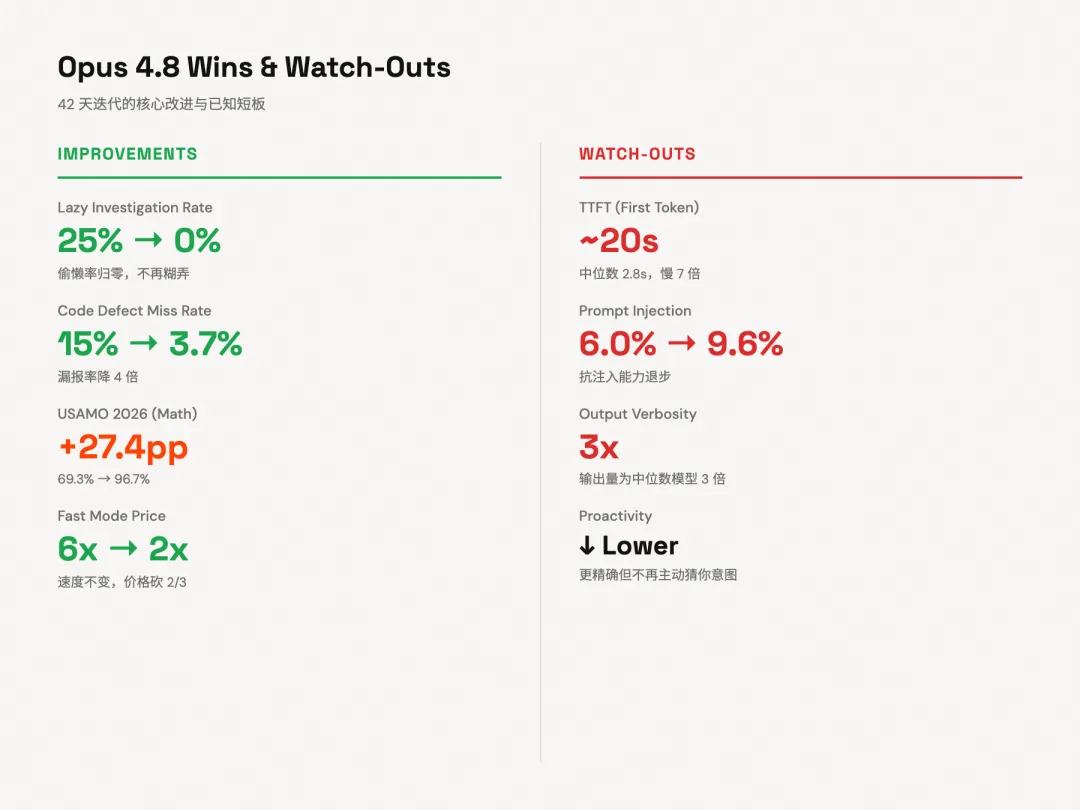
官方数据里还有一个数字我觉得值得说一下。Lazy investigation rate,就是模型碰到问题不认真排查就糊弄你的概率,从4.7的25%降到了4.8的0%。
零。
配合我自己「它会主动查文档」的体感,这个数字是可信的。从系统卡里的对齐安全评分来看,4.8的误对齐行为分数也从4.7的2.47降到了1.82,更诚实、更不容易配合你犯错。
Cursor的CEO说tool calling效率提升了,用更少步骤达到同样效果。Cognition的CEO Scott Wu说4.8修复了4.7的注释冗余和tool-calling问题,可以跑无人值守的工程流水线了。
这些改善不性感,不像数学暴涨30个百分点那么有冲击力。但对每天在用Claude干活的人来说,这才是你真正会感觉到的东西。
还有两个跟用法直接相关的更新提一下。
Effort控制,以前只有Claude Code里有,现在开放给了所有用户,免费用户也有。你可以手动调思考深度,从Low到Max。4.7只有自适应思考,不太能精确控制,4.8算是把操控权还给了用户。
Dynamic Workflows,让Claude自己编排脚本,在一次任务里拉起几十甚至上百个子agent并行干活。触发方式两种,直接跟Claude Code说「创建一个动态工作流」,或者把effort调成Ultracode让它自己判断。我还在小规模摸索,没跑通大场景,但方向是对的。
Fast mode也降价了,从标准版6倍价格降到2倍,速度还是2.5倍。Databricks那边说多模态处理的token成本比4.7便宜了61%。
好,主菜聊完了。来一点甜品。

聊聊同一天官宣的那笔650亿。
估值9650亿,距离一万亿差不到一个DeepSeek的估值。Anthropic用这一轮第一次在一级市场和二级市场上同时超过了OpenAI。
但数字不是最有意思的,投资方名单才是。
Micron、Samsung、SK hynix。全球仅有的三家HBM内存供应商,全部入股了Anthropic。有分析认为这根本不是传统的VC投资,而是以股权换芯片供应优先权的垂直整合协议。想想也对,在算力白热化的当下,确保芯片供应链稳定可能比模型多涨几个百分点更重要。
Cap table就是产业政策。
Anthropic的年化收入14个月涨了14倍,从10亿到470亿美元。用户量只有ChatGPT的5%,但单用户月均收入211美元,OpenAI大概25美元。5%的用户量,8倍的客单价。Claude Code一个产品就占了AI编程市场42%到54%的份额,年化收入25亿美元。
选在发模型的同一天官宣融资,不是巧合。模型制造技术领先的叙事,在投资人FOMO最强的窗口签支票。OpenAI也是这个套路,GPT-5发布后紧跟估值轮次,GPT-5.5发布同期秘密提交了S-1。模型即估值锚。
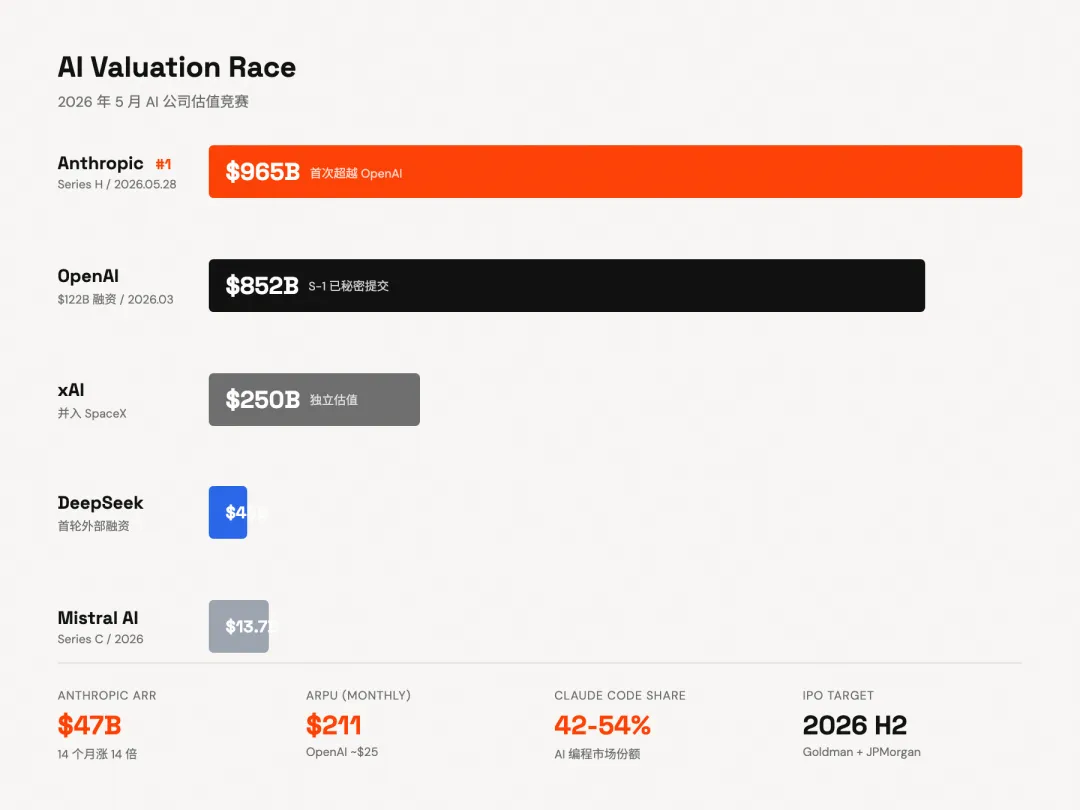
而且这两家现在都在冲IPO。Anthropic找了Goldman Sachs和JPMorgan做顾问,目标2026下半年。OpenAI预计最快9月。
有意思的是,就在4.8发布两天前,Altman和Amodei几乎同时收回了「AI会导致大规模失业」的预测。Altman说自己之前的判断「pretty wrong」,Amodei转向了杰文斯悖论的叙事。CEO一边说AI会让百万人失业,一边喊自己公司值一万亿,这两句话放在同一份招股书里,投资人会觉得你精神分裂。
从恐惧叙事到共存叙事的转向,与其说是认知更新,不如说是上市前的公关校准。
AI公司正在从实验室变成上市公司。这个身份切换可能比任何模型升级都有意思。
哦对了,Anthropic还留了个钩子。除了Opus这条线,手里还有一个代号Mythos的更高级别模型,属于Project Glasswing。几周后开放。从系统卡的数据看,Mythos Preview的对齐评分比4.8还好。更强,也更安全。
回到4.8本身。
对我来说,这次更新最重要的不是跑分涨了多少,而是工作方式变了。以前它是一个很聪明但经常自以为是的助手,你得盯着它、push它、帮它查资料。现在它开始学会先查资料、先确认理解、先看全局再动手。
作为一个PM,我不需要模型更聪明了。我需要它更靠谱。
4.8朝着这个方向走了一步。
不是一大步,但方向对了。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~ 谢谢你看我的文章,我们,下次再见。