 夜雨聆风
夜雨聆风





FinDocMRE:多模态大模型金融文档推理评估基准
“FinDocMRE: A Benchmark for Document-Level Financial Multimodal Reasoning Evaluation”

【 扫描文末二维码加入星球获取论文 】
摘要
LMMs在通用视觉任务表现出色,但在金融场景应用不足,现有基准忽视金融文档多模态数据整合。为此推出FinDocMRE多图像文档级金融多模态推理基准,通过半自动化流程构建数据集,含12207个样本,覆盖12个领域、5种任务类型。对11个LMMs的实验显示,无模型总分超65,各模型在不同任务表现差异大,擅长语义叙事,在数值估计和跨页视觉定位上表现不佳。FinDocMRE可引导金融LMMs向专家级文档分析推理发展。
简介
LMMs多模态理解与推理能力在金融领域应用受关注,以往评估方法主要针对NLP任务或孤立图表理解,无法体现真实文档级金融分析复杂性。
构建文档级基准面临三挑战:数据难获取,高质量开源金融PDF少;标注成本高,人工设计问题耗力且需专业知识;生成质量差,LMM生成问题有文本偏差,缺乏数值精度。
本文提出FinDocMRE基准,用于评估文档级金融推理场景下的LMMs,通过半自动化构建流程(数据准备、以视觉为中心的问答生成、专家验证)得到高质量数据集。该基准有12,207个样本,来自2,878份金融报告,涵盖多行业、多种问题格式和推理类别。
对11个代表性LMMs和人类专家基线进行评估,发现定量计算和定性合成存在差异,多图像推理是瓶颈。
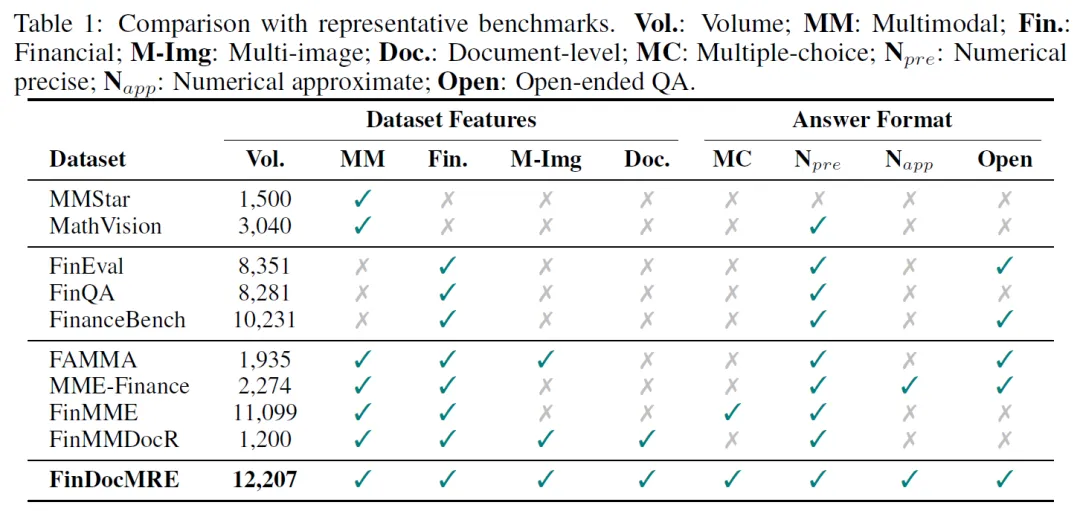
进行多维分析和消融研究,发现减少视觉搜索空间可提升性能,当前模型整合视觉基础和数值推理挑战大。
本文提出首个多图像文档级金融多模态推理基准,开发半自动化流程获高质量问答样本,对LMMs进行多维评估并对比分析。
相关工作
多模态大模型
LMMs在通用视觉理解和多模态推理方面进步显著,涵盖多种专有和开源模型。但在金融领域部署面临挑战,专业分析需视觉识别、数值推理和趋势解读。其作为金融代理在文档密集场景的可靠性待探索,需超越孤立任务的评估范式。
多模态基准
现有通用多模态基准(如 MME 等)在金融场景有局限,多为孤立视觉问答,未满足复杂领域需求;文档中心数据集(如 DocVQA)重 OCR 和实体提取,忽略跨模态数据综合推理。为此开发 FinDocMRE,以衔接基础视觉感知与专业文档分析推理。
金融基准
文本领域金融评估基准从聚焦特定 NLP 和推理任务发展到评估整体金融素养,近期扩展到视觉模态,但多依赖孤立、预定位图像。FinMMDocR 研究文档级金融推理,FinDocMRE 评估规模更大、任务格式更多样。
FinDocMRE 通过半自动化流程构建,包括数据准备、以视觉为中心的生成和专家验证,结合自动化生成的可扩展性和人工审核确保推理准确性。
FInDocMRE
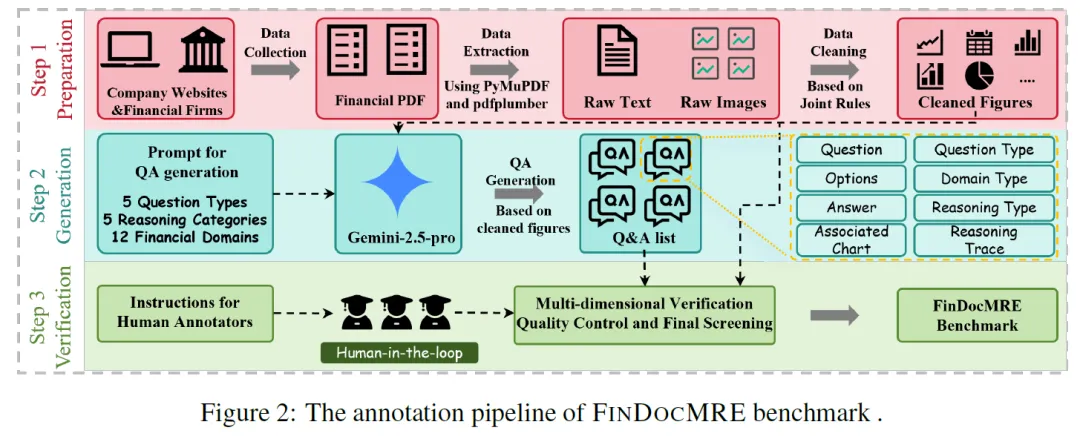
数据准备
数据采集:构建反映现实场景的基准,从官方网站和第三方聚合器收集 2878 份金融 PDF(2469 份中文、409 份英文),来源涵盖国内外权威机构,优先选取专业分析所需文档类型,排除纯文本文件以聚焦多模态推理。
以图表为中心的提取与清理:采用以图表为中心的提取流程,用 PyMuPDF 和 pdfplumber 解析图像和文本。运用联合规则过滤机制:几何过滤去除极端长宽比或低分辨率的布局伪影;语义过滤通过图像相似度计算去重,用 OCR 过滤非信息元素;文本索引验证仅保留叙述中明确引用的图表以确保分析相关性。
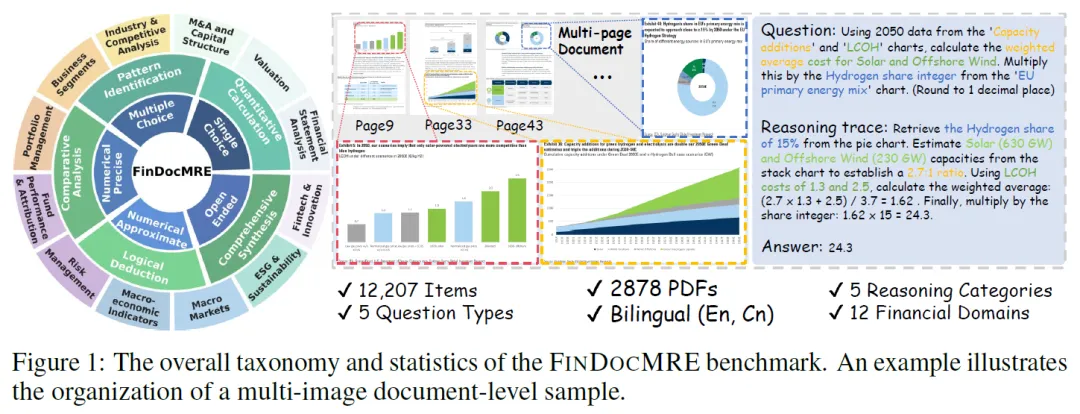
可视化样本生成
初步实验发现喂入全 PDF 页或带周边文本的图像会影响图表解读,采用 Gemini – 2.5 – Pro 以视觉为中心的生成策略,将提取的图表组合成图像序列,让模型生成问答对和推理痕迹,仅依据视觉数据推导见解。
为确保难度梯度,在生成提示中纳入多维分类法,涵盖 12 个金融领域和 5 个认知推理类别,应用严格 JSON 模式约束 5 种问题格式。
每个生成样本为包含问题、答案、领域类型和推理类型的元数据对象,需生成详细推理痕迹,模型记录相关图表 ID 以关联查询与证据。
专家校验
为应对视觉生成幻觉风险、保证专业保真度,采用人在环(HITL)验证流程,由三位超三年证券经验的资深金融研究员,按严格注释协议,对照源图表审核文档及生成样本,验证问题逻辑、选项合理性、答案准确性和关联图表 ID 精确性。验证团队严格筛选而非手动修正,采用一致共识机制,有专家发现缺陷则样本丢弃,仅无保留通过验证的样本纳入 FinDocMRE 基准,最终保留率约 55%。
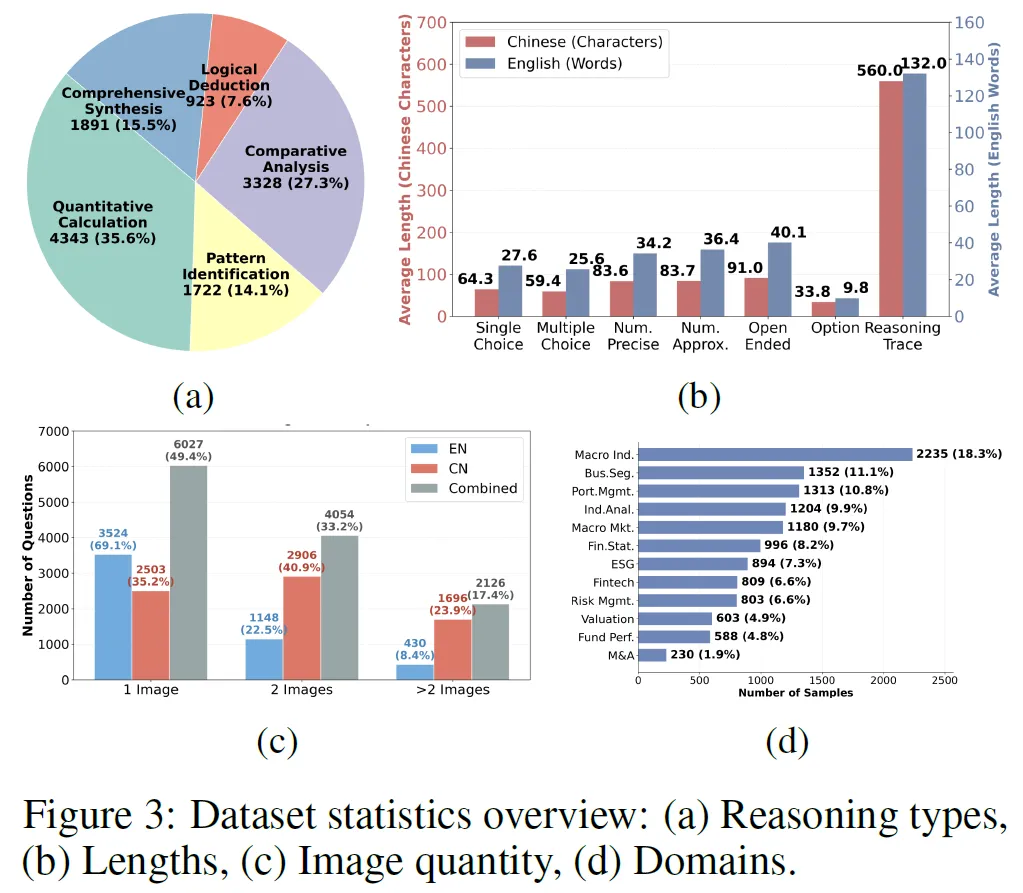
数据统计
数据规模与语言:FinDocMRE 含12,207个标注样本,来自2,878份金融文档,有7,105个中文和5,102个英文问答对,用于跨语言推理评估。
问题类型分布:区别于一般多模态数据集,FinDocMRE侧重定量分析,数值推理占39.8%,开放式查询占20.4%。
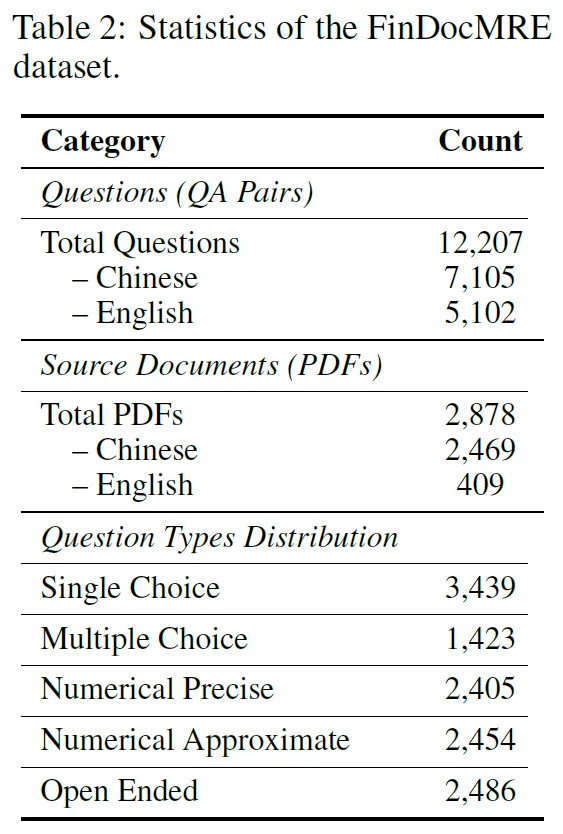
推理难度与视觉依赖:中文样本平均CoT长度560字符,英文132词,需多步推理;约50.6%问题需跨图表综合信息,图3展示其在不同金融领域和推理类型的覆盖情况。
实验
评估模型
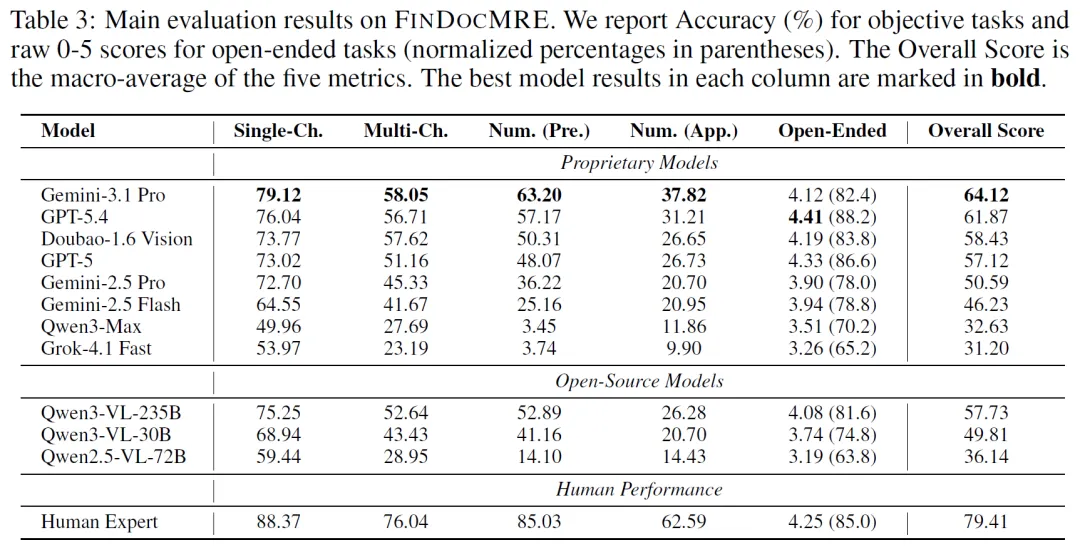
为评估先进大语言多模态模型(LMMs)在金融文档多关系抽取(FinDocMRE)的表现,选9个模型(含9个专有模型和3个开源模型)在零样本设置下测试其固有金融文档推理能力,排除小架构及高拒绝率模型;还邀请两位证券业专业金融分析师完成基准测试,以其平均分代表人类专家表现。
评估指标
评估策略:对确定性任务(单/多选、数值推理)用标准准确率,多选需与答案集精确匹配,数值估算有 5%相对误差容忍度,精确计算要求完全相等;对开放式查询采用 LLM 评判范式,用三个模型打分取平均。
总体得分:采用宏平均策略,将开放式得分缩放至 0 – 100 范围,计算五类问题的未加权均值,减少类别样本量不平衡的偏差。
多维度分析
主要结果:Gemini – 3.1 Pro(64.12)和Qwen3 – VL – 235B(57.73)整体得分最高,Qwen3 – VL – 235B在单项选择和数值精确任务中表现佳,但所有模型与人类专家基线(79.41)仍有约15分差距。视觉感知与定量推理表现差异大,数值近似任务精度低,GPT – 5.4在开放式场景语义得分领先。
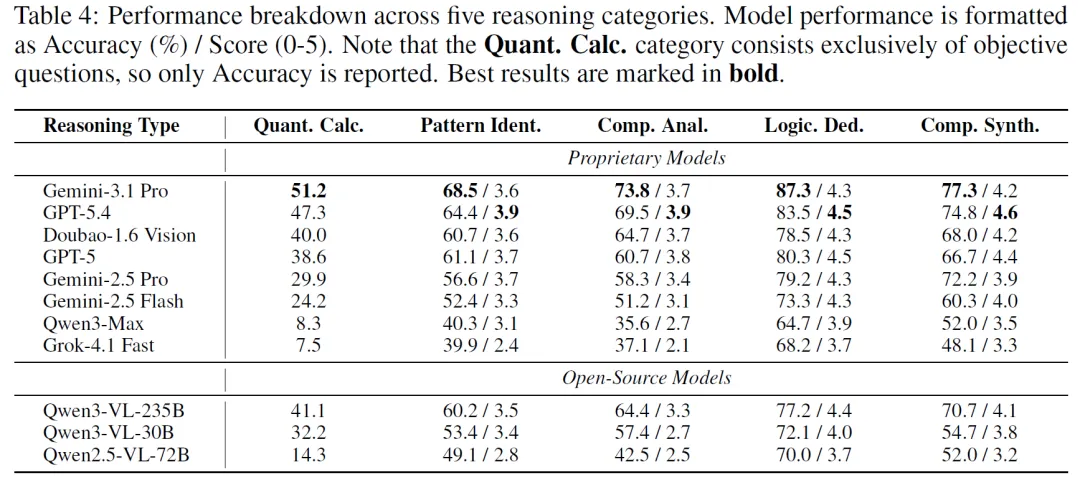
金融领域表现:不同模型在计算和综合方面表现有别,Gemini – 3.1 Pro在定量领域领先,GPT – 5.4在定性推理中出色。“微观”领域比“宏观”领域表现好,Gemini – 3.1 Pro在金融科技领域泛化能力强。
推理类型表现:Gemini – 3.1 Pro和GPT – 5.4在定量计算领先,在抽象推理中情况反转。Gemini – 3.1 Pro在逻辑演绎准确性高,GPT – 5.4语义得分高;在综合合成中,Gemini – 3.1 Pro客观准确性高,GPT – 5.4语义质量领先。
模型规模与进化影响:Qwen系列中,v3代内参数规模大的模型表现更好,跨代比较显示算法优化和多模态数据对齐对金融推理比参数数量更关键。
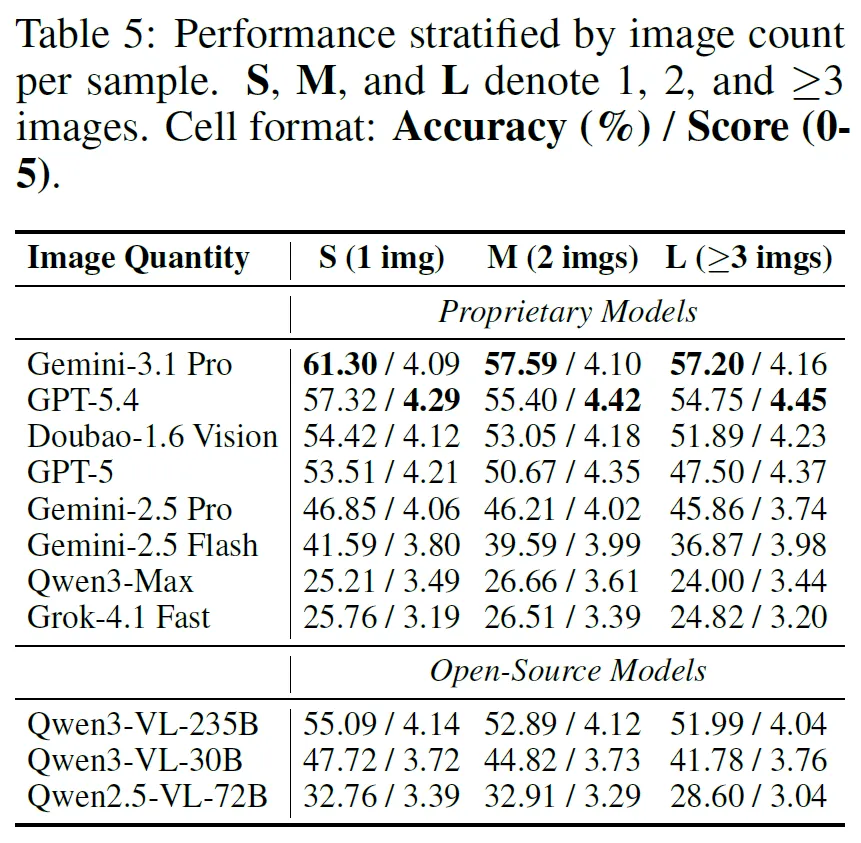
视觉复杂度影响:跨图表推理中,客观任务性能随视觉依赖增加而下降,开放式得分在复杂场景下稳定或提升。
语言表现:存在语言对齐偏差,Gemini – 3.1 Pro在英语子集领先,GPT – 5.4开放式任务表现佳;中文子集本土架构有主场优势,GPT – 5.4开放式得分高,感知与推理可分离。
消融分析
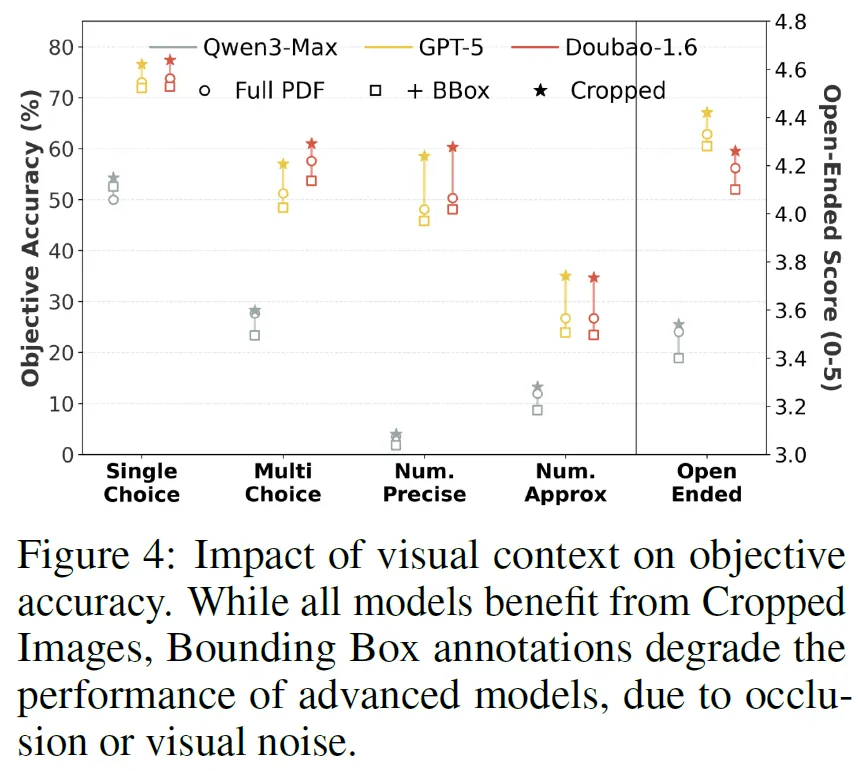
视觉上下文策略影响:通过三种策略进行消融研究,对比发现“裁剪图像”设置下领先模型精度最高,显示多页文档定位视觉证据是挑战;“PDF + 边界框”策略未提升性能,反而因视觉干扰等降低高容量模型精度。
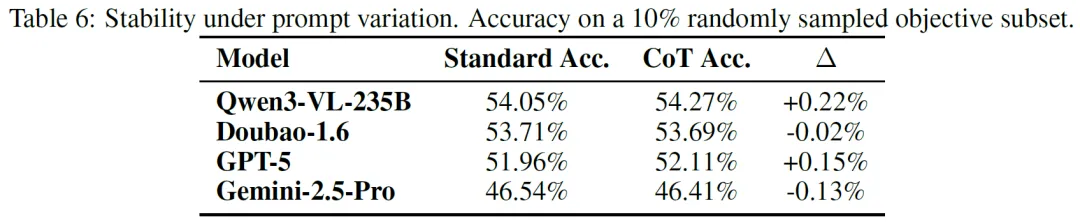
对提示变化的鲁棒性:在10%客观问题子集上对比标准提示和思维链提示,各模型性能波动小(∆<1%),模型相对排名不变,表明评估性能能反映模型文档理解能力,对提示变化有稳定鲁棒性。
案例分析
图5展示跨页乘法任务测试细粒度视觉定位。Qwen3 – VL – 30b虽定位目标图表,但推理易受视觉显著性偏差影响,无视图例约束致计算错误(本应26.6,算成76.0);GPT – 5能有效实现图例与像素对齐,过滤视觉噪声定位数据点。

总结
本文介绍FinDocMRE基准,其旨在推动多模态金融推理从孤立图表向文档级多模态情境发展,通过特定流程从金融报告编译12,207个样本,实验揭示“分析师 – 计算器二分法”,消融研究确定“视觉锚定瓶颈”,建议未来研究转向能长上下文锚定和工具辅助计算的代理架构。
目前FinDocMRE仍有两个局限:一是评估限于零样本设置,因样本含完整PDF文档及问答,提供少样本示例会超多数模型上下文窗口限制;二是单轮问答简化了复杂的专业金融工作流程,基准目前聚焦基础推理单元,多轮代理评估留待后续研究。
我们致力于人工智能、量化交易领域前沿研究,分享前沿论文、模型代码、策略实现。如有相关需求,请私信与我们联系。
请加微信“LingDuTech163”,或公众号后台私信“联系方式”。
关注【灵度智能】公众号,获取更多AI资讯。