 夜雨聆风
夜雨聆风





Word2Vec:词向量与语义空间
如何让计算机理解”苹果”和”香蕉”比”苹果”和”手机”更像?早期用 One-hot 编码,每个词是一个独立的符号,维度高达数万维,而且词与词之间没有任何相似度。Word2Vec 用一个简单的两层网络学出了携带语义的词向量,让语义相近的词在向量空间中也彼此靠近。这是算法学习笔记系列的第 14 篇。
什么是词向量?
设想把每个词表示为一个 One-hot 向量,词表有 N 个词,每个词就是一个 N 维向量,只有自己那维是 1,其余全是 0。这有两个问题:维度高达上万,且任意两个词的向量之间距离都相等,”猫”和”狗”的余弦距离跟”猫”和”手机”一样远,词与词之间毫无语义关联。
词向量(Word Embedding) 的思路则是把每个词映射为一个固定长度的稠密向量,比如 64 维。所有词向量放在一起,就构成一个语义空间,同类的词聚在一起:”猫””狗””兔子”在动物区,”跑””跳””走”在动作区。只不过这个空间有几十个维度,没法直接画出来,需要用 PCA 降到二维才能看到大致轮廓。
Word2Vec 就是学习这种词向量的方法。它用一个简单的两层网络,基于分布式语义假说(一个词的语义由它周围的词决定),通过预测词的上下文来学习向量表示(Efficient Estimation of Word Representations in Vector Space, Mikolov 2013)。
一、分布式语义假说与 Skip-gram
英国语言学家Firth 在 1957 年说了一句经典的话:
“You shall know a word by the company it keeps.”
一个词的语义,由它周围的词决定。
这就是分布式语义假说。想想看:当我们看到 “I drank ___”,即使空格被遮住,我们也能猜到这个词大概率是咖啡、茶、水之类的饮料。词的含义来自于它的上下文。
Word2Vec 正是基于这个思想:用一个词的上下文来学习它的向量表示。有两种实现方式:
-
CBOW (Continuous Bag of Words):用上下文词预测中心词 -
Skip-gram:用中心词预测上下文词
这里我们实现 Skip-gram,因为它对低频词更友好,在小数据集上效果更好。
Skip-gram 的结构非常简单:
-
在词表中用 One-hot 表示中心词 -
通过嵌入矩阵 映射为稠密向量 -
通过另一个矩阵 计算与所有上下文词的相似度 -
用 Softmax 转化为概率,最大化上下文词的概率
训练一个 Skip-gram 就是在最大化:
其中 是给定中心词 时上下文词 出现的概率。
这里有个问题:直接用 Softmax 计算这个概率,每次都需要对整个词表求和,计算量太大。
二、Negative Sampling:高效训练的秘诀
原始的 Word2Vec 用 Softmax,但对于 5 万词的词表,每次前向都需要算 5 万个指数,太慢了。
Mikolov 提出了 Negative Sampling:把多分类问题转化为二分类问题。
对于每个正样本(中心词,真正的上下文词),模型要学习判断这对词是否真的相邻。同时随机采样 k 个负样本(中心词,随机选的其他词),模型要能判断这些不是真正的搭配。
优化目标变成二分类的交叉熵损失:
其中 是 Sigmoid 函数, 是中心词向量(代码中的 W_in[center_idx]), 是上下文词向量(W_out[:, context_idx]), 是负样本向量(W_out[:, neg_idx])。
这样每次训练只需要计算 个 Sigmoid,通常是 5-20 个负样本。对比 Softmax 每次需要对整个词表(5 万词)算一遍指数,训练速度快了几千倍。
负样本的采样并不是均匀的,而是按照词频的 次方分布采样,这样既能保证低频词有一定被采样到的机会,又不会让高频词(”的”、”了”)霸占所有负样本。
三、实验:语义空间可视化
在 Tiny Shakespeare 数据集(前 30 万字符,1184 词词表)上训练 8 轮,损失曲线如下:
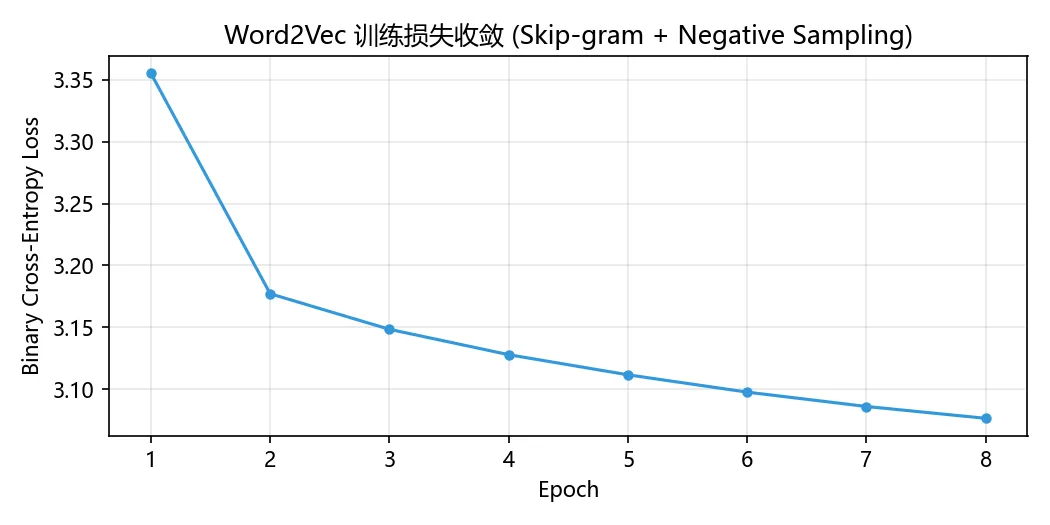
Word2Vec 训练损失曲线,8 轮中平稳下降
损失从 3.35 下降到 3.08,模型在持续学习词汇的分布模式(作为参考,随机初始化时预期损失约 7.6,对应所有 Sigmoid 输出均为 0.5)。
来看看学到的词向量效果。每个词后面列出的是与之余弦相似度最高的 5 个词,括号里的数值是相似度分数(0 到 1,越高越接近):
king → richard(0.61), sovereignty(0.55), ely(0.53), prince(0.53), unless(0.51)queen → margaret(0.67), elizabeth(0.66), bitter(0.54), wrong(0.53), words(0.51)love → heart's(0.64), claim(0.57), stones(0.56), kiss(0.55), country's(0.55)death → justice(0.52), charity(0.51), thine(0.51), lost(0.47), throne(0.47)heart → sorrow(0.54), lip(0.52), cheeks(0.51), mistress(0.51), adversaries(0.49)sword → begin(0.56), draw(0.56), kindly(0.55), eye(0.54), injury(0.54)god → bless(0.52), uncle(0.50), will(0.48), remember(0.47), counsel(0.46)father → brother(0.59), stabb'd(0.54), princely(0.54), brow(0.53), son(0.51)几个有意思的发现:
-
king→richard:因为 Richard III 是莎士比亚作品中的重要角色 -
queen→margaret,elizabeth:剧中关键女性角色 -
love→heart's,kiss:情感语义聚合在一起 -
sword→draw,injury:战场场景的词汇关联 -
father→brother,son:家族关系聚类效果明显 -
god→bless:宗教语义
尽管训练数据只有 30 万字(不到一部小说的量),词向量已经能捕捉到相当丰富的语义关系。
3.1 PCA 可视化
把学到的 1184 个词向量用 PCA 投影到二维平面:
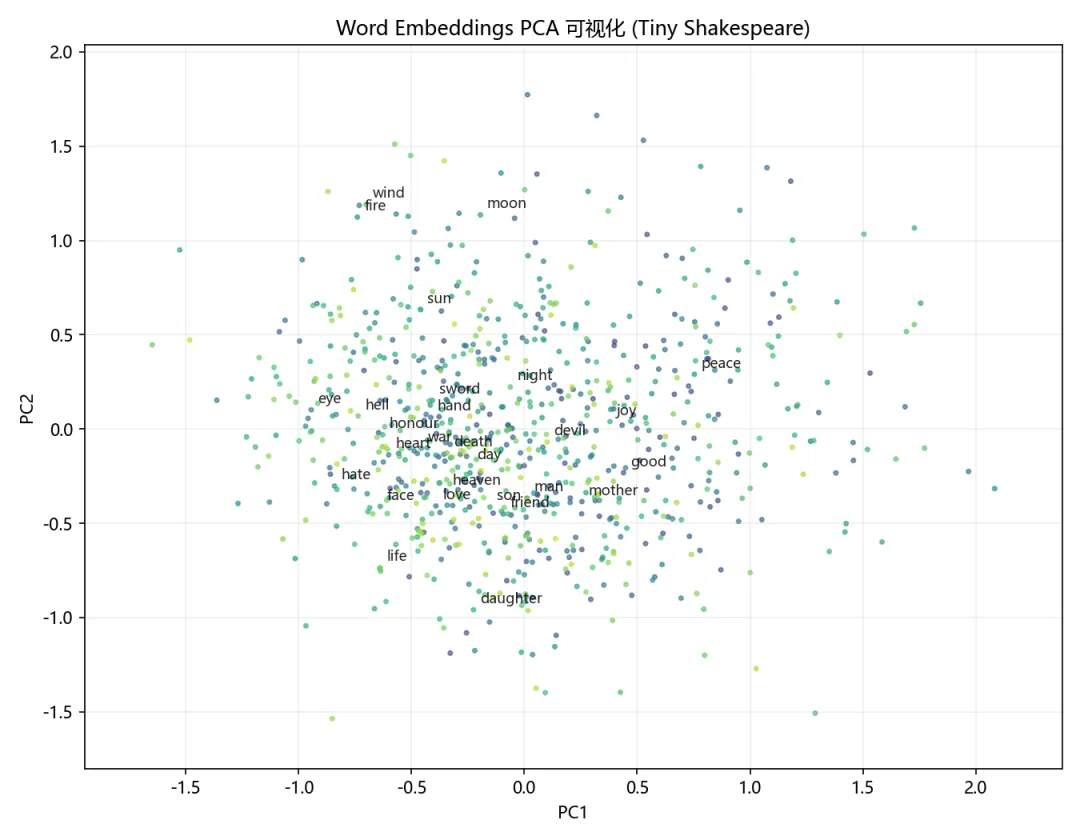
词向量的 PCA 二维投影,语义相近的词在空间中彼此靠近
可以看到语义相关的词在空间中确实彼此靠近。例如图中 king、queen、prince 聚集在左上区域,father、mother、brother 等家族词汇在右侧形成另一个集群。
为了更好地观察关系,选取部分关键词单独展示:
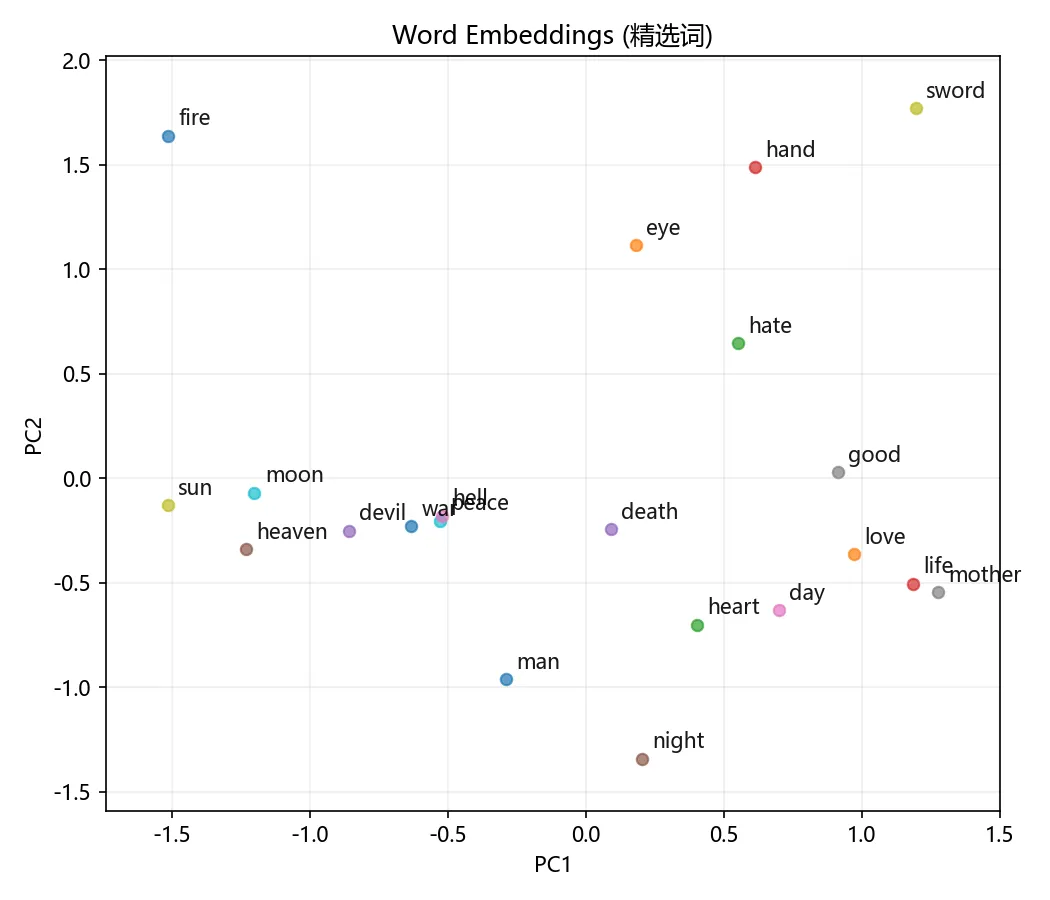
精选关键词的 PCA 投影,同一语义类的词汇形成明显聚类
虽然 Shakespeare 时代的英语与现代英语差异较大,但我们仍然能观察到一些语义聚类:
-
king,queen,prince等贵族称谓彼此接近 -
god,devil,heaven,hell等宗教词汇相互关联 -
sun,moon,star等天体词汇靠近 -
father,mother,brother,sister家族关系聚类明显
但需要注意,PCA 将高维向量(64 维)压缩到二维会丢失部分信息,图中距离较近的词在高维空间中不一定真的最相似。更精确的做法是直接计算余弦相似度。
3.2 向量的算术
Word2Vec 最令人惊叹的特性是词向量之间的语义类比。我们可以对词向量做加减法:
vector('king') - vector('man') + vector('woman') ≈ vector('queen')这是 Word2Vec 论文中最著名的例子,词向量空间中的方向和偏移量编码了语义维度。
不过在我们的模型上,由于训练数据较小(30 万字、1184 词词表),类比效果还很有限:
king - man + queen → world(0.51), sign(0.50), fellow(0.47), loss(0.45), note(0.44)man - woman + king → stabb'd(0.48), force(0.48), plantagenet(0.48), humour(0.47), catesby(0.44)day - night + sun → sovereignty(0.53), whole(0.51), thereof(0.50), nobles(0.48), crown(0.47)在小数据集上,类比推理需要更充分的训练才能稳定出现。原论文在 1000 亿词的 Google News 上训练,才能稳定复现 “king – man + woman ≈ queen” 这类效果。
四、意义与局限
Word2Vec 用简单的神经网络学会了携带语义的词向量,分布式表示远比 One-hot 高效,维度从 5 万降到了 100-300。预训练词向量从此成为 NLP 的基础设施,被广泛用于文本分类、序列标注、机器翻译等任务。时至今日,推荐系统中的物品嵌入(Item2Vec)、搜索召回中的快速语义匹配,都延续着同样的思路。
局限也很明显:一个词只有一个静态向量,无法区分多义词(”Love Apple” 和 “eat an apple” 中的 apple 是同一个向量);窗口通常只有 5-10 个词,无法捕捉长距离依赖。这些正是后来 ELMo、BERT、GPT 等上下文预训练模型要解决的问题。
代码实现:models/word2vec.py
完整实验:notebooks/day14_word2vec.ipynb