OpenClaw 技术架构解析:一个多智能体平台是如何设计的?
某个团队做了一个内部智能助手,接了飞书,跑得还不错。后来业务扩张,要同时支持钉钉、WhatsApp、企业微信。结果怎样?每接一个新平台,就得重写一遍消息处理逻辑,权限校验写了又写,上下文状态管理像一团乱麻,工具调用时还偶尔出现跨会话的数据串扰。
这不是个例,这几乎是所有”从单个 Agent 长出来”的系统,走到多渠道、多工具、多人协作时,必然会遭遇的架构危机。
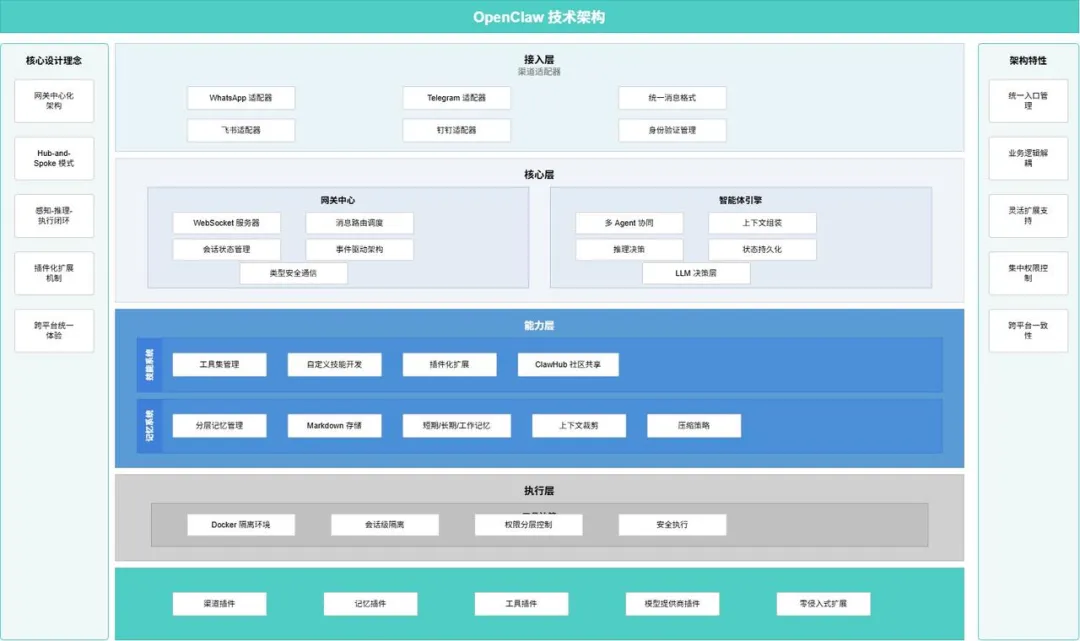
OpenClaw 的架构图乍一看信息量很大,但它有一个清晰的阅读逻辑。
从上到下,是一条消息的流动路径:用户发来的请求,从接入层进来,经过核心层的网关和引擎处理,调用能力层的工具和记忆,最终在执行层完成任务。
从左到右,是设计理念和架构特性的对应:左边列出的”网关中心化””Hub-and-Spoke 模式””感知-推理-执行闭环”,你能在图的主体结构中逐一找到对应的实现;右边的”统一入口管理””业务逻辑解耦”等,则是这套架构最终呈现出来的系统特性。
最下面单独有一层插件扩展层,它不在主流程里,却撑起了整个平台的生态弹性。
一个用户在飞书发了一条消息,另一个用户在 Telegram 发了一条,第三个用户在 WhatsApp 发了一条。
这三条消息,在各自平台上的数据结构完全不同。飞书有自己的消息体格式,Telegram 的 Bot API 返回的是另一套 JSON,WhatsApp Business API 又是一套。如果让上游的智能体引擎直接对接这些差异,代码会烂得很快。
每个渠道各自有一个适配器,负责把平台特有的消息格式,转换成系统统一的内部消息格式。从那一刻起,不管消息从哪里来,对核心层来说长得都一样。
身份验证也在这一层完成。用户是谁、有什么权限,在消息进入系统之前就已经确认好了,不需要在后面的每个模块里重复校验。
这个设计的价值不只是”整洁”,更重要的是:接一个新平台,只需要写一个新的渠道适配器,核心逻辑完全不动。
三、核心层(上):网关中心,解决”交通调度”的问题
可以把网关中心想象成一个智能交通调度系统。WebSocket 服务器维持着和各个客户端的实时连接,消息路由调度根据消息来源、用户身份和当前会话状态,决定这条消息该交给哪个 Agent 处理。
会话状态管理是这里最容易被忽视却最重要的能力。连续对话能不能顺畅,多轮任务能不能接得上,全靠它。如果状态管理做不好,每次对话对系统来说都像是第一次见面,Agent 会显得又健忘又割裂。
事件驱动架构的引入,让整个系统的模块之间不再是直接调用关系,而是通过事件来解耦。一个模块完成了某件事,发出一个事件,其他模块监听并响应。这种方式在系统复杂度上升之后,会显著降低维护成本。
类型安全通信,则是一道防线——确保模块之间传递的数据结构是清晰定义的,不会因为某个地方悄悄改了字段名,引发一连串难以追踪的运行时错误。
如果说网关中心是交通枢纽,智能体引擎就是这个系统真正的大脑。
先说多 Agent 协同,这是 OpenClaw 架构里最值得展开讲的部分。
单个 Agent 处理复杂任务有天然的上限。一个需要先查资料、再分析、再生成报告、最后发送通知的任务,如果全压在一个 Agent 上,提示词会很长,出错率会升高,而且难以复用和调试。
更好的方式是把任务分配给多个专职 Agent:一个负责信息检索,一个负责分析推理,一个负责生成内容,一个负责执行操作。它们之间有协作协议,有任务传递机制,相互配合完成整体目标。
上下文组装是另一个关键环节。在把请求送进大模型之前,需要把用户的当前输入、历史记忆、系统状态、工具调用结果等信息,拼装成一个完整的推理上下文。这个拼装过程做得好不好,直接影响大模型最后输出的质量。
推理决策层,也就是 LLM 决策层,是整个引擎的核心。它负责理解用户意图、规划任务步骤、判断下一步该调用哪个工具还是继续追问。
状态持久化在这里承担了”记录员”的角色——任务执行到哪一步、中间产生了哪些关键结果,都需要保存下来,方便后续的恢复、追踪和审计。
五、能力层:工具让 Agent 能干事,记忆让 Agent 记得住
一个 Agent 光会说话没用,它得能干事。这是工具系统的职责。
工具集管理负责维护系统里所有可调用的工具,包括内置的和外部接入的,每个工具有自己的权限范围和版本记录。开发者可以根据业务需求开发自定义技能,封装进来供 Agent 调用。
ClawHub 社区共享值得单独提一下。它的逻辑是:如果你为自己的业务开发了一个好用的工具插件,可以沉淀到社区里,供其他开发者复用。这和 npm、VS Code 插件市场的逻辑是一样的——生态的价值来自于共建和共享,而不只是平台方自己造轮子。
记忆系统解决的是另一个问题:Agent 怎么”记事”。
OpenClaw 把记忆分成了三层:短期记忆处理当前会话的上下文,工作记忆服务于正在执行的任务,长期记忆保存用户的偏好、历史知识和重要信息。
上下文裁剪和压缩策略,解决的是”记忆太多”的问题。把所有历史信息都塞进上下文,模型的处理成本会很高,而且效果未必更好。裁剪和压缩的作用是,在保留关键信息的前提下,只把当前任务最需要的内容送进去。
Markdown 存储这个选择看起来朴素,但有一个实用的好处:记忆内容对人类友好,可以直接阅读和编辑,也便于做版本管理。
Agent 调用了一个第三方工具,这个工具出了 bug,影响到了系统的其他部分;两个用户的会话数据偶尔串了,信息泄露;某个工具调用触发了一个危险操作,无法回溯是谁在什么情况下触发的。
这些场景在企业级应用里不是假设,是必须提前防范的真实风险。
Docker 隔离环境把任务运行在独立容器里,任何问题都限制在容器边界内,不会蔓延到宿主系统。会话级隔离确保不同用户、不同会话之间的数据和状态完全分开。权限分层控制根据用户身份和工具的敏感程度,设定不同的访问边界。
这一层在产品演示时往往是最不显眼的,但它决定了一个 Agent 平台能不能真正在企业环境里落地。
最后说插件扩展层,它在架构图里放在最下面,却可能是整个架构最值得投资的部分。
四类插件——渠道插件、记忆插件、工具插件、模型提供商插件——对应的是四个扩展维度。接入新的通信平台,换一套存储方案,集成新的外部 API,切换或新增大模型服务,都可以通过插件完成,不需要动核心系统的代码。
“零侵入式扩展”这五个字看起来是技术描述,背后藏着一个重要的工程哲学:核心系统一旦稳定,就应该尽量保持稳定,扩展性要在外围实现,而不是靠反复修改内核。
这个逻辑和 VS Code 的成功高度相似。VS Code 本身只是一个编辑器,但它的插件体系让它变成了一个几乎无所不能的开发环境。OpenClaw 的插件层,走的是同一条路。
统一 vs 灵活。 网关中心化意味着所有流量都过同一个入口,这带来了统一管控的便利,也意味着网关本身成了系统的关键节点。这是主动选择的取舍,不是设计缺陷。
安全 vs 效率。 Docker 隔离、会话隔离都有额外的资源开销。对于轻量场景,这些开销未必值得;对于数据敏感的企业场景,这个代价必须付。
开放 vs 可控。 插件生态越开放,平台的潜力越大,但随之而来的是质量控制、安全审查和兼容性维护的压力。ClawHub 社区能走多远,很大程度上取决于这个边界怎么划。
没有完美的架构,只有在特定约束下做出的最优取舍。OpenClaw 的价值不在于它解决了所有问题,而在于它把问题想清楚了,然后给出了一个可以在上面继续建设的结构。
企业 AI 应用从”能用”到”好用、可信、可扩展”,中间那段路需要的,正是这样的底座。
 夜雨聆风
夜雨聆风