 夜雨聆风
夜雨聆风





openclaw、Hermes 越用越傻越烧钱,我用 Rust 重写的 small Rust Hermes,既省钱又好用
很多朋友都有这样的体验,小龙虾,Hermes,刚打开的时候挺灵的。你让它读代码、写应用、做技术报告,做汇报,它有模有样,开始看起来很懂你的样子。可聊着聊着、干着干着,它就开始变笨:指令越来越听不懂,同一个地方绕来绕去,token 账单蹭蹭往上涨,最后你自己都怀疑,是不是它偷偷把模型换成了渣渣版。
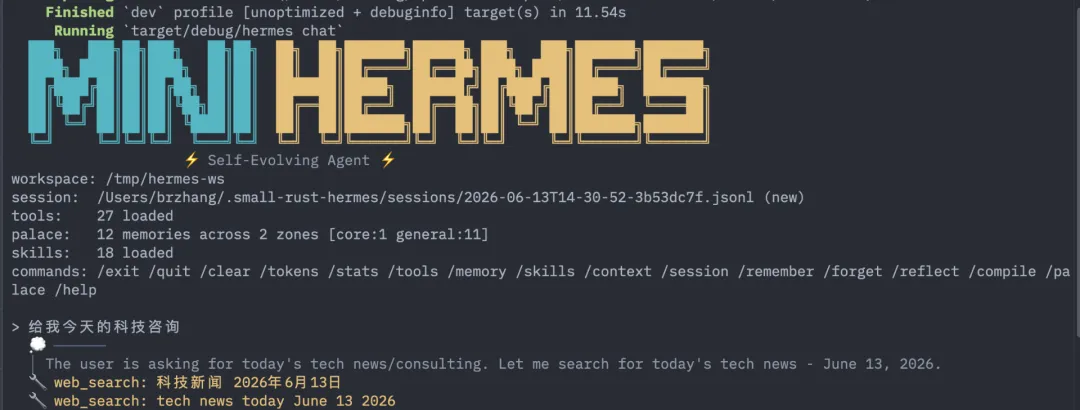
我用过 OpenClaw,也试过几个号称”全自主”的 Agent,结论挺一致:越用越傻,越用越贵。
一开始我也以为是模型不行。后来我自己动手,用 Rust 从零写了一个 agent 内核,对着 Claude Code 的设计抠了好几个月,才想明白一件事:问题几乎都不在模型,在模型外面那层壳。
行话管这层壳叫 harness。我得说句可能要得罪人的话:现在绝大多数 Agent 越用越傻,病根是它们把这层壳理解错了。它们都觉得壳是用来”堆功能”的,工具越加越多、选项越塞越满,结果模型站在一大堆功能面前反而懵了,不知道该挑哪个。
我的看法正相反:这层壳最难的地方不是加,是减。 没得选、只留一个最优解,才是最好的选择。难就难在,这个”唯一最优”特别不好找,找它远比多加十个功能费劲。openclaw 越做越臃肿,Hermes 也是;而我,偏要把 small Hermes 越做越简单。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这个项目我叫它 small Rust Hermes,平时我喊它”这只小怪兽”。这篇文章我不打算堆功能列表,就想借它跟你把一件事聊透:一个 Agent 到底聪不聪明、省不省钱,是被什么决定的。
如果你之前完全没听说过这个项目,没关系,我还是会科普下,但是还是建议你看看之前的演变思路,你才能够连接我做 small Rust Hermes 的核心思路。
先说人话:Agent 的那层”壳”到底是什么
模型是大脑。但你平时跟 Claude、GPT 聊天的那个对话框,并不等于一个 Agent。
一个能自己读代码、改文件、跑命令、查资料、一步步把活干完的 Agent,是「模型 + 一层壳」。这层壳,行话叫 harness,它干这么几件事:
|
|
|
|---|---|
|
|
|
|
|
|
说得再具体点,壳要维护一个循环:
你提一个需求 │ ▼模型想了想,说"我要先 grep 一下这个函数" │ ▼壳真的去执行 grep,把结果喂回给模型 │ ▼模型:"哦我懂了,改这一行",调用 edit 工具 │ ▼壳执行 edit,跑测试,把结果再喂回去 │ ▼……如此往复,直到模型说"干完了"这一圈一圈转下去,可能要二三十轮。壳做得好不好,直接决定了这二三十轮是顺滑高效,还是又笨又烧钱。
我的判断是这样:现在最强的几个模型,大家其实都用得起,差距没想象中那么大。真正拉开体验的,是外面这层壳。而一个 Agent “越用越傻越贵”的病根,绝大部分埋在壳里,不在模型里。
small Rust Hermes 这几个月,我干的事情就一句话:把这层壳,往干净、往透里做。
咱们这只small Hermes小怪兽长什么样
先给个整体印象。
它是用 Rust 从零写的,对标 Claude Code 的编码内核。12 个模块、两万行出头的代码,全程 forbid unsafe(一行不安全代码都不许有,Rust 圈的人懂这意味着什么)。而真正干活的那个 agent loop 内核,也就是 hermes-turn 加 hermes-core,两个加起来不到 2000 行。一个编码 Agent 的心脏,两千行就够了,剩下那些都是围着这颗心脏长出来的器官。
工具集是一个编码 Agent 该有的全套:读文件、写文件、精确改文件、跑 shell、按模式找文件(glob)、搜内容(grep)、看 git、搜网页、抓网页、还能派子 Agent。这套东西的完整度,已经是 Claude Code 的全部核心了,不是玩具,也不是巨无霸,该有的核心全都有。
模型上它三家都接:Anthropic、OpenAI、还有 DeepSeek。前端既有命令行,也有桌面 GUI,甚至能接到微信里跟你聊。
但这些”有什么”我不想多说,没意思。我想讲的是最近给它动的几刀,因为这几刀特别能说明,一个壳到底该怎么做才对。
提前打个招呼:下面这三刀,没有一刀是往上加功能的,全是”修”和”减”。但你千万别小看减法。每一刀砍下去之前,我都清楚它为什么在那、砍掉之后会怎样,砍的是冗余,留的是要害。这种”想透了再下刀”的减法,恰恰是我自己最得意的地方。
第一刀:让它别再烧冤枉钱,把缓存接上
先讲个最反直觉的事:Agent 烧钱,很多时候烧的是冤枉钱。
模型每调用一轮工具,壳都得把「系统提示词 + 全部工具定义 + 到目前为止的整段对话历史」重新发给模型一遍,按 token 收费。一个稍微复杂点的任务,模型要调二三十轮工具。这意味着最前面那段系统提示词和工具定义,被原价重复付费了二三十次。
Anthropic 早就给了解药,叫 prompt caching:把稳定不变的前缀缓存住,下次命中只收十分之一的钱,而且还更快。这是省钱的命门。
然后我给你讲个我自己踩的坑,特别典型。
我去通读这只小怪兽的代码,发现缓存这套东西,架构全都搭好了:系统提示词被精心设计成逐字节稳定(连当前时间这种每轮都变的东西,都特意挪到别处去,就为了不破坏缓存),缓存开关也一路从上层传了进来。看起来万事俱备。
可我顺着这根线摸到最底层、真正发 HTTP 请求的地方,傻眼了:这个开关,在最后一步被忽略了。全项目搜 cache_control 这个关键字,零命中。
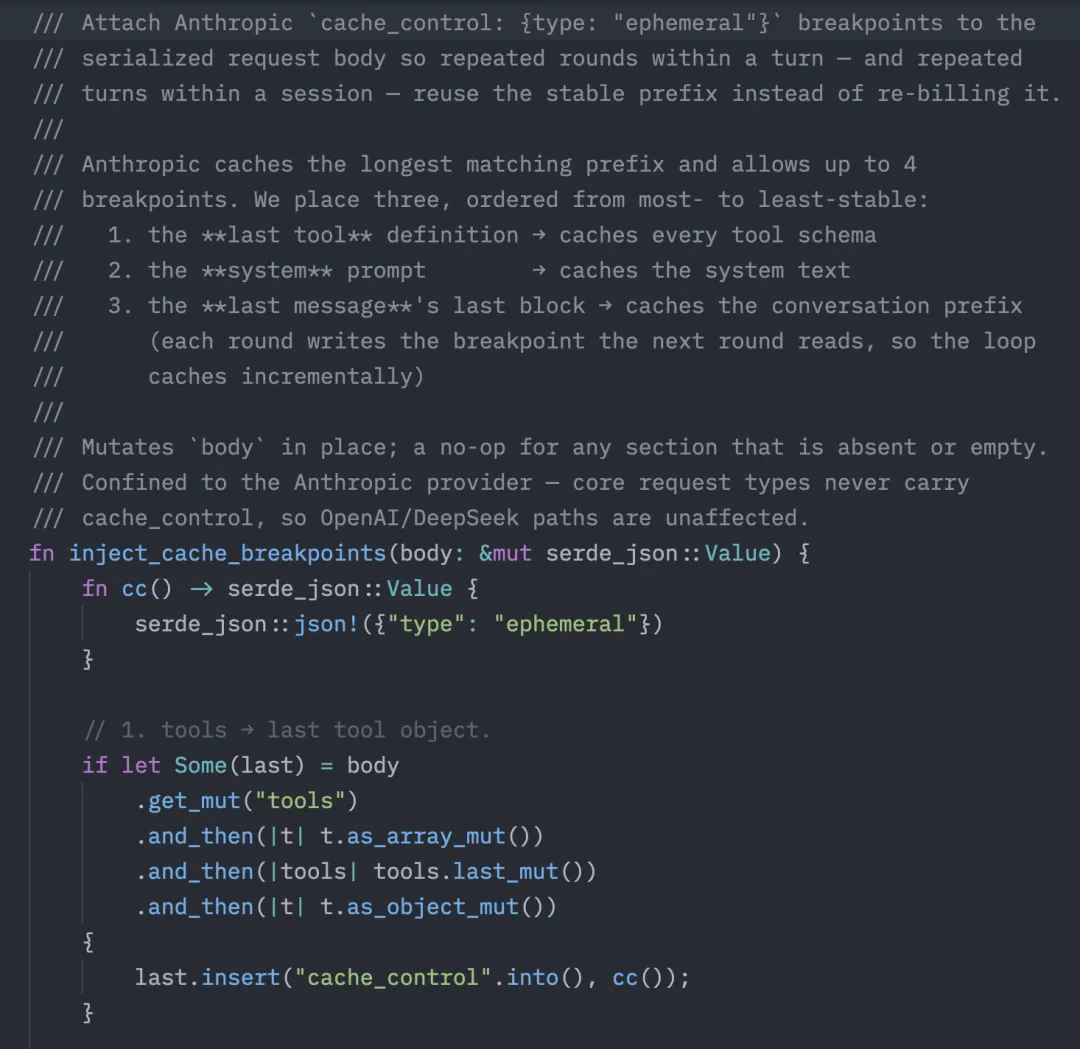
什么概念?变速箱造好了,离合器没接上。那个省钱开关,从头到尾就是个摆设,每一轮还是原价重付。
修复其实不复杂,就是在真正发 HTTP 请求的地方,把缓存断点挂回去。Anthropic 的玩法是给请求体打不超过 4 个 cache_control 标记,我把它们挂在三个最稳的位置上:
fn inject_cache_breakpoints(body: &mut serde_json::Value) { let cc = || serde_json::json!({ "type": "ephemeral" }); // ① 工具定义:挂在最后一个 tool 上,一次性缓存整段工具定义 if let Some(last) = body["tools"].as_array_mut().and_then(|t| t.last_mut()) { last["cache_control"] = cc(); } // ② 系统提示词:从 string 转成单块数组,挂上 cache_control if let Some(text) = body["system"].as_str().map(str::to_owned) { body["system"] = serde_json::json!([ { "type": "text", "text": text, "cache_control": cc() } ]); } // ③ 对话历史:挂在最近一条消息的最后一个 block 上 if let Some(b) = body["messages"].as_array_mut().and_then(|m| m.last_mut()) .and_then(|m| m["content"].as_array_mut()).and_then(|b| b.last_mut()) { b["cache_control"] = cc(); }}挂完之后,一个请求的结构就成了这样:
请求体 ┌─ tools[...] ← 断点① 缓存全部工具定义 ├─ system ← 断点② 缓存系统提示词 └─ messages[...] ← 断点③ 缓存到上一轮为止的全部历史 第 N 轮直接复用 0..N-1,只有最新一条消息按全价算就这么几行,效果却是数量级的:一个二三十轮的任务,那段三五千 token 的稳定前缀,从”每轮全价”变成”九成走缓存”,命中的部分只收十分之一的钱,而且更快。省钱和变快,是同一个动作完成的。
我还特意守住一条底线:DeepSeek 和 OpenAI 那两条线一个字节都没动,该全价还全价,只有 Anthropic 这条线吃缓存。省钱不能拿正确性去换。
我从这件事里得到的认知是:省下来的 token,会变成模型的”思考额度”。 你把浪费掉的钱省下来,模型就有预算去多想几步、多验证几次。省 token 这件事,听起来像抠门,实际上是在给聪明腾地方。
第二刀:让它别越用越傻,记忆得有门槛
接着说”越用越傻”这个病。
很多 Agent 都有个看着很美的功能:自动把对话里的东西记成长期记忆,下次再塞回上下文里,号称”越用越懂你”。
理想很丰满。现实是:它把一堆低质量、甚至自相矛盾的废话也记了下来,越积越多。然后每次对话,这堆噪声又被一股脑塞回去,污染模型的注意力。这才是”越用越傻”真正的发动机。它不是记得太少,是记了太多垃圾。
我的处理思路,是保留自动、但加门槛。具体三层:
第一层,每条反思出来的记忆都带一个置信度(低 / 中 / 高),只有过了你设的门槛才自动落盘,默认”中”以上。这个门槛你可以在配置里调,想保守就调到”高”。
第二层,落盘之前先查重。跟已有记忆太像的,直接拒绝(基于相似度算)。这样记忆库始终稀少而精,不会滚雪球。我还特意让这个”跳过”动作显示出来,你能看到它”↺ 跳过了一条和某记忆重复的”,整个过程是透明的,不是黑箱。
第三层是个例外,也是我觉得最关键的一点。当你亲口教它的时候,比如你说”记住,我以后都用 vim””我偏好 anyhow 不用 thiserror”,这种是你明确下的指令,再低的置信度也照记不误,门槛对它无效。
为什么要留这个例外?因为我一开始的设计是”所有记忆都要你点确认才存”。咱就是这么认为的:如果每条都要人确认,那还叫什么智能?你(也就是用户)亲口教的东西就该无条件记住,机器自己瞎琢磨出来的才需要门槛拦一道。这个分寸,我觉得是这一刀的灵魂。
把这三层落到代码上,其实就是一道闸门:
// 置信度本身是有序的,门槛直接用 >= 比就行enum Confidence { Low, Medium, High } // Low < Medium < High// 自动落盘的总闸:过了门槛、或者你亲口教的,才放行;还得躲开冲突let clears_floor = candidate.confidence >= min_confidence || explicit_intent;let eligible = auto_accept && clears_floor && !conflicts_existing;explicit_intent 就是第三层那个例外:你一旦说了”记住””以后””我偏好”,这个标记就为真,再低的置信度也照样放行。查重撞车的时候,它也不再默默把记忆吞掉,而是当面跟你说一声:
↺ skipped (similar to mem_a3f7, 91%)一条记忆从产生到落盘,全程看得见,不是黑箱。
一句话总结:让 Agent 变聪明的,不是记得多,是记得准。 市面上大多数号称”越用越懂你”的记忆系统,恰恰把这件事做反了:它们在比谁记得多,我在比谁记得准。
第三刀:让它能自己扛大活,学 Claude Code 的 任务规划
Claude Code 干大任务,有个特别朴素但特别好用的机制:开工前先把任务拆成一张 todo 清单,一次性写全,然后一项项推进,永远只有一项处于”进行中”,干完一项立刻勾掉。
这招为什么管用?大任务最怕的,是模型走着走着忘了自己最初要干嘛、漏掉了某个步骤。一张它自己维护的、看得见的清单,等于给它装了个”工作记忆”,把长任务死死焊在轨道上,不让它跑偏。
我照着这个思路给小怪兽也做了一套:一个 todo_write 工具,整张清单一次性写入、整体替换。我特意没做成”加一条、改一条”那种零敲碎打的接口,因为那样靠 ID 去对应,很容易对不上号,出现”找不到第 5 条任务”这种尴尬。整体替换最干净,模型每次把它脑子里最新的完整计划甩出来就行。
做的时候还顺手揪出一个隐蔽 bug:原来的 todo 状态是进程级全局的,多个会话之间会串味,你在这个项目里的待办,可能莫名其妙冒到另一个会话里。现在改成按会话隔离,各过各的。
// 之前:进程级全局 static,跨会话共享、永不重置,泄漏的温床static TODOS: Lazy<Mutex<Vec<Todo>>> = Lazy::new(Default::default);// 之后:挂到 host 实例上,随会话生、随会话灭,天然按会话隔离pub struct BuiltinToolHost { todos: TodoStore, // = Arc<Mutex<Vec<Todo>>> workspace: PathBuf, // ...}别急,还有一票”内核级”的东西
上面三刀只是最近动的。这只小怪兽的壳里,还有不少我挺得意的设计,简单点几个:
工具循环本身就很讲究。 安全的工具(比如读文件)并行跑,危险的工具(比如删东西)串行执行、还得先问你一句。你中途按下打断,它能把现场收拾干净,不会留下半拉子的工具调用让接口报错。这些都是踩过坑才会写的细节。
技能的”渐进式披露”。 它可以装几十个技能(写公众号、解析招标文件、做 PDF……),但平时上下文里只放每个技能的名字和一句话简介。模型觉得某个用得上了,才去调工具把完整说明读进来。这样几十个上百个技能也撑不爆上下文。这是我从 Claude Code 学到的、特别优雅的一招。当然,这是前期的功能,目前几乎所有的 agent 都这么在加载技能,不是这样的一定会遇到上下文爆炸的问题,也不是标准的 agent skills 的使用姿势。
还有记忆宫殿、权限系统、MCP 外部工具即插即用、派独立上下文的子 Agent…… 这些都在,但展开能再写三篇,这里就不啰嗦了。
核心就一条信仰,我前面说过:大道至简,能不加的复杂度坚决不加。我自己是一个比较笨的人,我不喜欢复杂,我就喜欢简单,简单的把事情给做了,最终的目标就是不要太复杂。
下两刀,我已经想好砍哪了
这只小怪兽离完美还远。但有意思的是,它接下来该往哪儿削,我心里特别清楚。有两个地方,我已经盯上了。
一个是记忆,它目前有三套并存的路径(宫殿索引、编译过的用户画像、老式的逐轮注入)。这明摆着违背了”大道至简”,迟早要砍到一套。我没急着动手,纯粹是因为没想清楚留哪一套之前不想瞎砍。砍错了,比暂时不砍更糟。
另一个是任务完成的判定。现在是靠在模型输出里搜一个 [GOAL_COMPLETE] 文本标记来判断”干完了”。我觉得这玩意儿挺脆的:万一模型把这串字写进了代码块或者解释里,就误判了。迟早得换成更结构化的信号,比如让它显式调一个”完成”工具。
把这两条主动摆出来,不是示弱。一个还在长的项目,本就该有清清楚楚的下一刀。我享受的恰恰是这个过程:把问题想透,再一刀一刀削下去。
写在最后
2024 年,大家讲的故事是”模型更大、更强”。可到了 2026,我隐隐觉得叙事在变:模型已经够强了,强到我们其实根本没把它用满。瓶颈悄悄从”大脑”挪到了”壳”上。
折腾 small Rust Hermes 这几个月,我最大的一个感受是这样的:Agent 表现得不聪明,很多时候真不怪模型,怪的是那层又厚又乱的壳。你给它灌一堆自相矛盾的记忆,让它每一轮都原价重付,再让它在没封顶的日志里淹死,神仙模型也救不回来。
所以你回头看,我做的这几刀,没有一刀是加法,全是”修”和”减”。把壳做干净、做透,模型那点聪明,自己就漏出来了。
省 token 和变聪明,从来就是同一件事。
项目地址:https://github.com/coder-brzhang/small-rust-hermes
注意,本项目仅在小张的500 多个人的小群(公众号菜单-联系我-加群)中分享。