 夜雨聆风
夜雨聆风





一文拆解 OpenAI Codex:为什么 AI 编程正在从代码补全走向软件工程 Agent?

过去几年,AI 编程最常见的使用方式,是在编辑器中补全下一行代码,或者把报错复制给大模型,再把答案粘贴回项目。
这种方式已经很有价值,但查找文件、理解依赖、运行命令、分析报错和验证结果,仍然主要由人完成。
Codex 改变的不是模型会不会写代码,而是人与 AI 之间的任务边界。
开发者可以交给它一个相对完整的目标。Codex 会读取代码库、修改文件、调用终端、运行测试,并根据结果继续调整。AI 编程开始从“回答一个问题”,走向“完成一段工作”。
一、Codex 不是代码补全工具
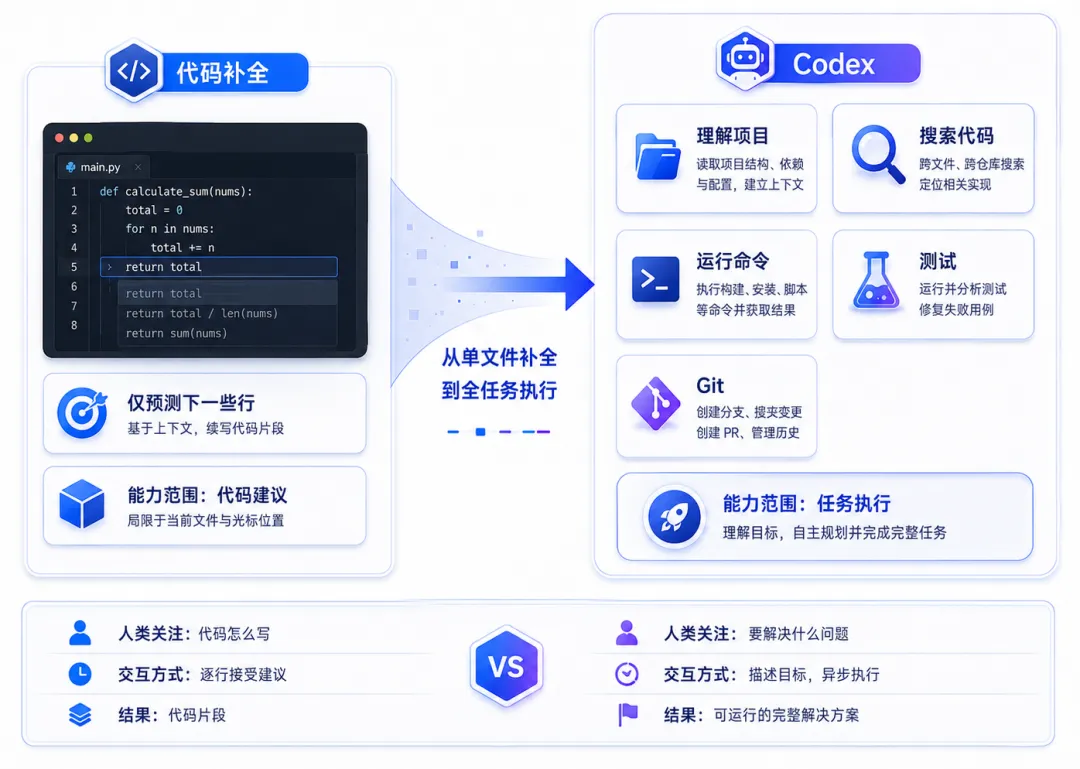
传统代码补全的核心,是根据光标附近的内容预测下一段代码。它能减少重复输入,但项目结构、任务拆解和结果验证仍由开发者负责。
Codex 更接近一个能够操作开发环境的 Agent。它不仅生成代码,还可以搜索项目、读取多个文件、运行脚本、修改实现并检查测试结果。
两者最大的区别,不是一次生成多少行代码,而是有没有形成执行闭环。
代码补全通常结束于“给出建议”;Codex 的任务可能结束于“文件已经修改、测试已经运行,变更已经准备好供人审查”。
二、真正重要的是 Agent Loop
真实开发很少一次修改就成功。程序可能无法编译,测试可能失败,依赖版本也可能与预期不同。
因此,软件工程 Agent 的核心不是一次模型调用,而是一套持续循环:
• 理解目标与约束;
• 搜索代码并读取环境;
• 调用编辑器、终端和测试工具;
• 观察输出与代码差异;
• 根据反馈继续修改;
• 整理结果并交付审查。
在这个过程中,模型负责推理和决策,Agent Harness 负责管理工具、上下文、权限和执行过程。
真正好用的 AI 编程产品,不只是模型更强,而是能让模型可靠地接触真实工程环境,并在失败后继续推进任务。
三、项目上下文为什么比提示词更重要?
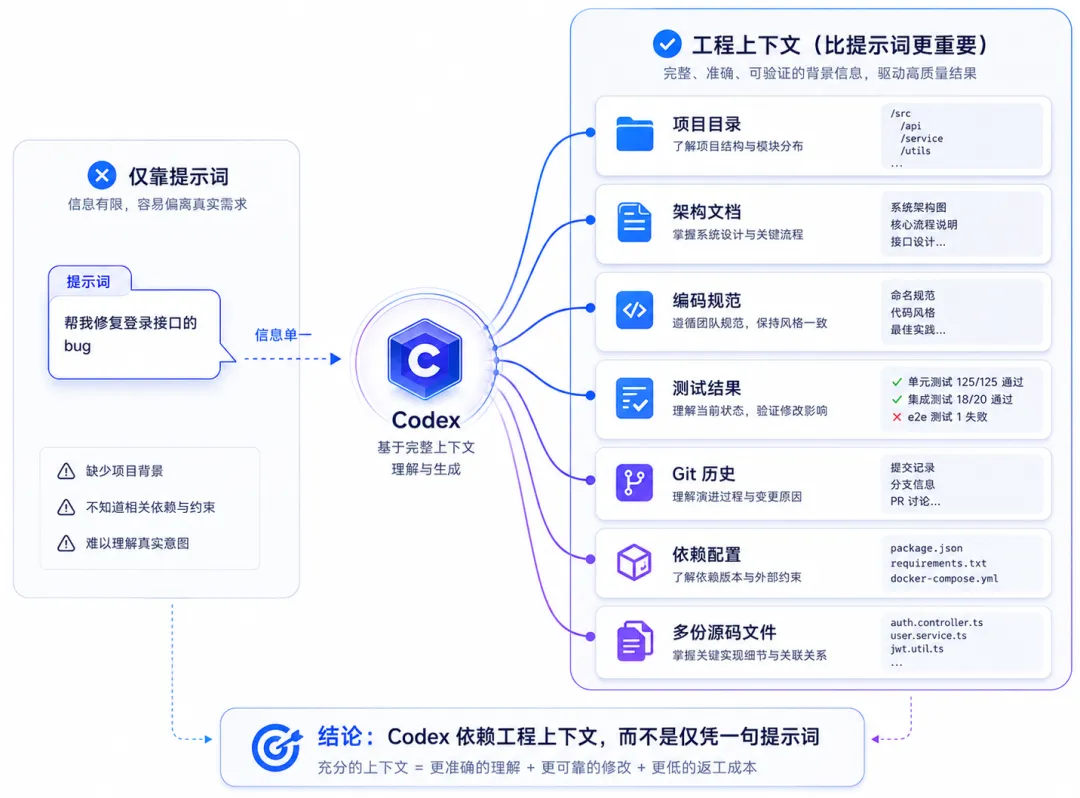
聊天式编程经常要求开发者反复解释项目背景:框架是什么、文件在哪里、接口如何定义、哪些代码不能修改。
Codex 进入项目环境后,可以主动读取目录、配置文件、测试代码和现有实现。它获得的不只是用户写下的一段提示词,而是任务所在的工程上下文。
过去,人需要把代码复制给模型;现在,Agent 可以自己寻找相关文件。过去,人负责决定运行什么命令;现在,Agent 可以读取项目配置,再选择编译、测试或检查工具。
但上下文并不是越多越好。大型代码库包含大量无关文件和历史实现,Agent 仍要判断哪些信息与当前任务有关,并在长任务中维护项目状态。
AI 编程的竞争,正在从“谁支持更长的输入”,走向“谁更懂真实工程环境”。
四、从单次对话走向并行工程
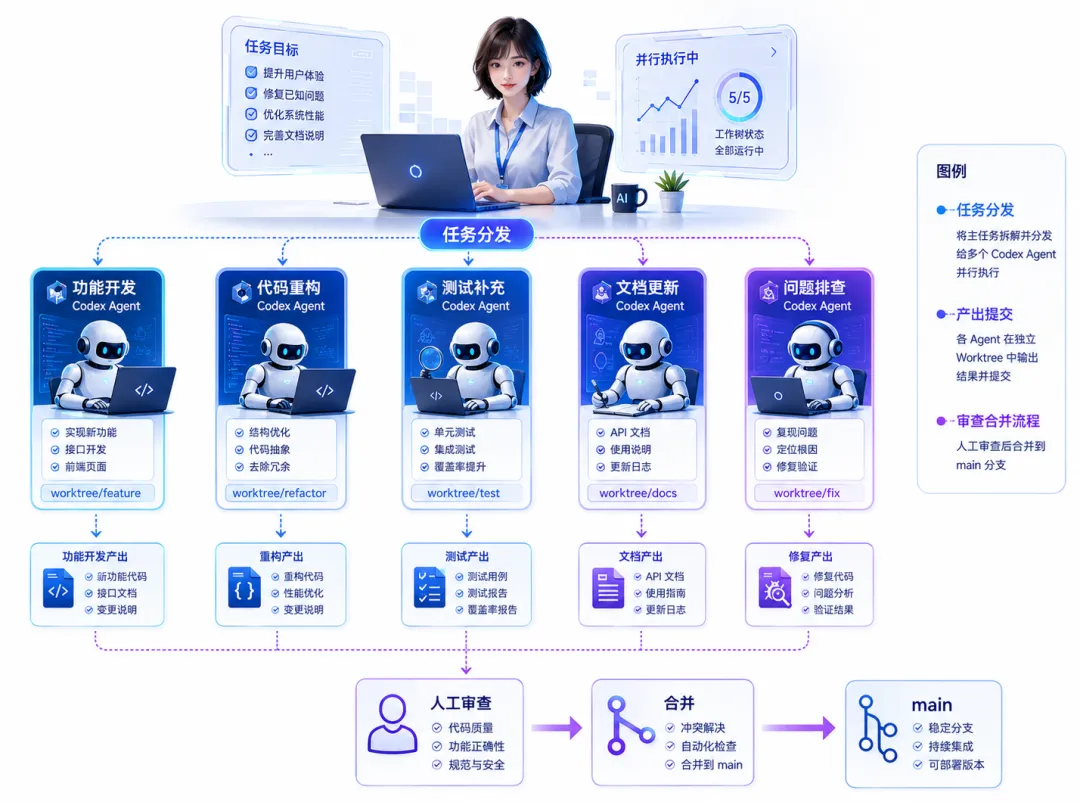
聊天式编程通常是一问一答。软件工程 Agent 的下一步,则是把多个任务放到独立环境中并行执行。
例如,一个 Agent 开发接口,另一个补充测试,第三个检查兼容性,第四个更新文档。不同任务通过独立 worktree 或云端环境运行,降低文件相互覆盖的风险,最终由开发者统一审查。
开发者的角色也随之变化。过去,一个工程师同一时间主要推进一条任务线;未来,他可能同时管理多个 Agent:定义目标、提供约束、检查进度并决定哪些结果进入主分支。
AI 不再只是坐在编辑器旁边提供建议,而是开始承担可以排队、并行和交付的工程任务。
五、ChatGPT 与 Codex 如何配合?
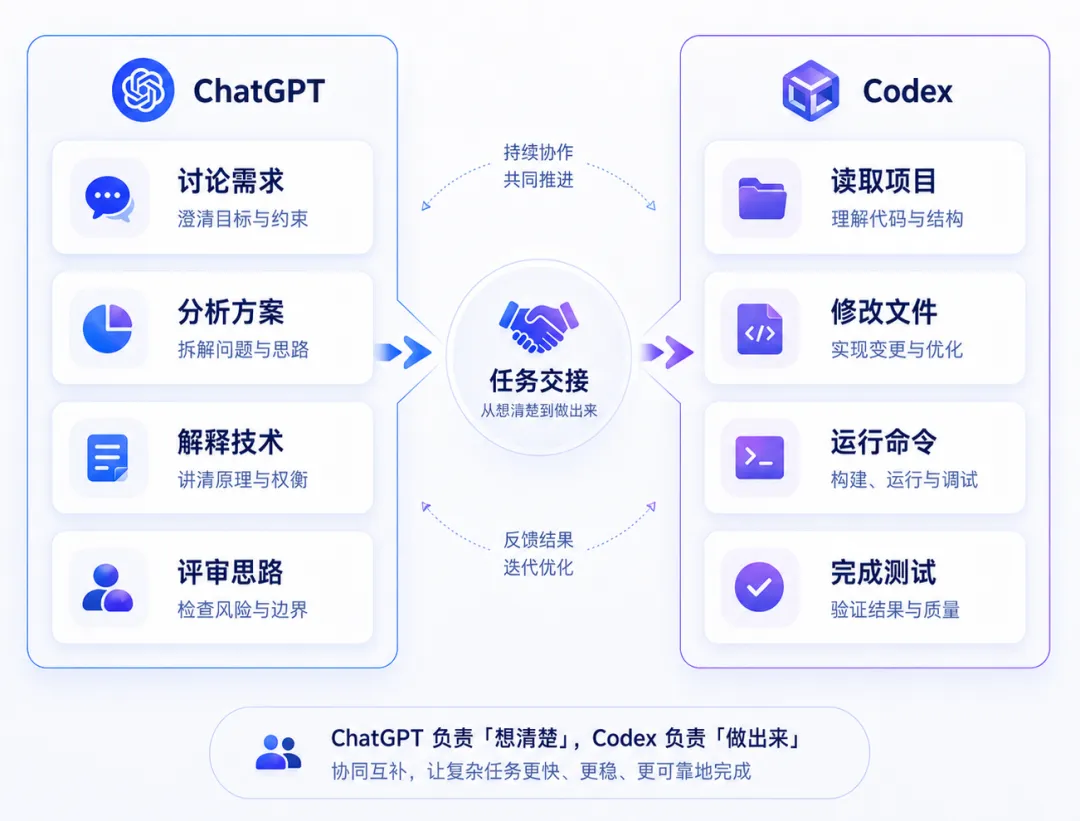
ChatGPT 与 Codex 并不是简单的替代关系。
ChatGPT 更适合梳理需求、比较方案、解释技术和评审思路,帮助开发者把模糊想法整理成清晰目标。
Codex 更适合进入工程环境执行任务,例如理解陌生代码、修改关联文件、修复缺陷、补充测试和准备代码变更。
一种更有效的方式,是先用 ChatGPT 把目标、边界和方案讨论清楚,再把明确任务交给 Codex。
前者偏向共同思考,后者偏向任务执行。两者结合之后,大模型才真正从“提供建议”进入“产生工程结果”。
六、Codex 是怎样一步步变成软件工程产品的?
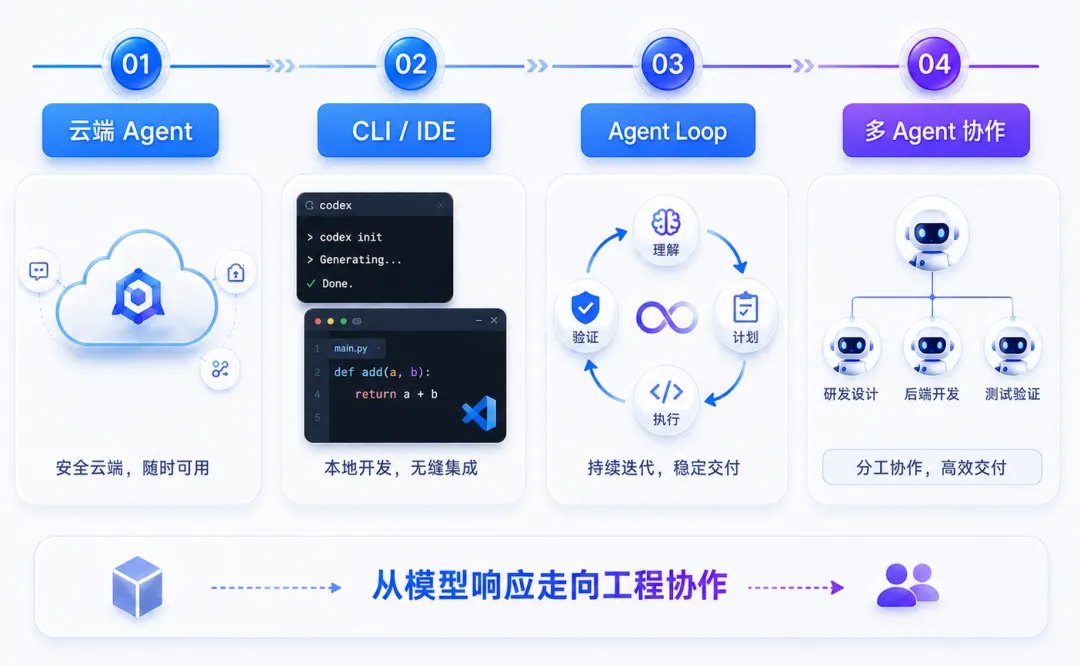
Codex 并不是突然出现的一款编程工具。
2025 年,OpenAI 首先推出云端 Codex,让 Agent 在独立沙箱中编写功能、修复缺陷、回答代码库问题并提出 Pull Request。它已经不是代码生成接口,而是一个能够承接任务的云端软件工程 Agent。
随后,Codex 逐步扩展到 CLI、IDE、云端服务和开发接口。模型开始连接本地代码、终端命令、Git 和真实开发工具。
到 2026 年推出 Codex App,产品重点进一步变成管理多个 Agent:不同线程可以在独立 worktree 或云端环境中并行执行,开发者在统一界面中查看进度、审查差异并管理 Git 变更。
这条演进路径说明,OpenAI 提供的不再只是一颗更会写代码的模型,而是在把模型、工具、执行环境和协作界面组合成完整的软件工程产品。
七、团队真正需要改造的是工程环境
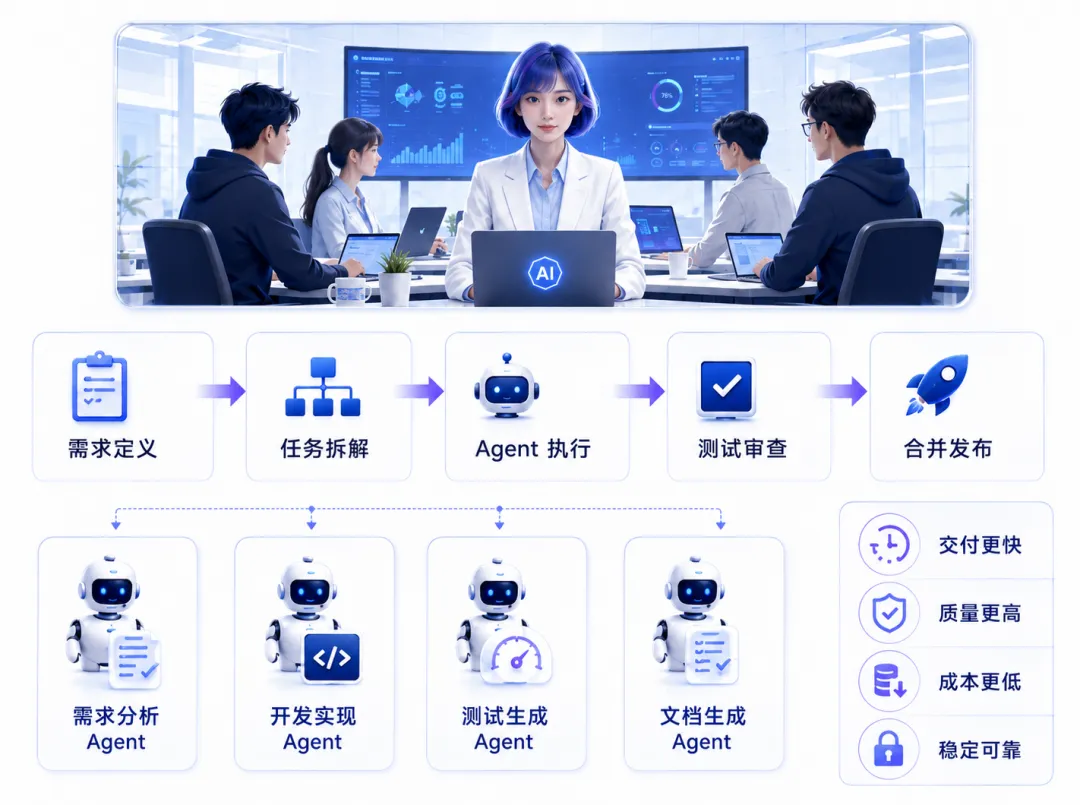
个人让 Codex 修改一段代码,与团队把它纳入研发流程,是两件不同的事。
团队应用的关键,不只是每个人拥有一个 AI 账号,而是代码库是否适合 Agent 工作。清晰的目录、准确的文档、稳定的测试和明确的规范,会直接影响执行质量。
这也是 Harness Engineering 的意义:围绕 Agent 重新设计代码库、工具、测试、CI、文档与反馈循环,使模型能够持续获得环境反馈。
未来团队需要重新决定:
• 哪些任务可以委派;
• 哪些命令必须批准;
• 哪些目录和数据不能访问;
• 代码必须通过哪些测试;
• 谁负责最终审查和合并。
AI 编程越深入,工程基础越不能含糊。过去可以依靠资深员工经验维持的项目,未必适合 Agent 稳定执行。
八、大模型竞争正在发生什么变化?
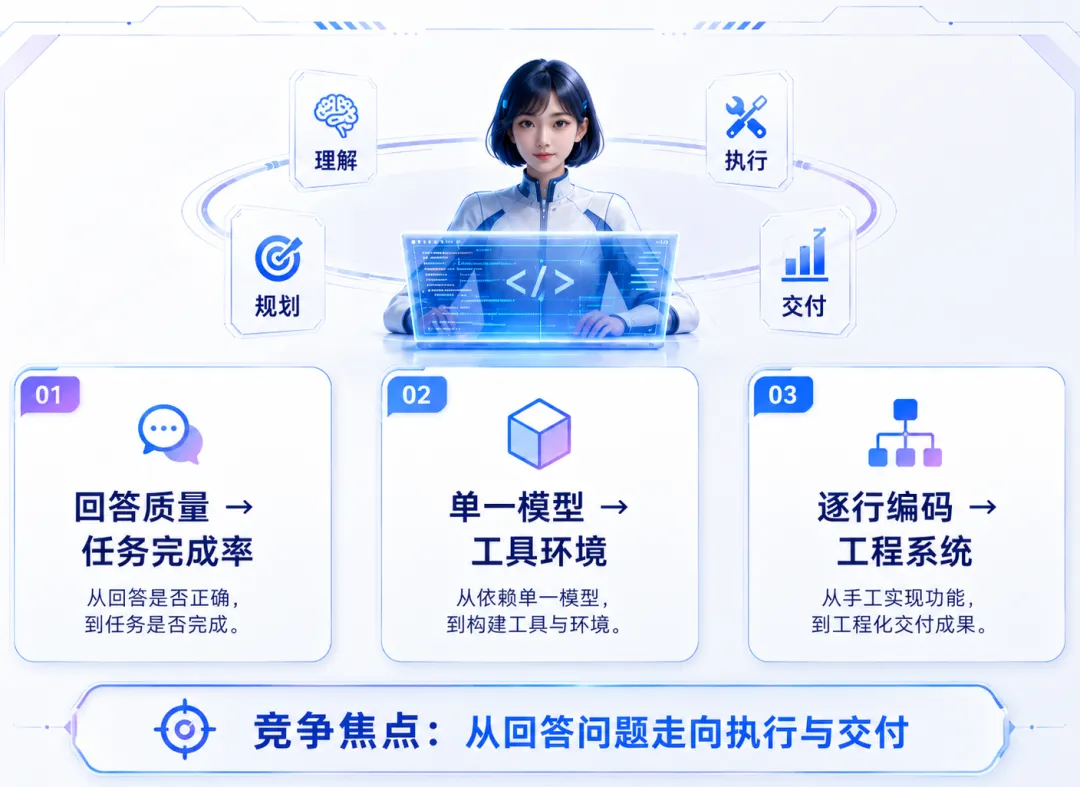
Codex 反映出的变化,不只发生在编程领域。
第一,大模型竞争正在从回答质量走向任务完成率。未来更重要的问题,不是模型能否给出漂亮答案,而是它能否正确使用工具、在失败后继续调整,并交付可以验证的结果。
第二,模型之外的系统越来越重要。同一个模型放在不同的上下文管理、权限机制、工具和测试环境中,最终效果可能完全不同。Agent Harness 正在成为产品差异的重要来源。
第三,人的角色正在从逐行实现,转向目标定义、系统设计和结果审查。工程师写代码的时间可能减少,但拆解问题、建立测试、设置权限和判断结果的责任不会消失。
大模型并没有因为接入终端,就自动成为可靠的软件工程师。可靠性来自模型、工具、工程环境和人工治理共同作用。
九、效率提升不等于取消审查
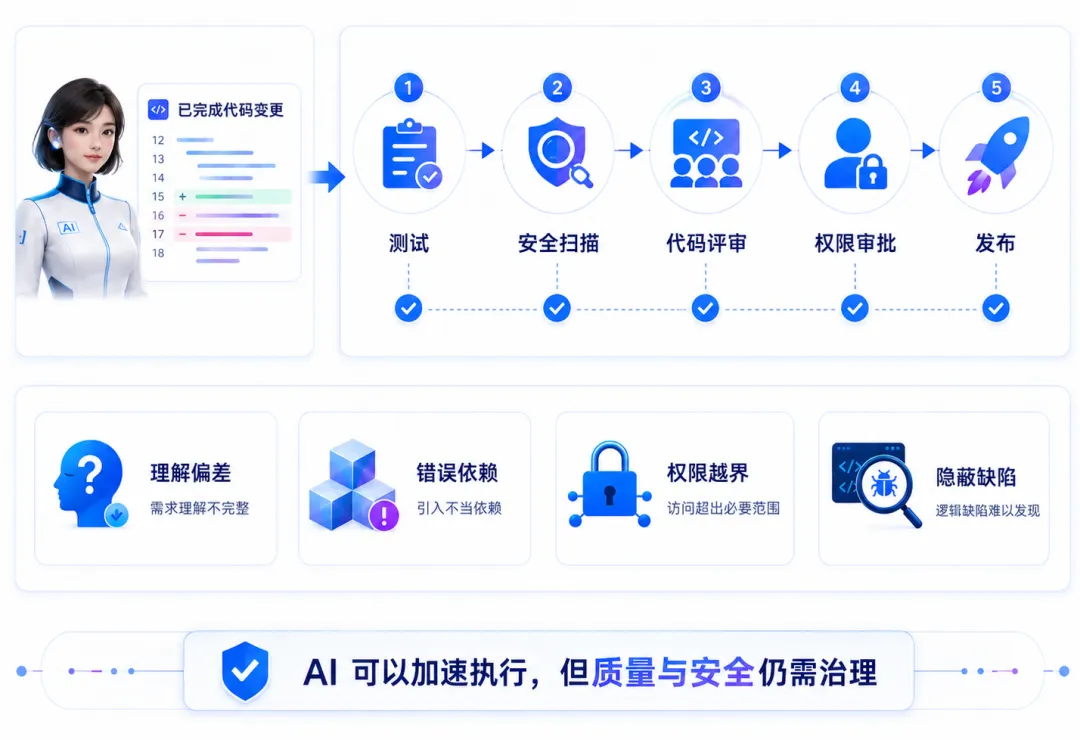
Agent 能够修改大量文件和执行命令,也意味着它拥有更大的操作能力。
任务描述不清时,它可能正确执行一个错误目标;测试覆盖不足时,它也可能提交表面可用、实际存在隐患的实现。
因此,Codex 没有让代码审查失去意义,反而让审查对象扩大了。开发者不仅要看代码,还要检查 Agent 理解了什么、修改了哪些文件、执行了哪些命令,以及测试是否覆盖真实需求。
合理的原则是:
让 Agent 承担更多执行工作,但把目标定义、权限边界和最终责任保留在人手中。
只有速度与测试、审计、权限和安全治理结合,才能真正转化为工程效率。
结语
Codex 最值得关注的地方,不是它一次能写多少代码,而是它正在把大模型从软件开发的对话窗口,推进到真实工程环境。
代码补全解决的是“下一行怎么写”,聊天式编程解决的是“这个问题怎么理解”,软件工程 Agent 试图解决的则是“这项工作能否被完整执行”。
这背后需要的不只是一颗更强的模型。项目上下文、工具调用、Agent Loop、独立环境、测试体系、权限控制和人工审查,缺一不可。
对开发者而言,未来的重要能力也不会只是写代码或写提示词,而是把目标描述清楚,把任务拆分合理,并设计一套能够验证 Agent 结果的工程环境。
大模型产品也正在跨过一个重要分界线:过去主要回答人提出的问题,未来则会越来越多地进入实际工作流,调用工具、操作系统并推动任务完成。
Codex 正是这场变化中最具代表性的产品之一。