 夜雨聆风
夜雨聆风





Hermes Agent 深度解析:OpenClaw之后,养“马”正当时
Hermes Agent 是由硅谷 AI 实验室 Nous Research 于 2026 年 2 月 25 日推出的开源 AI 智能体,定位为可长期成长的数字员工。Nous Research 成立于 2023 年,此前已推出 Hermes 系列开源大模型。团队当前估值约 10 亿美元,整体成熟度和行业关注度都较高。
从市场表现来看,Hermes Agent 上线不到三个月,日均 Token 消耗量就达到 2710 亿,超过 OpenClaw,登上全球 AI 应用调用榜首。同时,它在首月获得 2.2 万 GitHub Star,6 周内突破 6.4 万,如今已超过 19 万。
1. Hermes Agent VS OpenClaw
1.1 OpenClaw:执行至上,做最精准的任务执行者
OpenClaw 的设计理念可以概括为三个字:重执行。它的核心目标,是为 AI 智能体提供一套稳定、高效的任务执行框架——只要指令足够明确,它就能可靠且高质量地完成任务。
这种“执行优先、记忆从简”的路线,使其插件生态发展迅速。目前它已支上百种社区技能插件,覆盖编程、文档、爬虫、数据处理等多类场景。OpenClaw 面向的用户也非常清晰:如果你明确知道自己要做什么,只需要一个值得信赖的执行者,它会是很合适的选择。
1.2 Hermes Agent:成长进化,做与你同行的伙伴
Hermes Agent 的理念则完全不同。它的核心主张是:智能体不应只是单纯的工具,而应成为能与用户共同成长的伙伴。
Hermes 的最大特色在于自我进化能力:每次任务完成后,经验都会自动沉淀为可复用的技能(Skill),并可跨会话积累用户偏好,从而实现真正的“越用越聪明”。这意味着,使用 Hermes 的时间越久,它就越懂你,也越能提前预判你的需求。这种“学习优先、轻量执行”的设计,代表了一条截然不同的发展路径。
1.3 架构设计对比
两者的架构思路截然不同:
-
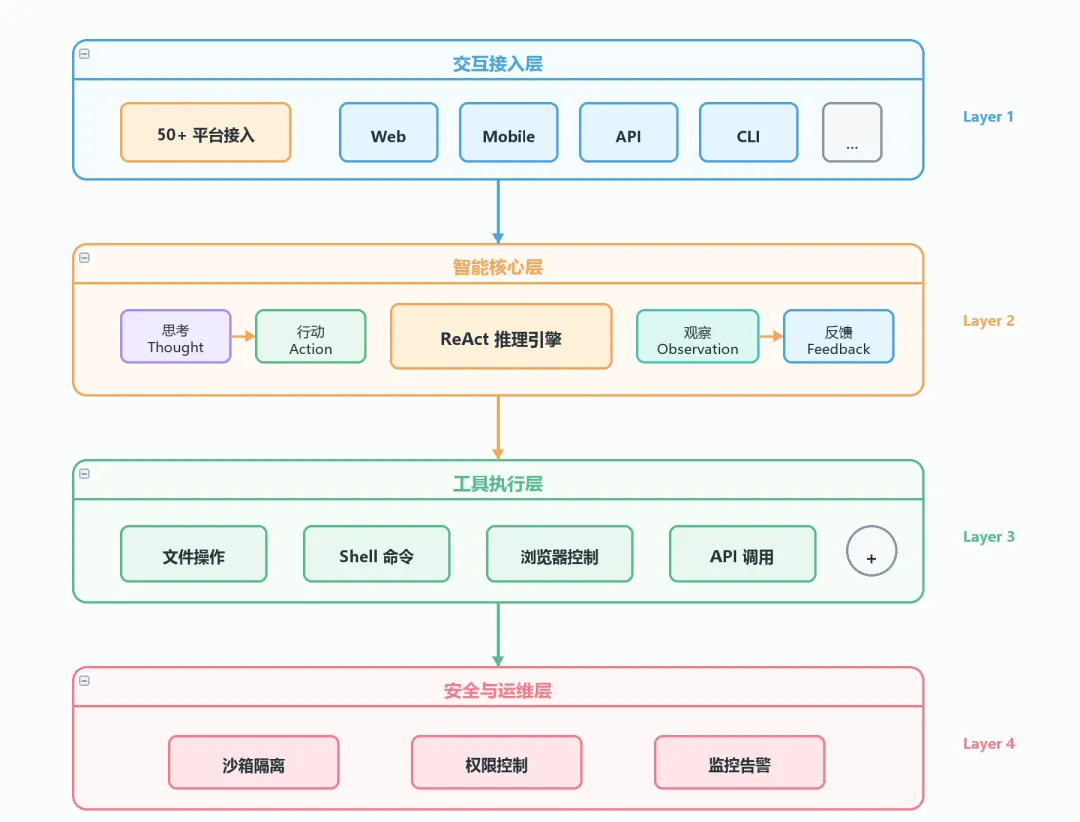
OpenClaw 以“连接”为核心。其架构分为四层:交互接入层、ReAct 推理核心层、工具执行层、安全沙箱层。所有渠道由统一的 Gateway 管理,技能从 ClawHub 直接下载使用。
-
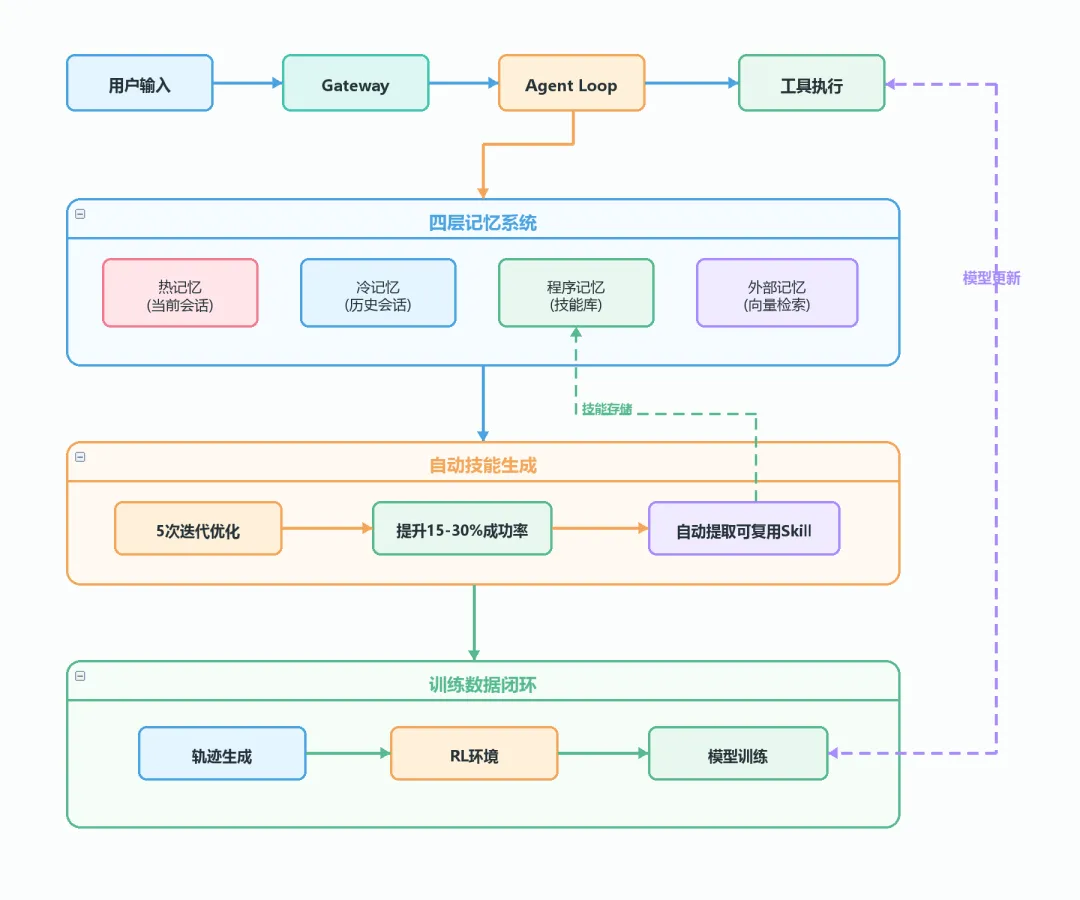
Hermes 以“学习”为核心。用户输入进入系统后,经过 Agent Loop,执行结果会被写入四层记忆体系:当前会话、历史会话、技能库和向量检索。如果某个任务在调用工具超过 5 次后仍成功完成,Hermes 会自动将这一经验提炼为可复用技能(Skill)并保存。下次遇到类似任务时,就可以直接调用该技能。据称,经过 5 轮迭代后,任务成功率可提升 15%–30%。
2. 核心技术能力
2.1 在线执行能力
在线执行能力,即 Hermes Agent 如何完成一次真实任务。
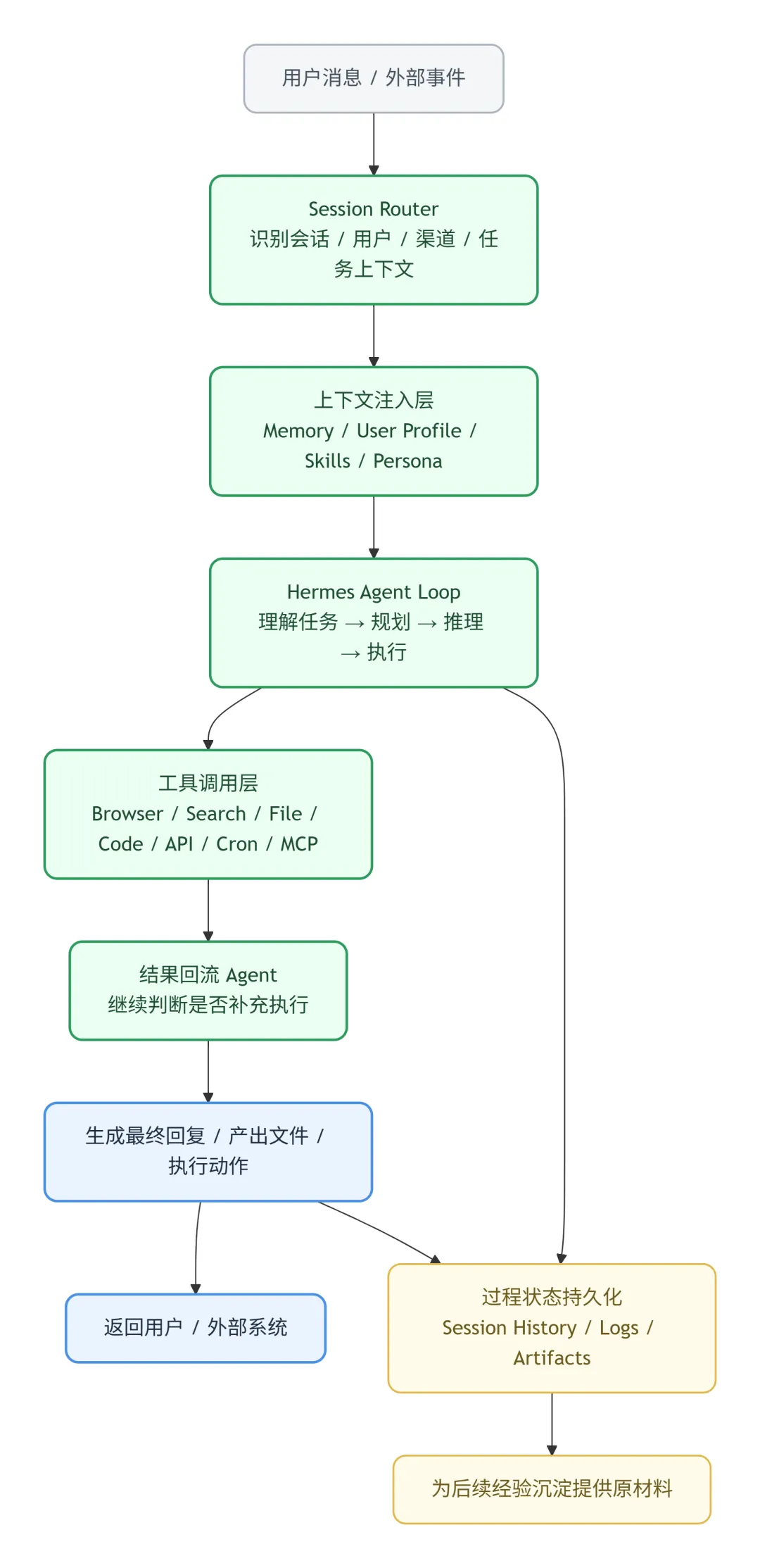
整体流程与大多数智能体相似。用户发来一条消息后,Agent 会先进行会话路由,识别当前用户是谁、来自哪个渠道,以及处在什么上下文中。
随后,它会将与该用户相关的长期记忆、用户偏好、已有技能和系统角色一并注入上下文。
接着,系统进入 Agent Loop 推理执行循环:根据任务需要调用工具,拿到结果后,再判断是否需要继续补充执行。
最后,它会将回复、文件或具体动作结果返回给用户。
与此同时,整个过程中的对话、执行轨迹、日志和产出都会被保存下来,作为后续经验沉淀的原材料。换句话说,这些过程不是“干完就散”,而是会留下完整的“工作复盘材料”。
2.1.1 在线执行中的提示词工程:怎么兼容不同模型
在提示词工程层面,Hermes 的核心设计理念是兼容主义与动态补丁,致力于解决不同模型能力差异带来的不确定性。
Hermes 会检测当前所使用的模型类型(如 GPT 系列或 Gemini 系列),然后动态地在系统提示词中追加对应模型的“使用约束”。
-
动态工具强制指导:根据底层模型类型,动态下发针对性补丁。
|
|
|
|
|---|---|---|
| GPT 系列 |
|
|
| Gemini 系列 |
|
|
-
极致的生态兼容:Hermes 的系统 Prompt 组装器原生兼容 OpenClaw(读取 AGENT.md、SOUL.md等配置文件)以及主流 AI Coding 工具(读取.cursorrules、.mdc),大幅降低跨架构迁移成本。
2.1.2 在线执行中的上下文工程:怎么管好记忆和上下文
上下文管理是长程 Agent 稳定性的关键。Hermes 在 Context 与 Memory 的处理上展现了较高的工程成熟度。
(1)动态比例阈值压缩
问题:AI 模型有上下文长度限制(例如 32K 或 200K Token)。当对话过长时,就会超出限制,模型可能报错,或“忘记”前面的内容。
传统做法(OpenClaw):设定一个固定的 Token 数量阈值(例如 20K),达到后就执行压缩。但不同模型的窗口大小不同,固定值并不通用。
Hermes 的做法:不看绝对 Token 数,而看比例。例如设定阈值为 50%,即占满模型“内存”一半时开始压缩。无论模型窗口是 32K 还是 200K,都会在相对合适的时间点触发压缩。
好处:同一套代码,既能跑在小窗口模型上以节省成本,也能跑在大窗口模型上以提升精度,无需为每个模型单独调整参数。
(2)内外双驱混合记忆机制
问题:Agent 需要记住长期信息(例如“用户喜欢 Python”),但只依赖当前会话上下文显然不够,而且系统重启后信息还会丢失。
Hermes 的做法:通过两种方式存储记忆。
-
内部静态存储(简单可靠)将重要事实写入本地 Markdown 文件(如
MEMORY.md、USER.md),Agent 启动时直接读入。同时,所有对话都保存在 SQLite 数据库中,方便回溯历史。 -
外部扩展总线(能力更强)可接入专业记忆插件(如 Mem0、Honcho),它们支持向量搜索(语义检索),能够在不同会话之间找到“相关但不完全相同”的记忆。例如你问“上次那个奇怪的 bug”,系统也能召回类似问题的记录。
好处:默认方案简单够用;需要更强能力时再接插件,长期记忆也能在上千轮对话中保持较高召回准确度。
(3)上下文即时注入
问题:Agent 如果要获取某个文件中的一段代码,传统做法通常需要多轮交互:
用户:帮我看看
main.py的 10 到 20 行。Agent:调用工具读取文件 → 拿到内容 → 再调用模型理解 → 再回答。
Hermes 的 @ 语法:你可以把想引用的信息直接写在提问中,让 Agent 一次性拿到上下文。例如:@file:main.py:10-20 或 @diff(最近改动的差异)。
Hermes 会在调用模型前,将这些 @ 标记直接替换为实际内容(如文件片段、差异内容),然后一次性发给模型。
2.2 经验沉淀能力
经验沉淀,是 Hermes 为什么会“越用越聪明、越用越顺手”的关键原因之一。
前面的在线执行阶段会产生大量“工作复盘材料”。Hermes 会利用 Curator(策展器)对这些材料进行周期性复盘,识别哪些信息值得长期保留,哪些流程可以复用。
这些信息会被沉淀到不同层次:
-
通过 Memory Manager,用户偏好会进入 User Profile,稳定事实会进入 Memory,形成记忆类沉淀。
-
通过 Skills Manager,可复用的工作流会被沉淀为 Skills。
-
此外,Hermes 还提供一个可选的高级记忆后端:Honcho Memory Provider。它可以将分散在多轮对话中的偏好与行为信号整合起来,在后续组装上下文时,提供更相关、更完整的用户画像。
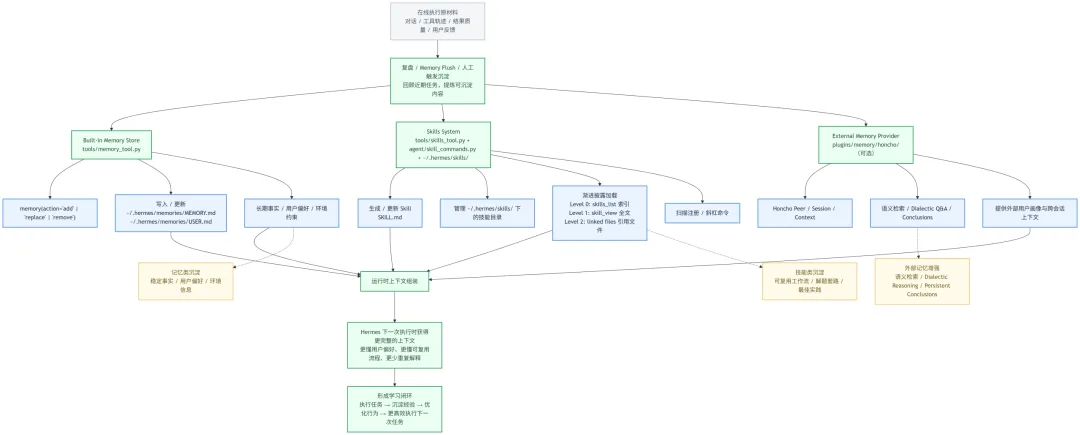
Hermes 的“越用越聪明”并非一句营销口号,而是由四个紧密协作的模块共同构成的数据闭环:执行任务 → 沉淀经验 → 优化行为 → 更高效地执行任务。下面分别介绍每个模块的角色,再串联整体流程。
各模块职责
|
|
|
|
|---|---|---|
| Memory Manager | agent/memory_manager.py |
MEMORY.md / USER.md)。 |
| Skills Manager | hermes_cli/skills_config.py
skills/ |
SKILL.md),支持渐进披露加载。 |
| Curator |
user-guide/features/curator.md) |
|
| Honcho Memory Provider | plugins/memory/honcho/
|
|
详细说明
1. Memory Manager(记忆管理器)
-
暴露三个工具: memory(action="add")、memory(action="replace")、memory(action="remove")。 -
作用:让 Agent 在对话中自主决定记录什么、修改什么。例如,用户说“我以后都用 Python”,Agent 可调用 memory add将这条偏好写入USER.md。 -
目标:从“被动存储对话”升级为“主动管理知识”。
2. Skills Manager(技能管理器)
Hermes Agent 的技能生成并非随意触发,而是基于一套较为精准的评估体系。当任务执行满足以下任一关键条件时,系统便会自动触发 skill_manage 工具来创建或更新技能。
-
高频执行:当同一基础工具、工具调用序列,或具有相似特征的任务被重复执行一定次数时,Hermes 会将其识别为可复用的高频模式。通常阈值为 5 次。 -
自主纠错:当 Agent 通过试错成功解决棘手错误,走通非标准但有效的执行路径时,其修复过程与有效路径会被自动记录并固化为技能。 -
用户反馈:当用户对 Agent 的某个输出提供显式修正指导时,系统会分析其前后逻辑差异,并将这些高价值反馈吸收、内化为新技能。 -
复杂任务:当任务执行链条达到一定复杂度时,例如包含 3 个及以上子任务,或工具调用链的执行成功率达到 90% 以上,系统会判定其具备提炼价值,并自动生成标准化技能模板。
此外,Skills Manager 负责管理 ~/.hermes/skills/ 目录下的全部技能文件夹。每个技能通常包含一个 SKILL.md(步骤说明)以及可选脚本。
-
从经验到技能的固化:满足条件时,Agent 的核心逻辑会调用 skill_manage工具(通常是create动作),生成一个符合agentskills.io开放标准的SKILL.md文档,其中包含 YAML 元数据和 Markdown 操作指南。 -
定制化触发门槛:开发者可根据需要调整触发阈值。例如通过 skill_trigger: min_executions: 5这样的配置项,将阈值设为大于或小于 5 次。 -
持续自我优化:已生成的技能并非一成不变。Hermes 会主动检测技能是否过时、存在缺陷或效率偏低,一旦发现问题,就会自动调用 patch动作进行精准修复。
3. Curator(策展器)
-
运行在后台(或由 Cron 周期性触发),向 Agent 发送类似“请回顾你最近的任务,哪些信息值得长期记忆?哪些重复步骤可以提炼成新技能?”的提示。 -
作用:弥补 Agent 自身缺乏元认知的缺陷。Agent 往往专注于当前任务,不会主动反思;Curator 则像一个“外部教练”,持续推动经验沉淀。 -
输出:调用 Memory Manager 更新记忆文件,或调用 Skills Manager 创建 / 更新技能。
4. Honcho Memory Provider(可选记忆后端)
-
替换默认基于 USER.md的简单文本记忆。 -
特点:采用辩证式用户建模(Dialectical User Modeling),能够处理彼此矛盾的用户陈述(例如“我喜欢简洁回答”与“请详细解释”),并通过置信度加权合并为更紧凑、无明显冲突的用户画像。 -
输出:仍会生成 USER.md,但内容经过 Honcho 优化,信息密度更高。
闭环工作流程
1. 用户与 Agent 对话 → 完成某个任务(如“部署一个 Flask 应用”)。2. Curator 定时触发 → 提示 Agent:“该任务中哪些步骤值得抽象?”3. Agent 使用 Memory Manager 记录关键约定(如“生产环境使用 Gunicorn”)。4. Agent 调用 Skills Manager 生成新技能 `deploy_flask`(内含步骤及参数)。5. 下次用户说“用 Flask 技能部署” → Skills Manager 自动加载该技能 → Agent 快速完成,无需重复解释。6. Honcho(若启用)持续分析并修正用户偏好,使 `USER.md` 越来越精准。为什么是“闭环”?
-
正向反馈:任务执行 → 经验固化 → 后续任务更快 → 更多时间探索新任务 → 进一步积累经验。 -
无需人工干预:除初始安装外,Curator 与 Memory Manager 的交互可由 Agent 自主完成。 -
跨会话持久化:记忆与技能存储在磁盘上,即使重启 Hermes,下次对话依然有效。
2.3 底层进化能力
底层进化,指的是 Hermes 如何通过 GRPO 闭环持续提升专项能力。当某一类任务仅靠 Skill、提示词或记忆机制已经很难继续提升时,Hermes 就可以借助 GRPO 做定向强化学习,训练出更适合该领域的新策略,甚至新的模型版本。
这里需要特别说明:Hermes 的 GRPO 闭环是一个离线能力升级系统,更偏向研究与工程扩展,并不是普通用户开箱即用的自动参数更新机制。
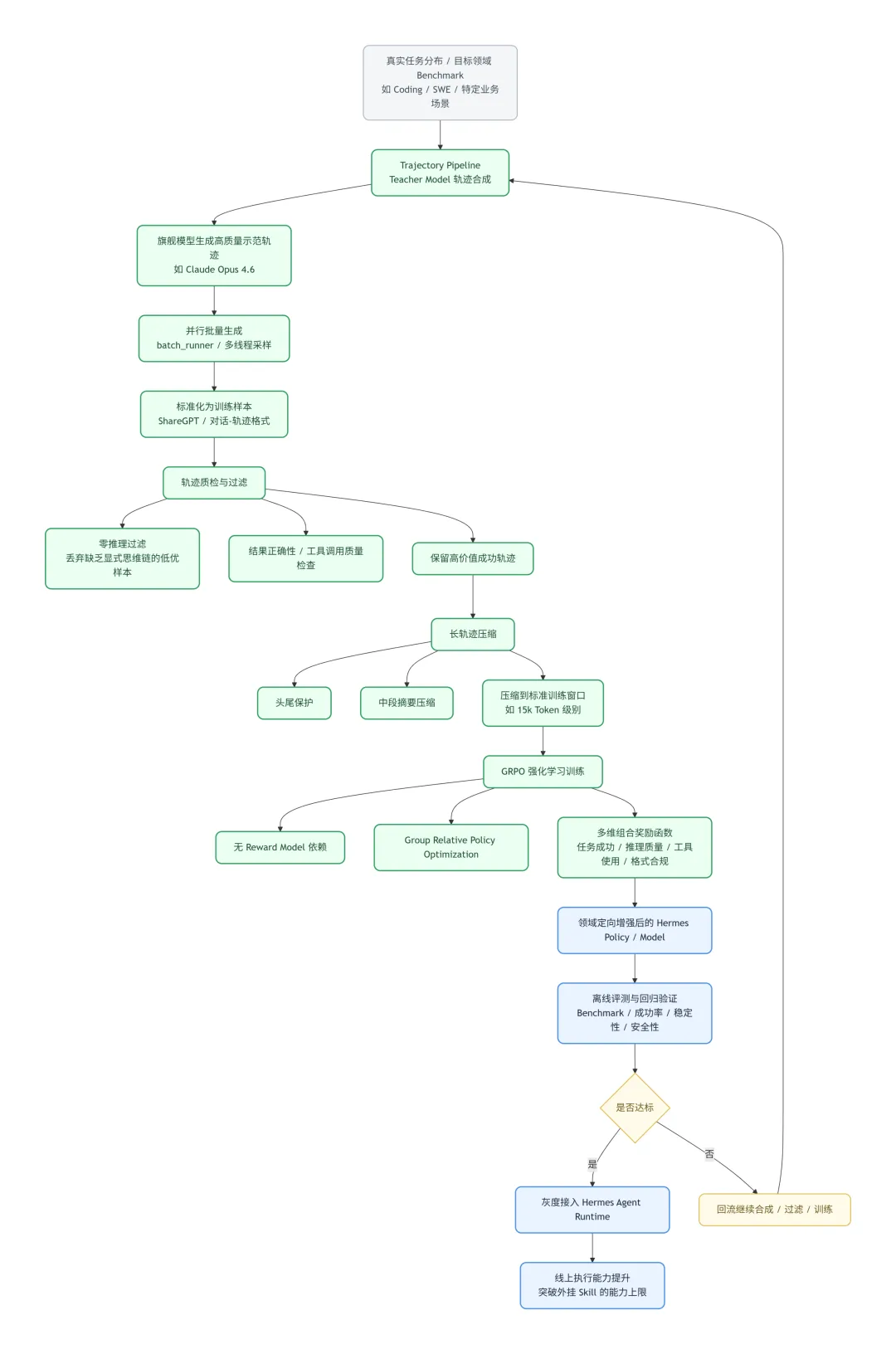
我们可以将它的训练流程拆解为四步:
-
第一步:高质量轨迹合成,而非被动收集数据Hermes 会使用旗舰模型作为 Teacher Model,围绕特定任务集或 Benchmark,批量生成高质量示范轨迹,并统一整理为标准训练格式。这意味着 Hermes 的训练数据并不完全依赖线上自然积累,而是可以主动构造。
-
第二步:质检过滤Agent 任务的执行轨迹通常较长,其中会包含大量试错、搜索与工具调用。Hermes 不会直接将这些原始长轨迹送入训练,而是先进行严格质检,过滤掉缺乏显式推理、结果质量差或工具调用混乱的低价值样本。
-
第三步:轨迹压缩系统采用“头尾保护、中间摘要”的方式,将超长轨迹压缩进标准训练窗口,同时尽量保留任务上下文与关键决策链路。
-
第四步:使用 GRPO 做定向强化GRPO 全称为群体相对策略优化(Group Relative Policy Optimization)。它不依赖独立的 Reward Model,而是通过组内相对优化提升表现。奖励可以覆盖多个方面,例如任务是否完成、推理过程是否清晰、工具使用是否高效、输出格式是否符合要求,以及行为是否稳定、安全。这替代了传统 RLHF 中需单独训练 Reward Model 的复杂流程,显著降低了训练难度与成本。
多维组合奖励函数设计参考表
|
|
|
|
|
|---|---|---|---|
| 正确性 |
|
|
|
| 格式规范 |
|
<reasoning>...<answer> 协议,按规定格式输出推理与答案 |
|
| 渐进格式 |
|
|
|
2.4 运行保障能力
运行保障,指的是 Hermes agent 如何通过 Harness,把大模型变成一个更可控的数字员工。
在 AI Agent 领域,Harness 普遍指为大语言模型提供工具调用、记忆管理和执行循环的底层支撑框架,相当于赋予模型“动手能力”与“运行环境”的基础设施。
这里运行保障主要通过以下三条核心机制来达成:
-
第一条主线:生命周期 Hook 拦截例如
on_agent_start、on_tool_call等钩子,允许我们在不修改主干逻辑的前提下,插入安全审计、权限控制、日志记录等能力。 -
第二条主线:结构化异常自愈体系Hermes 不是用“失败了就重试”这种粗粒度方式处理问题,而是将异常拆分为 14 类标准类型,并为每一类异常绑定对应恢复策略。
-
第三条主线:深层沙箱隔离机制这里主要体现为对多 Agent 的严格隔离。为防止递归死锁与权限逃逸,子 Agent 的并发数最多为 3 个,调用深度最多为 2 层,同时会屏蔽部分核心工具。
正是借助这些机制,Hermes 才能在可控边界内安全地开展工作。
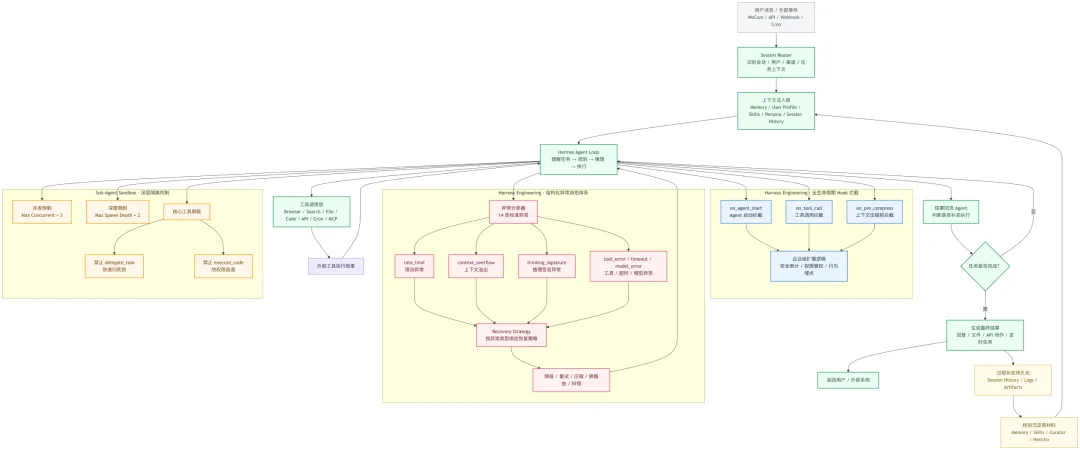
Harness 工程 = 给大模型这个“发动机”加上一整套“保护与安全系统”,让它能稳定运行、不轻易出事故。
大模型本身可能出错、产生幻觉,甚至被恶意利用。Hermes 在模型外层搭建了一套工程脚手架,用来确保输出可靠、运行安全,并在出现问题时具备一定的自愈能力。
2.4.1 结构化异常自愈体系
这不是简单的“出错后重试”,而是先识别错误类型,再进行针对性恢复。
Hermes 预设了 14 种异常分类,例如:
-
rate_limit:API 调用过于频繁,被限流 → 策略:等待几秒后再试。 -
context_overflow:对话过长,超出模型限制 → 策略:自动压缩历史上下文。 -
thinking_signature:模型进入无意义的循环思考 → 策略:强制打断并重新规划。
每类错误都有独立恢复方法,而不是盲目重试。这能保证长任务(例如整夜运行的批量处理)不会因为一次偶发错误就彻底失败。
2.4.2 全生命周期 Hook 拦截
你可以在不修改 Hermes 源代码的前提下,在关键节点插入自定义逻辑,用于审计、监控或权限控制。
例如:
-
on_agent_start:Agent 启动时,记录调用者和启动时间。 -
on_tool_call:Agent 每次执行命令或读取文件前,先检查是否具备权限。 -
on_pre_compress:在压缩对话历史前,先备份一份原始对话。
这相当于给 Agent 装上了“监控摄像头”和“遥控开关”,企业可以借此满足合规与审计要求。
2.4.3 深层沙箱隔离机制
为了避免 Agent 自己把自己“搞死”,或者子 Agent 失控,必须给它们加上明确约束。
具体限制包括:
-
并发数 ≤ 3:不能同时开启过多子任务,避免资源被耗尽。 -
调用深度 ≤ 2 层:子 Agent 不能再创建子 Agent,防止无限递归。 -
禁止访问危险工具:子 Agent 不能调用 delegate_task(避免继续派生子 Agent),也不能调用execute_code(避免执行任意代码导致权限逃逸)。
可以把它理解为:允许你找帮手(子 Agent),但帮手不能再去找帮手,而且帮手不能使用危险工具。
Harness 工程回答了一个核心问题:Agent 距离“真正可用”还缺什么? 答案并不只是一个会调用工具的模型,而是一整套工程化的运行、监控、安全、自愈体系。Hermes 把这些能力补齐了,因此它才有底气宣称:自己是在“将通用大模型锤炼为垂直领域的顶尖专家”。
模型是心脏,Harness 工程则是骨骼、血管与免疫系统。没有后者,心脏再强,也很难真正站起来。
3. 安装部署
Windows 用户注意:需通过 WSL2(Windows Subsystem for Linux)运行 Hermes Agent。Hermes Agent 基于 Python 和 Node.js 构建,部分依赖库(如
ripgrep、ffmpeg)在 Windows 原生环境中兼容性不佳。WSL2 提供完整的 Linux 内核环境,是 Windows 上运行 Hermes Agent 的最佳方案。
3.1 系统要求与 WSL2 配置(Windows 用户)
前提条件:Windows 10(2004+)或 Windows 11
-
以管理员身份打开 PowerShell,执行:
wsl --install -d Ubuntu-22.04 -
重启电脑。
-
启动 Ubuntu,并设置用户名与密码。
3.2 安装 Hermes Agent
3.2.1 配置 Ubuntu 环境
在 Ubuntu 终端中依次执行:
# 更新系统sudo apt update && sudo apt upgrade -y# 安装核心依赖sudo apt install -y build-essential python3.12 python3.12-venv python3.12-dev \ nodejs npm git ripgrep ffmpeg curl wget# 验证版本python3.12 --version # 需要 3.12+node --version # 需要 18+3.2.2 执行安装脚本
curl -fsSL https://res1.hermesagent.org.cn/install.sh | bash3.2.3 启动 Hermes
hermes3.2.4 配置模型
hermes modelhermes setup根据提示配置你要使用的模型即可。
3.3 配置消息平台(以企业微信为例)
为 Hermes Agent 配置消息网关,本质上是将“对话渠道”与“智能逻辑”分离,让 AI 能力通过用户已有的沟通工具触达最终用户。
3.3.1 前置条件
-
一个企业微信组织账号(自行申请即可) -
在企业微信管理后台创建一个 AI Bot -
获取 Bot ID 和 Secret
3.3.2 设置步骤
-
登录 企业微信管理后台,进入安全与管理 → 管理工具 → 创建 → 创建机器,配置机器人名称和描述,然后复制 Bot ID 与 Secret。
-
配置 Hermes:
-
方式一:交互式设置
hermes gateway setup选择 WeCom 并输入 Bot ID 与 Secret。
-
方式二:环境变量设置
在
~/.hermes/.env中添加:WECOM_BOT_ID=your-bot-idWECOM_SECRET=your-secretWECOM_ALLOWED_USERS=user_id_1,user_id_2 # 可选WECOM_HOME_CHANNEL=chat_id # 可选 -
启动网关:
hermes gateway
3.3.3 功能特性
-
WebSocket 传输(持久连接,无需公网端点) -
私聊与群聊消息(可配置访问策略) -
媒体支持(图片、文件、语音、视频) -
AES 加密媒体(自动解密入站附件) -
引用上下文(保留回复线程) -
Markdown 渲染(富文本响应) -
自动重连(指数退避机制)
4. 实践案例
4.1 案例一:构建每日简报机器人
这是一个最简单的官方实践教程,流程如下:
-
上午 8:00:Cron 调度器触发任务。 -
Hermes 启动一个带有指定 Prompt 的全新 Agent 会话。 -
执行网页搜索,抓取最新新闻。 -
总结为简报格式。 -
交付到企业微信(或飞书、微信等渠道)。
整个过程无需人工干预,你只需在喝早咖啡时阅读简报即可。
前提条件
-
已安装 Hermes Agent。
-
Gateway 正在运行。Gateway 守护进程负责处理 Cron 执行:
hermes gateway install # 作为用户服务安装sudo hermes gateway install --system # Linux 服务器:开机自启# 或前台运行hermes gateway -
Firecrawl API Key:在环境变量中设置
FIRECRAWL_API_KEY用于网页搜索。注册 Firecrawl 获取FIRECRAWL_API_KEY后,可直接用自然语言告诉 Hermes:FIRECRAWL_API_KEY=fc-xxxxxxxxxxxxx,让其代为配置。

-
已配置消息通道。若已创建企业微信 AI Bot,可直接用于推送;即使没有消息通道,也仍可通过 Hermes 启动一个聊天会话进行测试。
第 1 步:手动测试工作流
启动聊天会话:
hermes输入以下 Prompt:
搜索关于 AI Agents 和开源 LLM 的最新新闻。以简洁的简报格式总结前 3 条故事,并附上链接。Hermes 将搜索网页、阅读结果,并生成类似如下的内容:
☀️ 您的 AI 简报 — 2026 年 3 月 8 日1. Qwen 3 发布,拥有 235B 参数 阿里巴巴最新的开源权重模型在多个基准测试中追平了 GPT-4.5, 同时保持完全开源。 → https://qwenlm.github.io/blog/qwen3/2. LangChain 发布 Agent 协议标准 一种新的 Agent 间通信开放标准在发布首周就获得了 15 个主流框架的采用。 → https://blog.langchain.dev/agent-protocol/3. 欧盟 AI 法案开始对通用模型实施 首批合规截止日期到来,10M 参数阈值以下的开源模型 获得了豁免。 → https://artificialintelligenceact.eu/updates/如果运行正常,就可以开始自动化了。
第 2 步:创建 Cron 任务
现在让我们安排它每天早晨自动运行。你可以通过在企业微信聊天中实现。
直接告诉 Hermes AI BOT 你的需求:
每天早晨 8 点,搜索网页获取关于 AI Agents 和开源 LLM 的最新新闻。以简洁的简报格式总结前 3 条故事并附上链接。使用友好、专业的语气。发送到企业微信。Hermes 将使用统一的 cronjob 工具为你创建 Cron 任务。
黄金法则:自包含 Prompt
Cron 任务运行在完全全新的会话中——没有之前对话的记忆。因此,Prompt 必须包含 Agent 完成工作所需的全部信息。
❌ 不好的 Prompt:
做我平时的早间简报。✅ 好的 Prompt:
搜索网页获取关于 AI Agents 和开源 LLM 的最新新闻。查找过去 24 小时内至少 5 篇近期文章。以简洁的每日简报格式总结最重要的前 3 条故事。每条故事包括:一个清晰标题、2 句总结和来源 URL。使用友好、专业的语气。使用 emoji 项目符号进行格式化。好的提示词明确了搜索什么、需要多少篇文章、输出什么格式以及使用什么语气。这是 Agent 一次性完成任务所需的全部上下文。
第 3 步:自定义简报
一旦基础简报运行正常,你就可以进一步发挥创意。
-
多主题简报:在一个 Prompt 中涵盖多个领域。
/cron add "0 8 * * *" "创建一份涵盖三个主题的早间简报。针对每个主题,搜索网页获取过去 24 小时内的近期新闻,并总结前 2 条故事并附上链接。主题:1. AI 和机器学习 —— 侧重于开源模型和 Agent 框架2. 加密货币 —— 侧重于比特币、以太坊和监管新闻3. 空间探索 —— 侧重于 SpaceX、NASA 和商业航天格式要求:整洁的简报,带有章节标题和 emoji。最后附上今天的日期和一句励志名言。"-
使用委派进行并行研究:让 Hermes 将每个主题委派给 sub-agent,以加快生成速度。
/cron add "0 8 * * *" "通过将研究任务委派给 sub-agents 来创建早间简报。委派三个并行任务:1. Delegate: 搜索过去 24 小时内前 2 条 AI/ML 新闻故事并附带链接2. Delegate: 搜索过去 24 小时内前 2 条加密货币新闻故事并附带链接3. Delegate: 搜索过去 24 小时内前 2 条空间探索新闻故事并附带链接收集所有结果并将它们合并为一份整洁的简报,包含章节标题、emoji 格式和来源链接。添加今天的日期作为标题。"每个 sub-agent 都会独立且并行地进行搜索,然后由主 Agent 将内容汇总为一份完整简报。有关其工作方式的更多信息,可参阅委派文档。
-
仅限工作日:如果周末不需要简报,可使用针对周一至周五的 Cron 表达式 0 8 * * 1-5。
/cron add "0 8 * * 1-5" "搜索最新的 AI 和科技新闻..."-
每日两次简报:添加早间和晚间两个任务。
/cron add "0 8 * * *" "早间简报:搜索过去 12 小时的 AI 新闻..."/cron add "0 18 * * *" "晚间回顾:搜索过去 12 小时的 AI 新闻..."-
通过 Memory 添加个人上下文:如果你启用了 Memory,可以存储跨会话持久化的偏好设置。但请记住,Cron 任务运行在没有对话记忆的新会话中。若要添加个人上下文,请直接将其写入 Prompt:
/cron add "0 8 * * *" "你正在为一位资深 ML 工程师创建简报,他关心:PyTorch 生态系统、Transformer 架构、开源权重模型以及欧盟 AI 监管。除非涉及开源,否则跳过关于产品发布或融资的消息。搜索关于这些主题的最新新闻。总结前 3 条故事并附上链接。保持简洁和专业——读者不需要基础解释。"-
定制 Persona:直接告诉 Agent 你的角色、兴趣,以及需要跳过的内容。
第 4 步:管理任务
-
列出所有任务:
在聊天中输入:
/cron list或者在终端中执行:
hermes cron list你会看到类似如下的输出:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
-
移除任务:
在聊天中输入:
/cron remove a1b2c3d4或者使用自然语言:
Remove my morning briefing cron job.Hermes 会先调用 cronjob(action="list") 查找对应任务,再调用 cronjob(action="remove") 将其删除。
-
检查网关状态:
确保调度器(scheduler)正在运行:
hermes cron status如果 Gateway 没有运行,你的任务将无法执行。为保证可靠性,建议将其安装为后台服务:
hermes gateway install# 或者在 Linux 服务器上sudo hermes gateway install --system至此,你已经构建了一个可以正常工作的每日简报机器人。后续还可以继续探索:
-
**定时任务(Cron)**:关于调度格式、重复限制和推送选项的完整参考。 -
**任务委派(Delegation)**:深入了解并行 sub-agent 工作流。 -
**消息平台**:设置 Telegram、Discord 或其他推送目标。 -
**记忆(Memory)**:配置跨会话持久化上下文。 -
**技巧与最佳实践**:获取更多 Prompt 工程建议。
还能定时做什么? 竞争对手监控、GitHub 仓库摘要、天气预报、投资组合追踪、服务器健康检查,甚至每日笑话。只要能用 Prompt 描述,就可以被定时运行。
4.2 案例二:构建研发 Agent 军团
OpenClaw 的多智能体军团模式,同样可以在 Hermes Agent 上跑通。所有步骤都只需通过和 Hermes 对话,把要求说清楚即可。
相关案例可参考:
-
https://zhuanlan.zhihu.com/p/2030032217070637725 -
https://blog.csdn.net/wangjianwangzhefeng/article/details/160483927
5. 源码解析
Hermes 的整体架构可以概括为 “多入口 → 单一 Agent 核心 → 多样化后端” 的三层结构:
-
入口层:CLI、Gateway、ACP 适配器(对接 VS Code / Zed / JetBrains)、Batch Runner、API Server 等。 -
核心层: run_agent.py中的AIAgent类,统一编排提示词构建、Provider 选择、工具调度与会话持久化。 -
后端层:SQLite + FTS5 会话存储,以及终端(7 种后端)、浏览器(5 种后端)、Web、MCP 等多种执行后端。
┌─────────────────────────────────────────────────────────────────────┐│ 入口层(Entry Points) ││ ││ CLI (cli.py) Gateway (gateway/run.py) ACP (acp_adapter/) ││ Batch Runner API Server Python Library │└──────────┬──────────────┬───────────────────────┬───────────────────┘ │ │ │ ▼ ▼ ▼┌─────────────────────────────────────────────────────────────────────┐│ Agent 核心(AIAgent,run_agent.py) ││ ││ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ││ │ Prompt │ │ Provider │ │ Tool │ ││ │ Builder │ │ Resolution │ │ Dispatch │ ││ │ (prompt_ │ │ (runtime_ │ │ (model_ │ ││ │ builder.py) │ │ provider.py)│ │ tools.py) │ ││ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ ││ │ │ │ ││ ┌──────┴───────┐ ┌──────┴───────┐ ┌──────┴───────┐ ││ │ Compression │ │ 3 API Modes │ │ Tool Registry│ ││ │ & Caching │ │ chat_compl. │ │ (registry.py)│ ││ │ │ │ codex_resp. │ │ 68 tools │ ││ │ │ │ anthropic │ │ 52 toolsets │ ││ └──────────────┘ └──────────────┘ └──────────────┘ │└─────────┴─────────────────┴─────────────────┴───────────────────────┘ │ │ ▼ ▼┌───────────────────┐ ┌──────────────────────┐│ 会话存储 │ │ 工具后端 ││ Session Storage │ │ Tool Backends ││ (SQLite + FTS5) │ │ Terminal (7 backends) ││ hermes_state.py │ │ Browser (5 backends) ││ gateway/session.py│ │ Web (4 backends) │└───────────────────┘ │ MCP (动态) │ │ File / Vision / ... │ └──────────────────────┘代码目录结构如下:
hermes-agent/├── run_agent.py # AIAgent —— 核心对话循环(约 9,200 行)├── cli.py # HermesCLI —— 交互式终端界面(约 8,500 行)├── model_tools.py # Tool 发现、Schema 收集与分发├── toolsets.py # Tool 分组与平台预设├── hermes_state.py # SQLite 会话 / 状态数据库与 FTS5├── hermes_constants.py # HERMES_HOME 与 profile 感知路径├── batch_runner.py # 批量轨迹生成│├── agent/ # Agent 内部结构│ ├── prompt_builder.py # System Prompt 组装│ ├── context_engine.py # ContextEngine ABC(可插拔)│ ├── context_compressor.py # 默认引擎——有损摘要│ ├── prompt_caching.py # Anthropic Prompt 缓存│ ├── auxiliary_client.py # 用于辅助任务的辅助 LLM(Vision、总结)│ ├── model_metadata.py # Model Context 长度与 Token 估算│ ├── models_dev.py # models.dev 注册表集成│ ├── anthropic_adapter.py # Anthropic 消息 API 格式转换│ ├── display.py # KawaiiSpinner、Tool 预览格式│ ├── skill_commands.py # Skill 斜杠命令│ ├── memory_manager.py # Memory 管理器编排│ ├── memory_provider.py # Memory Provider ABC│ └── trajectory.py # 轨迹保存助手│├── hermes_cli/ # CLI 子命令和设置│ ├── main.py # 入口点 —— 所有 `hermes` 子命令│ ├── config.py # DEFAULT_CONFIG、OPTIONAL_ENV_VARS、迁移│ ├── commands.py # COMMAND_REGISTRY — 中央斜线命令定义│ ├── auth.py # PROVIDER_REGISTRY,凭证解析│ ├── runtime_provider.py # Provider → `api_mode` + 凭证│ ├── models.py # Model 目录、Provider 模型列表│ ├── model_switch.py # /model 命令逻辑(CLI + gateway 共享)│ ├── setup.py # 交互式设置向导(约 3,100 行)│ ├── skin_engine.py # CLI 主题引擎│ ├── skills_config.py # `hermes skills` —— 按平台启用 / 禁用│ ├── skills_hub.py # `/skills` 斜杠命令│ ├── tools_config.py # `hermes tools` —— 按平台启用 / 禁用│ ├── plugins.py # PluginManager —— 发现、加载与挂钩│ ├── callbacks.py # 终端回调(澄清、sudo、批准)│ └── gateway.py # `hermes gateway` 启动 / 停止│├── tools/ # Tool 实现(每个 Tool 一个文件)│ ├── registry.py # 中央 tool 注册表│ ├── approval.py # 危险命令检测│ ├── terminal_tool.py # 终端编排│ ├── process_registry.py # 后台进程管理│ ├── file_tools.py # 读文件、写文件、补丁、搜索文件│ ├── web_tools.py # 网络搜索、网络提取│ ├── browser_tool.py # 11 个浏览器自动化 Tool│ ├── code_execution_tool.py # `execute_code` 沙箱│ ├── delegate_tool.py # Subagent 委派│ ├── mcp_tool.py # MCP 客户端(约 2,200 行)│ ├── credential_files.py # 基于文件的凭证传递│ ├── env_passthrough.py # 沙箱的环境变量直通│ ├── ansi_strip.py # ANSI 逃逸剥离│ └── environments/ # 终端后端(本地、Docker、SSH、Modal、Daytona、Singularity)│├── gateway/ # 消息平台 Gateway│ ├── run.py # GatewayRunner —— 消息分发(约 7,500 行)│ ├── session.py # SessionStore — 会话持久化│ ├── delivery.py # 出站消息传递│ ├── pairing.py # DM配对授权│ ├── hooks.py # 钩子发现和生命周期事件│ ├── mirror.py # 跨session消息镜像│ ├── status.py # Token 锁,profile 范围内的进程跟踪│ ├── builtin_hooks/ # 始终注册的钩子│ └── platforms/ # 15 个适配器:telegram、discord、slack、whatsapp、│ # signal、matrix、mattermost、电子邮件、短信、│ # dingtalk、feishu、wecom、weixin、bluebubbles、家庭助理、webhook│├── acp_adapter/ # ACP 服务器(VS 代码 / Zed / JetBrains)├── cron/ # 调度程序(jobs.py、scheduler.py)├── plugins/memory/ # Memory provider 插件├── plugins/context_engine/ # Context 引擎插件├── environments/ # 强化学习训练环境 (Atropos)├── skills/ # 捆绑 skills(始终可用)├── optional-skills/ # 官方可选skills(显式安装)├── website/ # Docusaurus 文档网站└── tests/ # Pytest 套件(“0”,000+ 测试)5.1 入口层(Entry Points)
入口层提供多种调用方式,均对接同一个 AIAgent 核心。
5.1.1 六种调用方式
|
|
|
|---|---|
| CLI / TUI | hermes
/model、/personality、/new、/reset、/compress、/skills、/cron、/kanban 等。 |
| Gateway | hermes gateway start
|
| ACP Adapter |
|
| API Server | hermes api start
|
| Batch Runner | hermes batch run
|
| Python Library |
from run_agent import AIAgent 在 Python 程序中使用。 |
5.1.2 Gateway 内部机制:多平台分发
Gateway 将消息平台和 Agent 解耦,核心流程:
Telegram / Discord / Slack / WeCom / Feishu / DingTalk / ... ↓ Adapter 把平台事件统一为 GatewayMessage gateway/run.py 的 GatewayRunner(消息泵) ↓ 根据 conversation_id 找对应 SessionStore 的会话 AIAgent.run_conversation(...) ↓ 文本/语音/图片附件 → 转成 OpenAI 格式 gateway/delivery.py 出站投递 ↓ 按平台 adapter 还原成 Telegram/Discord/Slack 的消息关键能力:
-
DM Pairing( gateway/pairing.py):陌生人发起对话需要先经过授权,避免被滥用; -
Cross‑Session Mirror( gateway/mirror.py):在不同平台的对话之间镜像消息,实现“在 Telegram 跟它说话,在 Slack 也能看到上下文”; -
Status / Token Lock( gateway/status.py):避免同一个 Profile 被多个进程同时启动; -
Hooks( gateway/hooks.py):基于~/.hermes/hooks/下的HOOK.yaml+handler.py监听agent:start/agent:end/command:*等生命周期事件。
5.1.3 自动化层(Cron、Kanban、Webhook)
Hermes 提供三种互补的自动化机制,覆盖周期性任务、事件驱动任务和需人工介入的工作流。
Cron – 定时任务
-
定义:基于时间的任务调度器( cron/模块),每个 job 运行在全新的 Agent 会话中,可挂载技能,结果可投递到消息平台、邮件或文件。 -
适用场景: -
每日简报、周报生成 -
定时监控(服务器状态、竞品价格、GitHub 仓库趋势) -
定期数据备份或清理 -
用法示例: # 在聊天中直接告诉 Hermes/cron add "0 8 * * *""搜索 AI 新闻并发送到企业微信" -
何时使用:任务执行无需外部事件触发,无需人工实时介入,完全可自动化。
Webhook – 事件驱动
-
定义:Gateway 的 webhook 适配器接收外部系统(GitHub、Stripe、Slack 等)发送的 HTTP 请求,实时触发 Hermes 执行任务。 -
适用场景: -
PR 创建时自动运行代码检查并评论 -
支付成功后更新数据库并发送通知 -
Slack 斜杠命令直接调用 Agent -
配置示例(在 Gateway 中启用 webhook 平台): hermes gateway setup # 选择 webhook,获取回调 URL -
何时使用:任务由外部实时事件驱动,响应时间要求短(秒级),逻辑相对线性。
Kanban – 看板工作流
-
定义:基于 SQLite 的任务看板系统( hermes kanban+kanban_*工具组),支持多 Profile 协作、状态流转、人工介入与断点恢复。 -
适用场景: -
研发需求评审流程(设计 → 前端 → 后端 → 测试 → 发布) -
运维变更工单(申请 → 审批 → 执行 → 验证) -
多步骤数据分析任务(每一步需人工确认或处理异常) -
用法示例: hermes kanban create "修复登录 bug" --assignee @dev-team -
何时使用:任务需要多角色、多步骤、可暂停恢复,且需要持久化状态和人工决策。
决策指南
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
快速选择:
-
固定时间执行 → Cron -
外部事件触发且执行快速 → Webhook -
多步骤、需人工干预 → Kanban -
可以组合使用:例如 Webhook 接收事件后自动创建 Kanban 卡片,Cron 定期生成看板进度报表。
5.2 Agent 核心层(Agent Core)
run_agent.py 中的 AIAgent 是 Hermes 的“心脏”,负责提示词构建、Provider 选择、工具调度、会话管理与持久化。
5.2.1 AI Agent 核心职责
-
通过 prompt_builder.py拼装系统提示与工具 schema -
选择合适的 Provider 与 API 模式( chat_completions/codex_responses/anthropic_messages) -
发起可中断的模型调用( _interruptible_api_call) -
顺序或并发执行工具调用(带线程池) -
维护 OpenAI 格式的对话历史 -
执行压缩、重试、Provider 故障切换 -
跟踪父子 Agent 的迭代预算 -
在上下文耗尽前持久化记忆
5.2.2 三种 API 模式
|
|
|
|
|---|---|---|
chat_completions |
|
openai.OpenAI |
codex_responses |
|
openai.OpenAI
|
anthropic_messages |
|
anthropic.Anthropic
|
-
模式选择优先级:构造参数 > Provider 检测 > base URL 启发式 > 默认 chat_completions。 -
三种模式的消息编码、工具调用结构、流式与缓存机制不同,但内部统一收敛为 OpenAI 风格的 role/content/tool_calls字典。
5.2.3 Turn 生命周期(run_conversation())
Agent 处理单次用户消息(即一个“Turn”)的完整执行流程,是理解 Hermes 如何工作、如何管理长对话、如何调用工具的核心逻辑。每次你发一条消息给 Hermes,run_conversation() 都会被调用一次,整个生命周期可以分为四个阶段:
阶段一:准备上下文
在这一阶段,Hermes 为模型调用准备好所有必需的信息:
-
为本次任务生成唯一 ID( task_id),用于追踪和日志。 -
将你的消息追加到对话历史(维持完整的上下文)。 -
根据当前配置组装系统提示词(身份、记忆、技能列表等 prompt_builder.py),如果支持缓存则复用。 -
检查上下文长度:如果已用比例超过 50%,立即启动异步压缩,防止超出模型窗口限制。 -
将内部的对话历史转换为目标 API 要求的格式(OpenAI / Anthropic 的结构略有不同)。 -
注入临时提示层(ephemeral),比如提醒模型“上下文预算紧张,请尽量简洁”。 -
若使用 Anthropic 模型,打上 Prompt Caching 标记以降低成本。( 如果选用 Claude 等 Anthropic 家的模型,就在发给模型的提示中,给那些重复不变的长内容打上“缓存”标签,让 API 复用之前的计算结果,从而减少计算开销和费用。)
阶段二:调用模型
-
执行 _interruptible_api_call:向大模型发送当前消息 + 历史 + 工具定义。 -
这个调用是可中断的:用户按 Ctrl+C可以即时停止,Agent 会优雅退出循环。
阶段三:解析与执行工具(步骤 9 的分支 A)
如果模型返回的是 工具调用请求(例如 execute_command、search_web):
-
Hermes 解析工具名称和参数。 -
执行工具(并发或顺序,取决于工具类型)。 -
将工具的执行结果(输出、错误信息)以 tool角色追加到对话历史。 -
跳回阶段二(重新调用模型),让模型基于工具结果继续推理。
这个循环可能重复多次,直到模型不再请求工具。
阶段四:产出最终回复(步骤 9 的分支 B)
如果模型返回的是 纯文本回复(即最终答案):
-
将回复追加到对话历史。 -
持久化会话到 SQLite 数据库(可随时恢复)。 -
若内存管理器有未刷新的条目,执行 flush写入长期记忆(MEMORY.md/USER.md)。 -
将回复返回给用户(CLI、Gateway 或 API 调用者),本次 Turn 结束。
可视化流程
用户消息 → [准备上下文] → [调用模型] ↓ 模型返回工具调用? → 是 → 执行工具 → 追加结果 → 回到“调用模型” ↓ 否 最终回复 → 持久化 & 刷新记忆 → 返回用户为什么这个生命周期重要?
-
支持多步工具调用:Agent 不是一问一答,而是可以反复“思考-行动-观察”,直到任务完成。 -
自动上下文管理:超过阈值即压缩,避免超出模型限制导致失败。 -
可打断:用户可以在模型思考或工具执行过程中中止,节省时间。 -
故障恢复:会话持久化后,即使 Agent 重启,也能从上次中断的地方继续。
5.2.4 Prompt 构建(prompt_builder.py)
Hermes 的系统提示(System Prompt)并非硬编码字符串,而是由多个可插拔的槽位(Slot)按固定顺序动态拼装而成。这种设计使得不同来源(身份、记忆、项目约定、工具定义)的信息能够有机融合,同时支持渐进披露(Progressive Disclosure)以控制 Token 消耗。
拼装顺序(从上到下,后添加的内容在提示中更靠后):
-
Identity(身份核心)
-
来源: ~/.hermes/SOUL.md或内置默认。 -
作用:定义 Agent 的基本人格、职责边界、回答风格(如“你是一位资深 SRE 工程师”)。 -
特点:整个会话生命周期内固定,是缓存友好的基础层。 -
Personality(性格预设,可选)
-
来源:通过 /personality命令动态指定。 -
作用:叠加临时性格特征(例如“用幽默风趣的语气回答”)。 -
注意:不设置时直接跳过该槽位。 -
MEMORY(长期工作约定)
-
来源: ~/.hermes/memories/MEMORY.md(可手动或由 Agent 自动更新)。 -
作用:存储与环境、项目、工作流相关的持久化事实(如“项目使用 React 18 + TypeScript”)。 -
典型长度:约 800 Token。 -
USER PROFILE(用户画像)
-
来源: ~/.hermes/memories/USER.md。 -
作用:记录用户偏好、常用命令、个人习惯(如“用户偏好 zh-CN 输出”)。 -
典型长度:约 500 Token。 -
Context Files(项目级上下文文件)
-
来源:自动从当前工作目录向上查找 .hermes.md、AGENTS.md、CLAUDE.md、.cursorrules等。 -
作用:注入项目特有的指引(如代码规范、API 端口、测试命令)。 -
兼容性:原生支持 OpenClaw 及其他 AI 工具的配置文件格式。 -
Tool Schemas(工具模式定义)
-
来源:当前启用的 Toolset(如 web、terminal、file等组)。 -
作用:以 JSON Schema 形式告知模型可调用的工具及其参数要求。 -
动态性:随平台(CLI/Gateway)和用户配置而变化。 -
Skills Index(技能索引,Level 0)
-
来源: ~/.hermes/skills/下所有已安装技能的元数据。 -
格式:仅包含 {name, description, category}的列表(不加载完整 SKILL.md 正文)。 -
目的:实现渐进披露:先让模型知道“有哪些技能可用”,待模型决定调用某一技能时,再动态加载该技能的完整 Prompt(Level 1/2)。 -
典型长度:约 3000 Token。 -
Ephemeral Layers(临时提示层)
-
来源:程序运行时动态生成。 -
内容:上下文预算警告(“你的上下文已使用 70%”)、压缩指示(“下次回复前请压缩历史”)、预算超限降级策略等。 -
特点:每次模型调用前可能不同,不参与长期缓存。
冻结快照模式(Frozen Snapshot)
设计原理:为了最大化 Anthropic 等模型的 Prompt Caching 命中率,Hermes 在会话开始时将槽位 1–5(Identity、Personality、MEMORY、USER PROFILE、Context Files)快照一次,整个会话期间不再变更。即使 Agent 在运行过程中修改了 MEMORY.md,系统提示也不会实时更新,直到下一次创建新会话(或用户显式/reset)。好处:相同的系统提示前缀可以被模型服务端缓存,大幅降低重复调用的 Token 成本(对于长上下文模型尤其显著)。 代价:会话内对记忆文件的修改不会立即体现在系统提示中。Hermes 通过工具响应(Tool Response)或显式的“记住”命令来弥补这一限制。
5.2.5 消息交替规则
Hermes 在调用 OpenAI、Anthropic 等模型 API 时,必须严格遵循 Provider 规定的消息角色交替顺序。错误的交替会导致 API 直接拒绝请求,因此 Hermes 在构造对话历史时会强制校验以下规则。
基本交替模式
在一条完整的对话中,消息角色的顺序必须遵循:
System(可选) → User → Assistant → User → Assistant → ...-
系统消息后必须紧跟 User 消息,不能直接接 Assistant。 -
User 和 Assistant 必须交替出现,不允许两条连续的 User 或两条连续的 Assistant。
工具调用阶段的特殊规则
当模型请求调用工具时,交替规则发生变化:
Assistant(with tool_calls) → Tool → Tool → ... → Assistant(最终回复)-
Assistant(with tool_calls)之后只能跟 Tool 角色的消息,不能直接跟 User 或另一个 Assistant。 -
Tool 角色可以连续出现多条(对应并发工具调用的多个结果)。 -
最后必须以 Assistant 角色结束(模型综合工具结果后的最终回复)。
5.2.6 Provider Runtime:模型选择与故障切换
hermes_cli/runtime_provider.py + agent/auxiliary_client.py 协同决定每次调用走哪家模型:
-
Provider Routing:可以把多家 Provider 排序成优先级链; -
Fallback Providers:主 Provider 报错(限流/网络/5xx)时自动切换到下一家;视觉、压缩等辅助任务可以走单独的 fallback; -
Credential Pool:同一家 Provider 可挂多把 Key,按 round‑robin / 限流自动轮换; -
Auxiliary Client:耗 token 大的“次要任务”(视觉描述、长 chat 摘要、压缩)允许走更便宜/更快的辅助模型,主对话依然用旗舰模型。
5.2.7 学习闭环:Memory + Skills + Curator + Honcho
Hermes 的“越用越聪明”并非营销话术,而是由四个紧密协作的模块构成的数据闭环:执行任务 → 沉淀经验 → 优化行为 → 更高效地执行任务。下面分别介绍每个模块的角色,再串联整体流程。
各模块职责(在本文2.2节经验沉淀能力亦有介绍)
|
|
|
|
|---|---|---|
| Memory Manager | agent/memory_manager.py |
MEMORY.md / USER.md)。 |
| Skills Manager | hermes_cli/skills_config.py
skills/ |
SKILL.md),支持渐进披露加载。 |
| Curator |
user-guide/features/curator.md) |
|
| Honcho Memory Provider | plugins/memory/honcho/
|
|
详细说明
1. Memory Manager(记忆管理器)
-
暴露三个工具: memory(action="add")、memory(action="replace")、memory(action="remove")。 -
作用:让 Agent 在对话中自主决定记录什么、修改什么。例如,用户说“我以后都用 Python”,Agent 可调用 memory add将这条偏好写入USER.md。 -
目标:从“被动存储对话”升级为“主动管理知识”。
2. Skills Manager(技能管理器)
-
Hermes Agent 的技能生成并非随意触发,而是基于一套精准的评估体系,当任务执行满足以下任一关键条件时,它便会自动触发
skill_manage工具来创建或更新技能。 -
高频执行:当同一基础工具、工具调用序列或具有相似特征的任务被重复执行一定次数时,Hermes会将其识别为可复用的高频模式。通常,该阈值为5次。 -
自主纠错:当Agent通过试错成功解决棘手错误,走通非标准但有效的执行路径时,其修复过程与有效路径会被自动记录并固化为技能。 -
用户反馈:当用户对Agent的某个输出结果提供显式修正指导时,系统会分析其前后逻辑差异,将宝贵的反馈吸收并内化为自己的新技能。 -
复杂任务:当任务执行链条达到特定复杂度时,例如包含3个或以上子任务、或工具调用链的执行成功率达到90%以上,系统会判定其有提炼价值,自动生成标准化技能模板。 -
管理
~/.hermes/skills/目录下的所有技能文件夹,每个技能包含一个SKILL.md(步骤说明)以及可选的脚本。 -
从经验到技能的固化:满足条件时,Agent的核心逻辑是调用 skill_manage工具(通常是create动作)来生成一个符合agentskills.io开放标准的SKILL.md文档,包含YAML元数据和Markdown操作指南。 -
定制的触发门槛:开发者可根据需要调整触发阈值。例如通过 skill_trigger: min_executions: 5这样的配置项,可将阈值设为大于或小于5次。 -
持续的自我优化:生成的技能并非一成不变。Hermes会主动检测已生成技能是否过时、缺陷或低效,一旦发现即自动调用 patch动作进行精准修复。
3. Curator(策展器)
-
运行在后台(或由 Cron 周期性触发),向 Agent 发送类似于“请回顾你最近的任务,哪些信息值得长期记忆?哪些重复步骤可以提炼成一个新技能?”的提示。 -
作用:弥补 Agent 自身缺乏元认知的缺陷——Agent 忙于执行当前任务,不会主动反思。Curator 作为“外部教练”推动经验沉淀。 -
输出:调用 Memory Manager 更新记忆文件,或调用 Skills Manager 创建/更新技能。
4. Honcho Memory Provider(可选记忆后端)
-
替换默认的基于 USER.md的简单文本记忆。 -
特点:采用辩证式用户建模(Dialectical User Modeling),能够处理矛盾的用户陈述(例如“我喜欢简洁回答” vs “请详细解释”),通过置信度加权合并成更紧凑、无矛盾的画像。 -
输出:仍然生成 USER.md,但内容经过 Honcho 优化,信息密度更高。
5.2.8 会话存储:hermes_state.py + gateway/session.py
Hermes 使用单一 SQLite 数据库 ~/.hermes/hermes.db 存储:
-
每条对话历史(与 OpenAI 格式 1:1 对应,便于恢复); -
任务( task_id)、迭代、token usage、cost; -
工具调用日志、轨迹; -
Skills 元数据; -
Cron 任务与执行历史; -
Kanban 任务(独立 DB kanban.db)。
并启用 FTS5 全文索引,让 session_search 工具可以快速检索“上次我修过哪个 bug”。Gateway 自己也维护一份 gateway/session.py 中的 SessionStore,多平台对话与 Profile 相互隔离。
5.2.9 研究与训练:Atropos / Trajectory / Tinker
Hermes 把日常 Agent 跑出来的对话/工具调用直接当成 RL 训练数据:
-
batch_runner.py跑大量 prompt,输出 ShareGPT/Trajectory; -
environments/里实现了若干 Atropos 兼容的 RL 环境; -
trajectory_compressor.py提供轨迹压缩,便于训练; -
tinker-atropos、mini_swe_runner.py等脚手架让研究者能直接基于 Hermes 训练新一代工具调用模型。
这对绝大多数最终用户不可见,但对模型团队/学术机构非常有价值。
5.3 多样化后端层(Backends)
后端层提供工具执行环境、安全隔离与存储扩展能力。
5.3.1 工具运行时
工具系统由三层组成:
-
Registry( tools/registry.py):集中注册全部工具,每个工具是一个 Python 函数 + JSON Schema; -
Toolsets( toolsets.py):把工具按用途分组(web、terminal、file、browser、memory、delegation 等共 52 组);同时维护平台预设(hermes-cli、hermes-telegram、hermes-discord、hermes-wecom等),定义“在某平台默认开哪些组”; -
Dispatch( model_tools.py):每次推理前收集当前启用的工具 schema 作为可用工具列表,模型返回tool_calls后调度执行。
工具执行支持:
-
并发( tool_concurrency); -
审批回调(approval):危险命令(如 rm -rf /、改/etc)会触发tools/approval.py的检测。CLI 用户会看到一个“是否允许”的 prompt;Gateway 用户可以接到 DM 配对授权流程。
5.3.2 终端工具后端(7 种)
|
|
|
|
|---|---|---|
local |
|
|
docker |
|
|
ssh |
|
|
daytona |
|
|
modal |
|
|
singularity |
|
|
tmux* |
|
|
切换后端,例如切换到 Docker,只需 hermes config set terminal.backend docker 一条命令。
5.3.3 安全与隔离
Hermes 默认具备多种安全机制,将“安全”作为一等公民设计。这些机制覆盖了命令执行、运行环境、消息通道和凭证管理四个维度。
1. 危险命令检测
-
实现: tools/approval.py内置正则与模式集,识别rm -rf /、chmod 777、mkfs等高风险命令。 -
行为:当 Agent 试图执行匹配的命令时,Hermes 会暂停并要求用户确认(CLI 弹出 [y/N]提示;Gateway 则通过 DM 向用户发送审批请求)。 -
自定义:用户可在 ~/.hermes/config.yaml中配置白名单(允许某些命令绕过审批)或添加额外的黑名单规则。
2. 容器隔离(Container Isolation)
-
默认行为:当使用 docker后端时,Hermes 自动创建用户级容器,非特权模式运行。 -
高级配置:支持启用 --read-only(文件系统只读)、--cap-drop=ALL(移除所有 Linux Capabilities)等安全选项,将容器权限压缩到最小。 -
效果:即使 Agent 在容器内执行恶意代码,也无法影响宿主机或其他容器。
3. DM Pairing(私聊配对授权)
-
问题:如果将 Hermes 接入 Telegram、企业微信等 IM 平台,任何人都可以向你的 Bot 发送消息,可能被滥用。 -
解决方案:所有 IM 平台适配器默认拒绝未授权 DM。用户必须先在网关侧完成配对(例如发送 /pair命令 + 一次性 token),才能与 Agent 对话。 -
效果:只有你授权的人(或群组)才能使用 Agent,避免公开 Bot 被恶意利用。
4. 凭证文件透传(Credential Files)
-
问题:Agent 经常需要访问 API Key、SSH 私钥等敏感信息。若直接放入环境变量或命令参数,可能被泄露(例如通过 ps查看进程列表,或通过工具输出暴露)。 -
解决方案: tools/credential_files.py将这些凭证写入临时文件(权限600),然后将文件路径传递给沙箱内的命令,而非直接传递内容。 -
效果:凭证不会出现在命令行参数或日志中,且仅在需要的进程生命周期内存在。
详细的安全配置、威胁模型和最佳实践,请参考官方文档 user-guide/security.md。
5.3.4 关键概念词典
|
|
|
|
|---|---|---|
|
|
|
run_agent.py
|
|
|
|
|
|
|
|
chat_completions
codex_responses / anthropic_messages |
|
|
|
|
|
|
|
SKILL.md) |
|
|
|
MEMORY.md
USER.md |
|
|
|
|
|
|
|
local
docker / ssh / modal 等 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6 争议与挑战
前面我们介绍了 Hermes Agent 的很多优势,但它也存在一些争议和挑战。
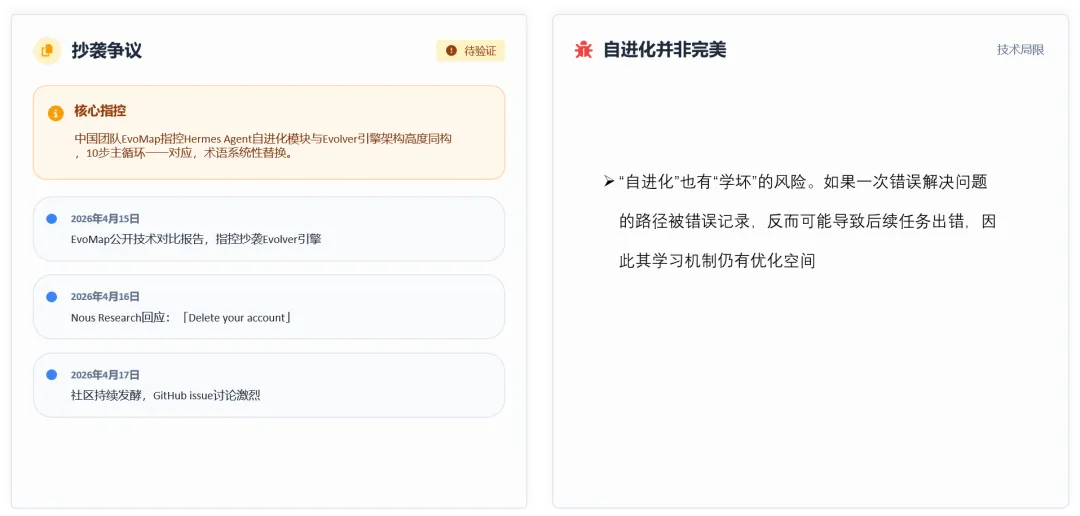
比如在今年 4 月中旬,中国团队 EvoMap指控 Hermes Agent 的自进化模块与 Evolver 引擎架构高度相似,认为两者在 10 步主循环上存在一一对应关系,只是做了术语替换。
另外,从技术角度看,自进化本身也存在“学坏”的风险。如果系统把一次错误的解决路径误判成有效经验,并记录下来,那么后面遇到类似任务时,就可能被这条错误经验带偏,反而让结果变差。
7 参考文献
6 争议与挑战
前面我们介绍了 Hermes Agent 的很多优势,但它也存在一些争议和挑战。
比如在今年 4 月中旬,中国团队 EvoMap指控 Hermes Agent 的自进化模块与 Evolver 引擎架构高度相似,认为两者在 10 步主循环上存在一一对应关系,只是做了术语替换。
另外,从技术角度看,自进化本身也存在“学坏”的风险。如果系统把一次错误的解决路径误判成有效经验,并记录下来,那么后面遇到类似任务时,就可能被这条错误经验带偏,反而让结果变差。