 夜雨聆风
夜雨聆风





为什么 OpenClaw 能"懂"你:LLM 底层原理的硬核拆解
AI Agent 深潜系列|第 1 篇
为什么 OpenClaw 能”懂”你:LLM 底层原理的硬核拆解
从概率计算到注意力机制,一位工程师的 LLM 认知重构
核心洞察
LLM 从来不认识中文字,从来不懂什么叫”文件夹”,它只是在算概率。搞懂 Token、自回归、Attention 这三个概念,你就拿到了理解 LLM 的钥匙。
引子
为什么”懂”要加引号
你在 OpenClaw 输入一行字:”帮我把下载文件夹按文件类型分类”。然后它真的开始动了——读取目录、识别后缀、创建文件夹、移动文件。一气呵成,仿佛它真的”懂”了你的意思。
但我要告诉你一个让很多工程师愣住的事实:LLM 从来不认识中文字,从来不懂什么叫”文件夹”,它只是在算概率。
这不是修辞,是字面意思。当你按下回车的那一刻,模型内部发生的事,可以被精确地描述为:在给定前文的条件下,计算下一个 token 出现的概率分布,然后”掷骰子”决定输出什么。
这句话里埋了三个核心概念:Token(词元)、概率分布(概率的质量分布在所有可能输出上)、自回归(用过去的输出影响未来的输入)。搞懂这三个东西,你就拿到了理解 LLM 的钥匙。
01.
Token:LLM 不认识字,只认识 Token
什么是 Token
当你输入”帮我把下载文件夹按类型分类”时,模型收到的不是这段中文,而是一串数字 ID。每个 ID 对应一个 Token——它是模型处理信息的最小单位,但这个”最小单位”既不是字,也不是词。
主流 LLM 使用 BPE(Byte Pair Encoding,字节对编码) 或其变体进行分词。核心思想是:用频率统计把常见字符组合”粘”在一起,形成新的 token。
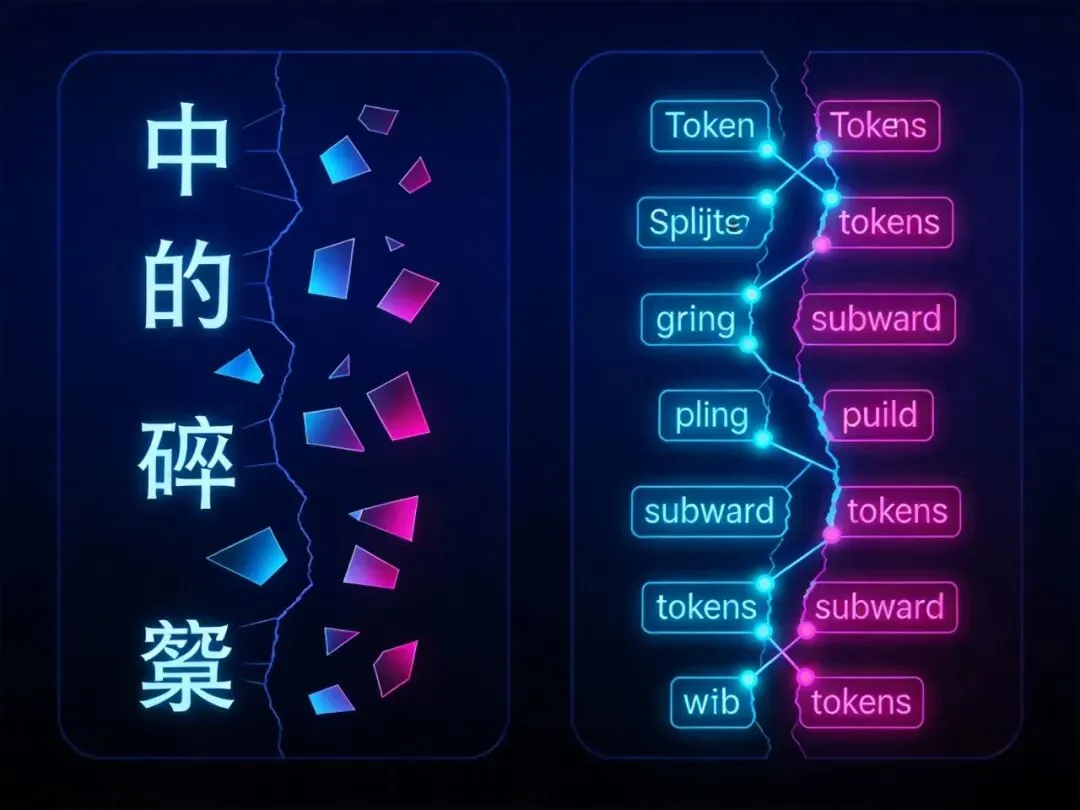
中文 vs 英文 Token 切分对比
举个简单的伪代码演示:
# BPE 分词简化演示 def bpe_tokenize(text, vocab): # 输入: "LLM真的很强" + 词表 # 输出: ["LLM", "真的", "很", "强"] tokens = [] while text: # 贪婪匹配最长前缀 for end in range(len(text), 0, -1): if text[:end] in vocab: tokens.append(text[:end]) text = text[end:] break return tokens这段代码揭示了 BPE 的本质:它不是按语义切分,是按统计共现频率切分。所以 “LLM” 可能是一个 token(因为它是英文常见缩写),而”真的”可能被切成”真””的”两个 token——完全取决于训练语料中的分布。
中文 vs 英文:2-3 倍的 Token 成本
这是 IC 工程师必须知道的一个工程事实:中文比英文费 token。
4:1
“大语言模型” vs “LLM”
3:1
“人工智能” vs “AI”
2.3:1
“帮我整理文件夹” vs “organize my files”
原因很直接:英文单词在 BPE 训练中容易被合并成 subword(子词),常见词根、前缀、后缀形成固定 token。而中文是方块字,每个字单独成 unicode,再被 BPE 合并时效率更低。
工程启示:在构建 Agent 系统时,路径命名尽量用英文或缩写;批量工具调用时合并请求,减少交互轮次;对于长任务,考虑使用支持更长上下文窗口的模型(如 Claude Opus 4.8 的 1M token)。
02.
自回归:用过去预测未来的工程意义
概率分布的物理含义
当你向 LLM 提问时,它不是在”检索答案”,而是在采样下一个 token。
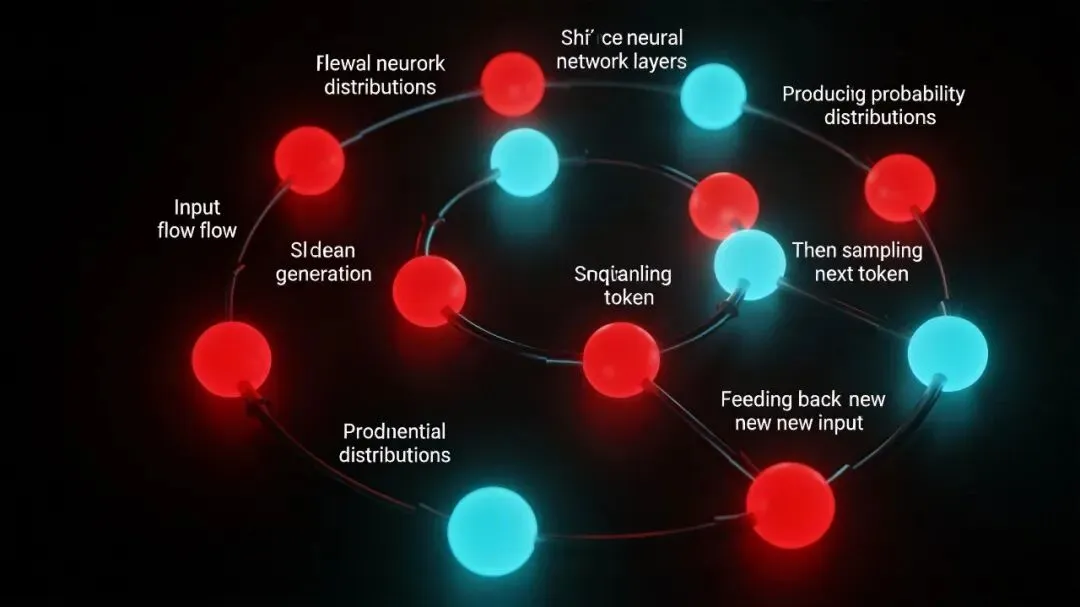
自回归生成过程示意
具体过程是这样的:
-
输入被编码为 token 序列:[T1, T2, T3, …] -
模型计算:P(T_next | T1, T2, T3, …) -
这是一个概率分布——模型给每个可能的下一个 token 分配一个概率 -
模型”掷骰子”,根据概率分布抽样出实际的输出 token -
这个输出 token 被加入序列,然后回到步骤 2
“掷骰子”是字面意思,不是比喻。即使你两次问完全相同的问题,模型也可能给出不同的答案——因为概率分布是确定的,但采样是随机的。
采样参数:Temperature / Top-p / Top-k
这三个参数是 Agent 开发者必须掌握的”旋钮”:
Temperature(温度)
T=0:完全贪婪,只选最高概率(危险陷阱)T=1:保持原始分布T>1:分布变平,输出更随机
Top-p(核采样)
从概率最高的 token 开始累加,直到总概率超过 p(通常是 0.9-0.95)。比 Top-k 更自适应
Top-k
直接限制为概率最高的 k 个 token。简单粗暴,但不够灵活
def sample_token(logits, temperature=1.0, top_p=0.95): if temperature == 0: return argmax(logits) # 贪婪选择 logits = logits / temperature # 温度缩放 probs = softmax(logits) # softmax 得到概率分布 # Top-p 过滤 sorted_indices = argsort(probs, descending=True) cumsum = 0 for i, idx in enumerate(sorted_indices): cumsum += probs[idx] if cumsum > top_p: probs = mask_below(probs, i) break return random_choice(range(len(probs)), p=probs)陷阱:Temperature=0 反而更危险
很多开发者以为 T=0 是”最安全”的设置——输出最确定、最稳定。错了。
T=0 等价于贪婪选择(Greedy Decoding),它会总是选择概率最高的 token。这导致两个问题:
- 陷入重复循环
:当模型对某个 token 的概率远高于其他时,会反复选择同一个 token - 幻觉加剧
:模型对”正确答案”的概率可能只比”错误答案”高一点点,T=0 强制选最高概率,系统性选择错误答案而不自知
Agent 开发建议
对于需要稳定输出的任务(如代码生成),用 T=0.3~0.5;对于需要创意或探索的任务,用 T=0.7~1.0;永远不要用 T=0。
为什么 LLM 会”编”(幻觉)的概率论解释
LLM 生成内容时,每个 token 都是独立采样的。这意味着:
100 个 token 全正确的概率
0.8100 ≈ 0.00002%
这就是幻觉的数学根源:错误会累积,而且几乎必然累积。所以,Agent 系统必须引入外部验证机制(如代码执行、搜索确认),而不是让 LLM 无限自洽地”编下去”。
03.
Attention:上下文窗口的硬约束
Attention 的简化直觉:会议主持人
想象你在主持一个会议,需要记住每个人说了什么,然后在做决定时”加权”考虑相关发言。
这就是 Attention(注意力机制)的本质:
- Query(Q)
:当前要生成的 token(当前议题) - Key(K)
:每个历史 token 的”摘要”(发言要点) - Value(V)
:每个历史 token 的”内容”(发言全文)
计算过程:Q 和每个 K 做点积得到”相关度分数”,softmax 归一化得到注意力权重(0~1,相加=1),最后用权重对 V 加权求和。

Attention 矩阵热力图(亮色=高注意力)
一句话概括:Attention = 关键词加权和
为什么不是 RNN:技术党爱看的演进逻辑
在 Attention 出现之前,RNN(循环神经网络)是处理序列数据的主流方案。RNN 被淘汰的原因,本质上是工程上的失败。
RNN 的致命问题:长距离依赖。当 Token3 需要参考 Token1 的信息时,信号必须经过 Token2 的”中转”。这个过程中:
-
梯度会指数级衰减(vanishing gradient)→ 模型忘记远处的信息 -
计算必须串行 → 无法并行,GPU 利用率低
Attention 的解决方案:直接计算任意两个 token 之间的关系,跳过了”中转”。这就是为什么 2017 年的论文”Attention Is All You Need”(Transformer 架构)成为转折点。
O(n²) 复杂度:窗口扩展的工程天花板
标准 Attention 的复杂度是 O(n²)——序列长度的平方。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这就是为什么扩展上下文窗口不是简单的”数字增加”:它需要算法优化(FlashAttention 将显存降到 O(n))、硬件升级(多卡并行)、以及模型架构创新(如 DeepSeek V4 的稀疏注意力)。
从 4K 到 1M:扩的是”窗口”还是”能力”?
2024 年主流模型的上下文窗口是 4K-32K,2026 年顶级模型已经标称 1M。但窗口大小不等于理解能力。
GPT-5.5接近 100%(头尾)/ ~85%(中间)
Claude Opus 4.8~95%(全范围)
Qwen3.6-Plus~99.5%(500K 内)
核心结论:扩大窗口是必要的,但不代表模型能高效利用整个窗口。中间位置的信息容易”被忽略”,这是 Transformer 架构的固有问题。
Cursor / Devin / OpenClaw 在长上下文上的工程取舍
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
04.
KV Cache:长对话为什么越来越贵
KV Cache 的工作原理:空间换时间
当你和 LLM 进行多轮对话时,每一轮都需要重新计算所有历史 token 的 Attention——这是巨大的浪费。
KV Cache 的思路是:把已经计算过的 Key 和 Value 缓存起来,只计算新 token 的 K/V,然后拼接到缓存上。
# 无 KV Cache(每轮都重算) output = attention(Q, [K_all], [V_all]) # 有 KV Cache(增量计算) cache_K, cache_V = load_cache() K_new, V_new = compute_kv(new_token) K_all = concat(cache_K, K_new) V_all = concat(cache_V, V_new) output = attention(Q, K_all, V_all)这本质上是用内存空间换计算时间——典型的工程妥协。

Token 累积消耗曲线
自己怎么估算 Agent 成本:迷你公式
总成本 = 输入 Token 数 × 输入单价 + 输出 Token 数 × 输出单价
以 OpenClaw 调用 GPT-5.5 为例,假设一个 100 轮对话的 Agent 任务:
每轮平均输入500 tokens
每轮平均输出200 tokens
100轮总成本(GPT-5.5)$4.9
100轮总成本(Claude Opus 4.8)$0.75
价格杀手锏:DeepSeek V4 Pro
1 元 / 百万 tokens ≈ $0.14 / 1M。比 Claude Opus 便宜约 3500 倍。这就是为什么在 OpenRouter 上,中国模型已经占据了 60%+ 的流量。
vLLM / PagedAttention:把吞吐量拉 10 倍
工业级推理框架 vLLM 通过 PagedAttention 彻底改变了游戏规则:
KV Cache 利用率20-38% → 96.3%
硬件成本-75%
吞吐量提升+2200%(22倍)
技术原理:传统方案预分配连续显存,但 KV Cache 长度不可预测,导致大量碎片。PagedAttention 用操作系统的”虚拟内存分页”思想,允许非连续显存分配,将利用率提升到 96%+。
05.
回到 OpenClaw:它为什么”懂你”、也会”瞎说”
核心洞察:LLM 的”懂”是统计相关,不是真懂
当你对 OpenClaw 说”帮我把下载文件夹按类型分类”时,它”懂”了。
但这个”懂”的本质是:训练数据中,类似的输入经常对应类似的输出。模型学会了”输入 → 动作”的统计关联,而不是真正理解了”文件夹”、”分类”的语义。
这就像你教鹦鹉说”你好”,它会说,但它不懂”你好”的意思。
“瞎说”案例:跨时钟域握手逻辑
让我用一个 IC 工程师熟悉的场景来演示 LLM 的幻觉:
你让 Agent 写一个 CDC(跨时钟域)握手模块:
“帮我写一个异步 FIFO 的握手逻辑,跨时钟域,同步信号”
Agent 可能输出的代码:
// 危险:这是 LLM”编”的典型 CDC 代码 reg [1:0] req_sync; reg [1:0] ack_sync; // 问题:只同步了 2 拍,可能不够 // LLM 没有意识到这个设计在高速时钟下会失效
真正的 CDC 设计需要:至少 2-3 级握手同步(取决于时钟比率)、MTBF 计算、可能的 Gray Code 编码。
LLM 不知道你设计的是 1GHz 跨到 100MHz,它只是根据”见过的类似代码”生成输出——但训练数据中 1GHz CDC 案例极少。
Agent 在 LLM 之上做”工程补偿”的三种手段
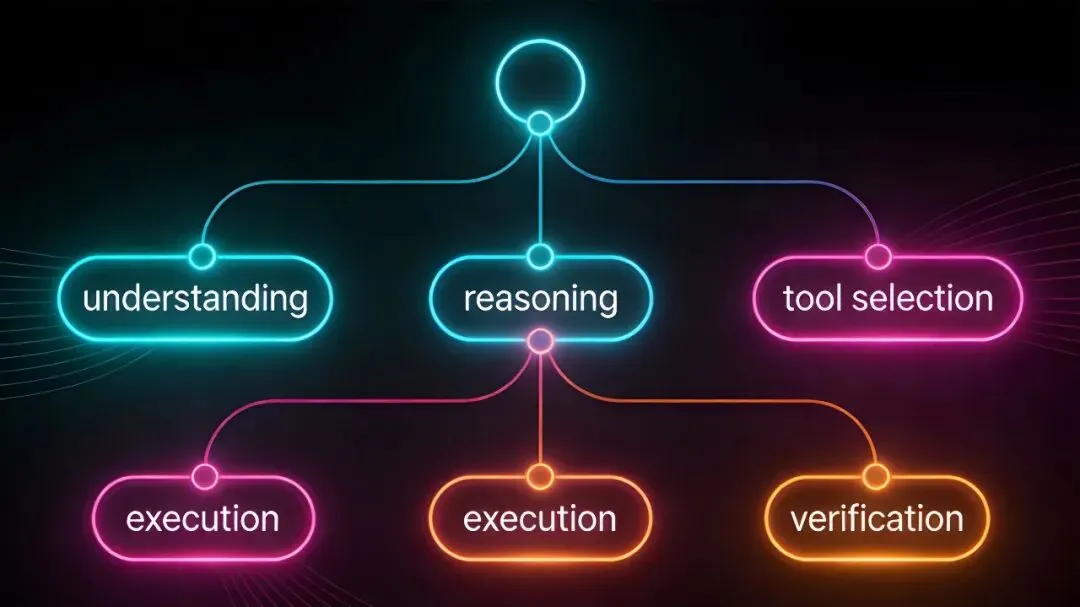
OpenClaw 决策链路全景图
OpenClaw 能相对可靠地工作,靠的不是更强的 LLM,而是工程补偿层:
- 手段一:工具调用验证
LLM 输出 → Agent 拦截检查 → 执行前确认 → 执行后验证 - 手段二:多 Agent 交叉验证
主 Agent 生成代码 → 评审 Agent 检查 → 问题则重新生成 - 手段三:外部知识检索(RAG)
用户问题涉及 CDC → 检索内部知识库/IC 设计手册 → 将检索结果注入上下文 → 基于真实参考资料生成
收尾
回到开头的问题
OpenClaw 为什么能”懂”你?
答案已经揭晓:它没有真正的理解,它只是在做极其复杂的概率计算。Token 是它的信息原子,Attention 是它的关联引擎,概率分布是它的决策机制,KV Cache 是它的记忆形式。
这套机制让它在很多任务上表现出”智能”,但也让它必然面临幻觉、长上下文成本、采样不稳定等问题。
下一篇预告
《OpenClaw 是怎么接管你电脑的:ReAct、Function Call、MCP 三大协议》
我们将拆解 Agent 如何从”能说话”进化到”能动手”
附录:关键参数速查(2026年5月)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关注「芯智说」| AI Agent 深潜系列 v2.1 | 第 1 篇
数据来源:2026年5月最新搜索核实 | 见 data_check.md