 夜雨聆风
夜雨聆风





开源 Agent 怎么搭?拆 OpenClaw 和 Hermes 之后我又改了一遍我的 Datus
一个十年数仓老兵正在复刻 Datus-Agent。把 OpenClaw 和 Hermes 两个开源 agent 的底层架构拆开看完,再回头看自己写的 NL2SQL agent,发现该补的洞还不少。
阅读提示
这一篇帮你搞清:两个明星开源 agent 的内核到底长什么样、各自在哪里下了重注 这一篇能让你直接动手:把它们的设计思想往自己的 agent 项目里搬,不只是抄代码 这一篇能让你带走一个判断:通用个人助理 / 自学习 agent / 垂直行业 agent 是三条不同的路,别混着抄
我为什么去拆这两个项目
我现在做的事是用 LangChain + LangGraph 复刻 Datus-Agent —— 一个企业内部用的 NL2SQL 数据分析 agent。Day 10 刚把 SQL 执行 + 反思循环节点跑通,本来打算继续往下推输出节点。
但我卡在一个问题上:我的反思循环是不是只是 SQL 失败重试?真正”会自己长出能力”的 agent,架构上和我有什么本质不同?
带着这个问题,我去读了两个东西:
-
OpenClaw( openclaw/openclaw):一个 TypeScript 写的个人 AI 助理框架,22+ 通道适配器,Gateway 控制面 + 单 agent 内核 -
Hermes Agent( NousResearch/hermes-agent):Nous Research 出品的”会成长的 agent”,Python 写的,强调自学习闭环
读完一圈,我对自己项目的判断更清楚了。这篇就是把读架构的笔记整理出来,顺便和我自己正在写的 Datus 做一次三方对照。
第一个:OpenClaw —— 个人助理的”控制面 / 数据面”分离
一句话定位
OpenClaw 把自己叫做 personal AI assistant —— 跑在你自己设备上的、单用户的、随时在线的 AI 助理。它要解决的问题不是”agent 怎么思考”,而是:怎么让一个 agent 同时驻守在 22 个 IM 通道里,还能跑在 macOS 菜单栏、iOS、Android 各种设备上。
支持的通道一长串:WhatsApp / Telegram / Slack / Discord / Signal / iMessage / Feishu / WeChat / QQ / IRC / Matrix ……几乎你能想到的都有。
架构图
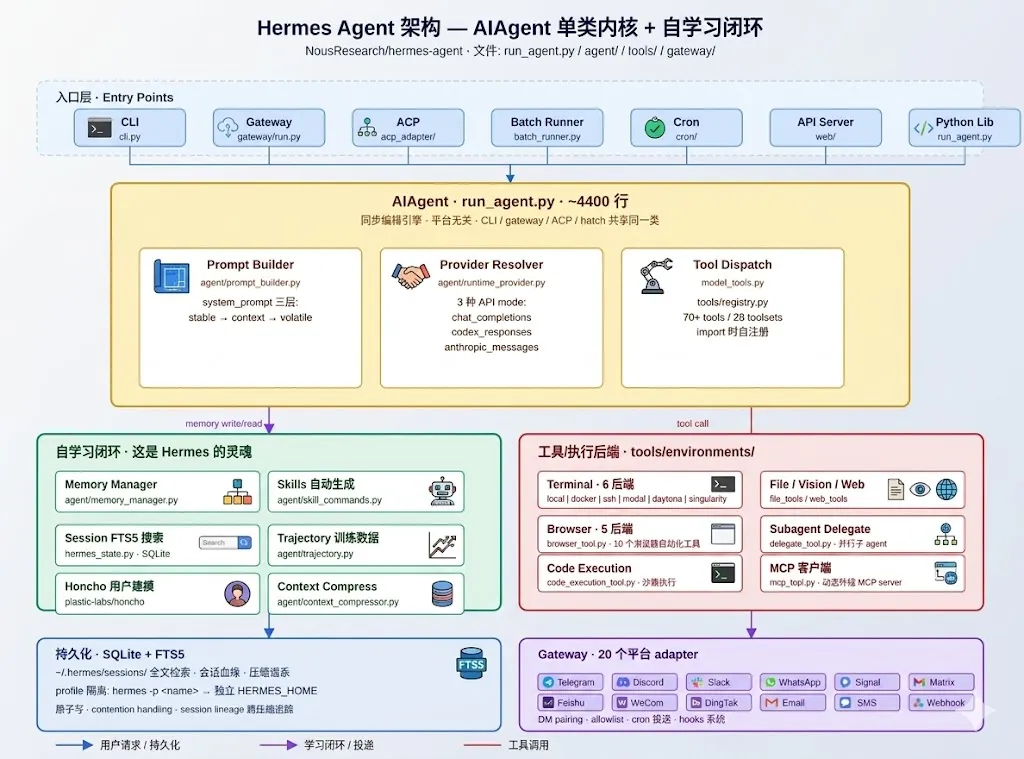
图 1|OpenClaw 架构 — Gateway 控制平面 + 单 Agent 内核
四层从上往下:
-
通道层( channels/*):22+ 个适配器,每个对接一种 IM -
Gateway 守护进程:单进程,绑 127.0.0.1:18789,WebSocket 是它的核心协议 -
Agent Runtime + Skills:workspace 目录注入 6 个 bootstrap 文件 -
Nodes 层:macOS/iOS/Android 设备作为远程客户端连回 Gateway
它的核心设计选择
1. Gateway 是控制面,不是 agent
这是我读完最大的一个收获。OpenClaw 的官方文档里写得很直白:
“The Gateway is just the control plane — the product is the assistant.”
Gateway 只做一件事:统一所有 IM 通道、设备节点、控制台 UI 的接入。它不思考,不调 LLM,不执行工具。它只负责:
-
维护 WebSocket 长连接 -
用 JSON Schema 校验所有入站消息 -
推送事件给订阅者(agent / chat / presence / heartbeat) -
做 device pairing(首次配对 → 颁发 device token)
这种控制面 / 数据面分离的思路,和数据库圈做 proxy 的套路一模一样。我做了十年数仓,太熟悉这种分层了 —— 把”协议适配 / 鉴权 / 路由”和”业务逻辑”撕开,对手运维、对扩展通道都更友好。
2. 单 agent / 单 workspace
这点和 Hermes、和我自己的 Datus 都不一样:一个 Gateway 进程内只有一个 agent runtime,一个 workspace 目录。
~/.openclaw/workspace/
├── AGENTS.md # 操作指令 + 记忆
├── SOUL.md # 人格 / 边界 / 语气
├── TOOLS.md # 工具使用习惯
├── BOOTSTRAP.md # 一次性首启仪式(用完删除)
├── IDENTITY.md # agent 名字 / 表情符号
└── USER.md # 用户画像 / 称呼偏好
新会话第一轮,OpenClaw 把这 6 个文件的内容拼到 system prompt 的 Project Context 里。这是它”记忆”的物理形式 —— 文件就是记忆,不搞向量数据库,不搞 SQLite 表。
这个选择是有取舍的:好处是简单透明可手编,坏处是没法做语义检索,记忆量大了 prompt 就爆。但作为”个人助理”这个产品定位,它对的是单个用户的轻量长期使用,不需要存几万条历史。
3. Multi-agent routing 不是多 agent,是多路由
OpenClaw 也支持 multi-agent,但语义和你想象的不一样 —— 它指的是:把不同通道 / 账号 / 联系人路由到不同的 agent(每个 agent 是独立 workspace + session)。
例:你可以让 Slack 工作群里的 agent 用一个 workspace(专业、严肃),让 WhatsApp 家人群的 agent 用另一个 workspace(轻松、家长里短)。它们彼此隔离,没有跨 agent 协作。
这和 Hermes / Datus 那种”一个 agent 委派给子 agent”是两件事。OpenClaw 的多 agent 更像是”多个独立 instance”,不是”协作团队”。
4. Sandbox 默认开放,非 main 才隔离
agents.defaults.sandbox.mode: "non-main"
默认情况下,main session 的工具直接在 host 上跑(毕竟是你自己的设备);非 main session(比如群聊、外部联系人触发的)才进沙箱。沙箱后端有 Docker / SSH / OpenShell 三选一,默认 deny 列表是 browser, canvas, nodes, cron, discord, gateway。
这个信任分级的设计很值得学:自己用就给最大权限,外人触发就进沙箱。比一刀切默认沙箱体验好太多。
OpenClaw 的局限
读完代码(其实主要是读文档 + README,56K commits 我没全读),有几个点我觉得不太适合搬到企业场景:
-
单 Gateway 单 host:扩展性差,多机部署需要自己解决会话同步 -
记忆全靠 Markdown 文件:缺乏结构化检索,难做权限控制 -
没有反思循环 / 多步规划:每次 LLM 调用是单轮 + tool call,复杂任务靠 prompt 工程顶
但作为”个人助理”这条赛道,它已经把工程化做到了行业头部 —— 22 个通道适配器、3 端原生 app、设备配对协议,光这套基建就够大多数团队抄半年。
第二个:Hermes Agent —— 把”自学习”前置在架构里
一句话定位
Hermes 把自己叫做 the agent that grows with you。它的核心 claim 是:
“The only agent with a built-in learning loop — it creates skills from experience, improves them during use, nudges itself to persist knowledge, searches its own past conversations, and builds a deepening model of who you are across sessions.”
翻译过来:**别的 agent 是”工具”,Hermes 想做”会成长的伙伴”**。
架构图
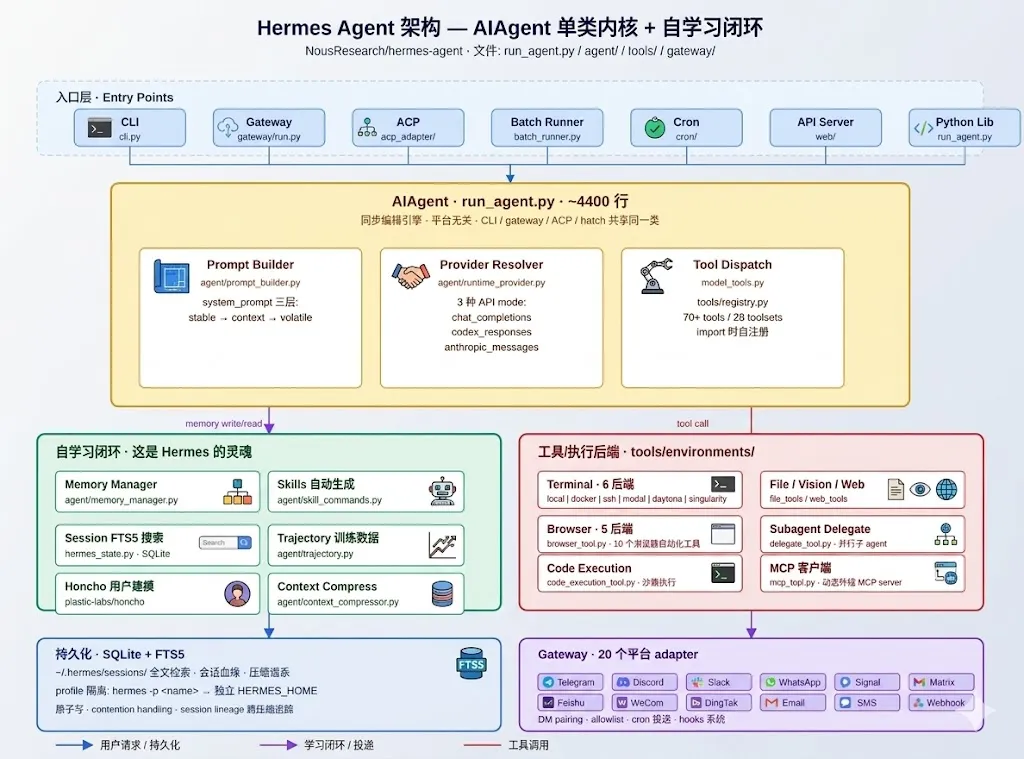
图 2|Hermes Agent 架构 — AIAgent 单类内核 + 自学习闭环
四层:
-
入口层:CLI / Gateway / ACP / Batch / Cron / API Server / Python Lib,七种入口共享同一个 AIAgent 内核 -
AIAgent 核心( run_agent.py,~4400 行):Prompt Builder + Provider Resolver + Tool Dispatch -
左边自学习闭环 + 右边工具后端:这是 Hermes 的灵魂 -
持久化(SQLite + FTS5)+ Gateway 20 个平台 adapter
Agent Loop 的细节
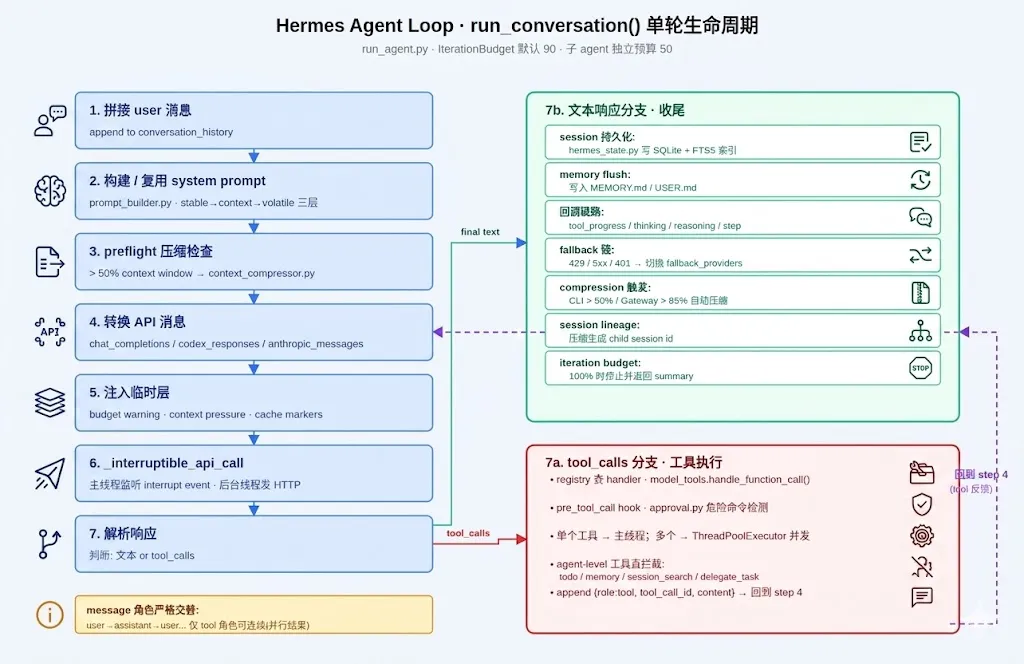
图 3|Hermes Agent Loop · run_conversation() 单轮生命周期
7 个步骤一轮:
-
拼接 user 消息到 conversation_history -
构建或复用 system prompt( prompt_builder.py三层拼接:stable → context → volatile) -
preflight 压缩检查(context 超 50% 触发) -
转换 API 消息(3 种 API mode 自适应) -
注入临时层(budget warning / cache markers) -
_interruptible_api_call(主线程监听中断 + 后台线程发 HTTP) -
解析响应: -
文本 → session 持久化 + memory flush + 返回 -
tool_calls → 执行工具 → append → 回到步骤 4
它的核心设计选择
1. 三种 API mode 一套消息格式
Hermes 内部统一用 OpenAI 风格的消息(role / content / tool_calls),但对外支持三种 API 模式:
|
|
|
|
|---|---|---|
chat_completions |
|
openai.OpenAI |
codex_responses |
|
openai.OpenAI
|
anthropic_messages |
|
anthropic.Anthropic |
模式解析顺序:构造参数 > provider 检测 > base URL 启发式 > 默认 chat_completions。
这种”内部统一格式 + 出口适配多协议”的做法,和 LiteLLM 是同一个思路,但 Hermes 是手工写的,不依赖外部库 —— 因为它要支持 18+ provider,每个的 OAuth、credential pool、alias resolution 都不一样。
2. Agent-level tools 直接拦截
这是我读到最眼前一亮的设计:有些工具不会走正常的 tools/registry.py 注册机制,而是被 run_agent.py 直接拦截:
|
|
|
|---|---|
todo |
|
memory |
|
session_search |
|
delegate_task |
|
这些工具会在不调 LLM 的情况下直接修改 agent 状态、返回合成的 tool result。这是把”agent 自我管理”的能力做成了一等公民。
我现在的 Datus 里没有这一层 —— 工具就是工具,不区分”业务工具”和”agent 自管理工具”。这是我后面要补的。
3. 自学习闭环:Skills 自动生成 + Honcho 用户建模 + FTS5 跨会话搜索
这是 Hermes 最值钱的部分,也是它”会成长”的物理实现:
-
Skills 自动生成:复杂任务完成后,agent 会自己写 skill 文件存到 skills/目录,下次类似任务直接命中 -
Memory Manager:定期 nudge agent “把这个对话里有价值的信息持久化” -
FTS5 全文搜索:所有 session 存 SQLite,建 FTS5 索引,agent 可以用 session_search工具查自己以前说过什么 -
Honcho 用户建模(接 plastic-labs/honcho):跨会话维护一个”我了解的这个用户”的模型 -
Trajectory 训练数据:把 session 导出成 ShareGPT 格式,可以直接拿去微调下一代模型
这五个东西串起来,就是一个真正的学习闭环:用 → 记 → 检索 → 形成技能 → 反哺训练。
我做数仓十年,对”数据飞轮”有本能的敏感。Hermes 这套设计本质是 agent 的数据飞轮 —— 用得越多越聪明,而且还能反哺底层模型。这不是 prompt 工程能堆出来的,必须前置在架构里。
4. 6 种终端后端
工具执行支持 6 个 backend:local / Docker / SSH / Modal / Daytona / Singularity。其中 Modal 和 Daytona 是 serverless —— agent 空闲时环境冬眠,几乎零成本,唤醒就跑。
这个对个人玩家友好,但企业场景我会更倾向 SSH + 自有 Kubernetes,可控。
三方对照
图 4|OpenClaw vs Hermes vs Datus-Agent · 三套架构对照
把三个 agent 摆在一起看,定位差别非常明显:
-
OpenClaw:通用个人助理,重通道接入和设备协议,单用户单 agent -
Hermes:自学习 agent,重记忆 / 学习 / 反思闭环,跨平台跨 IDE -
Datus(我的复刻):垂直 NL2SQL,重 SQL 质量和数据底座,企业多租户
我从这两个项目里搬了什么回 Datus
读完两个项目,我对自己 Day 10 写完的反思循环节点又有了新的判断。这是我接下来会改的几个点:
1. 控制面 / Agent 内核分离(学 OpenClaw)
我现在的 Datus,CLI / FastAPI / Web / MCP 四个入口共享 Agent 内核 —— 这点和 Hermes 一致。但我没有一个真正的 Gateway 守护进程:每个入口启动时都自己拉起 Agent。
OpenClaw 的设计更干净:一个长驻 Gateway,所有入口都连过来。这意味着:
-
session 状态在 Gateway 里统一维护,不用每个入口各自管 -
多入口并发问题(同一 session 在 CLI 和 Web 同时打开)天然解决 -
重启服务不用各家入口都重启
这个改动不小,要等 M3 里程碑再上。
2. Agent-level tools 单独建一层(学 Hermes)
我现在的工具设计是”业务工具”扁平化的:run_query / get_schema / search_metric / render_template 都在同一个 registry 里。
但其实有些工具是给 agent 自己用的:
-
update_workflow_state(让 agent 调整自己的 workflow 节点) -
search_my_history(查自己以前的 SQL) -
mark_metric_learned(把这次理解的指标标记为”已学会”)
这些工具不应该走通用 registry,应该被 WorkflowRunner 直接拦截,不消耗 LLM 一轮。这是 Hermes 的 agent-level tools 设计的核心价值。
3. 学习闭环要前置到架构里(学 Hermes)
我现在的 Datus 反思循环只有一种:SQL 跑挂了 → LLM 分析错误 → 重新生成。这是被动反思。
Hermes 的设计提示我,更值钱的是主动反思:
-
这次任务用户最后采纳了哪个 SQL?标记为”成功 case” -
用户多次问相似问题,能不能自动生成一个 reference SQL 入库? -
某个业务指标 LLM 反复理解错,能不能 nudge 自己”去更新指标定义”?
这些都需要额外的存储 + 额外的 nudge 机制前置在架构里,不能等到上线后再补。我打算在 Day 15 之后把这块加进 plan。
4. Skills 体系,但用 SQL 模板的方式实现
OpenClaw 和 Hermes 都有 skills 概念 —— 一段 Markdown 文件,描述”怎么做某事”。
我现在的 Datus 已经有类似的东西了:Jinja2 SQL 模板 + 业务指标定义。但我的模板是人工维护的,不是 agent 自动生成的。
这是我下一阶段会补的:让 agent 在反思循环里,把”成功的 SQL + 提取的参数”自动写成新的模板存到 LanceDB。这就是 Hermes “skills 自动生成” 在 NL2SQL 场景的特化版本。
边界和判断
读完两个项目,我要警惕的是:别看见好东西就照搬。
OpenClaw 的通道适配器对我没用 —— 我做的是企业内部 NL2SQL,没人会从 WhatsApp 发”帮我查一下昨天的 GMV”。
Hermes 的 Honcho 用户建模也没用 —— 企业 agent 的用户是数据分析师,他们要的不是”agent 懂我”,而是”SQL 不要错”。
值得搬的是设计思想,不是具体实现:
-
OpenClaw 教我”控制面 / 数据面要分离” -
Hermes 教我”自学习闭环要前置在架构里” -
我自己负责的是”行业落地的 SQL 质量和指标语义层”
这三个东西合起来,才是我想做的 Datus-Agent 的完整形态。
这一步之后
接下来 Day 11 我会继续按 plan 推输出节点(把 SQL 执行结果格式化为用户可读响应),但已经在 plan 里加了三个新增的子需求:
-
子需求 6.1:Gateway 守护进程(学 OpenClaw 的控制面分离) -
子需求 6.2:Agent-level tools 拦截层(学 Hermes 的 agent 自管理工具) -
子需求 6.3:自动 reference SQL 生成(学 Hermes 的 skills 自动生成)
读源码这件事不能只读不动。读完一定要回头改自己的项目,否则只是收藏夹的一次刷新。
写到这里突然想起来:我做了十年数仓,第一次觉得”读别人代码”和”维护别人 ETL”是两件完全不同的事。维护 ETL 是被动接受历史,读 agent 源码是主动选择未来。
你最近读过哪些开源 agent?哪些设计真正改变了你写代码的方式?评论区聊聊。