 夜雨聆风
夜雨聆风





Stata:如何组织实证分析文档-global-rangestat
👇 连享会 · 推文导航 | www.lianxh.cn
🍓 连享会 · 2026 AI 实证研究
嘉宾:司继春(上海对外经贸大学)
时间:2026 年 6 月 27-28 日
咨询:王老师 18903405450(微信)

连享会:2026AI-Agent专题 · 线上
时间:6月20-21日
嘉宾:李学恒 (中山大学)
咨询:王老师 18903405450(微信)

A班和B班的区别
-
解决的问题不同:A班偏向搭建AI科研协作系统,B班偏向把实证研究做扎实。
-
课程定位:A班关注AI科研工作流,包括工作台、文献与知识管理、写作系统和论文修改流程;B班关注实证研究本身,包括数据获取、代码复查、识别策略和理论建模。
-
要解决的问题:
-
A班——AI工具很多,但东一榔头西一棒槌,没有稳定系统? -
B班——数据是否可靠、Stata代码能不能信、识别策略是否站得住、机制解释是否有理论含量?
在A班把工具理顺,在B班把研究做扎实,从而让好的研究想法更高效的产出。

作者:陆心平 (中山大学)邮箱:luxp5@mail2.sysu.edu.cn
编者按:本文部分摘译自下文,特此致谢!Source:Acemoglu D, Restrepo P. Automation and new tasks: How technology displaces and reinstates labor[J]. Journal of Economic Perspectives, 2019, 33(2): 3-30. -PDF-
目录
-
1. 引言
-
2. 论文介绍
-
2.1 主要内容
-
2.2 实证分析框架
-
3. 实证分析文档结构
-
3.1 总体:以文件类型分类
-
3.2 细分:以实现过程及目的分类
-
4. 核心命令及方法介绍
-
4.1 global:全局暂元
-
4.2 rangestat:计算移动平均
-
5. 相关推文
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:

1. 引言
在实证分析中,面对来源多样的数据和繁复的处理过程,我们应该如何整理文档结构,以便未来的自己和读者能够清晰、便捷地了解实证分析过程、重现论文结果?
本篇推文将以 Acemoglu 和 Restrepo 在 2019 年发表在 JPE 上的论文 “Automation and New Tasks: How Technology Displaces and Reinstates Labor” 为例,着重分析其实证分析文档的组织特点,并简要介绍实证分析中作者用到的核心命令及研究方法,以期为我们未来的实证分析工作提供借鉴。
2. 论文介绍
2.1 主要内容
这篇文章讲述了一个什么故事呢?自工业革命以来,技术进步对于劳动力需求和生产力的影响引起了社会各界的广泛讨论,作者基于已有的研究,认为新技术不仅提高了资本和劳动力的生产力,而且还影响了这些生产因素的任务分配——我们称之为生产中的任务内容。生产任务内容的变化可能会对劳动力需求的变化和生产率产生重大影响。具体如下图所示:
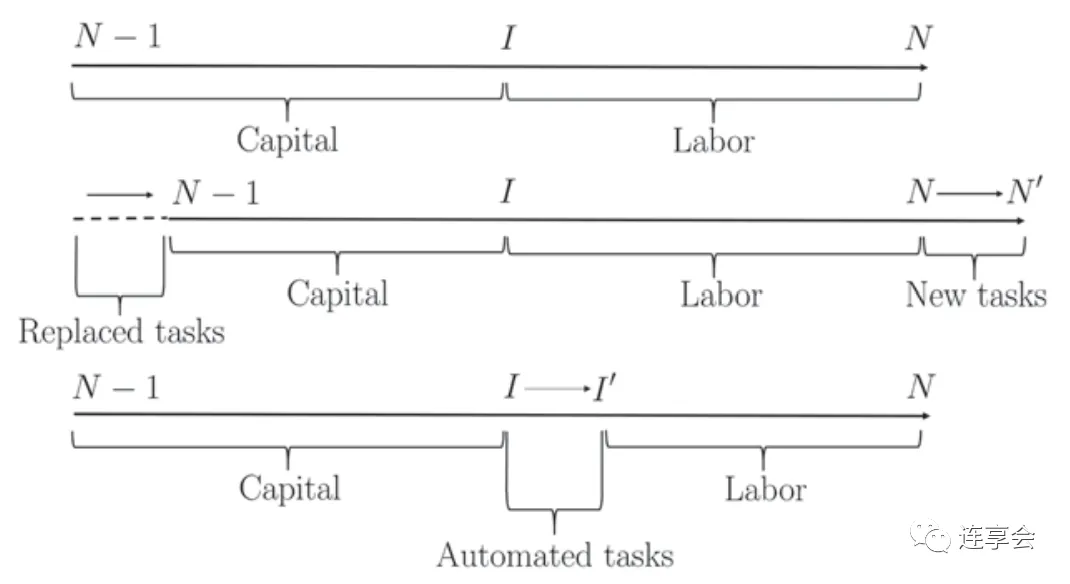
其中,生产需要完成一系列的任务,标准化到位于 N-1 和 N 之间。I 上面的任务只能通过人工生产,下面的任务是自动化的,将用资本生产。I 的增加代表了自动化技术或简称为自动化的引入。N 的增加对应于新的劳动密集型任务或简称的新任务的引入。
2.2 实证分析框架
作者从四个途径阐明了二战以来,技术进步对美国劳动力需求 (表现为美国总工资账单的变化) 的影响:
其中,各个效应的含义及在实证中的测量方法如下:
Productivity effect:是指各种技术来源对 GDP 的贡献的总和,在实证中,我们用人均 log(GDP) 的变化来测量该效应。
Composition effect:是指新技术、结构转型和偏好导致的跨部门增加值 (value-added) 的重新分配对劳动力需求的影响。举一个例子,服务业部门相对于农业部门是劳动密集型的产业,若某种技术的进步使得服务业部门在总生产中的占比更高,那么就会增加对劳动力的需求,反之会降低对劳动力的需求。在实证中,我们用劳动力份额加权的行业增值份额变化的总和来测量该效应。
Substitution effect:是指任务价格的变化导致行业中劳动密集型和资本密集型任务的相互替代。比如,随着有效工资相对于资本的有效租金率上升,劳动力产生的任务的价格相对于资本产生的任务的价格增加,就会在任务之间产生了替代效应,从而改变行业中的劳动力份额。实证中,总的替代效应是行业替代效应的就业加权之和。其中劳动力份额的表达式如下:
-
和 分别指提高资本生产力的技术和提高劳动力生产力的技术。在实证中, 的增长速度等于平均劳动生产率的增长速度,即在 1947 至 1987 年间每年增长 2%,在 1987 至 2017 年间每年增长 1.46%; -
和 分别为资本生产部门和劳动生产部门的要素价格,在实证中,数据来自经济分析局、劳工统计局、国民收入和产品账户; -
表示生产中通过劳动生产的任务的份额,反之 表示生产中通过资本生产的任务的份额; -
是任务之间替代的弹性,即用一个任务替代另一个任务的容易程度,也就是资本和劳动力之间替代的 (派生) 弹性。在在实证中,作者以 Oberfield 和 Raval’s (2014) 对资本和劳动力之间的替代弹性作为基线,即 。
Change in task content:是指行业生产内容的变化对劳动力需求的影响,总的变化可表述为各行业生产任务内容变化的就业加权之和。在实证中,作者认为只有行业中生产内容的变化和替代效应 (Substitution effect) 会影响一个行业中的劳动力份额。因此,行业生产内容的变化表现为不能用替代效应来解释的劳动力份额的剩余变化,即:
进一步地,Change in task content 可分解为:
其中,Displacement effect 是指由于新技术的开发和采用,使资本能够在一系列任务中取代劳动力,从而减少了对劳动力的需求 (如上图的第三种情形)。在实证中,作者通过计算行业任务内容负变化的五年移动平均值来测量其大小;
Reinstatement effect 是指新技术的开发和采用,引入了劳动力具有相对优势的新任务 (如上图的第二种情形),创造了新的就业机会,从而增加了对劳动力的需求。在实证中,作者通过计算行业任务内容正变化的五年移动平均值来测量其大小。
特别地,作者为 Displacement effect 和 Reinstatement effect 分别寻找了代理变量,来验证这两种效应对任务内容变化的影响。其中,Displacement effect 代理变量为:
-
行业的机器人渗透率 (Acemoglu 和 Restrepo,2018); -
1990 年从事日常重复性工作的职业在行业就业中的占比 (Acemoglu 和 Autor, 2011); -
148 个制造业 (详细分类) 中使用自动化技术的公司份额 (以就业加权)。
Reinstatement effect 代理变量为:
-
新职业 (基于 Lin (2011) 编写的 1991 Dictionary of Occupational Titles) 在 1990 年总就业中的占比; -
1990 年有大量新兴任务的职业在总就业中的占 (基于 O*NET); -
新职业 (1990 年不在该行业但在 2016 年存在的职业) 所占行业的就业增长份额; -
1990 年至 2016 年间,行业中职业数量增长的百分比。
3. 实证分析文档结构
为了运用这个框架解释美国在 1947-1987 年和 1987-2017 年劳动力需求的变化,这篇文章的实证分析过程非常复杂。其数据来源也非常多样化,如来自美国国家统计局的 GDP 和劳动力份额数据、来自美国经济分析局 (BEA) 的消费者价格指数、就业、人口等数据、来自 NBER-CES 制造业数据库的行业数据以及其它已有研究的数据等等。
然而,作者提供的实证分析文档结构非常清晰 (见下图),这一部分将着重这篇文章的实证分析文档的组织特点。
D:.└─replication_acemoglu_restrepo_jep │ .DS_Store │ readme.pdf │ ├─cleaners │ clean_bea_broad.do │ clean_bea_broad_1947_1987.do │ clean_bea_productivity.do │ clean_bls_mfp.do │ clean_census_industry_xs.do │ clean_nipa_R.do │ clean_offshoring.do │ clean_smt.do │ ├─clean_data │ apr_measure.dta │ beaio_smt.dta │ census_characteristics_BEA.dta │ census_education1990_BEA.dta │ census_education2014_BEA.dta │ census_occdiversity_BEA.dta │ china-sag_bea.dta │ china-sag_sic87dd.dta │ FH_offshoring_bea.dta │ FH_offshoring_sic87dd.dta │ panel_bea72.dta │ panel_beaNAICS.dta │ panel_budd.dta │ price_bea.dta │ qty_bea.dta │ tfp_bea.dta │ ├─dofiles │ analyze_var_jep.do │ correlates automation final.do │ correlates newtasks final.do │ correlates prices and quantities.do │ decomposition 1947-1987, alt order.do │ decomposition 1947-1987, manufacturing.do │ decomposition 1947-1987.do │ decomposition 1987-2017, alt order.do │ decomposition 1987-2017, BLS.do │ decomposition 1987-2017, manufacturing.do │ decomposition 1987-2017.do │ executer_final.do │ sectoral trends.do │ ├─figs ├─raw_data │ ├─aggregates │ │ consumer_price_pce.dta │ │ employment.dta │ │ population.dta │ │ quantities_manuf.dta │ │ rognlie_r.dta │ │ taxes_KN.dta │ │ tfp.dta │ │ │ ├─bea_klems │ │ BEA-BLS-industry-level-production-account-1987-1998.xlsx │ │ BEA-BLS-industry-level-production-account-1998-2016.xlsx │ │ │ ├─industry │ │ 1977_table_sic87_codes.dta │ │ 1982_table_sic87_codes.dta │ │ 1987_table_sic87_codes.dta │ │ 1992_table_sic87_codes.dta │ │ 1997_table_sic87_codes.dta │ │ 2002_table_sic87_codes.dta │ │ 2007_table_sic87_codes.dta │ │ FH_offshoring_naics.dta │ │ GDPbyInd_VA_1947-2017.xlsx │ │ GDPbyInd_VA_SIC.xls │ │ hrs.xlsx │ │ klemsmfpbymeasure.xlsx │ │ klemsmfpxgbymeasure.xlsx │ │ naics5811.dta │ │ nber-ces-naics-emp.dta │ │ Section3All_xls.xlsx │ │ sic5811.dta │ │ smt88.dta │ │ smt93.dta │ │ │ ├─ipums │ └─occs │ create_occ1990dd_acs.do │ new1980-wk.dta │ new2000-wk.dta │ new91-wk.dta │ occ1980_occ1990dd.dta │ occ1990dd_acs_names.dta │ occ1990_occ1990dd.dta │ occ2000_occ1990dd.dta │ occACS_occ1990dd.dta │ recode_acs.do │ subfile_ind1990dd.do │ task_changes_occ1990dd_acs_allyrs.dta │ ├─tables ├─temp_data └─xwalks consolidate_nipa.dta cw_n97_s87.dta master_xwalk.dta naics4_xwalk.dta sic72_sic87.dta sic72_xwalk.dta sic87_sic87dd.dta3.1 总体:以文件类型分类
总体上,根据文件类型,作者提供的实证分析文档有三个组成部分,分别是数据 (dta&xlsx)、程序 (dofiles) 和结果的输出 (graph & figures),这一分类方式有两个优点:
-
一是清晰明了,便于查找和调用; -
二是符合实现逻辑,即先有原始数据,再对数据进行清洗和分析,最后输出结果。
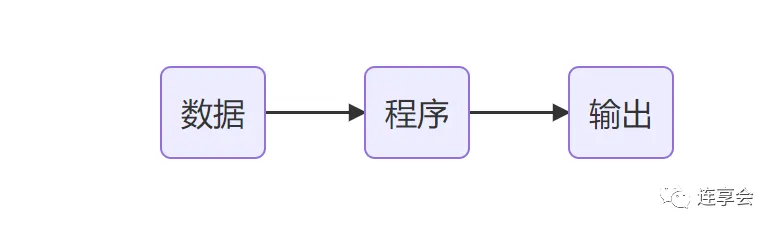
3.2 细分:以实现过程及目的分类
具体地,根据实现过程及目的,我们可以将文档进一步细分整理。例如作者将结果的输出分为 graph 和 figures 两个文件夹,分别存放输出的图表。数据和程序的细分如下:
3.2.1 数据
首先,依据数据的清洗和分析过程,我们可以将数据分为原始数据、清洗过程中创建的数据以及清洗后的数据,如作者将数据分为了 raw_data、temp_data 和 clean_data 三个文件夹。
随后,基于数据的对象和来源,我们可以进一步细分。例如如作者将原始数据分为了国家总体层面的数据、行业层面的数据以及关于职业类型的数据,并分别放入 aggregates、industry、occs 三个文件夹中。特别地,来自美国商务部经济分析局 (BEA) 和美国劳务统计局 (BLS) 的数据以及来自世界人口数据库 (IPUMS) 的数据,分别放入了 bea_klems 和 ipums 两个文件夹中。
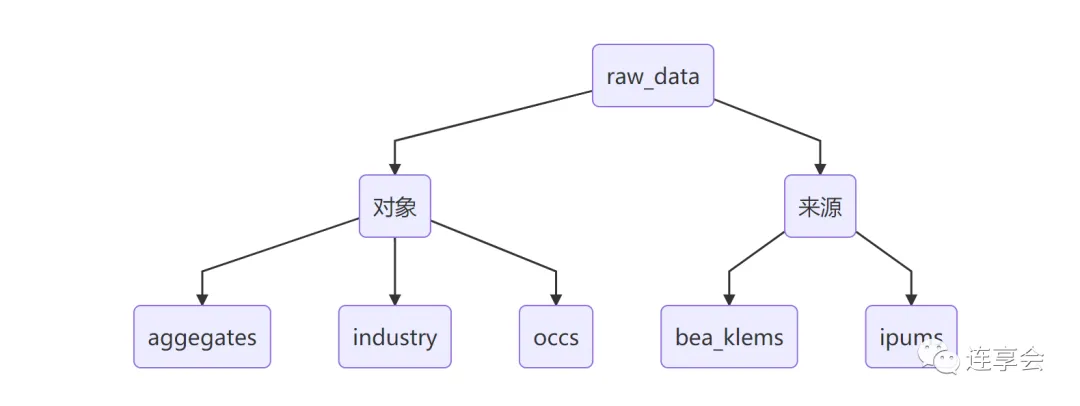
3.2.2 程序
对于程序,也就是 dofiles 文件,作者又是如何分类的呢?又有哪些值得借鉴之处?
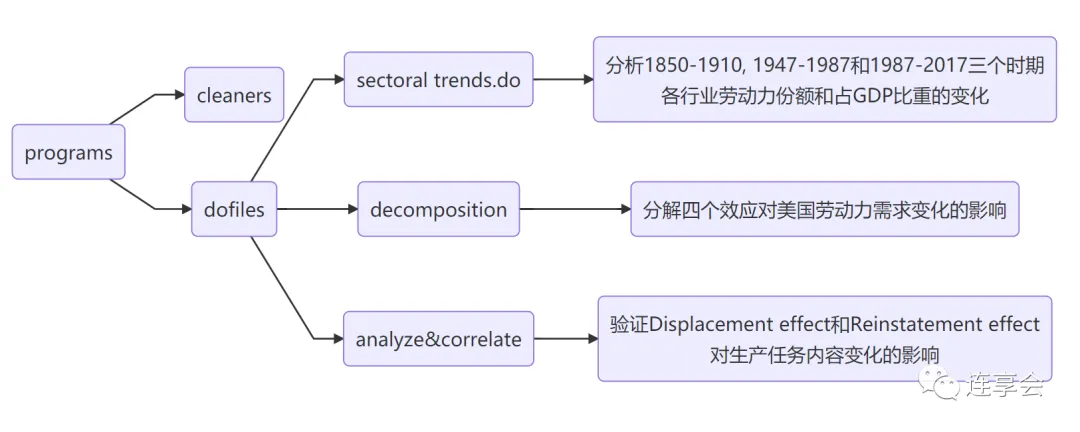
一是总体上作者依据不同的目的,将程序分为了用于数据清洗的代码和用于实证分析的代码,分别放入了 cleaners 和 dofiles 两个文件夹中。
二是我们编写程序是为了满足实证分析中的需求,对应地,作者根据程序服务的不同实证分析过程,将代码写入各自独立的 dofile 文档,并撰写了一个可以调用生成文中分析报告的所有程序的主 dofile 文档。
三是作者对于 dofile 文档的命名方式也十分值得我们学习和借鉴——多用动词+对象的方式命名。
四是作者在每一个 do 文件的开头,都清晰地写明了该程序在整个实证分析过程中的用途,便于读者和 72 小时后的自己理解和重现。以 sectoral trend.do 为例,作者在开头首先写明了文章题目、作者等信息,其后说明这个 do file 是用于输出附件中的图 A15、文中的图 2 和图 4,并在最后注明了最新的修改日期。
/*******************************************************************************"Automation and New Tasks: How Technology Changes Labor Demand"by D. Acemoglu and P. Restrepo, JEP 20192.22.2019Pascual RestrepoThis do file generates:- Figure A15 in the Appendix: Labor share and sectoral evolutions during the mechanization of agriculture: 1850 -1910- Figure 2 in the paper: Labor share and sectoral evolutions during 1947 - 1987- Figure 4 in the paper: Labor share and sectoral evolutions during 1987 - 2017(revised by G. Marcolongo on 3.27.2019 )*******************************************************************************/总之,对于程序文件的分类,我们可以从程序本身的目的出发,将其与文中分析的过程相对应,详见下图:
4. 核心命令及方法介绍
4.1 global:全局暂元
global 是作者在编写程序中用到最多的命令之一,尤其是在用于调用其它所有程序的主程序中。那么 global 究竟是何方神圣?这一小节主要介绍 global 的作用和基本语法。
4.1.1 什么是 global?
global 实际上是 Stata 中暂元 (macros) 的一种,又被称为全局暂元。而所谓暂元,我们可以将其直观地理解为用一个简单的名词来代表一系列复杂和冗长的字符或式子。
除了全局暂元 (global) 外,还有局部暂元 (local)。顾名思义,它们的区别在于局部暂元仅在定义它的 do 文件中有效,而全局暂元可以应用到不同的 do 文件当中,直至我们退出 Stata 时才会失效。
因此,当我们需要定义一个为可为多个 do 文件共同调用的暂元,就只能选用全局暂元——正如作者需要在多个 do 文件中定义 和 的增长速度。
4.1.2 global 的基本语法
设置暂元
定义全局暂元的基本语法结构为:
global name [=] value其中,name 为全局暂元的名称,value 为全局暂元存储的内容。
如果储存任意文本信息,不需要等号。例如作者将 和 的增长速度,以及绘制代表不同效应影响的直线所需的特定格式,储存在了不同的暂元中。
这种做法的好处显而易见。在重复性的工作中,运用全局暂元会更加简洁清晰,不易出错。如作者需要绘制在不同的时期、不同的行业中 Productivity effect 的折线,只需调用对应的暂元,就能保证前后格式的一致性。并且在后续程序中,如想更改 的值,只需改变暂元的定义即可,比如将 0.8 改为 0.6,对暂元所做的改变会在所有后续模型中应用。
如果储存结果,则暂元定义 global name = text (含等于号)。在此定义下,Stata 会将右侧的文本视为表达式,会先计算,再将计算结果赋给暂元。
举个例子,我们利用 Stata 自带的数据 auto.dta,生成一个新变量 gen price2=price+15,分别用 global m1=price2 和 global m2 price2 两种形式储存在暂元中,此时调用这两个暂元,输出值都是 4114。
也许你会认为,m1 和 m2 是一样的,那么我们接下来运行一下 replace price2=price-15。再次调用两个暂元,我们发现 m1 依旧是 4114,而 m2 变为了 4084。
这是由于 m2 储存的是公式 price2,而添加等号后 Stata 会在计算 price2 后,再将结果储存在暂元中。
. sysuse auto.dta. gen price2=price+15. global m1=price2. global m2 price2. dis $m14114. dis $m24114. replace price2=price-15. dis $m14114. disp $m24084调用暂元
前面的演示过程中,已经涉及了全局暂元的调用方法——$name。其中 name 是指代我们设定的暂元的名字。值得注意的一点是,如果是字符型的暂元,调用时我们需要添加双引号,否则 Stata 会报错。
. global effects productivity composition. disp $effectsproductivity not found这时候,我们只需要在调用时添加双引号,就可以纠正这一错误。
. global effects productivity composition. disp "$effects"productivity composition删除暂元
macro drop name 可用于删除特定暂元,macro drop _all 删除非系统自带的所有人为的暂元。
查看暂元
macro list 即可查看现有的暂元,我们也可以通过这个命令非常方便地查看作者定义的暂元。在所有列出的暂元中,以 s_ 的前缀开头,以及 F1、F2、F7、F8 等都是是系统自带的暂元。
4.2 rangestat:计算移动平均
上文提到,作者通过计算 Change in task content 正负变化的五年移动平均值来刻画 Displacement effect 和 Reinstatement effect 的大小。那么作者是如何通过 Stata 实现这一目的的呢?这就不得不涉及到一个关键命令 rangestat,这一部分主要介绍这一命令的基础用法。
4.2.1 什么是 rangestat?
rangestat 是 Stata 用于完成滚动计算任务的命令之一,此外还有 rolling 和 asrol。相较而言,rangestat 的一个优点在于可以灵活设置滚动窗口,而 rolling 和 asrol 分别只能向后和向前滚动。
4.2.2 rangestat 的基本语法
rangestat 的基本语法结构如下:
rangestat (stat) {varlist | new_varname=varname} [{varlist | new_varname=varname} ...] [if] [in], interval (keyvar low high) [options]其中,(stat) 是我们需要计算的统计量,它可以是:
obs 原始观察值个数 count 滚动窗口中非缺失值的个数 missing 滚动窗口中缺失值的个数 mean 非缺失值的算术平均值 sum 滚动窗口中所有值求和 sd 非缺失值的标准差 variance 方差 min 滚动窗口中的最小值 median 滚动窗口中的中间值 max 滚动窗口中的最大值 first 滚动窗口中的第一个观察值 last 滚动窗口中的最后一个观察值 firstnm 滚动窗口中第一个非缺失的观察值 lastnm 滚动窗口中最后一个非缺失的观察值interval (keyvar low high) 用于定义计算当前统计量的滚动窗口,keyvar 是一个数值变量,[low high] 是该数值变量的闭区间。如作者需要计算以当年为中心,5 年行业任务内容的平均值,则将滚动窗口设置为 interval(year -2 2)。
此外,[options] 包括:
by(varlist) 分组计算滚动统计量excludeself 剔除当前观察值casewise 按情况删除变量组内的观察值describe 列出新产生的变量的名称local(name) 为新产生的变量定义一个局部暂元在实证中,作者需要分别计算各行业任务内容变化的平均值,因此,[options] 可写为 by(incode),即按行业代码分组计算。
作者编写的完整 rangestat 命令为:
rangestat (mean) task_content_*, interval(year -2 2) by(indcode)随后,若平均值为负值,则记为是 Displacement effect 的大小;若为正值,则体现了 Reinstatement effect 的作用。
*Industry element of the Displacement effect:gen task_negative_5yr=min(task_content_i_mean, 0)*Industry element of the Reinstatement effect:gen task_positive_5yr=max(task_content_i_mean, 0)5. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh local 滚动, m安装最新版lianxh命令:ssc install lianxh, replace
-
专题:Stata教程 -
Stata编程:暂元,local!暂元,local! -
专题:数据处理 -
滚动计算:rangerun和rangestat命令简介 -
滚动吧统计量!Stata数据处理 -
专题:Stata程序 -
Stata程序:暂元-(local)-和全局暂元-(global) -
专题:回归分析 -
Stata:滚动回归的五个命令-rolling
连享会:2026暑期班 · 线上
时间:7月21-31日
嘉宾:连玉君(初级班) || 茅家铭(高级班) || 范馨月(论文班)
咨询:王老师 18903405450(微信)

🍓 连享会 · 2026 社会网络分析专题
嘉宾:杨张博 (西安交通大学)
时间:2026 年 8 月 18-19 日
咨询:王老师 18903405450(微信)

New! Stata 搜索神器:
lianxh和songblGIF 动图介绍
搜: 推文、数据分享、期刊论文、重现代码 ……
👉 安装:. ssc install lianxh. ssc install songbl
👉 使用:. lianxh DID 倍分法. songbl all

🍏 关于我们
-
连享会 ( www.lianxh.cn,推文列表) 由中山大学连玉君老师团队创办,定期分享实证分析经验。 -
直通车: 👉【百度一下:连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。
