 夜雨聆风
夜雨聆风





【OpenClaw】记忆系统:让AI不再健忘

AI 记忆、数据库与长期上下文
没有记忆的 AI,再聪明也只是临时工;能沉淀经验的助手,才配叫长期搭子。
如果你每天都要重新告诉 AI:“我是谁、你是谁、我们昨天做到哪了、这件事别再犯第二次”,那你用的就不是助手,是一个高级复读机。
真正能长期帮你干活的 AI,不能只会聊天。它必须记得偏好,记得项目背景,记得踩过的坑,也记得哪些事不该再问第二遍。
OpenClaw 的记忆系统解决的就是这个问题:让 AI 从一次性对话工具,变成一个能持续积累经验的个人助手。
1. MEMORY.md:长期记忆,不是聊天记录
很多人一听“AI 记忆”,第一反应是:把所有聊天记录都塞进去。
这思路听起来简单,实际很蠢。
聊天记录是流水账,长期记忆应该是提炼后的共识。OpenClaw 里最核心的长期记忆文件通常是 `MEMORY.md`。它不是用来存所有废话的,而是存那些未来还会影响决策的信息。
比如:
·用户叫什么,偏好什么沟通风格;
·当前长期项目是什么;
·已经确认过的命名、规则和边界;
·反复踩坑后总结出的止损策略;
·哪些事情必须先问,哪些事情可以直接做。
这和普通 session 记忆的区别很大。
session 记忆像“今天上午我们聊了什么”,窗口一换、上下文一长,就可能丢。`MEMORY.md` 更像个人助手的长期工作手册:少、准、可复用。
好的长期记忆不是越多越好,而是越能指导行动越好。
· · ·
2. memory/:每天的工作日志,先粗记,再提炼
长期记忆不能写成垃圾场,但日常工作又确实需要留痕。OpenClaw 通常会用 `memory/` 目录保存每日日志,比如 `memory/2026-06-20.md`。
这个目录更像工作日记,适合记录当天发生了什么:
·今天执行了哪个定时任务;
·生成了哪些文件;
·上传公众号时卡在哪一步;
·哪个模型超时了;
·哪个流程下次应该换方案。
它和 `MEMORY.md` 的关系很像“原始笔记”和“长期经验”。
当天的细节先写进每日日志,过几天发现某条经验反复出现,再提炼进 `MEMORY.md`。这样既不会丢事实,也不会把长期记忆撑成一坨没人想读的历史包袱。
举个例子:
某次公众号上传失败,日志里可以写:“真实 Chrome 未连接,无法复用公众号登录态,本地 docx 已保留。”
如果这类问题反复出现,再把规则提炼进长期记忆或 `AGENTS.md`:公众号后台必须使用 `profile=user`,不能降级到干净浏览器扫码。
这就是记忆系统真正有价值的地方:不是记录情绪,而是让下一次执行更稳。
· · ·
3. 语义搜索:不是翻文件,是找相关经验
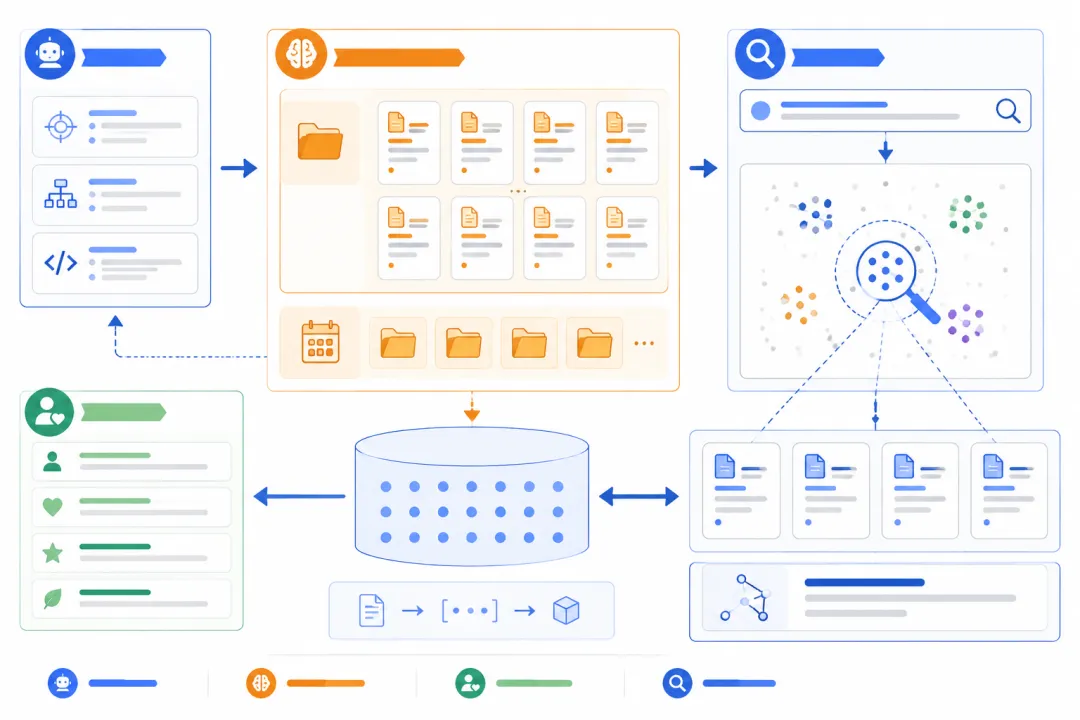
文中配图:OpenClaw 记忆系统文件结构
文件多了之后,另一个问题马上出现:记了,但找不到。
OpenClaw 的 `memory_search` 就是为这个场景准备的。它不是简单按关键词 grep,而是用语义搜索找“意思相关”的内容。
比如你问:“昨天公众号定时任务进展怎么样?”
系统不应该只搜索“昨天”两个字,而应该理解这句话和这些内容有关:
·cron 定时任务;
·公众号文章;
·某年某月某日;
·上传状态;
·本地产物;
·失败日志。
这就是语义搜索的优势:你不用精确记得文件名和措辞,助手也能把相关记忆捞出来。
但这里有个现实提醒:语义搜索依赖索引和 embedding provider。如果配置坏了,搜索就会失效。所以靠谱的工作流不能只靠搜索,还要有结构化文件命名兜底。
比如:
·文章排期放 `article_schedule.json`;
·每日日志用 `memory/YYYY-MM-DD.md`;
·生成文档用 `公众号文章_YYYY-MM-DD.docx`;
·配图统一放 `images/`。
文件组织清楚,AI 才不至于像个翻抽屉的醉汉。
· · ·
4. SOUL.md 和 IDENTITY.md:记住“怎么做人”
记忆不只是事实,也包括风格和边界。
OpenClaw 里常见的个性文件包括 `SOUL.md` 和 `IDENTITY.md`。
`IDENTITY.md` 更偏“我是谁”:名字、角色、描述、头像、面向用户的身份。
`SOUL.md` 更偏“我怎么做事”:语气、价值观、边界、遇到不确定时怎么处理。
这两个文件的意义,不是给 AI 搞玄学人设,而是让助手在不同会话里保持一致。
比如一个用户喜欢“专业但不死板,直接一点,可以嘴欠但别误事”,那就应该写进人格规则。以后无论是写文章、查进度、整理工作流,助手都应该沿着这个风格输出。
这比每次开头都说“请你用专业但轻松的语气”高效多了。
更重要的是边界。
一个个人助手会接触文件、消息、浏览器、账号登录态。没有边界的记忆系统很危险。哪些信息可以复用,哪些不能外传;哪些操作可以直接做,哪些必须先问;这些都应该写清楚。
记忆不是为了让 AI 更会自作主张,而是让它更少犯同样的错。
· · ·
5. 文件分工:别把所有东西塞进一个 Markdown
一套实用的 OpenClaw 记忆结构,大概可以这么分:
`AGENTS.md`:操作手册。写工作规范、工具使用规则、红线、项目约定。
`MEMORY.md`:长期记忆。写稳定偏好、长期项目背景、反复验证过的经验。
`memory/*.md`:每日日志。写当天发生的事、任务结果、失败原因、临时记录。
`SOUL.md`:做事风格。写助手的语气、价值观、边界感。
`IDENTITY.md`:身份信息。写名字、角色、简介、头像等元数据。
这套分工的核心是:不同生命周期的信息放到不同地方。
临时事实不要污染长期记忆;长期规则不要散落在每日日志;人格边界不要混在项目排期里。
否则时间一长,AI 不是有记忆,而是背着一座垃圾山。
· · ·
总结:记忆系统的本质,是降低重复沟通成本
OpenClaw 的记忆系统不是为了炫技,也不是为了让 AI 假装有灵魂。
它的真正价值很朴素:
让助手少问废话,多接住上下文;少重复犯错,多沉淀经验;少像一次性聊天窗口,多像一个长期合作的数字搭子。
一个没有记忆的 AI,再聪明也只是临时工。
一个有清晰记忆结构、每日日志、长期经验和行为边界的 AI,才可能真正开始替你承担长期任务。
如果你正在搭自己的 OpenClaw,不要只盯着模型多强、工具多炫。先把记忆系统整理好。
因为最后决定一个个人助手好不好用的,往往不是它第一次回答有多惊艳,而是它第十次、第百次合作时,还记不记得你们一路踩过哪些坑。
这才是“让 AI 不再健忘”的真正意义。