 夜雨聆风
夜雨聆风





A21 词嵌入 Word2Vec:让机器读懂"词义",还能做"国王 – 男人 + 女人 = 女王"
【必修· 扫盲】主干必读——看懂 AI 全貌的最短路径。
上一篇 LSTM 的代码里,藏了一个不起眼却至关重要的部件——`Embedding`,词嵌入。
它要解决一个最根本的问题:机器只认数字,不认汉字。你输入“猫”,计算机看到的得是一串数。可这串数该怎么定?随便编号吗——猫=1、狗=2、苹果=3?不行。这样一来,”猫(1)”和”狗(2)”的距离,竟然和”猫(1)”和”苹果(3)”差不多,可猫和狗明明更像。编号丢掉了“词义”。
词嵌入(Word Embedding),就是教机器把每个词变成一串“懂意思”的数字。它是现代 AI 理解语言的真正起点,也是大模型的地基。
一、它到底在解决什么问题?
一句话:把每个词表示成一个向量(一串数字),让意思相近的词,向量也相近。
不再用孤零零的编号,而是给每个词一个几百维的向量。训练之后,“猫”和”狗”的向量会离得很近(都是宠物),而”猫”和”苹果”会离得很远。词义,第一次变成了可以计算的几何距离。
二、它凭什么能学会词义?一句话道破
机器没读过字典,怎么知道“猫”和”狗”意思相近?靠一条朴素到惊人的语言学洞察:
“看一个词交什么朋友,就知道它是什么样的词。”(一个词的意思,由它周围经常出现的词决定。)
“猫”和”狗”周围,总出现”养””可爱””喂””宠物”这些词;而”苹果”周围是”吃””水果””甜”。既然它们的“邻居圈”高度重合,模型就推断它俩意思相近,于是把它们的向量学得很靠近。 Word2Vec 就是用这个思路训练的:让模型根据一个词去预测它的上下文邻居,反复训练,词向量就自然成型了。
三、最神奇的地方:词义可以做加减法
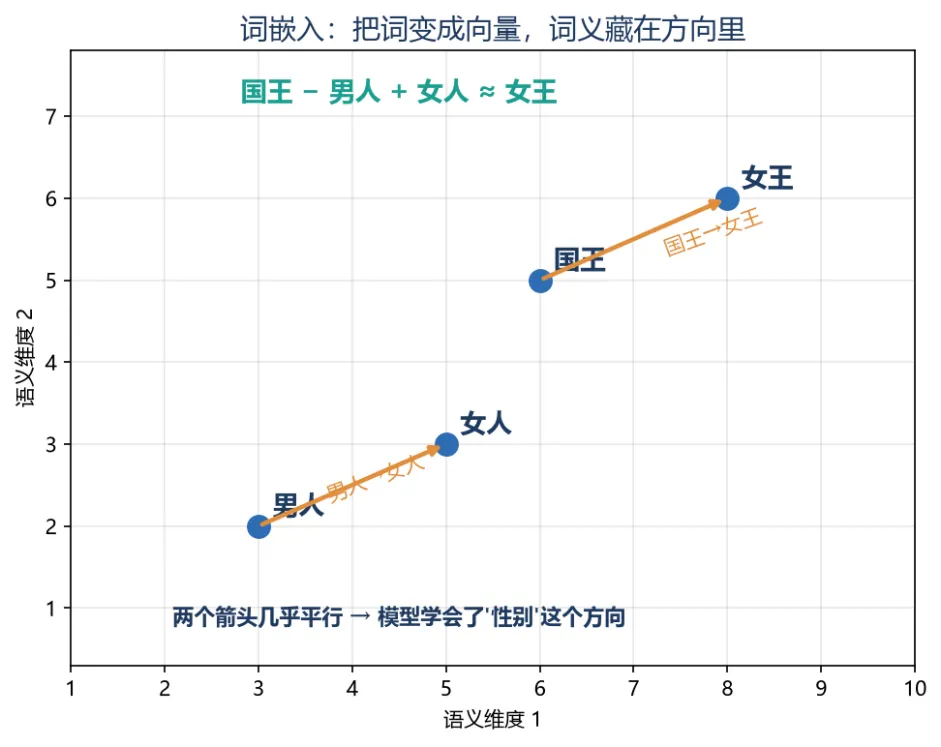
图:国王→女王 和 男人→女人 两个箭头几乎平行,模型学会了”性别”这个方向
这是词嵌入最让人拍案叫绝的特性。当词变成向量后,词与词之间的关系,变成了向量之间的方向:
向量(国王) − 向量(男人) + 向量(女人) ≈ 向量(女王)
看上图,“国王→女王”和”男人→女人”这两个箭头几乎完全平行、等长——这说明模型自己悟出了一个叫”性别”的方向!你把”国王”减去”男人”(去掉君主里的男性属性),再加上”女人”(注入女性属性),结果就精准地落在了”女王”附近。
类似地还有“北京 – 中国 + 法国 ≈ 巴黎”(首都关系)。机器并不知道什么叫国王、什么叫性别,但它从海量文本里,把这些抽象语义关系变成了精确的几何运算。这就是词嵌入的魔力。
四、核心代码
# 用 gensim 训练词向量 (pip install gensim)from gensim.models import Word2Vec# 训练语料:每句话已分好词sentences = [ [“猫“, “是“, “可爱“, “的“, “宠物“], [“狗“, “是“, “忠诚“, “的“, “宠物“], [“苹果“, “是“, “甜“, “的“, “水果“], [“香蕉“, “是“, “甜“, “的“, “水果“],]model = Word2Vec(sentences, vector_size=50, window=2, min_count=1, epochs=100)print(“‘猫‘的词向量(前5维):”, model.wv[“猫“][:5].round(3))print(“和‘猫‘最像的词:”, model.wv.most_similar(“猫“, topn=2))
跑完,`most_similar` 会告诉你和”猫”最接近的词——在足够大的语料上,它会精准地找出”狗”这类同属宠物的词。机器,就这样无师自通地学会了”词义”。
五、它能用在哪?
·一切 NLP 任务的输入第一步:分类、翻译、问答,都先把词转成向量
·搜索引擎的语义匹配(搜“手机”也能匹配到”智能机”)
·推荐系统(把商品、用户也“嵌入”成向量算相似度)
·大模型的地基:GPT 们处理你输入的每个字,第一步就是查它的嵌入向量
判断口诀:任何要让机器“理解”词、商品、用户等离散对象的场景,第一步几乎都是把它嵌入成向量。它是连接“符号”与”计算”的桥梁。
六、一句话记住它
词嵌入 = 把每个词变成一串”懂意思”的向量,意思近的词向量也近,连”国王-男人+女人≈女王”这种语义运算都能做。
它的灵魂是一句话:一个词的意思,由它的“朋友圈”决定。这是机器理解语言的真正起点。
下一篇预告:词嵌入解决了“单个词”的理解,但一个词在不同句子里意思会变(”苹果”是水果还是手机?)。要真正读懂一句话,模型得学会在读每个词时,动态地关注句子里其他相关的词。这个能力,催生了统治当今 AI 的王者架构。下一招——也是本章压轴:注意力机制与 Transformer。