 夜雨聆风
夜雨聆风





161K Star,微软出的这个工具把文档跟大模型打通了——PDF/一键喂给AI
microsoft/markitdown,单月新增 3.4 万 Star,总 Star 161K。它做的事说穿了就一句话:把 PDF、Word、PPT、Excel、音视频字幕、YouTube 链接,一键转成干净的 Markdown,直接喂给大模型。
如果你做过 RAG、搞过知识库、或者日常需要给 AI 看文档,你立刻知道这个工具解决了什么痛点。
痛点:文档是 LLM 消化不了的石块
LLM 吃的是文本。你给它一个 PDF,它需要先解析——但 PDF 的格式千奇百怪:扫描件、双层文本、表格混排、公式、图表。每一种都需要不同的处理方案。
以前的流程是这样的:PDF → 转 Word → 手工对齐 → 复制粘贴 → 删掉乱码 → 调格式 → 喂给 LLM。一篇文章折腾 10 分钟,一个文档库折腾一整天。
markitdown 把这个流程压缩成一行命令:
markitdown document.pdf输出一个干净的 Markdown 文件。表格变成 Markdown 表格,列表变成 Markdown 列表,代码块保留语法高亮标记,图片变成链接引用。不仅仅是文本提取,是语义结构保留。
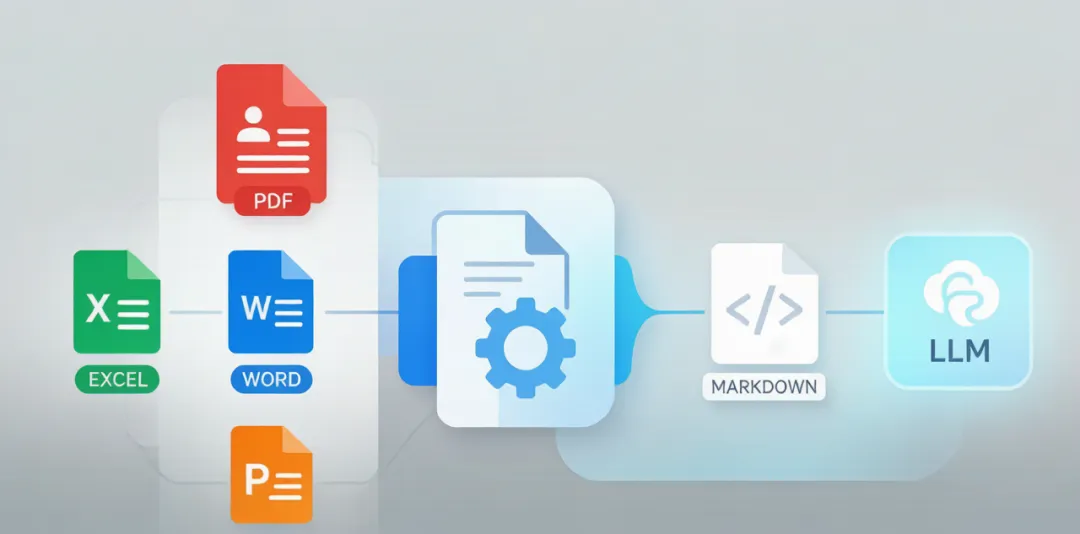
它支持什么格式
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
v0.1.6 版本新增了 Azure Document Intelligence 集成,云端高质量转换又加了一个选项。本地处理和云端处理两条路径都通了。
为什么 161K 人 Star 了这个项目
三个原因,按重要性排序:
第一,它是 LLM 应用的基础设施。 所有 RAG 应用、知识库问答、文档摘要系统,第一步都是「把文档转成 LLM 能吃的格式」。markitdown 把这第一步做到了零摩擦。不需要装七种工具、不需要配五个 API、不需要手工调试每种格式的参数——一行命令搞定。
第二,微软出品,打磨到位。 161K Star 不是靠着微软的品牌刷出来的。这个项目对中文 PDF 的支持非常好——很多开源 PDF 转 Markdown 工具对中文文字提取的准确率惨不忍睹,markitdown 的准确率明显更高。表格混排的 Word 文档转换后格式不乱,这是竞品做不到的。
第三,生态位置精准。 它不做一个大而全的产品,只专注做一件事:文档 → Markdown。这件事是 LLM 应用管道的第一个环节,也是效率损耗最大的环节。markitdown 把这个环节磨到了最薄。
三个程序员最常用的场景
场景一:技术文档喂给 AI 做代码生成。 你有一个 50 页的 API 文档 PDF,想让 AI 基于文档生成对接代码。以前你得手动把文档内容一段段复制给 AI。现在一行 markitdown api-doc.pdf,出来的 Markdown 直接复制到 Claude 里:「基于这份 API 文档生成 Python 对接代码。」整个过程从半小时压缩到一分钟。
场景二:搭建本地知识库 RAG。 你的团队有几百份 Word 文档和 PDF,想做一个内部知识库问答系统。第一步就是把所有文档转成 Markdown。markitdown 支持批量处理,一个目录扔进去全转。
场景三:音视频会议记录转文档。 录音文件 → 语音转文字 → Markdown 会议纪要。一段 YouTube 技术分享视频 → 提取字幕 → Markdown 文字稿。
markitdown 不是最 fancy 的 AI 项目,但它是你用 AI 做任何文档相关工作之前的第一步。把它装到你的工具链里,今天就省掉你 20 分钟手工排版的时间。
你平时怎么给 AI 喂文档?
👇 评论区聊聊:
-
A. 复制粘贴 + 手工排版,很痛苦 -
B. 已经在用 markitdown 之类的工具 -
C. 用 LangChain 之类框架的文档加载器 -
D. 没喂过文档,只聊天