 夜雨聆风
夜雨聆风





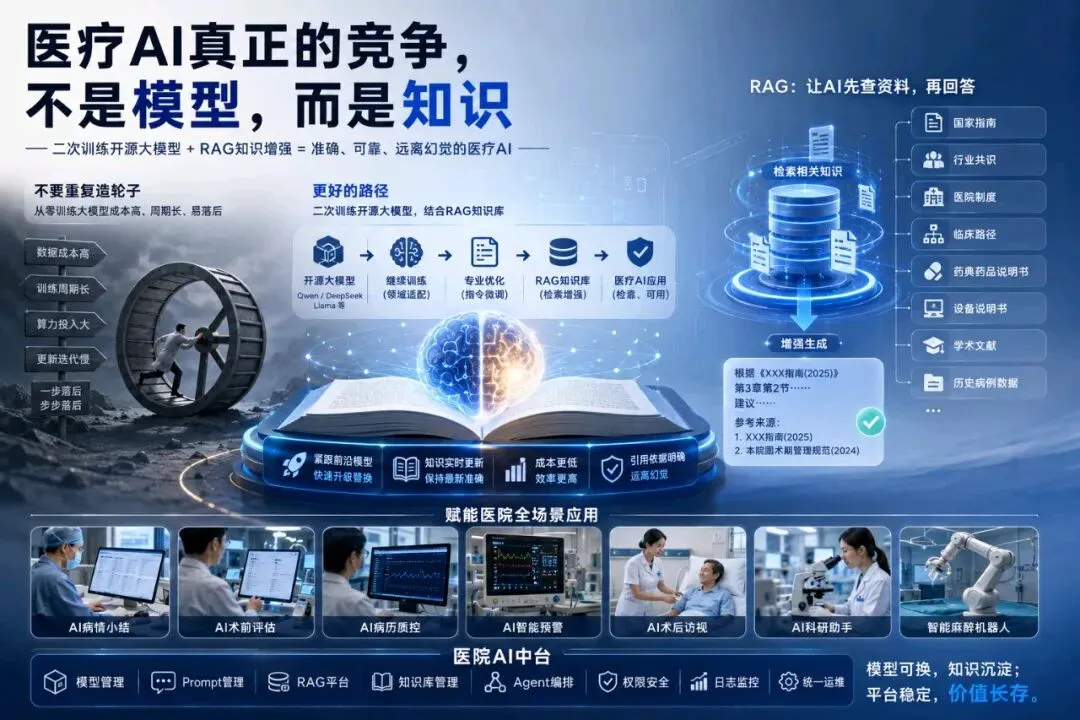
医疗AI公司真正的竞争,不是模型,而是知识,为什么医疗软件公司不必重复造一个大模型?
过去两年,AI的发展速度,远远超过了大多数人的想象。
国外的闭源模型我就不说了,仅仅国内,几乎每隔几个月,都会出现一个新的开源大模型版本。
Qwen,Kimi,DeepSeek,GLM…
还有越来越多优秀的模型不断出现。
与此同时,越来越多的软件公司开始宣传:“我们拥有自己的医疗大模型。”
刚开始,我也一直在思考。
医疗软件公司,是不是也应该训练一个属于自己的大模型?
后来,随着AI项目越做越多,我越来越觉得。
真正的问题,可能问错了。
医疗软件公司,真的需要重新训练一个大模型吗?
训练一个基础大模型,意味着什么?
海量的数据,庞大的GPU算力。
持续数月甚至更长时间的训练。
巨额投入。
而当模型终于训练完成的时候。
开源社区,很可能已经发布了下一代模型。
今天追赶Qwen,明天追赶DeepSeek。
后天,又会出现新的模型。
如果始终跟着基础模型奔跑。
很容易出现一种局面。
一步落后,步步落后。
真正值得投入的,不是模型,而是医疗知识。
我越来越觉得。
基础模型,越来越像汽车发动机。
优秀的发动机,可以买,可以买国产的,可以买开源的。
甚至未来,可能会越来越便宜。
真正决定一辆汽车价值的。
不是发动机,而是整车设计。
医疗AI也是一样,真正值钱的。
不是参数,不是模型,不是算力,而是医疗知识,是临床工作流,是医生几十年积累下来的经验。

什么才是真正的”医疗AI”?
很多人理解医疗AI,就是把一个通用模型,重新训练一遍。
其实,真正能够落地的医疗AI,远远不止如此。
它至少包括:
医疗领域继续训练,专业Prompt设计,医院知识库,RAG检索,临床工作流,权限管理,AI中台,医生审核。
最终形成一个完整的医疗AI体系。
基础模型,只是其中的一块基石,而不是全部。
RAG,为什么比重新训练模型更重要?
很多人第一次听到RAG,都会觉得这个名字很陌生。
其实它的思想非常简单:AI不要急着回答。
先查资料,再回答。
例如,今天国家发布了最新版围术期指南。
如果重新训练模型,可能需要几个月,甚至更长时间。
如果采用RAG,只需要把最新版指南加入知识库,几分钟以后,AI就能够引用最新内容回答问题。
模型没有改变,知识却已经更新,这就是RAG最大的价值。
不是让AI更聪明,而是让AI始终站在最新知识之上。

大模型决定AI有多聪明,RAG决定AI有多可靠
这是我最近最大的体会。
大模型,负责理解,负责推理,负责生成答案。
而RAG,负责寻找依据,负责引用指南,负责调用医院制度,负责调用患者病历,负责调用最新知识。
对于医疗来说,可靠,往往比聪明更加重要。
因为医生真正需要的,不是一个会聊天的AI。
而是一个能够告诉你:“我的依据是什么。”,“我的结论来自哪里。”
这样的AI,才能真正进入临床。

医疗软件公司,真正应该建设什么?
如果让我规划一家医疗软件公司的AI路线。
我不会把绝大部分资源,投入到重新训练一个基础模型。
而会重点建设:医疗知识库,RAG平台,Prompt平台,AI中台,Agent平台,临床工作流。
这些能力,不会因为底层模型升级而失效。
今天可以使用Qwen,明天可以使用DeepSeek。
未来,还可以接入新的模型。
底层模型不断更新,上层能力持续积累,这才是一条能够长期发展的道路。

医院在AI时代,真正应该承担什么角色?
医院最大的财富,其实不是GPU,也不是服务器,而是数据,是真实世界里的临床经验,是规范的数据治理,是不断完善的医疗知识。
医院更适合作为:AI应用平台,知识提供者,临床验证者,工作流设计者。
而不是每一家医院,都去训练一个自己的基础大模型。
医院真正需要建设的,是自己的数字底座,自己的知识库,自己的AI中台。
让优秀的大模型,能够真正理解医院,理解医生,理解患者。

写在最后
刚开始接触AI的时候,我一直认为:
模型越大,AI越强。
后来慢慢发现。
真正决定医疗AI价值的。
并不是参数,而是知识。
不是GPU数量,而是临床经验。
不是模型排行榜,而是医生是否愿意相信它。
未来。
基础模型还会不断更新,新的模型还会不断出现。
但真正沉淀下来的,一定是医疗知识,是医院自己的数据,是临床工作流,也是医生几十年积累下来的经验。
模型可以不断更换,知识却会不断积累。
也许,这才是医疗AI真正的护城河。
模型终将开源,算力终将普及,真正不会贬值的,是医疗知识、临床经验,以及把它们组织起来的能力。

知而后行,行而求知。
从手术室到机房,从临床到系统。
记录一名麻醉医生关于医疗AI、医院信息化与持续成长的探索。
—— 医路智行录