 夜雨聆风
夜雨聆风





RAG 时代,文档切分才是那个被低估的核心问题
往 AI 知识库传了文档却答不上来,大多数人忽略了这一步
你有没有遇到过这种情况:
公司花了几周整理了一份知识库,往 AI 系统里一传,兴冲冲问它一个问题——它要么说”我不知道”,要么答非所问,明明文档里就写着答案。
很多人第一反应是:AI 模型不够好,换个更强的。
但实际上,大多数时候问题根本不在模型,而在文档是怎么被”喂”进去的——也就是文档切分。
这是 RAG 知识库里最容易被忽略、但又最关键的一步。
一个类比说清楚什么是”文档切分”
先用一个生活里的类比。
你有一本《企业管理手册》,300 页。
现在有人问你:”我们公司年假怎么算?”
你会怎么翻这本书?正常人不会把整本书从头到尾念一遍,你会先找目录——”人事制度”章节——然后定位到”假期管理”这一页,找到对应的条文。
AI 知识库回答问题的过程是一样的。
文档切分,就是把一本书拆成一张张”可检索的卡片”。拆得好,AI 能精准找到对应的那张卡;拆得不好,要么把一张完整的条文拦腰截断,要么把完全不相关的内容塞进同一张卡——AI 自然答不上来。
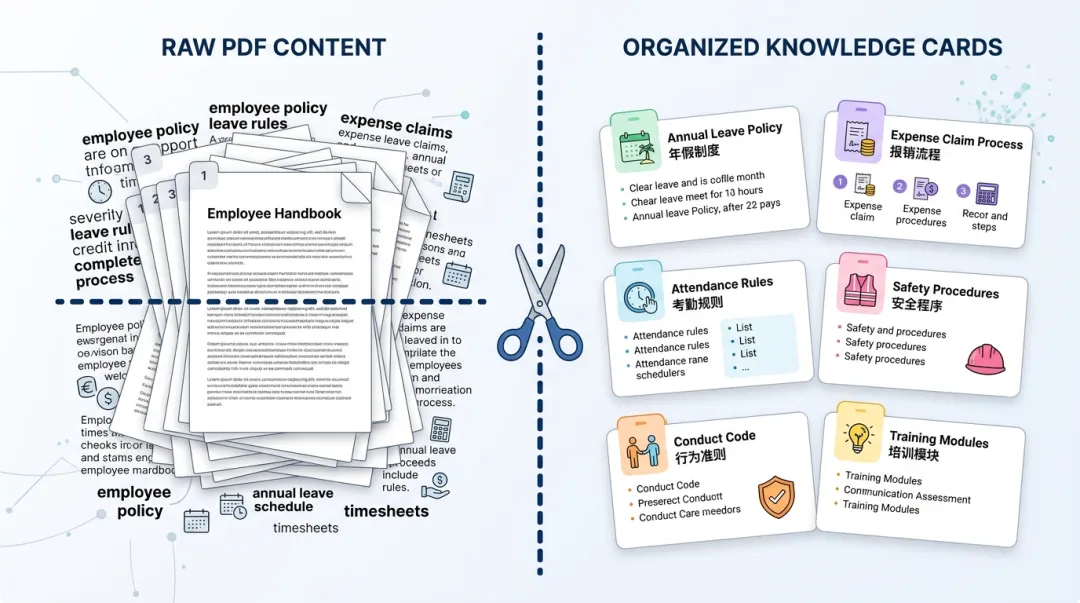
RAG 知识库是怎么工作的?
在说切分策略之前,先把 RAG 的基本逻辑过一遍。不懂技术也能理解。
RAG 的全称是”检索增强生成”,它的流程可以分成四步:
第一步:文档进来,切成小块。这一步叫 Chunking(切分),就是把长文档切成若干”语义块”,每个小块尽量包含一个完整的知识点。
第二步:每个小块转成向量,存进数据库。向量你可以理解成”数字指纹”,语义相近的内容,指纹相似,在数据库里离得近。
第三步:用户提问,AI 把问题也转成向量,去数据库里找最相似的块。这步叫检索。
第四步:把找到的内容当作上下文,喂给大模型生成答案。检索质量直接决定生成质量——如果捞出来的块本身是乱的、截断的,AI 再强也救不回来。
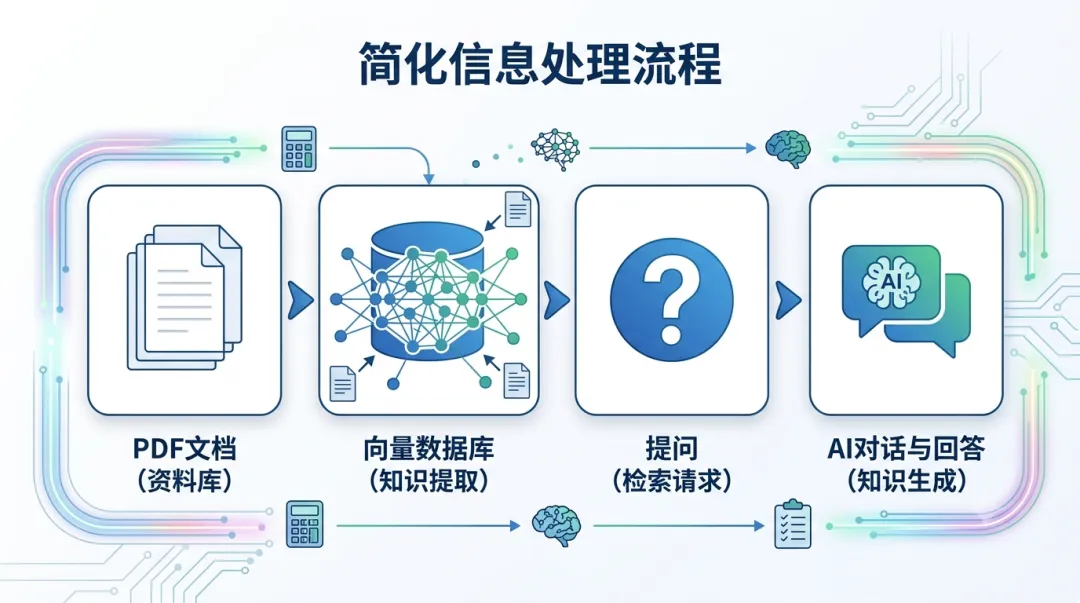
文档切分发生在第一步,却是整个流程效果的天花板。
一个被忽视的基础问题:Token 怎么数
在介绍具体策略之前,先说一个特别容易被忽略的基础问题:Token 怎么数?
很多人以为”1000 字 ≈ 多少 Token”,然后凭感觉设参数。这是 RAG 系统里最常见的隐性错误来源。
正确的做法是:用跟 AI 模型一样的编码方式来数 Token。
目前主流 AI 模型(GPT-4o、Claude、DeepSeek)使用的都是 cl100k_base 编码,一个 Python 库叫 tiktoken 可以精确计算。
这意味着:你设置 chunk_size=500,指的是 500 个 Token,不是 500 个字。中文大约 1-2 个字算 1 Token,英文大约 4 个字符算 1 Token。差别很大,用 tiktoken 才能算准。
后面所有参数建议都以 Token 为单位,不再用模糊的”字数”。
五种文档切分策略,一种一种说
策略一:固定大小切——最快但不推荐
按 Token 数均匀切,比如每 500 Token 一切,中间重叠 50 Token。
优点是快,缺点是容易把一句话从中间截断。比如切到”公司规定员工每年享有——15天带薪年假”,AI 拿到前半截根本没法理解。
适合场景:日志文件、快速原型、不太在意准确性的场合。
策略二:递归字符切——当前工业界主流
这个策略的核心思路是按层级来切。
先按段落切(\n\n 换行符),如果某段太长,再按句子切(句号、感叹号),再太长按标点切,最后才按 Token 数强行截断。
就像翻书时,先翻到”第X章”,章太长再看”第X节”,节太长再看”第X段”。
这是目前企业级 RAG 系统用得最多的基础策略。
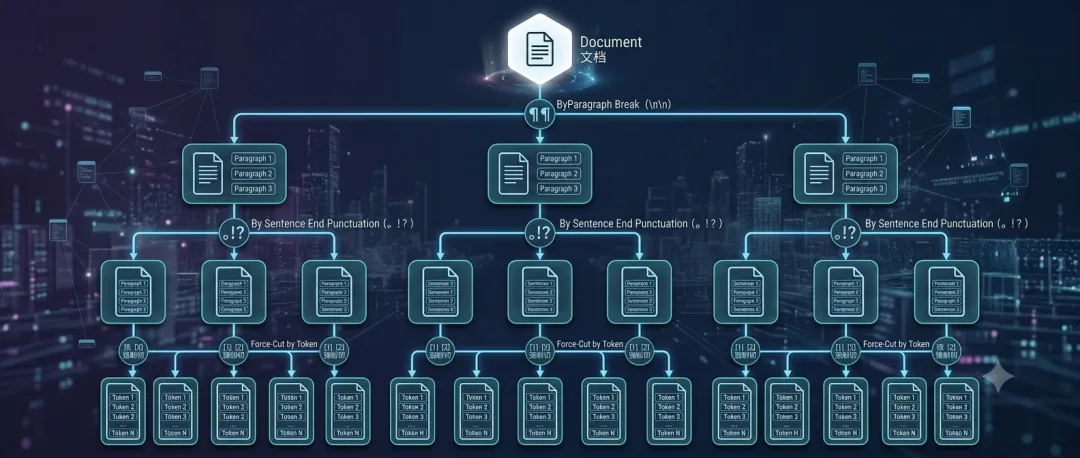
适合场景:几乎所有类型的文档,是绝大多数项目的起点。
策略三:语义切分——更聪明但更贵
递归切分是按”格式”来切的。但有时候一段话包含两个主题,比如:”公司去年营收增长20%,同时员工数量也增加了15%。”这句话前后是两个主题,递归切分会把它们放在一起,语义不纯净。
语义切分的做法是:先把每句话转成向量,计算相邻句子的相似度——相似度高就合并,骤降就切开。
计算量更大,但切出来的块语义高度一致,不会在中间混入不相关的内容。
|
|
|
|
|---|---|---|
|
|
|
|
| 0.55–0.65(推荐) |
|
|
|
|
|
|
适合场景:高价值文档(合同、财务报告、医疗记录),需要精确问答的场景。
策略四:结构感知切分——文档有结构就用它
Markdown 文件、Word 文档这类文档本身有标题层级——H1、H2、H3 层层嵌套。结构感知切分就是顺着文档的原生结构来切。
一个 H2 标题下的内容,本身就是一个独立主题,不需要靠算法去猜哪里应该切。
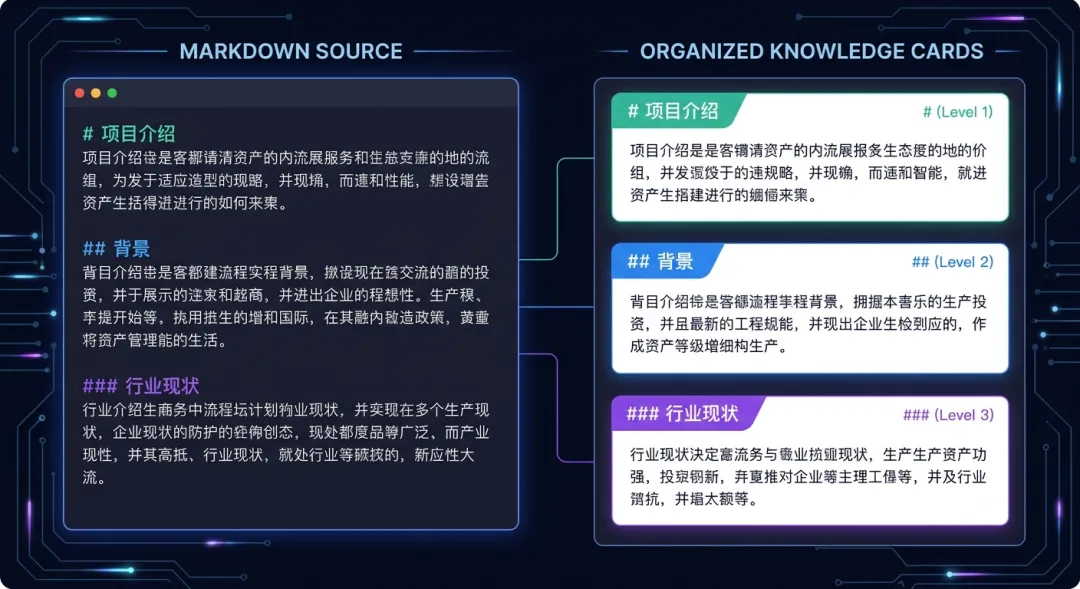
适合场景:有清晰结构的文档(Markdown、Word、技术文档、帮助中心)。
策略五:LLM 辅助切分——最精准也最贵
最极端的做法:直接让大模型来切。
你把文档丢给 GPT-4o,告诉它”把这篇文档按语义完整段落切分,每个块要有独立完整的语义,表格和代码块要整体保留”。
它会按知识点来切,而且知道哪些内容天然是一个整体。
成本参考:处理约 10 万字文档,预估花费$0.8-1.5(按 2026 年定价)。适合小批量、高价值的核心文档,不适合处理上万份文件。
适合场景:合同审核、医疗指南、法律法规等不允许出错的文档。
进阶技巧:让 RAG 效果翻倍的三个方法
技巧一:父子切分——精确检索 + 完整上下文
这是一个”两层楼”的切分方法。
底层(Child):切成很小的块,比如每 300 Token 一个块——用于检索,精准匹配问题。
上层(Parent):切成大块,比如每 2000 Token 一个块——包含完整的上下文,不会出现”半截话”。
工作原理:用户提问时,先在底层小块里找最匹配的,找到后拉出它对应的大块作为上下文。这样既精准又完整。
一个关键技术改进:早期的父子切分用”字符串包含”来判断 Child 和 Parent 的关系——如果小块的文字被大块包含,就建立关联。但这在生产环境中容易出错。更新更好的做法是记录每个块在原文中的起止位置(
start_index),用位置范围来判断 Child 是否落在 Parent 的范围内,精准可靠。
适合场景:所有生产级 RAG 系统。
技巧二:HyDE——用一个假答案去找真答案
传统做法:用户问”公司年假怎么算”,直接拿这句话去检索。
HyDE 的做法:先用 AI 根据问题生成一个”假设的标准答案”,比如 AI 先写一段”公司年假计算的标准规定……”,再用这个假答案去找真实文档。
为什么有效?因为假答案和真实文档的语义更接近,检索命中率更高。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
技巧三:CRAG——让 AI 先判断检索质量再生成
很多 RAG 系统有一个通病:检索到一堆内容,不管质量好坏全塞给大模型,让大模型自己判断。
CRAG(自我纠正 RAG)的思路是:在检索之后多加一步,让 AI 先评判检索质量。
评判结果有三种:
正确:找到了,直接用
部分相关:补充网络搜索
不相关:重新检索,换策略

GraphRAG:专门解决”多跳问题”的增强手段
前面三个技巧都是对标准 RAG 的优化。还有一种更专门的技术叫GraphRAG,专门解决一类特殊问题:多跳推理。
什么叫多跳?举个例子:”公司 CEO 的母校是哪所?”
这个问题要答对,你需要串联两步知识:① CEO 是谁,② 那个人毕业于哪所学校。普通 RAG 很难回答这类问题,因为答案分散在两份不同文档里。
GraphRAG 的解决思路是:把知识库里所有实体和关系抽出来,建一张”知识地图”,而不是一堆孤立的文本块。
检索时,AI 顺着这张地图从一个实体跳到另一个实体,找到关联路径,串联回答。
什么时候需要 GraphRAG:
需要回答多跳问题(”A 和 B 是什么关系?”)
需要回答全局性问题(”这份年报的核心主题是什么?”)
知识高度关联,需要关联分析
什么时候不需要:
简单的事实问答(”今天几号?”)
文档之间没有太多关联
数据量特别大(GraphRAG 构建成本高)
成本参考(用 GPT-4o 构建):
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
建议先用核心文档子集验证效果,再全量扩展。
文档类型不同,处理方式也不一样
表格:必须整块保留
很多人不自觉地把表格按行拆开,拆开以后,每一行都没有意义了。正确做法:表格必须整块存储,同时加一段描述文本,比如”2024年Q1-Q4季度收入对比表,Q1收入1000万,Q4增长至1500万”。这样用户问”哪季度增长最快”,AI 能搜到这张表并正确理解它的内容。
代码块:按函数/类切,不拆分逻辑单元
代码不能按行数切。正确的切分边界是函数定义、类定义、import 语句——这些是代码的”自然段落”。
扫描件和图片:必须先做 OCR
纸质文件扫描出来的 PDF,必须先用 OCR 转成可搜索的文本。企业推荐用RAGFlow DeepDoc或IBM 开发的 Docling(开源,支持复杂 PDF)。
跨页表格:处理更复杂
如果一张表格跨了两页,普通切分会把上下两部分分到不同的块里。解决方案是用多模态模型(GPT-4o 等)直接理解表格图片,生成结构化描述,与原表格一起存储。
选对策略,从问自己三个问题开始
很多人卡在”不知道该用哪种策略”。其实不难,先问自己三个问题:
问题一:你的文档有清晰的章节标题吗?
如果有——用结构感知切分。标题本身就是天然边界,按 H1、H2 切出来的块天然语义完整,不需要再靠算法猜哪里该断开。
如果没有、或者文档是纯文字——用递归字符切分。这是绝大多数文档的默认起点,够用、稳定。
问题二:这份文档出错代价大吗?
比如合同、医疗指南、重要的财务报告——出错代价高,用 LLM 辅助切分。多花一点成本,但保证每个块语义完整、不截断关键条款。
日常文档、会议记录、产品说明——递归字符切分足够。
问题三:你的用户会问多复杂的问题?
简单事实问答(”今天有什么会?””年假有几天?”)——标准切分够用。
需要推理和关联(”A 和 B 之间有什么关系?””公司今年战略和去年有什么变化?”)——考虑引入 GraphRAG,先用小批量核心文档验证效果。
一个信号,帮你判断知识库是否需要优化切分
不用懂技术,有一个简单的方法可以判断你的 RAG 知识库是不是切分出了问题:
随机挑 20 个用户的真实提问,统计 AI 答错的规律。
如果 AI 答错的问题符合以下模式,说明大概率是切分出了问题:
“半截话”问题:AI 回答缺少主语或结论,读起来不完整。→ 块被从中间切断了,应该检查 chunk_overlap 是否太小,或者改用结构感知切分。
“答非所问”问题:用户问 A 主题,AI 回答里掺了大量 B 主题的内容。→ 块太大、语义不纯净,应该检查 chunk_size 是否太大,或者改用语义切分。
“跨页失效”问题:用户问的是文档里明确写过的内容,但 AI 说”我没有找到相关信息”。→ 可能是表格被打散、图片内容没有提取、或者块太小导致关键段落被跳过了。
这个诊断不需要任何技术背景,任何负责运营知识库的人都可以做。每周花 10 分钟做一次,准确率比调参数高得多。
一句话总结
RAG 知识库的效果好不好,50% 取决于你选什么模型,50% 取决于你怎么把文档切分喂进去。
文档切分看起来是件小事,但它决定了 AI 能不能”读懂”你的知识库。结构清晰的切分,让 AI 在对的语境里找到对的答案;胡乱切的文档,再强的模型也救不回来。
下次你的 AI 知识库答非所问,别急着换模型,先看看文档是怎么切的。