 夜雨聆风
夜雨聆风刚刚,OpenAI 突然放出重磅更新——GPT-5.4 Thinking 和 GPT-5.4 Pro 同步上线,即刻在 ChatGPT、API 和 Codex 全面铺开。

这条消息在 X 平台发出后,两小时浏览量突破 312 万。
第一时间通读了 OpenAI 的官方技术博客,把所有关键信息拆解如下。先说结论:GPT-5.4 不只是"刷了几个分"那么简单——它是 OpenAI 第一个将推理、编码、计算机操作和 Agent 能力统一到同一个模型里的产品。
OpenAI 这次的定位很明确:GPT-5.4 是为专业工作设计的。 它把 GPT-5.3 Codex 业界领先的编码能力,和 GPT-5.2 的通用推理能力合二为一,同时新增了原生计算机操作、百万级上下文、工具搜索等多项重磅特性。
两个版本,各有侧重
GPT-5.4 Thinking(模型 ID: gpt-5.4):面向日常使用的旗舰推理模型,已在 ChatGPT 中灰度上线GPT-5.4 Pro(模型 ID: gpt-5.4-pro):面向极端复杂任务的增强版,开最大推理预算时性能拉满
六大核心升级
1. 首个原生支持"计算机操作"的通用模型
这是本次发布最大的亮点。GPT-5.4 不再只是"聊天 + 写代码",它可以直接操控桌面环境——通过截图理解屏幕内容,发出鼠标点击和键盘输入指令,完成跨应用的复杂工作流。
在 OSWorld 基准测试(衡量模型在真实桌面环境中的操作能力)上,GPT-5.4 拿到了 75.0% 的成功率,不仅远超自家 GPT-5.2 的 47.3%,甚至超越了人类表现。

OpenAI 特别强调,GPT-5.4 既擅长通过 Playwright 等库编写代码来操控计算机,也能直接根据截图发出鼠标键盘指令。开发者还可以通过系统消息灵活调整模型行为,甚至配置自定义的安全确认策略。
2. 百万级 Token 上下文窗口
GPT-5.4 在 API 和 Codex 中支持高达 100 万 Token 的上下文窗口,让 Agent 可以在更长的时间跨度内规划、执行和验证任务。这对于需要处理大型代码库、长文档或多轮复杂工作流的场景来说,是质的飞跃。
3. 工具搜索(Tool Search):Token 消耗直降 47%
以前给模型传入工具定义时,所有工具的完整描述都要塞进上下文,几十个 MCP 工具轻松占掉上万 Token。
GPT-5.4 引入了工具搜索机制——模型只接收一份轻量工具列表,需要用某个工具时才动态查找并加载其完整定义。
OpenAI 用 Scale 的 MCP-Atlas 基准(250 个任务,36 个 MCP 服务器)做了实测:开启工具搜索后,总 Token 消耗降低 47%,准确率不变。 对于那些动辄挂载几十个 MCP 服务器的开发者来说,这个改进直接影响钱包。
4. 史上最省 Token 的推理模型
OpenAI 称 GPT-5.4 是他们"最高效的推理模型"——完成同样的任务,消耗的 Token 显著少于 GPT-5.2,推理速度也更快。Codex 中开启 /fast 模式后,Token 输出速度还能再提升 1.5 倍。
5. 可中断、可调整方向的"思考"
在 ChatGPT 中,GPT-5.4 Thinking 在处理复杂任务时会先给出一个思路大纲(preamble)。你可以在它"想"的过程中随时打断,追加指令或修正方向,不用等它跑完再从头来。
之前用思考模型,一旦它开始推理你就只能干等。现在终于可以"随时插嘴"了——这在实际使用中体验提升巨大。
6. 史上最准确:幻觉率大幅下降
在一组用户标记了事实错误的真实对话中,GPT-5.4 的单条声明虚假率比 GPT-5.2 **降低了 33%,完整回复中包含任何错误的概率降低了 18%**。OpenAI 称其为"迄今最准确的模型"。
专业工作能力:44 个职业横评,碾压行业平均
OpenAI 在 GDPval 基准上做了一项很有说服力的测试——这个基准涵盖了美国 GDP 贡献最大的 9 个行业、44 个职业,要求模型完成真实的工作产出,比如销售演示文稿、会计电子表格、急诊排班表、制造业流程图,甚至短视频。
结果:GPT-5.4 在 83% 的对比中匹配或超过行业专业人士,而 GPT-5.2 这一数字是 70.9%。
几个细节值得关注:
电子表格:在模拟投行初级分析师的建模任务上,GPT-5.4 的均分大幅超过 GPT-5.2 演示文稿:人工评审在多数情况下更偏好 GPT-5.4 的产出,原因是"美学更好、视觉更丰富、图片生成运用更得当" ChatGPT for Excel 插件同日发布,企业用户可以在 Excel 中直接调用 GPT-5.4
Mercor 的 CEO 评价说:
“"GPT-5.4 是我们测过的最好的模型。它在我们的 APEX-Agents 基准上登顶,尤其擅长创建长周期交付物,如幻灯片、财务模型和法律分析,同时速度更快、成本更低。"
Harvey(AI 法律平台)的应用研究负责人也表示:
“"在 BigLaw Bench 评测中,GPT-5.4 拿到了 91%。它在处理复杂交易分析、长合同审查和高精度法律细节上,目前是最好的。"
编码能力:继承 Codex 衣钵,前端表现"肉眼可见地好"
GPT-5.4 整合了 GPT-5.3 Codex 的编程能力。在 SWE-Bench Pro(公开)上拿到 **57.7%**,略高于 GPT-5.3 Codex 的 56.8%,同时延迟更低。
但最让人兴奋的可能不是分数,而是 OpenAI 在文章里放的那个演示——用 GPT-5.4 从一条提示词直接生成了一个完整的等距视角主题公园模拟游戏,包含:
瓷砖化路径铺设、游乐设施建造 游客寻路、排队、乘坐循环 金钱、游客数、幸福度、清洁度等运营指标 用 AI 图片生成制作全套等距素材 用 Playwright Interactive 自动化浏览器测试

Cursor 的开发者教育副总裁 Lee Robinson 评价:
“"GPT-5.4 目前是我们内部基准的领导者。工程师们觉得它比之前的模型更自然、更果断——面对模糊问题不会反复犹豫,还会主动并行化工作。"
OpenAI 同时发布了实验性的 Playwright Interactive Codex 技能,允许 Codex 可视化调试网页和 Electron 应用——甚至可以一边构建应用一边测试。
Agent 能力全面升级:搜索、工具调用、多步推理
搜索能力飙升。 在 BrowseComp(衡量 AI 能否在网上持续搜索找到难以定位的信息)上,GPT-5.4 比 GPT-5.2 暴涨 17 个百分点,GPT-5.4 Pro 更是拿到了 89.3% 的新纪录。
Zapier CEO 的评价很直接:
“"GPT-5.4 xhigh 是多步工具使用的新标杆。它能完成之前模型半途放弃的任务——是我们测过的最执着的模型。"
工具调用更精准。 在 Toolathlon 基准(测试 AI Agent 使用真实 API 完成多步任务的能力)上,GPT-5.4 达到 **54.6%**,比 GPT-5.2 的 45.7% 提升近 9 个百分点。
完整基准对比:GPT-5.4 vs Claude vs Gemini
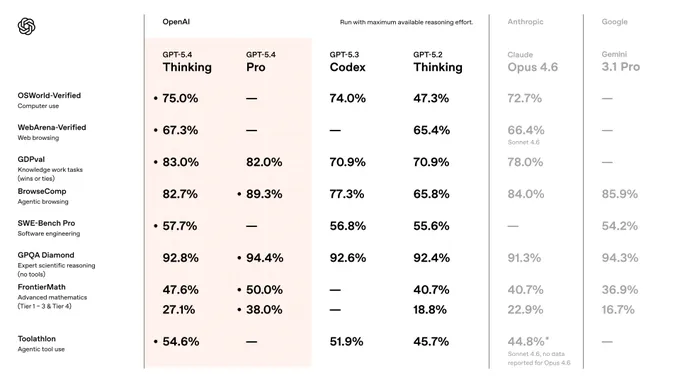
这是很多人最关心的部分。OpenAI 这次放出了完整的横评表格:
| 75.0% | ||||||
| 67.3% | ||||||
| 83.0% | ||||||
| 89.3% | ||||||
| 57.7% | ||||||
| 94.4% | ||||||
| 50.0% | ||||||
| 38.0% | ||||||
| 54.6% |
“*注:WebArena 和 Toolathlon 中 Claude 的成绩来自 Sonnet 4.6,Opus 4.6 暂无公开数据。
价格:单价涨了,但总成本可能降了
OpenAI 坦言 GPT-5.4 的单价高于 GPT-5.2,但因为 Token 效率大幅提升,实际任务的总成本可能更低。
Batch 和 Flex 定价为标准价的一半,Priority 处理为两倍。
对开发者来说,关键不是看单价,而是看完成同一任务的总消耗。如果 Token 用量真的砍半,那即使单价涨了,总账单反而可能更低。
可用性和过渡安排
ChatGPT Plus / Team / Pro 用户:GPT-5.4 Thinking 今天开始灰度推送,替代 GPT-5.2 Thinking Enterprise / Edu 用户:管理员可在后台开启抢先体验 GPT-5.4 Pro:仅对 Pro 和 Enterprise 套餐开放 GPT-5.2 Thinking:将在模型选择器的"Legacy Models"中保留三个月,2026 年 6 月 5 日正式退役 API: gpt-5.4和gpt-5.4-pro现已可用
GPT-5.4 的发布让格局更加清晰:
OpenAI:用 GPT-5.4 将推理、编码、计算机操作、Agent 工具统一到一个模型里,综合实力重回第一 Anthropic:Claude Opus 4.6 在 Agent 浏览和科学推理上仍不落下风,Claude Code 在开发者生态中的渗透率持续走高 Google:Gemini 3.1 Pro 在搜索和科学推理上暗暗发力,GPQA Diamond 几乎追平 GPT-5.4 Pro
三家各有攻防,谁也没形成碾压优势。对普通用户和开发者来说,这反而是最好的局面——竞争越激烈,工具越好、越便宜。
我的建议是:不要 All in 任何一家。 在各家模型轮流"屠榜"的节奏下,最明智的做法是保持灵活,根据具体任务选最合适的模型。
