 夜雨聆风
夜雨聆风
| 框架 | 核心代码量 | 功能完整度 | 定制门槛 | 资源占用 |
|---|---|---|---|---|
| nanobot | ~4000 行 | 全功能 Agent | 极低(改配置即可) | 极低 |
| OpenClaw | ~40 万行 | 全功能 Agent | 高 | 中高 |
| LangChain | 数十万行 | 工具链丰富 | 中高 | 中 |
| AutoGPT | 数万行 | 自动化能力强 | 中 | 中高 |
在AI Agent领域,坊间流传着一个“不可能三角”:功能强大、代码简洁、易于定制,三者似乎永远不可兼得。nanobot 仅用约4000行代码,就实现了一个功能完备的AI助手,比OpenClaw小了99%。
笔者最近用AI阅读了nanobot的源码,被其精巧的设计打动。今天将带大家一探究竟,看看这4000行代码背后隐藏着怎样的架构智慧。这篇文章面向有一定编程基础的工程师,力求做到既深入又通俗。

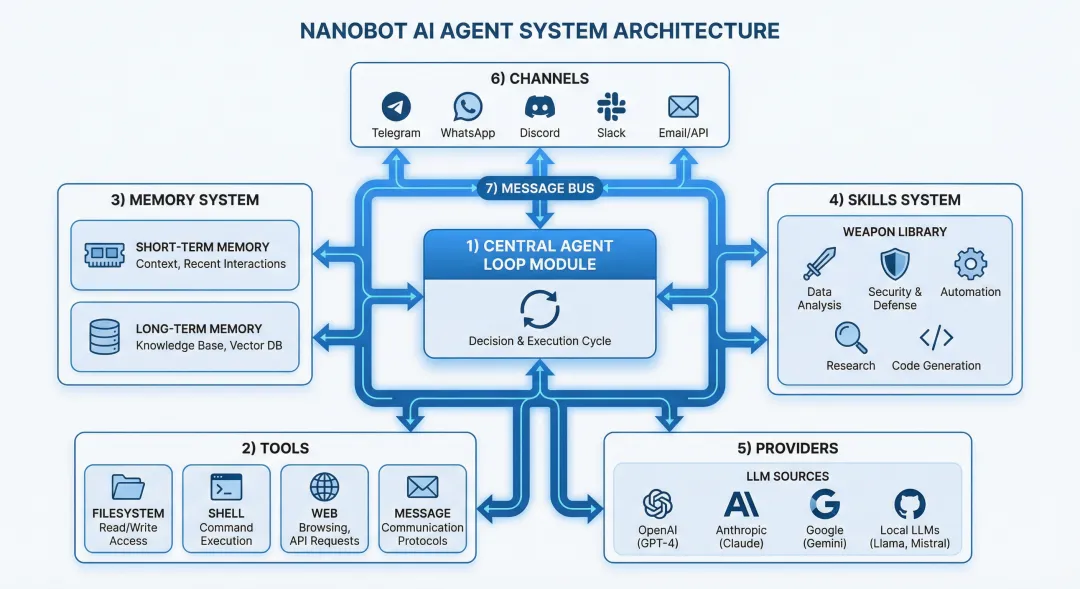
一、整体架构:一个“小而美”的Agent系统
在深入代码之前,我们先从宏观角度理解nanobot的架构设计。nanobot采用模块化设计,核心组件各司其职,通过清晰定义的接口进行交互。
从目录结构就能感受到这种设计思路:
nanobot/├── agent/ # 核心Agent逻辑│ ├── loop.py # Agent主循环│ ├── context.py # 上下文构建│ ├── memory.py # 记忆系统│ ├── skills.py # 技能加载器│ ├── subagent.py # 子代理管理│ └── tools/ # 内置工具集├── providers/ # LLM提供者├── channels/ # 通讯渠道(飞书、QQ等十多款)├── bus/ # 消息总线├── session/ # 会话管理└── config/ # 配置管理
这个架构可以用一句话概括:Agent Loop是大脑,Tools是手脚,Memory是记忆,Skills是武器库,Providers是大脑的营养源。 接下来,让我们逐一拆解每个核心组件。
二、核心组件深度解析
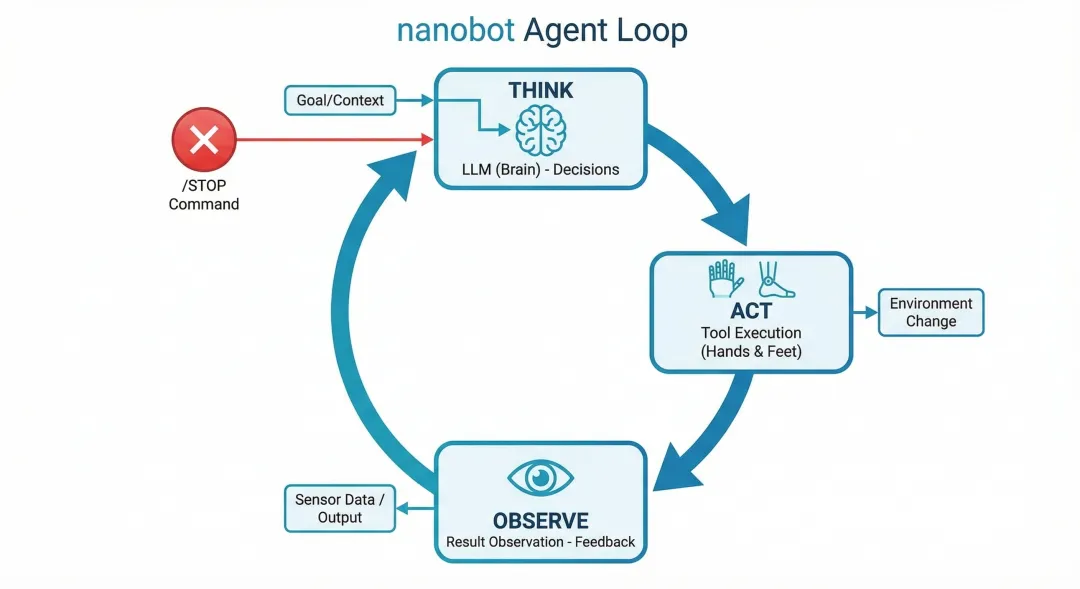
2.1 Agent Loop —— 代理循环:整个系统的心脏
如果我们只能选择一个最重要的文件,那一定是loop.py。这个文件(约500行代码)包含了Agent的核心运行逻辑。让我带大家看看它的核心流程:
async def _run_agent_loop(self, initial_messages, on_progress=None):"""运行Agent迭代循环"""messages = initial_messagesiteration = 0while iteration < self.max_iterations:iteration += 1# 第一步:调用LLM获取响应response = await self.provider.chat(messages=messages,tools=self.tools.get_definitions(),model=self.model,temperature=self.temperature,max_tokens=self.max_tokens,)# 第二步:如果有工具调用,执行工具if response.has_tool_calls:# 添加助手消息(包含工具调用)messages = self.context.add_assistant_message(...)# 逐个执行工具调用for tool_call in response.tool_calls:result = await self.tools.execute(tool_call.name, tool_call.arguments)messages = self.context.add_tool_result(messages, ...)else:# 没有工具调用,说明任务完成final_content = response.contentbreak
这个流程有多聪明?它完美复现了人类思考问题的模式:“思考→行动→观察→再思考→再行动→...” 的循环。LLM负责思考和决策,工具负责执行具体操作,观察结果反馈给LLM,形成闭环。
更重要的是,这个循环是可中断的。用户随时可以输入/stop来终止当前任务,代码中有完善的取消机制:
if msg.content.strip().lower() == "/stop":await self._handle_stop(msg)
这种设计让系统响应灵敏,用户体验极佳。
2.2 Context Builder —— 上下文构建:给LLM喂“合适”的信息
ContextBuilder(context.py)负责组装发送给LLM的完整上下文。这包括:系统提示词、历史消息、当前输入、内存内容、技能信息等。
它的核心方法build_messages构建了完整的消息列表:
def build_messages(self, history, current_message, media=None, channel=None, chat_id=None):"""构建完整的消息列表"""# 1. 运行时上下文(时间、渠道等)runtime_ctx = self._build_runtime_context(channel, chat_id)# 2. 用户消息(可能包含图片)user_content = self._build_user_content(current_message, media)# 3. 合并所有内容return [{"role": "system", "content": self.build_system_prompt()},*history,{"role": "user", "content": merged},]
这里的系统提示词构建尤为精妙,采用渐进式加载策略:
def build_system_prompt(self, skill_names=None):parts = [self._get_identity()] # 核心身份parts.append(self._load_bootstrap_files()) # 引导文件parts.append(self.memory.get_memory_context()) # 记忆parts.append(self.skills.load_skills_for_context(...)) # 常用技能parts.append(self.skills.build_skills_summary()) # 技能概要return "\n\n---\n\n".join(parts)
引导文件机制是nanobot的一个亮点。用户可以在工作区放置5个特殊的Markdown文件来自定义Agent行为:
AGENTS.md- Agent角色定义SOUL.md- 核心价值观USER.md- 用户信息TOOLS.md- 工具说明IDENTITY.md- 身份定义
这种设计让用户不需要修改代码,就能深度定制Agent的“性格”和能力。
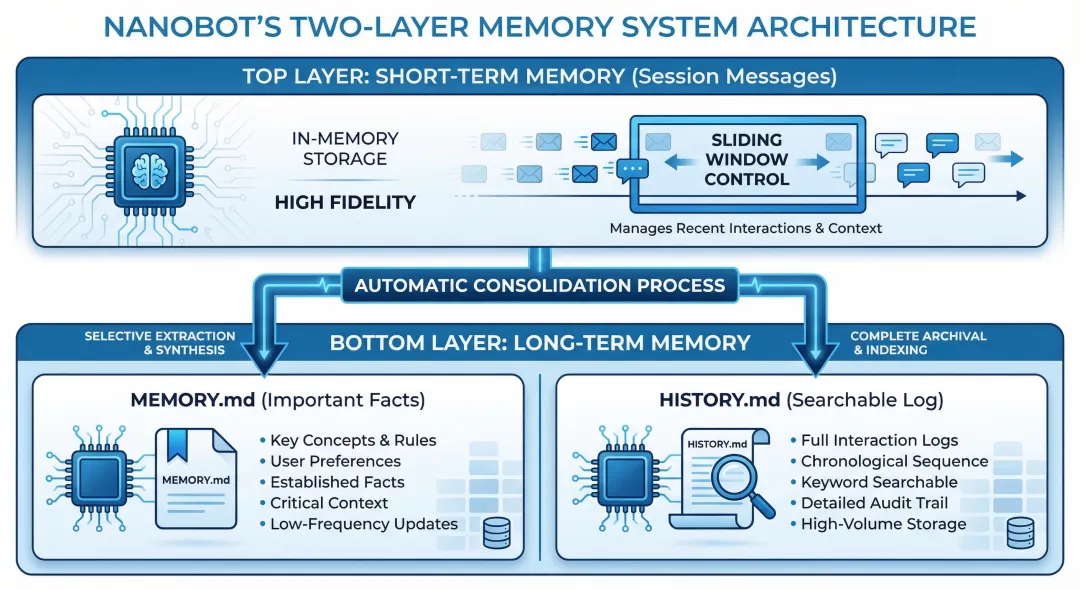
2.3 Memory System —— 两层记忆体系:让Agent“记住”一切
nanobot的记忆系统(memory.py)采用经典的双层记忆架构:
短期记忆:会话历史(Session Messages)
存储在内存中
保真度高,完整保留对话细节
通过滑动窗口控制长度
长期记忆:两层存储
MEMORY.md- 长期事实记忆(重要信息)HISTORY.md- 可搜索的历史日志
class MemoryStore:"""两层记忆:MEMORY.md(长期事实)+ HISTORY.md(可搜索日志)"""def __init__(self, workspace):self.memory_dir = ensure_dir(workspace / "memory")self.memory_file = self.memory_dir / "MEMORY.md"self.history_file = self.memory_dir / "HISTORY.md"
最令人称道的是自动记忆整合功能。当会话消息积累到一定数量(默认50条)时,系统会自动触发记忆整合:
async def consolidate(self, session, provider, model, archive_all=False, memory_window=50):"""将旧消息整合到MEMORY.md和HISTORY.md"""# 1. 提取待整合的消息old_messages = session.messages[session.last_consolidated:-keep_count]# 2. 调用LLM进行总结response = await provider.chat(messages=[...],tools=_SAVE_MEMORY_TOOL, # 专门用于保存记忆的工具)# 3. LLM决定:哪些写入MEMORY,哪些写入HISTORYif entry := args.get("history_entry"):self.append_history(entry) # 写入HISTORY.mdif update := args.get("memory_update"):self.write_long_term(update) # 更新MEMORY.md
这个设计太精妙了!它让LLM自己决定什么值得记住、什么可以遗忘,实现了自动化的信息过滤和结构化存储。
2.4 Skills System —— 技能系统:按需加载的“武器库”
SkillsLoader(skills.py)实现了nanobot的技能系统。技能本质上是Markdown文件(SKILL.md),告诉Agent如何使用特定工具或完成特定任务。
渐进式加载是这里的核心智慧:
def build_system_prompt(self):# 1. 常用技能:总是加载完整内容always_skills = self.skills.get_always_skills()always_content = self.skills.load_skills_for_context(always_skills)# 2. 其他技能:只显示摘要skills_summary = self.skills.build_skills_summary()# Agent如果需要某个技能,会自己用read_file读取
技能可以来自两个地方:
内置技能:项目自带的技能(如github、weather等)
用户技能:用户在工作区
skills/目录下自定义的技能
每个技能支持通过YAML Frontmatter声明元数据:
---name: githubdescription: GitHub操作技能always: false # 是否总是加载requires:bins: [gh] # 需要的命令行工具env: [GH_TOKEN] # 需要的环境变量---
系统会自动检查依赖是否满足,未满足的技能会标记为available="false",并提示用户如何安装依赖。
2.5 Subagent Manager —— 子代理:并行处理复杂任务
当用户提出一个复杂任务时,主Agent可以“孵化”子代理(subagent.py)来并行处理:
async def spawn(self, task, label=None, origin_channel="cli", ...):"""孵化一个子代理来执行后台任务"""task_id = str(uuid.uuid4())[:8]# 创建后台任务bg_task = asyncio.create_task(self._run_subagent(task_id, task, display_label, origin))# 立即返回,让主Agent可以继续响应用户return f"Subagent [{display_label}] started (id: {task_id}). I'll notify you when it completes."
子代理拥有受限的工具集(只读文件、写入文件、执行Shell、搜索网页等),而且默认不能发送消息或孵化新的子代理,这体现了最小权限原则。
子代理完成任务后,会通过消息总线将结果注入主Agent:
async def _announce_result(self, task_id, result, origin, status):"""通过消息总线宣布结果"""msg = InboundMessage(channel="system",sender_id="subagent",chat_id=f"{origin['channel']}:{origin['chat_id']}",content=announce_content,)await self.bus.publish_inbound(msg)
这种设计让复杂任务可以后台异步执行,用户无需等待,极大提升了系统的响应能力。
2.6 Tool System —— 工具系统:Agent的“四肢”
nanobot的工具系统设计得非常优雅。采用注册制:
class ToolRegistry:def __init__(self):self._tools: dict[str, Tool] = {}def register(self, tool: Tool) -> None:self._tools[tool.name] = toolasync def execute(self, name: str, params: dict) -> str:tool = self._tools.get(name)return await tool.execute(**params)
每个工具只需要继承Tool基类并实现三个属性和一个方法:
class Tool(ABC):@property@abstractmethoddef name(self) -> str:pass # 工具名称@property@abstractmethoddef description(self) -> str:pass # 工具描述(给LLM看)@property@abstractmethoddef parameters(self) -> dict:pass # JSON Schema参数定义@abstractmethodasync def execute(self, **kwargs) -> str:pass # 执行逻辑
来看看一个具体工具长什么样(文件系统工具):
class ReadFileTool(Tool):@propertydef name(self) -> str:return "read_file"@propertydef description(self) -> str:return "Read content from a file..."@propertydef parameters(self) -> dict:return {"type": "object","properties": {"path": {"type": "string", "description": "File path to read"},},"required": ["path"]}async def execute(self, path, **kwargs) -> str:# 实际的文件读取逻辑content = Path(path).read_text()return content
nanobot内置的工具包括:
文件系统:read_file, write_file, edit_file, list_dir
Shell执行:exec(执行命令行)
网络:web_search, web_fetch
消息:message(发送消息到各渠道)
子代理:spawn(孵化子代理)
定时任务:cron(定时执行)
MCP集成:mcp(Model Context Protocol)
2.7 Provider System —— LLM提供者:灵活的“大脑”选择
LLM Provider采用适配器模式,统一的抽象接口让切换不同的LLM变得轻而易举:
class LLMProvider(ABC):@abstractmethodasync def chat(self, messages, tools=None, model=None, ...):"""发送聊天请求"""pass@abstractmethoddef get_default_model(self) -> str:"""获取默认模型"""pass
nanobot支持的LLM提供者包括:
OpenRouter - 推荐,支持几乎所有主流模型
Anthropic - Claude直连
OpenAI - GPT直连
Groq - 高速推理 + Whisper语音转文字
Google Gemini - Gemini直连
vLLM - 本地模型支持
这种设计让用户可以根据需求(速度、成本、效果)灵活选择最适合的模型。
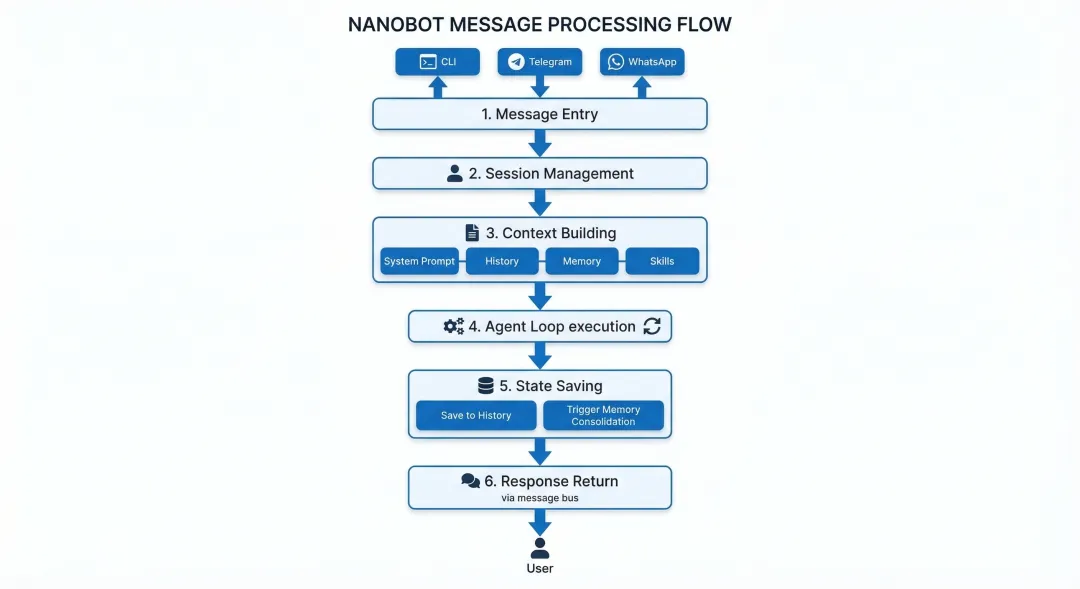
三、一次完整的对话流程
理解了各个组件,让我们把它们串起来,看看一次完整的对话是怎么处理的:
第一步:消息入口
用户通过CLI、Telegram、WhatsApp等渠道发送消息。消息被包装成InboundMessage,通过消息总线(bus)传递给Agent。
第二步:会话管理
Agent根据会话key获取或创建会话对象(Session),加载历史消息。
第三步:构建上下文
ContextBuilder组装系统提示词(包括身份、引导文件、记忆、技能概要)、历史消息和当前输入。
第四步:Agent循环
进入主循环:
调用LLM获取响应
如果有工具调用,执行工具,将结果返回给LLM
如果没有工具调用,说明任务完成
第五步:保存状态
将本次对话保存到会话历史
如果消息达到阈值,触发记忆整合
第六步:返回响应
通过消息总线将响应发送回用户所在的渠道。
整个流程如行云流水,每个组件各司其职,又紧密协作。
四、设计亮点总结
回顾nanobot的代码,有几个设计让我印象深刻:
1. 极简主义
4000行代码实现完整Agent功能,每个模块都恰到好处,不多不少。这体现了“少即是多”的哲学。
2. 模块化设计
每个组件职责单一,通过清晰接口交互。这种设计让代码易于理解,维护和扩展。
3. 渐进式加载
无论是技能还是记忆,都采用按需加载策略。这既控制了上下文长度,又保证了灵活性。
4. 自动化记忆
让LLM自己决定什么值得记住,实现了真正智能的信息管理。
5. 安全优先
子代理受限的工具集、严格的参数验证、沙箱限制执行,体现了安全设计思想。
6. 用户友好
引导文件机制让非开发者也能深度定制Agent行为,降低了使用门槛。
五、写在最后
nanobot是一个值得细细品味的项目。它用4000行代码诠释了什么是“优雅的复杂度”——表面上功能强大,背后的设计却简洁优美。
对于想学习Agent开发的工程师,我强烈建议阅读它的源码。你可以从loop.py入手,跟随代码走一遍完整流程,然后深入感兴趣的模块。这绝对是一次物超所值的技术之旅。
项目地址:https://github.com/HKUDS/nanobot
如果你对nanobot或者AI Agent开发有什么问题,欢迎在评论区交流讨论。

「1 分钟上手」
# 1. 安装pip install nanobot-ai# 2. 初始化配置nanobot onboard# 3. 启动对话nanobot agent

其他相关分享:
OpenClaw:正在觉醒的AI超级生命体——26万星标背后的开源革命
