 夜雨聆风
夜雨聆风最近几周,OpenClaw 讨论最多的两个话题,一个是安全边界,一个是上下文成本。前者决定它敢不敢接真实权限,后者决定它能不能把长任务做完。
很多人提到“上下文压缩”,第一反应还是一句很轻飘的话:窗口快满了,就让模型总结一下。
但真正跑过长链路 Agent 的人都知道,事情没这么简单。会话里塞进来的不只是聊天记录,还有工具调用结果、文件读取内容、命令输出、失败日志、工作区引导文件(AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md 等),以及最近几轮必须保真的操作上下文。你真把这些东西一股脑丢给模型做摘要,最容易丢的往往正是不能丢的部分。
这篇我想把 OpenClaw 的上下文窗口压缩单独拆开讲清楚。结合 openclawcn 文档站里关于 context、compaction、session pruning 和 deep-dive/framework-focus 实现链路的说明,可以把它的思路概括成一句话:OpenClaw 真正值钱的地方,不是做了一次摘要,而是把“上下文失控”拆成了可治理的执行链路。
文档站在深入解析页给出了一个极精炼的总公式:
上下文稳定 ≈ 窗口预检 + 历史卫生 + 配对修复 + 压缩重试 + 超时快照 + 溢出恢复
太长不看版(9 条)
• OpenClaw 处理的不是单一的“历史过长”,而是三类问题同时出现:旧轮次堆积、旧工具结果膨胀、单条超大输出刺穿窗口。 • 第一层不是摘要,而是预防性裁剪:限制历史轮次、渐进式修剪旧 tool result、限制单条工具结果最多占上下文的 30%。 • 第二层才是 Compaction,但它也不是“一次性摘要”,而是带预裁剪、分段摘要、合并摘要、失败降级和结构化补充信息的完整流水线。压缩前还会先触发一次静默的记忆刷新(Memory Flush),把关键状态写入磁盘,防止压缩丢失。 • 第三层把溢出视为正常故障路径:检测 overflow 后显式重试 compaction,不行再做持久级 tool result 截断,最后才建议 /reset。• OpenClaw 在压缩时保护了几类关键不变量:最近对话、tool_use 和 tool_result 的配对关系、文件读写痕迹、工具失败记录、AGENTS.md 里的关键规则。 • Transcript Hygiene(对话记录清理)按提供商策略自动修复配对问题,避免截断后 provider 400 报错。这不是压缩的一部分,而是独立的运行前修正层。 • 记忆系统不只是上下文里的临时信息,而是有一条上下文 → 磁盘 → 向量索引的完整持久化路径,支持混合搜索(BM25 + 向量)。 • 文档站把这条链路总结得很清楚: 窗口预检 → 历史卫生 → 配对修复 → 压缩重试 → 超时快照 → 溢出恢复。这比“快满了就总结”完整得多。• 如果你也在做 Agent,比某个 prompt 更有参考价值的,是这套“渐进式降级 + 结构化保真 + 失败可恢复”的工程思路。
先把文档里的几个概念分开
官方文档把几个经常被混着说的词分得很清楚,这对理解 OpenClaw 很重要。
第一,上下文是模型这一次真正看到的全部内容,包括系统提示词(OpenClaw 构建)、对话历史、工具调用与结果、附件/转录(图片/音频/文件),以及压缩后的摘要和修剪产物。文档里特别提醒:上下文与"记忆"不是同一回事——记忆可以存储在磁盘上并稍后重新加载,上下文是模型当前窗口内的内容。你可以用 /context list 或 /context detail 查看当前上下文的精确构成和大小。
第二,Compaction 是“把较早历史总结后写回会话”。它会持久化到 session 的 JSONL 记录里,后续请求看到的是“摘要 + 最近几轮原始消息”。
第三,Session Pruning 不是持久化摘要,而是每次调用前在内存里临时修剪旧的工具结果。请求发完,这次修剪并不会去重写磁盘上的 JSONL 历史。文档明确说明它仅影响 toolResult 消息,用户和助手消息永远不会被修改。
第四,文档站还提到了 Transcript Hygiene(对话记录清理)——这是按提供商做的内存中修正,用于满足不同提供商(Anthropic、Google、OpenAI 等)的严格格式要求,包括工具调用 id 清理、工具结果配对修复、轮次验证/排序等。这些修正同样不会重写磁盘记录。
第五,深入解析页强调了一条固定执行顺序:先窗口预检 → 再历史卫生 → 再配对修复 → 再压缩重试 → 超时快照 → 最后溢出恢复。这说明 OpenClaw 把上下文治理当成一条可恢复的状态机,而不是单点功能。
先别把上下文压缩理解成“一次摘要调用”
在普通聊天产品里,上下文问题通常只有一个维度:历史消息太多了。
但 OpenClaw 这类会动手的 Agent,至少同时面对三种膨胀源。
第一类是旧轮次累积。用户和 Agent 对话轮次越来越多,早期消息会把窗口慢慢吃满。
第二类是工具结果膨胀。真正占空间的,常常不是对话,而是 read_file、bash、browser 这些工具吐回来的大段内容。尤其是读大文件、跑长日志、抓网页结构时,一条 tool result 顶几十轮对话是常态。
第三类是单次极端输出。例如一次命令直接打印十几万字符,或者读进来一个超长文件,这种情况甚至不需要“长会话”,一次调用就能把窗口刺穿。
所以,上下文压缩在这里不是一个动作,而是一组判断:
• 哪些信息可以直接删。 • 哪些信息只能裁剪,不能完全清掉。 • 哪些信息可以摘要,但摘要后还得补回关键结构。 • 哪些信息绝对不能丢,一旦丢了,系统行为就会漂。
更贴近工程的说法是,OpenClaw 管的不是“字数”,而是上下文里的信息等级。
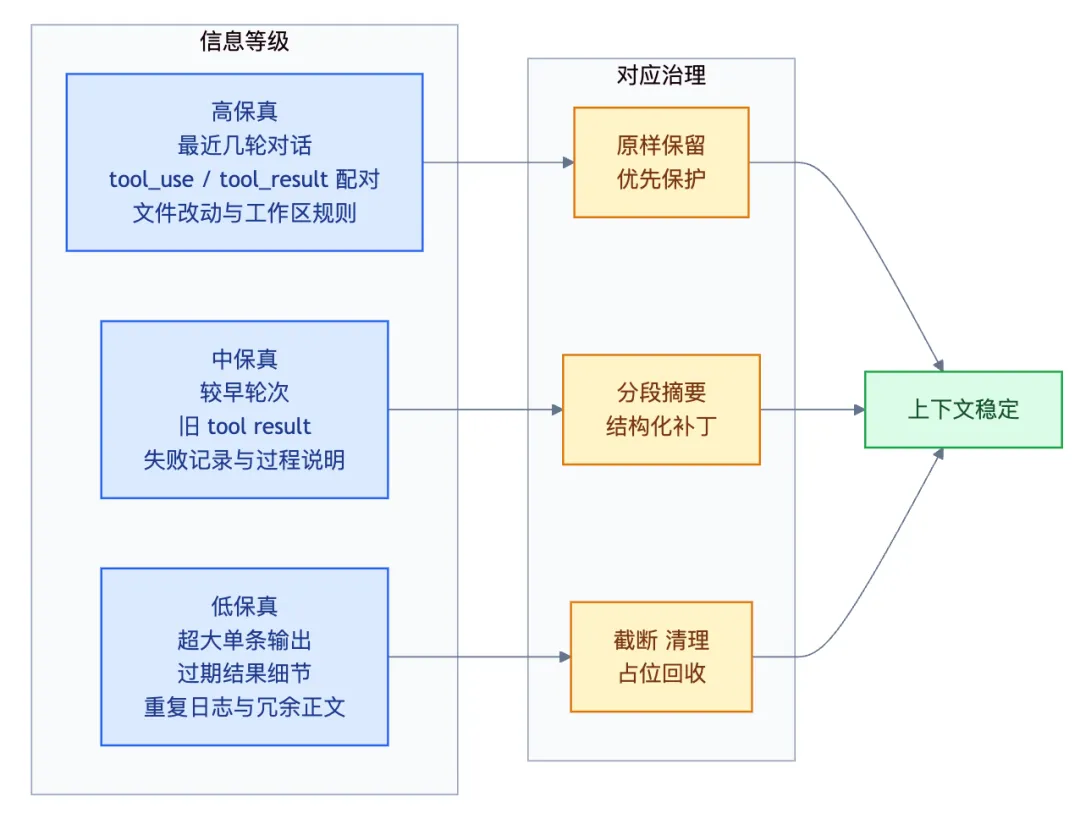
第一层先少删错,再谈压缩
OpenClaw 的第一层防线发生在真正调用 LLM 之前。它的目标不是“压到最小”,而是先把明显冗余的部分减掉,让会话尽可能不走到昂贵的摘要流程。
实现页里把这一步叫 window guard。意思很直接:如果窗口已经低于安全下限,系统会在昂贵的 attempt 之前先拦下明显会炸的调用。
1. 历史轮次限制:先从最粗粒度下手
最简单的一层叫 History Turn Limit。
它的做法不复杂:从消息尾部往前数,只保留最近 N 轮用户消息及其后续链路。这里最关键的细节不是“限制轮次”本身,而是截断点落在完整的 user turn 边界上。换句话说,它不会把一组 user -> assistant -> tool_result 拦腰切开,避免会话结构被剪碎。
这件事看起来朴素,但很重要。Agent 系统最怕的不是删得多,而是删得乱。
2. Context Pruning:真正的大头,是旧 tool result
OpenClaw 更有意思的设计在 Context Pruning。它假设一个事实:长会话里最容易失控的不是聊天,而是历史工具结果。
所以它不是泛化地修剪所有消息,而是专门盯着“旧的、可修剪的 tool result”下手。
默认策略分两档:
softTrimRatio: 0.3) | ... 并附加原始大小注释 | ||
hardClearRatio: 0.5) | [Old tool result content cleared] |
这里还有三个很像“架构师会盯”的保护规则。
第一,第一条 user 消息之前的工具结果不修剪。因为这部分常常包含启动时读进来的身份文件、工作区说明或项目规则。把这些删掉,Agent 很可能连“自己现在在哪个项目、要遵守什么约束”都忘了。
第二,最近几条 assistant 关联的 tool result 不动,默认保护最近 3 条 assistant 消息附近的工具结果。原因很直接,最近动作是 Agent 当前决策最依赖的短期记忆。
第三,图片类结果不动,并且支持工具白名单和黑名单。也就是说,OpenClaw 不是按“消息类型”一刀切,而是按“内容形态 + 工具种类 + 距离当前决策的远近”做选择。
还有一个容易被忽略、但很工程化的点:这套 pruning 默认带 5 分钟 TTL(mode: "cache-ttl")。文档里明确提到,这类 pruning 仅对 Anthropic API 调用(和 OpenRouter Anthropic 模型)生效,并建议把 ttl 与模型的 cacheRetention 对齐。其背后的经济学逻辑是:Anthropic 的提示缓存仅在 TTL 内适用,如果会话空闲超过 TTL,下一个请求会重新缓存完整提示。剪枝在 TTL 过期后先修剪会话,然后重置缓存窗口,使后续请求可以复用新缓存的上下文,而不是对完整历史重新缓存——这能显著降低 cacheWrite 成本。5 分钟内不重复修剪,本质上是在兼顾上下文瘦身和 prompt cache 经济性。
3. 单条 tool result 截断:防止一条结果直接刺穿窗口
除了“很多旧结果累积太大”,OpenClaw 还单独处理“某一条结果本身巨大”的场景。
它给单条 tool result 设了一条硬边界:最多只能占上下文窗口的 30%,并且还有一个绝对上限 400000 字符。超过后会截断,并在末尾明确告诉模型:这里只是部分内容,如果需要更多,请按 offset 或 limit 继续读取。
这其实是在给工具调用建立一条系统约束:工具可以返回大结果,但不能直接霸占会话。
放在 Agent 里,这比看上去重要得多。因为工具世界和对话世界的体量不是一个数量级,不加这条边界,模型很容易被某一次“读太多”拖死。
一张图看懂 OpenClaw 的压缩链路
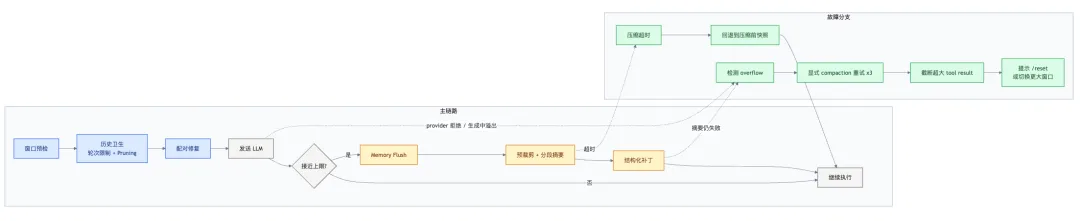
从这张图就能看出来,OpenClaw 的顺序很明确:轻量裁剪优先,摘要其次,暴力截断兜底。
第二层才是 Compaction,但它不是“一把梭”
很多系统做到这里就结束了:上下文快满了,启动一个“summary prompt”,把前文扔进去,让模型总结后替换掉历史。
OpenClaw 走得更远。它把 Compaction 做成了一条单独的治理流水线。
0. 压缩前先做一件事:记忆刷新(Memory Flush)
这是一个很容易被忽略但极有价值的设计。OpenClaw 在自动压缩之前,会先触发一个静默的记忆刷新回合(memoryFlush),提醒模型将持久状态写入磁盘(例如写到 memory/YYYY-MM-DD.md),这样压缩就不会擦除关键上下文。
触发条件是软阈值:当会话 token 估计超过 contextWindow - reserveTokensFloor - softThresholdTokens(默认 softThresholdTokens: 4000)时运行。这个回合使用 NO_REPLY 抑制输出,用户完全看不到。每个压缩周期只刷新一次,且仅在工作区可写时运行。
这意味着 OpenClaw 的记忆不只是"上下文里的临时信息",而是有一条上下文 → 磁盘的主动持久化路径。压缩可能丢细节,但磁盘上的记忆文件不会被压缩覆盖。
1. 触发前,先收集 Agent 后面还会用到的事实
Compaction 不只是生成一段摘要,它会先收集几类后续决策很需要的信息:
• 读过哪些文件 • 改过哪些文件 • 最近有哪些工具失败 • 当前工作区必须遵守的关键规则
这一点很关键。因为长任务里最容易丢的,往往不是“聊了什么”,而是“已经做了什么、踩过什么坑、项目有哪条红线不能碰”。
如果压缩之后这些信息消失了,Agent 很容易重复读文件、重复踩失败命令,或者把工作区约束忘掉。
2. 真正做摘要前,还会先做一轮历史预裁剪
如果待压缩内容本身已经太大,OpenClaw 不会硬把全部历史塞进摘要模型,而是先做 pruneHistoryForContextShare。
它会按 token 份额把旧消息切成若干 chunk,先丢掉最老的一块,再把被丢掉的部分单独摘要成 droppedSummary,然后把这段摘要带入下一轮主压缩流程。
这个做法的意义在于,摘要流程自己也有上下文窗口。如果你不先控制摘要输入,压缩调用本身就可能溢出。
这里还有一个必须单独点出来的细节:每次丢弃旧 chunk 之后,OpenClaw 还会修复 tool_use 和 tool_result 的配对关系。实现说明里把这件事放得很靠前,因为 Anthropic 这类接口会严格检查两者是否成对出现,一旦你把前面的 tool_use 删掉、后面的 tool_result 留在历史里,请求会直接 400 报错。OpenClaw 的 Transcript Hygiene 模块会按提供商策略自动处理:Anthropic 做配对修复并合成缺失的工具结果,Google 还额外做工具调用 id 的严格字母数字清理和轮次重排序。深入解析页把执行顺序写得很明确:先清洗与校验 → 再做 turn 限额 → 最后修复配对。很多人以为“摘要失败”是模型问题,实际上会话结构先坏了。
3. 大历史不做一次摘要,而是分段摘要再合并
OpenClaw 在 summarizeInStages 里做的是分而治之。
简单说就是三步:
1. 把消息按 token 份额拆成多个 chunk。 2. 逐段摘要,每段单独调用模型。 3. 如果得到多个 partial summaries,再做一次“摘要的摘要”合并成最终版本。
这套逻辑的价值不在“聪明”,在稳定。
因为摘要模型也有窗口上限,大历史如果只做单次摘要,失败是迟早的事。分段之后,单次失败的爆炸半径小得多,也更容易重试。
4. chunk 大小不是写死的,而会根据消息体积自适应
OpenClaw 没把 chunk ratio 固定死,而是看“平均消息有多大”再动态缩小比例。
默认基准是每块不超过上下文窗口的 40%,如果平均消息体积已经很大,就一路缩到 15% 左右。再加上一个 1.2 的安全系数,去覆盖 chars / 4 这种粗估 token 方法带来的偏差。
这背后的工程判断很明确:宁可多切几段,也别让摘要调用本身变成新的超限来源。
5. 超大消息有三级降级,不让一次失败拖垮整个压缩
OpenClaw 的 summarizeWithFallback 还有一个很值得抄的设计,就是它没把“摘要失败”当成一次致命错误,而是准备了三级降级路径:
• 第一级,正常尝试全量摘要。 • 第二级,如果失败,先把单条超大的消息剔出去,只摘要剩余部分,并在结果里标明有大消息被省略。 • 第三级,如果还是不行,至少返回一个兜底说明,告诉系统这轮上下文过大、摘要不可用。
这意味着 compaction 即便做不到“高质量摘要”,也尽量做到“返回一个不会让系统崩掉的结果”。
6. 摘要输出不是纯自然语言,而是带结构化补丁
OpenClaw 最后产出的 summary,除了概括历史,还会补回几段结构化状态。
它会在摘要后补上结构化内容,例如:
• Tool Failures• <read-files>• <modified-files>• <workspace-critical-rules>
这件事为什么值钱?
因为 Agent 后续决策依赖的不只是语义理解,还依赖状态延续。自然语言摘要很容易把“失败过三次 bash 命令”和“这个文件已经改过”压成一句模糊的描述,但结构化补丁可以把这些高价值状态直接钉住。
说得直白一点,OpenClaw 压的不是“会话事实”,压的是“冗余表述”。
7. 安全上也做了隔离,避免把脏内容喂回摘要模型
Compaction 还专门避开了 toolResult.details 这类不可信字段,不让这些潜在的外部 payload 直接进入摘要 prompt。
这是个非常典型的 Agent 安全问题。工具返回的数据本来就可能夹带恶意内容,如果你在压缩阶段把这些内容原封不动送进模型,相当于给了二次 prompt injection 一条高速通道。
OpenClaw 这里的选择很稳:不可信的细节,不参与摘要。
8. 记忆不只是上下文,还有磁盘持久化 + 向量搜索
这是文档里一个很容易被忽略但极有价值的设计。OpenClaw 的记忆系统是智能体工作空间中的纯 Markdown 文件,而不是只存在于上下文窗口里的临时信息。
默认布局使用两个记忆层:
• memory/YYYY-MM-DD.md:每日日志(仅追加),在会话开始时读取今天和昨天的内容• MEMORY.md(可选):精心整理的长期记忆,仅在主要的私人会话中加载
更进一步,OpenClaw 还支持向量记忆搜索:在记忆文件上构建小型向量索引,让语义查询可以找到相关笔记,即使措辞不同。默认启用混合搜索(BM25 + 向量),既能处理"这意味着同一件事"的语义匹配,也能精确命中 ID、代码符号、错误字符串这类高信号 token。
这意味着 OpenClaw 的记忆不只是"上下文里的临时信息",而是有一条上下文 → 磁盘 → 向量索引的完整持久化路径。压缩可能丢细节,但磁盘上的记忆文件不会被压缩覆盖,而且还能被语义检索。
第三层把“溢出”当成正常故障路径
真正成熟的系统,不会假设前两层一定成功。
OpenClaw 的第三层设计,恰恰说明它把 context overflow 视为一种正常会发生的运行时错误,而不是必须靠人工接管的意外。
1. 先判断是不是上下文溢出
它会识别两类典型信号:
• prompt 在提交阶段就被 provider 拒绝(请求前溢出) • assistant 生成过程中返回上下文过长错误(请求中溢出)
也就是说,它不只盯 API 的一种报错形式,而是从请求前和请求中两端去识别 overflow。
2. 溢出后不是立刻重置,而是按顺序兜底
实现页把恢复顺序写得很直白:compact -> truncate -> readable error。
默认恢复顺序大致是这样的:
1. 如果本轮已经触发过 SDK 自动 compaction,先直接重试,避免重复压缩。 2. 如果还没做过显式 compaction,就以 overflow触发一次专门的压缩。3. 显式 compaction 最多尝试 3 次。 4. 如果仍然失败,再检查会话里是不是有超大 tool result。 5. 如果有,就对 session 做持久级截断。 6. 所有手段都用尽后,才提示用户 /reset或切换更大窗口模型。
这个顺序很自然。它尽量把“保留会话连续性”放在前面,把“让用户重开一局”放在最后。
3. 压缩超时也要回到干净快照
这是文档里一个很容易被忽略,但很能体现工程成熟度的点。
压缩过程中如果超时,OpenClaw 优先回到压缩前快照,而不是把一份半压缩、半旧状态的 transcript 暴露出来。文档里把这件事叫 snapshot 兜底。实现上,订阅层需要显式暴露 waitForCompactionRetry 语义——"压缩中超时"要能选到可用快照,而不是把半压缩状态返回给用户。
它解决的是一种很真实的线上问题:失败并不可怕,脏状态才可怕。深入解析页的验收清单里甚至专门列了一条:"压缩中超时仍能返回一致快照,而不是空响应或脏状态"。
4. 持久级截断不是原地改历史,而是 branching 重写
这里还有个我很喜欢的细节。
OpenClaw 对持久级 tool result 截断,不是直接去改旧 session entry,而是从那个节点的父位置拉一个新分支,再把后续 entry 重新追加到新分支上,只在需要的地方替换成截断结果。
这保住了 session 的 append-only 语义,也让历史修改可追溯。
你可以把它理解成 Git 的思路:不是重写原地事实,而是从旧状态分叉出一个更安全的新版本。
对 Agent 系统来说,这比“直接改 JSON 文件”高级太多了。因为一旦你开始频繁原地篡改历史,会话的可审计性和问题复盘能力会迅速变差。
这套方案真正值钱的,是 4 个工程判断
看完具体实现,再往上提一层,我觉得 OpenClaw 这套压缩设计里更有参考价值的,是下面 4 个判断。
1. 渐进式降级,比一把梭摘要稳得多
先限制轮次,再修剪旧工具结果,再限制单条结果,再做 compaction,最后才进入持久级截断和人工重置。
这是一条典型的分层治理链路。轻量操作优先,重操作后置,越往后代价越高、侵入性越强。
一上来就做摘要,最大的问题不是贵,而是你会太早把“可恢复的原始信息”变成“不可逆的二手信息”。
2. 真正该保护的是不变量,不是原文逐字保留
OpenClaw 并不执着于“每一条消息都完整保留”,但它很执着于几类不变量:
• 最近短期记忆不能乱 • tool_use 和 tool_result 的配对不能乱 • 文件读写历史不能丢 • 工具失败记录不能丢 • 工作区关键规则不能丢
这就是工程系统和普通聊天总结的差别。前者保护运行正确性,后者往往只保护阅读流畅度。
3. 压缩和 Provider Cache 要一起设计
配置稿和文档站里还有一个很容易被忽略的点:OpenClaw 默认把 pruning 的 TTL 设成 5 分钟,这和 Anthropic 的 cacheRetention: "short" 周期是对齐的。OpenClaw 甚至支持通过 Heartbeat 保温机制(heartbeat.every: "55m")在闲置间隙让缓存保持"温热",避免对完整提示词重新缓存。
意思是,在 provider 侧的 prompt cache 还活着的时候,它尽量不去频繁改写历史,避免把原本可以 cacheRead 的前缀白白打碎。等 cache 自然过期,再做 pruning,成本更可控。对于 Anthropic,cacheRead 比普通 input tokens 便宜得多,而 cacheWrite 会以更高倍率计费。
这件事很说明问题。真正的上下文治理,从来不只是“怎么压缩”,还包括怎么和模型服务商的缓存、计费和延迟机制一起算账。
4. 摘要失败时取消,不硬着头皮写入坏结果
OpenClaw 在 compaction 上有一条很克制的策略:如果 API key 缺失、摘要抛错、流程异常,就直接 cancel,保留原始历史,而不是强行塞进一段质量不可控的 summary。
这其实是在贯彻一个很成熟的运行原则:坏摘要比没摘要更危险。
没摘要,顶多进入下一层 overflow 恢复。坏摘要一旦写进会话,系统接下来的每一步都会建立在错误记忆之上。
如果你今天就想抄,我会先抄这 6 个点
如果你也在做自己的 Agent,我建议先别急着优化 prompt,先把下面这 6 个点补齐:
1. 把上下文问题拆开看,至少区分“旧轮次”“旧工具结果”“单条超大结果”三类。 2. 给旧 tool result 做渐进式 trimming,不要一满就直接整段清空。 3. 给最近几轮短期记忆设保护区,别为了省 token 把当前决策依据一起删了。 4. Compaction 输出别只有摘要正文,至少补回失败记录、文件读写痕迹和工作区规则。 5. 对 overflow 设计一条明确恢复链路,不要只会报错让用户重来。 6. 如果要持久化改历史,用 branch 或版本化思路,不要原地覆盖旧会话。
再进一步,如果你正在实际配置 OpenClaw,通常可以先看这几个参数:
agents.defaults.contextTokens | 200000 | |
agents.defaults.compaction.mode | "default" | "default""safeguard" 只在接近上限时才压缩 |
agents.defaults.compaction.reserveTokens | 20000 | |
agents.defaults.compaction.keepRecentTokens | 40000 | |
agents.defaults.contextPruning.mode | "cache-ttl" | |
agents.defaults.contextPruning.ttl | "5m" | |
agents.defaults.contextPruning.softTrimRatio | 0.3 | |
agents.defaults.contextPruning.hardClearRatio | 0.5 |
参数值不是越大越好,关键是要和你的模型窗口、Provider 缓存周期、任务类型一起看。你可以随时用 /status 查看当前会话的上下文使用情况,用 /usage tokens 追踪每次回复的 token 消耗。
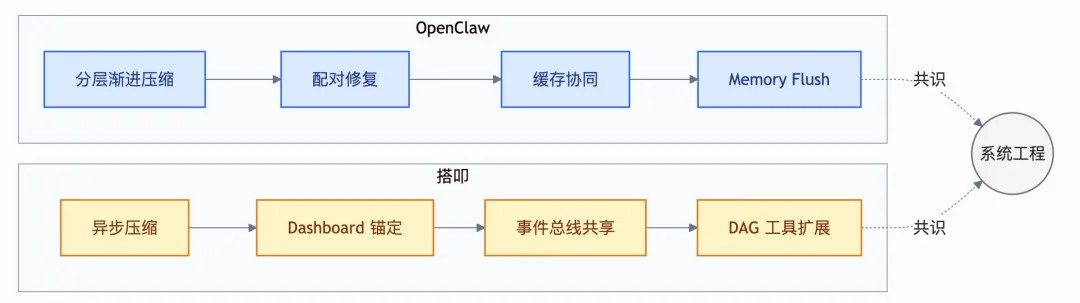
横向对比:OpenClaw vs 搭叩的上下文管理
最近搭叩(Dakou)也发了一篇上下文管理的深度文章,提出了七大策略(压缩、替换、保留、锚定、合并、共享、动态扩展)。两套系统在理念上有很多共鸣,但侧重点不同。
| 压缩触发 | ||
| 摘要策略 | summarizeInStages),带三级降级 | |
| 结构化保真 | ||
| 配对修复 | ||
| 溢出恢复 | ||
| 缓存协同 | ||
| 记忆持久化 | ||
| 多 Agent | ||
| 工具管理 |
两者最大的共识是:上下文管理不是一个功能点,而是一个系统工程。搭叩的 Dashboard + 锚定思路很有参考价值,OpenClaw 的分层降级 + 配对修复 + 缓存协同则在工程稳定性上走得更远。
写在最后
对 Agent 来说,上下文窗口从来不是“多给一点 token 就万事大吉”的问题。
你真正要管理的,是哪些信息必须保真,哪些信息允许有损压缩,哪些信息一旦失败必须还能恢复。
OpenClaw 这套实现最有参考价值的地方,恰恰在这里。它把“上下文压缩”从一个 prompt 技巧,做成了一种系统能力。
如果你也在做自己的 Agent,这套设计里最有参考价值的,还是那条主线:先把窗口守住,再把历史整理干净,最后给溢出准备一条稳定的恢复路径。很多长上下文问题,最后其实都是治理问题。
参考文档
[1] 上下文: https://openclawcn.com/zh-cn/docs/concepts/context/[2] 压缩与 Compaction: https://openclawcn.com/zh-cn/docs/concepts/compaction/[3] 会话修剪: https://openclawcn.com/zh-cn/docs/concepts/session-pruning/[4] 对话记录清理: https://openclawcn.com/zh-cn/docs/reference/transcript-hygiene/[5] 会话管理深入了解: https://openclawcn.com/zh-cn/docs/reference/session-management-compaction/[6] 上下文工程: https://openclawcn.com/zh-cn/docs/deep-dive/framework-focus/context-engineering/[7] 上下文管理实战: https://openclawcn.com/zh-cn/docs/deep-dive/framework-focus/context-management-implementation/[8] 记忆系统: https://openclawcn.com/zh-cn/docs/concepts/memory/[9] Prompt Caching: https://openclawcn.com/zh-cn/docs/reference/prompt-caching/
延伸阅读
Anthropic 发布 2026 Agentic Coding 趋势报告:八大趋势与 4 个优先级深度解读
如喜欢本文,请点击右上角,把文章分享到朋友圈如有想了解学习的技术点,请留言给若飞安排分享
因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享
·END·
相关阅读:
Claude Code 最佳实践:把上下文变成生产力(团队可落地版) 把 AI 当成新同事:Agent Coding 的上下文与验证体系 Skill 到底是什么:从第一性原理深入剖析 Claude Agent Skills 把 Claude Code 用成工程工具:8 条黄金法则与一套可复用工作流 Anthropic 官方 33 页指南拆解: 构建Skills的最佳实践 2026 开年这篇综述,把高效 Agents 讲得很工程(附落地清单) AI编程实践:从 Claude Code 到团队协作的 6 个落地抓手
Anthropic 发布 2026 Agentic Coding 趋势报告:八大趋势与 4 个优先级深度解读
Claude Agent Teams 架构与实战拆解
Claude Code 创始人亲授:10 条进阶秘籍(附 12 条工作流 Prompt 清单)
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
我们都是架构师!

关注架构师(JiaGouX),添加“星标”
获取每天技术干货,一起成为牛逼架构师
技术群请加若飞:1321113940 进架构师群
投稿、合作、版权等邮箱:admin@137x.com
