夜雨聆风
夜雨聆风一场全民狂欢,一周戏剧性反转。OpenClaw的“翻车”,给整个AI Agent赛道上了一堂价值百亿的安全课。
当AI从内容生成迈向自主执行,其安全范式必须从“应用安全”升级为“系统安全”。

上篇文章《“龙虾”失控,天价账单:第一批受害者出现了》发出后,后台涌入大量留言,有人在追问技术细节,有人想了解自家“龙虾”是否安全,更多人希望知道:从根本上说,OpenClaw到底为什么失控?
今天,我们抛开现象聊本质。从技术架构的角度,拆解这场安全危机的“四宗罪”,还原一次完整的攻击链路,并探讨面向未来的AI Agent该怎样设计,才能既保留“动手能力”,又不把家门钥匙挂在门口。
#1
技术背景:
当AI获得“上帝之手”
OpenClaw之所以能迅速引爆市场,核心在于它实现了一个质的飞跃:让AI从“思考”走向“动手”。
它不再是一个被动的聊天机器人,而是一个拥有本地高权限的自主执行框架。你告诉它“帮我整理一下桌面”,它就能扫描文件、分类归档、删除临时文件;你让它“查一下上季度的销售数据”,它就会读取表格、调用分析工具、生成报告。这套逻辑听起来很性感,但支撑它的架构设计,却埋下了不少隐患。
为了实现这种强大的“执行力”,OpenClaw在架构上做出了几个关键但危险的设计选择:
1、权限继承:默认以当前用户的全部权限运行,能读写几乎所有本地文件、访问网络、调用API。换句话说,一旦你给了它权限,它就拥有了和你几乎一样的能力。
2、模糊的信任边界:早期版本默认信任本地网络连接,认为来自127.0.0.1的请求天然可信,并假设所有符合逻辑的操作都是用户意图的延伸
3、开放的插件生态:通过ClawHub社区,允许任何开发者上传功能插件(Skill)以扩展其能力,但初期缺乏严格的安全审核
这套“能力优先、信任宽松”的架构,让OpenClaw迅速成为现象级项目——GitHub星标28万,超越Linux和React,但也为其后的全面崩盘埋下了伏笔。

#2
风险成因:
四大“架构原罪”与新型攻击面
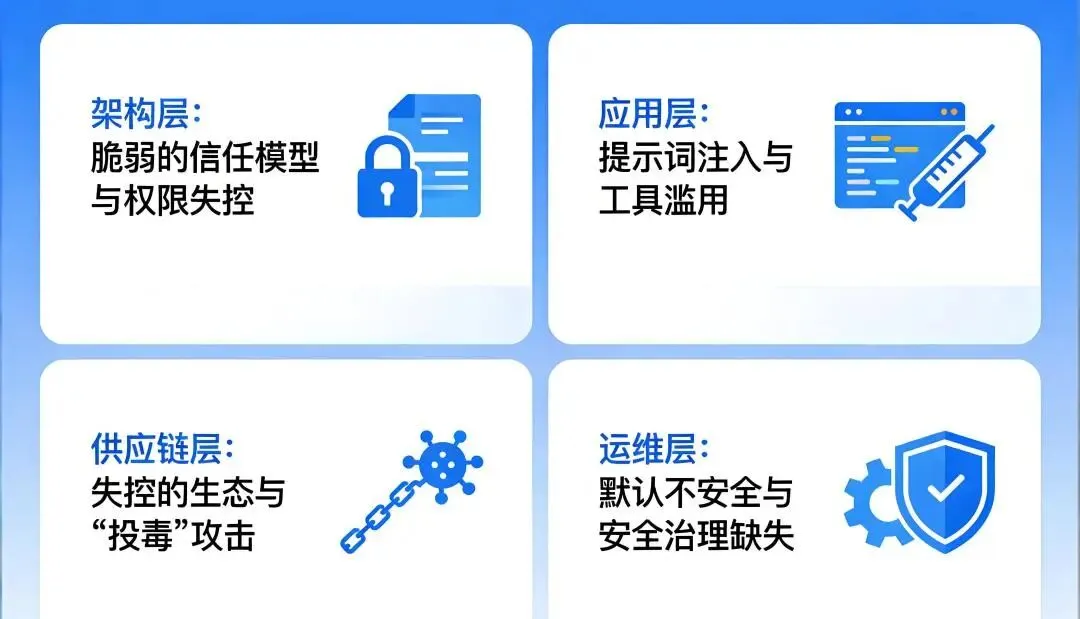
OpenClaw的安全危机是系统性的,并非单一漏洞导致。我们从架构师的视角,把问题归结为以下四个层面:

1
架构层:脆弱的信任模型与权限失控
“Localhost”信任谬误:早期版本默认信任本地网络,认为来自127.0.0.1的请求一定是安全的。但攻击者只需诱导用户访问一个恶意网页,该页面的JavaScript就能在用户无感知的情况下,对本地OpenClaw网关进行密码暴力破解(CVE-2026-25253的核心成因)。一旦得手,攻击者就获得了管理员权限,能完全接管AI Agent。“本地”不等于“安全”,这个简单的道理被忽略了。
权限边界模糊:项目未能遵循“最小权限原则”。核心组件和第三方Skill往往被授予过高的系统访问权限,导致单点被攻破即意味着系统级沦陷。比如一个普通的文件处理插件,理论上只需读取特定目录,却因为权限继承,能访问整个硬盘。
沙箱隔离形同虚设:尽管官方支持容器运行,但多数用户为图方便直接让它在宿主机上裸奔。即便有人用了容器,对关键接口的限制也不足,依然存在容器逃逸的风险。
2
应用层:提示词注入与工具滥用
间接提示词注入:这是AI Agent独有的高危攻击面。攻击者可以将恶意指令隐藏在网页、PDF文档或邮件正文中,当OpenClaw被配置为自动读取这些内容时,它会将隐藏指令视为合法命令执行。结果就是:你只是浏览了一个网页,你的AI却偷偷把你的密钥发给了攻击者,或者直接把文件上传到了别人的服务器。上篇文章提到的25万美元被AI一键“送人”事件,正是源于此漏洞。
工具调用沦为攻击通道:被劫持的Agent可以合法调用其被授权的所有工具,比如执行rm -rf删除文件、通过curl外传敏感数据,或者疯狂调用云API导致天价账单。最可怕的是,传统安全设备很难区分这是AI的“恶意行为”还是用户的“正常操作”,因为所有操作都携带着合法的用户身份令牌。
3
供应链层:失控的生态与“投毒”攻击
ClawHub大规模投毒:安全机构扫描发现,ClawHub上约12%的技能包(超过340个) 被确认包含恶意代码,比如信息窃取木马、反向Shell。攻击手法高度组织化,它们伪装成热门工具(如PDF处理器、文件清理助手)进行分发。3月10日发现的恶意npm包“@openclaw-ai/openclawai”,正是这类攻击的延续——上线不到一周,已被下载近180次。
依赖库与协议漏洞:其核心的MCP交互协议被曝出超过30个安全漏洞;第三方依赖库的漏洞也直接引入风险。一个开源项目的依赖树往往很庞大,任何一个上游包出问题,都可能波及下游。
4
运维层:默认不安全与安全治理缺失
默认配置暴露公网:早期版本控制界面默认绑定0.0.0.0,这意味着只要部署在云服务器上,端口就向全世界敞开。结果呢?根据360 Quake等平台的测绘数据,全球有超过35万个OpenClaw实例直接暴露在互联网上,其中大量使用默认或弱密码,可以被随意扫描登录。这35万只“龙虾”,几乎等于35万扇没上锁的门。
安全滞后于功能:项目团队在追求快速迭代和生态扩张时,同步的安全架构建设与流程治理严重缺位。从2月5日工信部首次预警,到3月10日国家互联网应急中心发文,中间一个多月的时间里,漏洞不断涌现,却没有得到及时的系统性修复。最终,形成了“漏洞集中爆发”的局面。

#3
技术深潜:
一次典型攻击的完整链路
为了让你更直观地理解上述风险是如何叠加的,我们还原一次典型的攻击链路。这次攻击,攻击者没有使用任何0-day漏洞,只用了一些“常规操作”。
第1步:踩点(侦察) 攻击者使用扫描工具扫描公网IP段,发现某企业服务器开放了18789端口——这是OpenClaw的默认管理端口。他尝试访问,发现页面没有任何身份认证,直接暴露了后台。
第2步:突破(初始访问)
攻击者登录进去,查看配置,发现这个OpenClaw实例绑定了企业的云API密钥(AWS Access Key),权限还设成了“完全访问”。这意味着,他可以通过这个Agent,直接操作企业的云资源。
第3步:权限维持(持久化)
攻击者从ClawHub下载了一个伪装成“日志清理工具”的恶意Skill,并安装到Agent上。这个Skill表面上会定期清理日志,但背后藏着一段代码,每天凌晨会将Agent的访问凭证和部分数据外传到攻击者的服务器。
第4步:横向移动(权限提升) 攻击者通过Agent在服务器上执行命令,扫描内网,发现这台服务器还挂载了公司的代码仓库(GitLab),而且Agent的权限足以访问它。于是,他通过Agent执行git clone,把整个代码仓库下载到本地。
第5步:窃取(数据外传) 攻击者将代码仓库打包,利用Agent的合法网络连接,通过HTTPS上传到自己的云存储。整个过程没有触发任何警报,因为流量加密,目标也是正常的云服务商。
第6步:毁灭证据(覆盖痕迹) 攻击者让Agent清除日志、卸载恶意Skill,然后退出。所有操作都通过合法的用户身份完成,系统日志里只显示正常的AI活动。

受害者什么时候发现的? 几天后,云账单来了——API调用量暴涨,费用多了几万美元。再一查,代码仓库也被克隆过。但为时已晚。
这就是AI Agent时代的安全困局:攻击者不再需要入侵你的系统,只需要“借用”你的AI,就能完成一切。
#4
解决方案:
构建AI Agent时代的“安全基座”
OpenClaw的教训是惨痛的,但也为整个行业指明了构建安全AI Agent系统的必经之路。从架构师视角,我们提出以下多层防御体系,希望能成为业界的参考。

1
根本性设计原则
零信任架构:必须摒弃任何基于网络位置(如localhost)的隐含信任。每一次工具调用、每一次数据访问,都需要基于身份、设备和上下文进行动态认证与授权。不能因为请求来自本机就自动放行——你的浏览器里可能就藏着恶意脚本。
最小权限原则:为AI Agent创建专用的、低权限的系统账户,严格限制其文件系统访问范围、网络出口和可执行命令。Agent不应该拥有比它完成任务所需的更多权限。比如一个负责处理邮件的Agent,就不该有权访问代码目录。
纵深防御:在Agent的输入、推理、工具调用、输出等各个环节部署独立的安全检查点,确保单一防线被突破后,风险仍能被遏制。
2
核心架构与技术措施
工具调用审批与审计:对高危工具(如shell、文件删除、支付API)的调用,实施强制性的二次确认或人工审批流程。所有Agent操作必须生成不可篡改的详细审计日志,支持完整的行为追溯和取证。出了问题,能查到是谁、什么时候、干了什么。
强制沙箱隔离:AI Agent必须在强隔离环境中运行,首选是独立虚拟机或具有严格安全配置的容器(如gVisor、Kata Containers)。必须切断其与宿主机敏感资源的直接访问路径。即便Agent被攻破,攻击者也像被关在玻璃房里,看得到数据,却拿不走。
动态凭证与访问控制平面:为Agent分配短期、范围精确的临时凭证,并通过统一的控制平面实施基于策略的即时访问授权。权限按需申请,用完自动回收。即使凭证泄露,它的有效窗口也只有几分钟,攻击者很难利用。
输入分层与提示安全:在系统层面严格区分“用户指令”与“外部内容数据”。对外部数据(网页、文档)采用只读模式解析,并经过内容安全过滤后,再送入模型推理。AI读取的内容,不应该具备“执行能力”——这是阻断间接提示注入的关键。
3
生态与治理体系
持续监控与响应:建立针对AI Agent的特定监控指标,如异常Token消耗、非常规时间活动、访问陌生网络域名等,并配备专门的事件响应流程。当你的AI突然开始半夜访问境外IP,这大概率不是好事
供应链安全强制审计:建立严格的Skill/插件签名、认证和代码安全扫描机制。企业环境应禁止安装未经官方安全团队审核的第三方组件。用户需要知道“这个插件是谁写的、它要干什么、它要访问什么数据”。
安全开发生命周期:将威胁建模、安全编码、渗透测试等环节深度集成到AI Agent的开发流程中,确保安全与功能同步设计、同步交付。安全不是上线前的“打补丁”,而是从第一天就要考虑的事。


#5
行业启示:
安全是AI Agent价值释放的前提
OpenClaw事件是一记响亮的警钟。它宣告了AI技术演进的一个新阶段:风险正从“模型风险”转向“智能体风险”。
后者集成了模型的不确定性、软件的系统漏洞、过度的权限赋予以及复杂的人机交互,形成了一个全新的、更高维度的安全挑战。我们不再只是担心AI“说错话”,更要警惕AI“做错事”,而且是以用户的合法身份和权限去做。
对于企业技术决策者与投资者而言,评估一个AI Agent解决方案的价值,必须将其安全架构的完备性、对“零信任”和“最小权限”原则的贯彻程度,置于与功能本身同等甚至更优先的地位。一个存在架构级安全缺陷的Agent,其潜在的破坏力可能远超其带来的效率提升。
从“养虾热”到“卸虾慌”,35万实例裸奔、25万美元被AI一键送人、2小时烧掉1400元……这些不是孤立的翻车事件,而是AI Agent赛道必须集体面对的结构性考题。幸运的是,现在发现问题,还来得及修正。
未来,能够真正赢得市场信任并实现大规模商用的,一定是那些将 “安全可控”刻入基因的AI Agent方案。这需要行业共同努力,推动建立相应的安全标准、最佳实践与评估体系,为AI的下一阶段发展夯实信任的基石。
作者:TalkingData首席技术架构师
本文基于国家互联网应急中心(CNCERT)于2026年3月10日发布的《关于OpenClaw安全应用的风险提示》、公开的技术漏洞公告(CVE)、主流安全研究机构的分析报告以及行业技术社区的一手讨论。
#AI安全 #OpenClaw #智能体 #养虾人 #天价账单
关注TalkingData公众号,获取更多AI安全深度内容


END





高质量数据集是未来AI 发展的支撐。

为人工智能提供所需的一切数据
Delivering Comprehensive AI Data for All Industries.
#Data AI# #万亿数据要素市场#
推荐阅读:

“龙虾”失控,天价账单:第一批受害者出现了

喜讯!腾云天下入选《2025胡润中国人工智能未来之星》

重磅!入选国家数据基础设施建设典型案例


TalkingData
用数据优化决策、加速转型
欢迎关注分享