 夜雨聆风
夜雨聆风
一、引言
1.1 从「打字聊天」到「开口说话」
养虾第一阶段,大家多半是用文字和龙虾打交道:你打字,它回字。用久了自然会想:要是它能像人一样听得懂我说的话,再用声音回我一句,该多好。眼睛不用盯着屏幕,手上忙别的也能问一句「今天日程有啥」,这才是和 AI Agent 更自然、更接近真人的交互方式。
1.2 不止「能说」:多角色、有性格、有陪伴
一旦上了语音,玩法就多了。
多 Agent 场景:你可以给不同角色配不同音色,比如运营用女声、客服用男声、代码助手用另一种腔调。用户不用看屏幕,光听声音就能分辨「现在是谁在说话」,多任务并行时效率会高很多。
人格感:给某只龙虾固定一个你喜欢的音色,它在心理上会更像「一个具体的人」,而不是一串文字。互动会更有趣,也更容易投入。
情感陪伴与娱乐:睡前听它念一段、开车时和它聊几句,语音把 Agent 从「工具」往「伙伴」那边推了一步。
今天我们就从 OpenClaw 的语音入口(STT)和出口(TTS)怎么接、怎么配,一路说到配置技巧和进阶方向。
二、语音在 OpenClaw 里的位置:整体流程
OpenClaw 里,听和说是两条线,在架构里各占一块。
- 语音输入(STT/ASR)
:用户发来的语音消息或附件里的音频,先被转成文字(转录),再把这串文字当「用户说的一句话」喂给 Agent。配置在 tools.media.audio,包括用哪个模型/服务转写、大小限制、是否把转录结果回显到聊天里等。 - 语音输出(TTS)
:Agent 的回复(或其中一段)被转成音频,再通过渠道发出去,比如 Telegram 的语音气泡。配置在 messages.tts,包括用哪个 TTS 服务、默认音色、是否自动把每条回复都读出来等。
流程可以简化为:
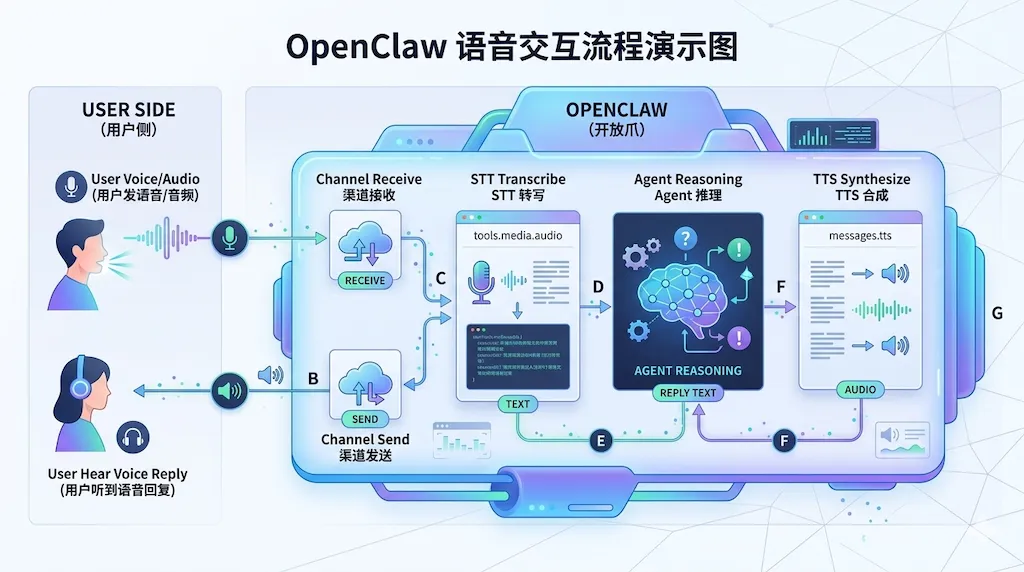
三、TTS:让小龙虾「会讲话」
3.1 方案大致分两类
本地方案(不依赖云、不花 API 钱):
- Edge TTS
:用微软 Edge 的在线神经 TTS,通过 node-edge-tts调用,不需要 API Key,音质不错。适合入门、不想折腾密钥的人。 - mlx-audio
:Apple Silicon 上跑的本地 TTS,延迟低,隐私好,适合 Mac 用户想完全本地的场景。 - mac-tts
:基于系统 say命令,零配置,音色和效果比较基础,适合「能出声就行」的快速验证。
云端方案(按量付费、音色多、效果稳定):
腾讯云、阿里云、AWS 等都有 TTS 能力;不少用户反馈腾讯云 TTS 价格便宜,国内接入也方便。阿里、AWS 类似,按需选。
第一次玩语音回复,建议先用 Edge TTS 把链路跑通,再按需要换成本地(mlx-audio)或云(如腾讯云)。
3.2 配置写在哪:messages.tts
TTS 的配置节点是 messages.tts,写在 openclaw.json(或你用的配置里)。下面是一个「自动语音 + Edge 为主」的示例:
{"messages": {"tts": {"auto": "always","provider": "edge","edge": {"enabled": true,"voice": "zh-CN-XiaoxiaoNeural","lang": "zh-CN","outputFormat": "audio-24khz-48kbitrate-mono-mp3","rate": "+0%","pitch": "+0%"}}}}
auto: "always":每条回复都转成语音。还可选 "inbound"(只有你发语音时才回语音)、"tagged"(仅带[[tts]]的回复才读)、"off"(关掉自动)。provider: "edge":优先用 Edge TTS;不配 API Key 时 OpenClaw 默认也是 Edge。 edge.voice:音色,如普通话女声「晓晓」 zh-CN-XiaoxiaoNeural、粤语女声「晓曼」zh-HK-HiuMaanNeural。更多音色查微软文档或社区技能。
3.3 交给龙虾来配
不想手改 JSON 的话,可以直接对龙虾说人话,让它帮你改配置或给出可粘贴的片段。
例如:
默认语音:zh-CN-XiaoxiaoNeural(晓晓,普通话女声);粤语语音:zh-HK-HiuMaanNeural(晓曼,粤语女声);所有回复自动语音。3.4 找现成方案:clawhub / skillhub 搜 tts
社区里已经有人把各种 TTS(Edge、腾讯云、mlx-audio 等)做成技能或配置片段。在 clawhub 或 skillhub 里搜 tts,可以找到一键配置、音色列表、故障排查等,比自己从零查文档快。
四、STT(ASR):让小龙虾「能听」
4.1 方案大致分两类
本地方案:
- mlx-whisper
:Apple Silicon 上跑的 Whisper,速度快、隐私好,Mac 用户首选。 - faster-whisper、openai-whisper
云端方案:
腾讯云 tencentcloud-asr、阿里云、AWS 等,按分钟或按次计费。国内入门可以优先试 tencentcloud-asr,价格相对友好。
STT 在 OpenClaw 里归在 音频理解(audio understanding):语音/音频附件当作媒体输入,由 tools.media.audio 里配置的模型列表依次尝试转写。
4.2 配置写在哪:tools.media.audio
STT 相关配置在 tools.media.audio,其中 models 决定「用谁来转写、按什么顺序试」。
示例(先云端再本地 CLI):
{"tools": {"media": {"audio": {"enabled": true,"maxBytes": 20971520,"language": "zh","models": [{ "provider": "openai", "model": "gpt-4o-mini-transcribe" },{"type": "cli","command": "whisper","args": ["--model", "base", "{{MediaPath}}"],"timeoutSeconds": 45}]}}}}
enabled: true打开音频理解;不发语音可以关掉。 models是一个有序列表:先试第一个(例如 OpenAI 转写),失败或跳过再试下一个(例如本机 whisper CLI)。把 tencentcloud-asr、mlx-whisper 等配成 provider 或 CLI 条目即可,具体字段以社区技能或文档为准。
不配 models 时,OpenClaw 会按默认顺序自动检测(本地 CLI、Gemini、OpenAI 等),本机有对应命令且没关掉 tools.media.audio 就会尝试用。
4.3 交给龙虾来配(例如 mlx-whisper)
你可以用自然语言让龙虾帮你写 STT 配置,例如:
用 mlx-whisper 做语音转文字,本机优先,转写超时 60 秒。龙虾会根据你当前环境(是否 Mac、是否已装 mlx-whisper)给出 tools.media.audio.models 片段,你贴进配置即可。
4.4 找现成方案:clawhub / skillhub 搜 stt 或 asr
在 clawhub 或 skillhub 里搜 stt 或 asr,可以找到 tencentcloud-asr、mlx-whisper、faster-whisper 等现成配置或技能,直接套用或改几项即可。
五、进阶:方言、声音克隆与更多
如果你有方言、多语种、声音克隆等需求,可以往这些方向看:
- NoizAI:提供高质量克隆/定制音色的服务,可对接 OpenClaw 的 TTS 能力(通过自定义 provider 或技能)。
各大云厂商也有「定制发音人」「声音复刻」类产品,按厂商文档配置到 messages.tts的对应 provider 即可。
这类算进阶玩法,先把 Edge + 腾讯云 ASR 或 mlx-whisper 跑顺,再按需加一层。
六、小结:方案对比与怎么选
建议:
- 先打通
:Edge TTS + 任一本机或云端 STT(如 mlx-whisper 或 tencentcloud-asr),保证「能听、能说」。 - 再优化
:按需求换音色、加多角色、上云端或本地高阶方案。 - 找现成
:clawhub / skillhub 搜 tts、stt、asr,省时间。
七、结语:从「打字」到「对话」
和龙虾打交道,已经可以从「只能打字」变成「你说它听、它说你听」。
多 Agent 时用不同音色区分角色,单 Agent 时用固定音色增加真实感;往后还会有更自然的打断、情绪和多轮节奏。
先把听和说的链路在 OpenClaw 里跑起来,再往「更像人」的方向慢慢调,小龙虾就能从「能听声音 and 会讲话」一步步变成你习惯的那种语音伙伴。
延伸阅读
Text-to-Speech(TTS 配置与命令) Audio and Voice Notes(音频理解与 STT 配置) clawhub / skillhub 搜索:tts、stt、asr
