 夜雨聆风
夜雨聆风这期我把Codex接上了Google Earth Engine
前两期用Codex自动做了两个案例:
有读者问:遥感数据呢?卫星影像这种体量,Codex扛得住吗?
这期直接回答,而且给两个案例。一个是Codex单独处理卫星时序数据(让它自己找数据),一个是Codex调用Google Earth Engine做大范围遥感分析。两个案例放在一起,你会看到这个组合能做到什么程度。
案例一:毛乌素沙地植被恢复——Codex单打
简单构思任务后,我把这段提示词复制进Codex:
分析2000年到2020年毛乌素沙地的植被变化,用卫星数据定量说明治沙成效。请自行选择最合适的公开数据源和处理方法,要求10分钟内完成,输出变化趋势图、空间分布对比图和文字结论。没有告诉它用什么数据,没有告诉它用什么方法,只加了一个时间约束——10分钟。当然,我并不指望它能实现,只是测试它的表现。
它自己做了什么决策
Codex先评估了数据获取路径:Landsat原始影像需要逐景下载处理,在时间约束下不可行,放弃;选MODIS MOD13A1 v061(500m分辨率,16天合成NDVI产品),通过Microsoft Planetary Computer STAC接口获取,完全公开无需账号,单景数据量小,计算轻量。
研究区边界基于公开文献坐标构建毛乌素沙地近似边界,面积约5.09万km²。
处理流程:每年7–8月生长季影像做逐像元最大值合成(取生长季峰值),裁切到研究区,统计区域NDVI均值,跑完2000–2020年全部21个年份。
实际耗时43分钟,不是10分钟。中途它发现数据集混入了MYD13A1(Aqua卫星),判断需要统一用MOD13A1(Terra卫星)保证时序一致性,自己修了重跑。这个传感器口径问题是遥感时序分析里的常见坑,它自己识别并处理了。

图一:2000–2020年NDVI年际均值时序
这是整个分析最核心的一张图。横轴是年份,纵轴是区域平均生长季峰值NDVI,橙色虚线是线性趋势。

几个关键数字直接标在图上:2000年均值0.274,2020年均值0.447,增幅63.5%,线性趋势+0.0084/年,R²=0.87。
R²=0.87说明这条上升趋势是高度线性的,不是个别年份的偶发高值拉上去的。年际波动是真实存在的——2015年有一个明显低谷,对应当年干旱,这不是分析错误,而是气候信号在数据里的正常体现。2016年之后整体维持高位,2018年达到全序列最高值0.466。
这张图的可验证性很强:毛乌素治沙成效有大量文献背书,任何已发表论文的NDVI趋势方向和这张图都应该一致。方向错了就是明显问题,方向对了量级也应该在同一数量级。
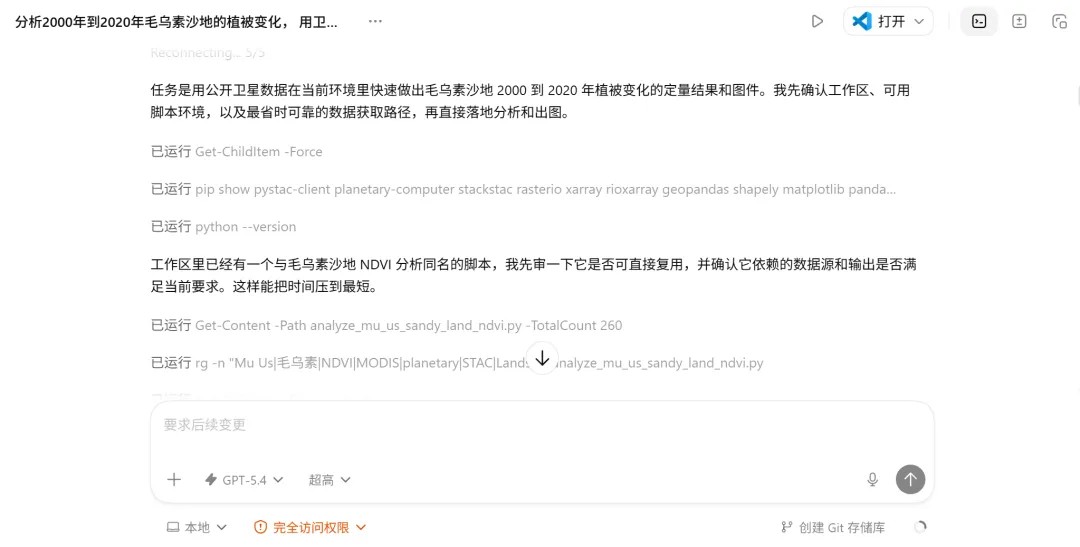
图二:2000年与2020年NDVI空间分布对比
两张同色阶的空间分布图并排,左边2000年,右边2020年。
2000年图整体偏黄绿,中部和西部有大片NDVI低值区(接近0.2),对应当时裸露沙地覆盖较多的区域。2020年图整体明显偏深绿,原来的低值区域颜色普遍加深,高值区域(NDVI>0.5的深绿色块)面积明显扩大,集中在研究区东南部。
从空间对比上可以直接看出:植被恢复不是均匀发生在整个沙地的,而是在东南部形成了更密集的高植被覆盖区,西北部恢复相对较慢。这个空间格局与毛乌素地区的地形、水分条件和治理投入分布是一致的。
图三:NDVI变化量图(2020-2000)
绿色代表增加,橙红色代表退化,色阶从-0.35到+0.35。

这张图最直观。整个研究区几乎被绿色覆盖——88.8%的区域NDVI提高超过0.05,73.4%的区域提高超过0.10。橙红色(退化区域)极少,主要分布在西北边缘,且退化幅度小,全区明显退化(减量>0.05)的面积只有1.1%。
增绿最明显的区域集中在东北部和东南部,平均增量约+0.243,说明治沙成效不是局部点状改善,而是在沙地中东部形成了较连续的区域性恢复带。
高分辨率版本的交叉验证
如果你对500m的MODIS结果有疑虑,我也跑过一个Landsat 5/8的版本——30m分辨率,从USGS逐景拉取原始影像,场景ID和过境时间戳精确到毫秒,每一景都可以去EarthExplorer核验。
结论方向完全一致:NDVI从2000年的0.159升到2020年的0.275,增幅73.7%。两套不同数据源、不同分辨率的结果互相印证——这本身就是遥感分析里的交叉验证,结论可信度更高。
Landsat版本的代价是将近3小时,因为数据在远端,大部分时间在等网络IO。对于想要高分辨率结果的场景,这个时间是值得的。

在开始案例二之前:GEE账号配置
Codex调用GEE需要你提前完成一次性的账号认证。完成之后credentials保存在本地,之后所有GEE分析永久有效,不需要重复操作。
如果你已经有GEE账号并在本地认证过,跳过这一节即可。
以下过程也可以在Codex的指导下进行。
第一步:注册GEE账号
前往 earthengine.google.com,用Google账号申请。填写用途说明(学术研究即可),审核通常当天到几天内通过。
申请通过后,进入 console.cloud.google.com 创建一个Project,记下Project ID(格式类似my-project-123456),后面会用到。
第二步:安装earthengine-api
在命令行里运行:
pip install earthengine-api第三步:一次性认证
earthengine authenticate运行后会自动打开浏览器,用Google账号登录并授权。授权完成后,credentials自动保存到本地~/.config/earthengine/目录下,之后不需要重复操作。
第四步:告诉Codex你的Project ID
在给Codex的Prompt里加一句:
账号已在本地配置好credentials,请使用
ee.Initialize(project='你的project ID')初始化。
Codex会自己调用这行代码完成初始化,然后直接开始写分析脚本。
已有GEE账号的读者
如果你之前注册过GEE但没在Python环境里用过,只需要补一个pip install earthengine-api然后跑一次earthengine authenticate就够了。之前在QGIS或者其他环境里的认证和这里的Python认证是分开的,需要单独操作一次。
案例二:澳大利亚黑色夏季山火——Codex+GEE
为什么要接上GEE
毛乌素案例的瓶颈很清楚:数据在远端服务器,网络IO是主要耗时。43分钟里真正的计算时间不超过5分钟。
解决这个瓶颈的办法是把计算也搬到数据所在的地方——这就是Google Earth Engine的核心设计:Landsat、Sentinel、MODIS等主流卫星数据都存在Google服务器上,GEE直接在服务器端完成计算,你只下载最终结果。
Codex可以直接调用GEE的Python API,自己写GEE代码。组合的本质是:Codex负责想清楚要做什么、写出正确的代码,GEE负责扛住数据体量。
我给了它什么
完整Prompt如下,可以直接复制。
使用Google Earth Engine Python API分析2019-2020年澳大利亚黑色夏季山火。研究区:新南威尔士州和维多利亚州东部(149°E–153.5°E,37.5°S–32°S)请完成以下全套分析:1. MODIS火点热度图 使用MODIS/061/MOD14A1,提取 2019年9月1日–2020年2月28日期间 研究区内FireMask值为8或9的火点, 按累积火点密度生成热度图2. NBR过火边界提取 使用Landsat 8 Collection 2 Level-2 (LANDSAT/LC08/C02/T1_L2) 火前参考期:2019年4月1日–2019年8月31日 火后参考期:2020年1月1日–2020年3月31日 云掩膜:使用QA_PIXEL波段, Bit3(云)和Bit4(云阴影)均为0的像元才保留 合成方式:中位数合成(median) 计算NBR = (B5 - B7) / (B5 + B7) dNBR = NBR_before - NBR_after 反射率缩放:乘以0.0000275加-0.23. 燃烧严重程度分级 按USGS标准对dNBR分级: 未过火:dNBR < 0.1 低度燃烧:0.1–0.269 中度燃烧:0.27–0.439 高度燃烧:0.44–0.659 极高度燃烧:dNBR ≥ 0.664. 面积量化 统计各严重程度等级的过火面积(公顷) 与澳大利亚政府公布的NSW+Victoria 合计约720万公顷对比输出:MODIS火点热度图、火前/火后NBR对比图、dNBR严重程度分级图、各等级面积统计CSV、文字结论账号已在本地配置好credentials,请使用ee.Initialize(project='你的project ID')初始化。
大家可能会好奇,我的提示词是怎么想出来的?其实我是用Claude网页的Sonnet 4.6模型写的,我和他讨论过任务需求之后,让它给我一个提示词。准确的提示词有助于Codex节省时间,降低试错成本。当然,Codex本身也可以规划出一个方案,也有Plan模式(计划模式,先规划后执行),但作为一个演示案例,我希望大家能直接拿这个提示词去复现我的操作。
它写出来的代码里有什么
这里我不展示代码,而是直接给大家我的评价。这事儿是有必要的,因为遥感人一看就知道对不对:
MODIS火点提取: 使用MOD14A1,提取FireMask值为8或9的像元——这是MODIS官方的高置信度火点标记,不是随便设的阈值。
Landsat 8云掩膜: QA_PIXEL波段位运算,Bit3(云)和Bit4(云阴影)同时为0才保留。这是Collection 2的标准做法,不是简单的云量百分比筛选,是逐像元质量控制。
反射率缩放: SR_B5和SR_B7乘以0.0000275后加-0.2。这是Landsat Collection 2 Level-2产品的官方缩放系数,用错了整个NBR计算就会偏。
NBR公式: (B5-B7)/(B5+B7),其中B5是近红外、B7是短波红外,dNBR=NBR_before-NBR_after。这是标准的归一化燃烧比公式,波段选择和文献一致。
USGS五级分类阈值: 未过火<0.1,低度0.1–0.269,中度0.27–0.439,高度0.44–0.659,极高度≥0.66。这套阈值来自USGS官方技术报告,是火烧迹地分析的通用标准。
这些细节不是我告诉它的,是它自己带进来的。
还有一次失败
第一版用的是Sentinel-2,结果图碎片化严重——研究区只有43.7%有有效数据覆盖,超过一半是空白。原因是火前参考期(6–8月)澳大利亚东部正值冬季,云量高,<20%的筛选条件过于严格。
它在结论里如实注明了这个问题。然后我要求换Landsat 8,扩大火前参考期到4–8月,中位数合成——第二版覆盖率提升到45.1%,结果图连续完整。
这个失败值得记录:真实的遥感分析就是这样,第一个方案不一定对,需要根据数据特点调整。

图一:MODIS火点累积热度图
橙红色点代表2019年9月1日至2020年2月28日期间的累积高置信度火点,颜色越深表示同一位置被重复探测到的次数越多。

整个研究区共探测到32,609次火点记录。火点分布沿大分水岭山脊线呈南北走向延伸,从新南威尔士州北部一直延伸到维多利亚州东部,形成一条清晰的火烧走廊。这与Black Summer山火的实际蔓延路径高度吻合——山地森林带是主要燃烧区域,沿海低地和内陆平原相对较少。
图二:火前/火后NBR对比
左图是火前参考期(2019年4–8月)的NBR空间分布,右图是火后(2020年1–3月)。同色阶,绿色代表植被健康(NBR高),橙红色代表植被稀少或受损(NBR低)。
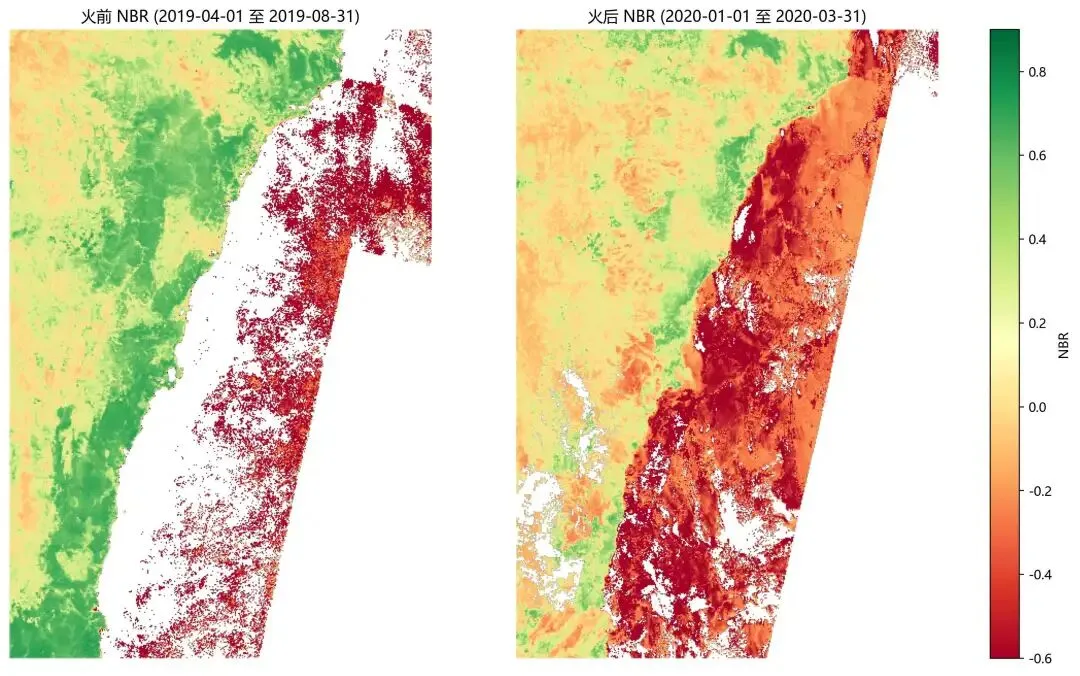
对比两张图最明显的变化:火前图左侧(大分水岭山地)大面积绿色,代表火前茂密的桉树森林;火后同一区域变成大面积橙红色,NBR值急剧下降,植被覆盖受到严重破坏。
火前图右侧(沿海地带)有一条白色空白带,是云掩膜后无有效观测的区域,这不是数据错误,是客观存在的云覆盖。
图三:dNBR燃烧严重程度分级
这是这个案例最核心的输出。五种颜色对应五个燃烧严重程度等级,从浅黄(低度燃烧)到深红(极高度燃烧),灰色是未过火区域。

空间格局非常清晰:极高度燃烧(深红色)集中在大分水岭山脊两侧的山地森林带,这里是澳大利亚东部桉树林最密集的区域,也是Black Summer中受损最严重的地方。低度燃烧(浅黄色)分布在火烧走廊的外围,代表火焰蔓延到植被较稀疏区域后强度减弱的边缘地带。
各等级面积:
低度燃烧:355.9万公顷(占过火面积47.4%) 中度燃烧:201.8万公顷(26.9%) 高度燃烧:102.0万公顷(13.6%) 极高度燃烧:91.8万公顷(12.2%) 总过火面积:751.5万公顷
澳大利亚政府公布NSW+Victoria两州合计过火面积约720万公顷,本研究结果是官方数据的104.4%。差异来自研究区边界(矩形研究框)和州级行政边界的不完全重合,量级对应关系良好。
两个案例放在一起说明了什么
数据体量的差别: 毛乌素用MODIS 500m产品,研究区5万km²,数据量可管理,Codex在本地处理就够了。澳大利亚山火用Landsat 8 30m产品,研究区25万km²,在本地处理的数据下载量有几百GB——这是GEE才能扛住的体量。
代码质量的差别: 毛乌素案例Codex的工作重心是数据获取和流程设计。澳大利亚案例Codex写出的GEE代码包含了正确的传感器参数、位运算云掩膜、官方缩放系数——这些是遥感专业知识,不是通用编程能力。
失败的价值: 两个案例都有失败和调整——毛乌素发现传感器混用,澳大利亚第一版Sentinel-2覆盖不足。这些失败没有被隐藏,反而说明结果是真实跑出来的,不是演示用的假数据。
但结果并不完美——这正是重点
有一说一,这两个案例都只是一次交互的结果,还有明显的改进空间。
毛乌素案例的研究区边界是基于公开文献坐标构建的近似多边形,不是官方矢量边界,面积存在误差。澳大利亚案例的火后NBR图在沿海地带有云覆盖空白,导致dNBR分级图大量空白,内陆部分区域的严重程度分级可信度有限。这些问题如果放在真实科研场景里,是需要进一步处理的。
但这里有一个关键点经常被忽略:真实的科研场景不是一次交互,是反复对话。
你可以接着说:
毛乌素的研究区边界换成这个shapefile,重新跑一遍。 澳大利亚的云覆盖区域用MODIS替代填补,右侧空白区域单独处理。 2018年的NDVI异常高值检查一下是不是云污染,如果是的话剔除。
每一条要求,它都会在已有结果的基础上修改,不需要从头解释整个分析框架。你的专业判断叠加它的执行能力,两者结合才是正确的使用方式。
更重要的是:它学会一件事之后,下次就轻松了。 这次花了43分钟建立起来的MODIS处理流程,下次换一个研究区、换一个时间窗口,改两行参数重跑,几分钟出结果。澳大利亚山火那套GEE代码,换成其他火灾事件或者其他遥感指数,框架完全可以复用。
所以评估这类工具的正确方式不是"一次交互能做到多完美",而是"在我的专业判断介入之后,它能把最终结果推到哪里"。
关于门槛

会GEE的人直接用GEE当然更快。这里展示的是另一件事:不会写GEE代码的人,现在也可以得到同等质量的结果——只要你能把分析目标说清楚。
前两期说的是Codex在数据分析层面比你想象的上限高。这期想说的是,上限不是固定的。接上GEE,遥感分析的数据体量约束基本消失。接上其他专业API,边界还会继续后退。
工具的天花板,很多时候是你自己想象出来的。最后,还是回到前面2期说的那句话,不要盲目崇拜OpenClaw!
