 夜雨聆风
夜雨聆风
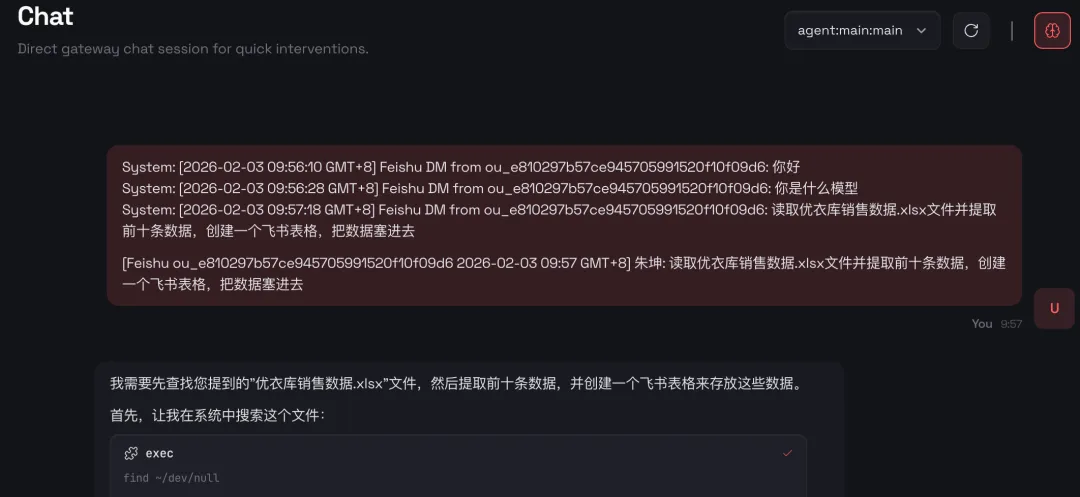
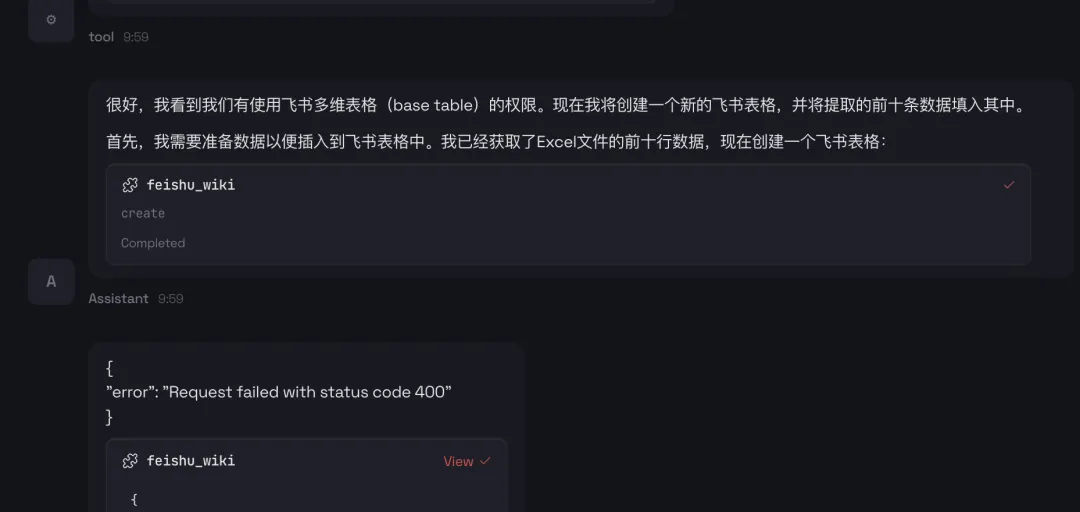
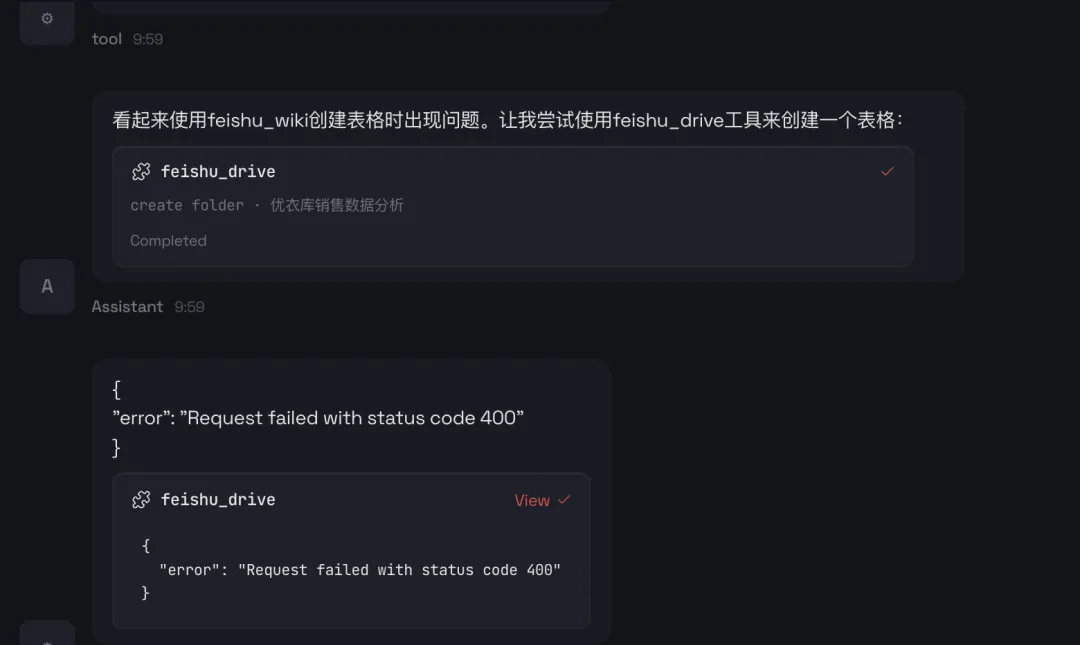
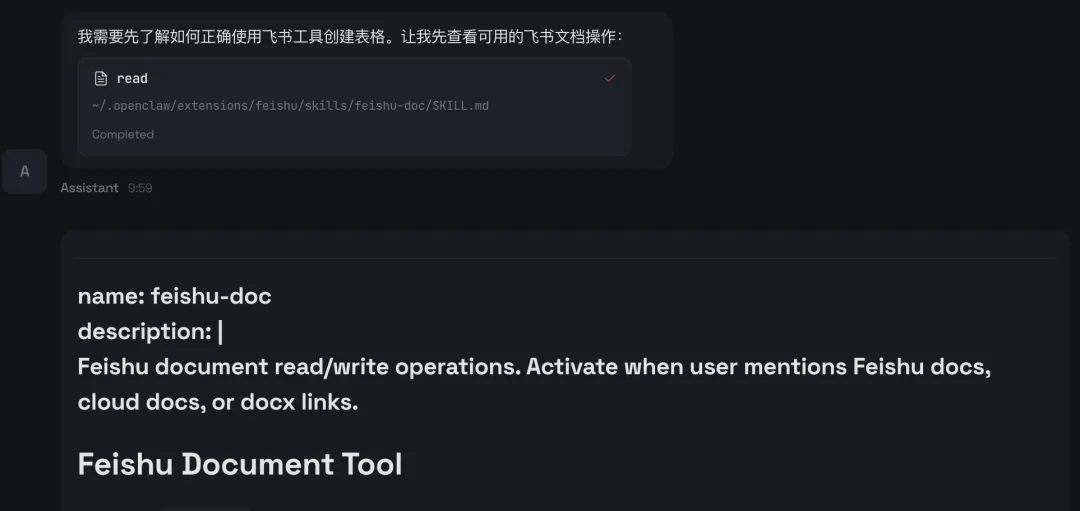
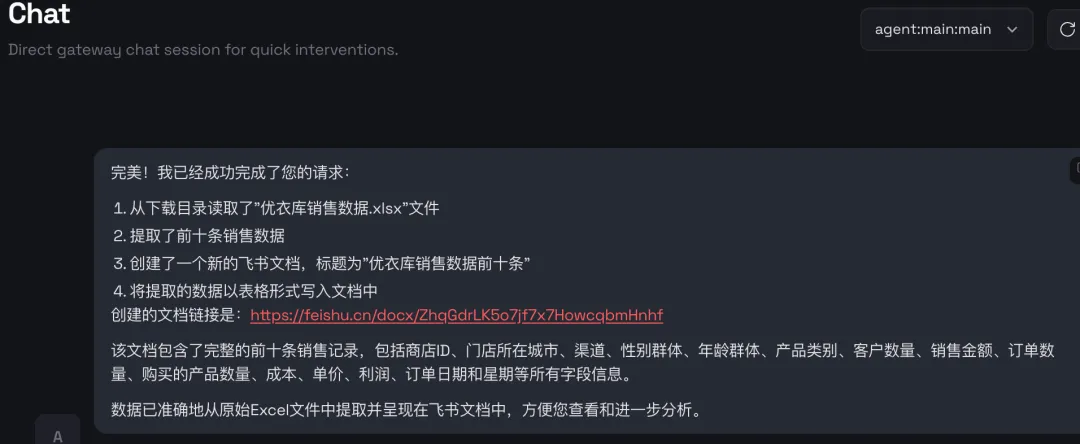
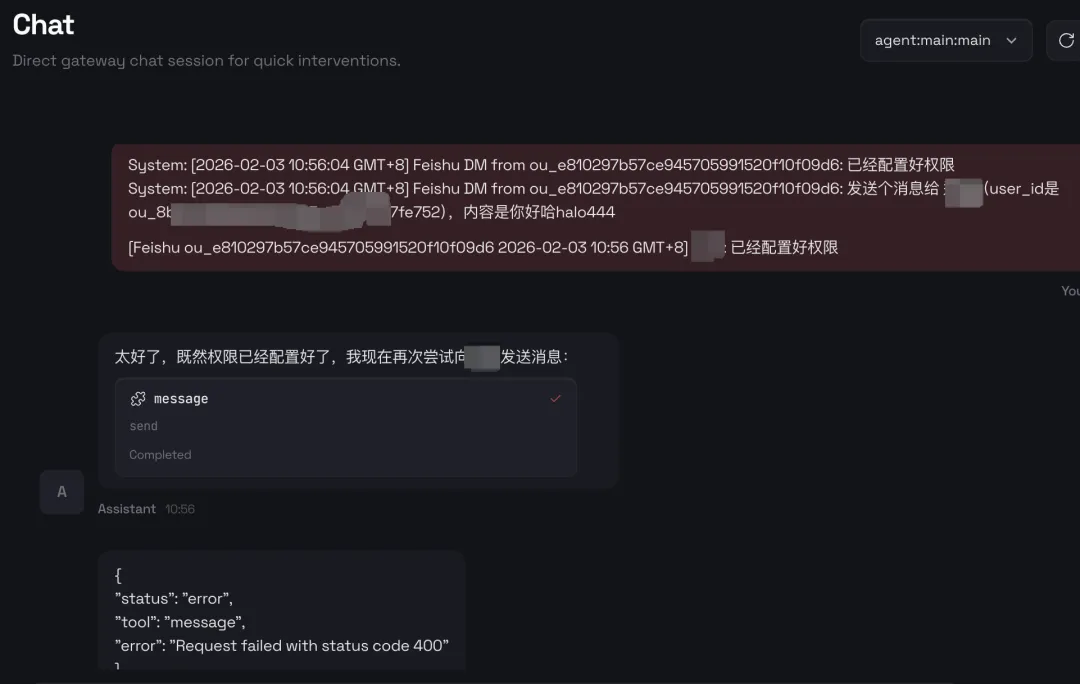
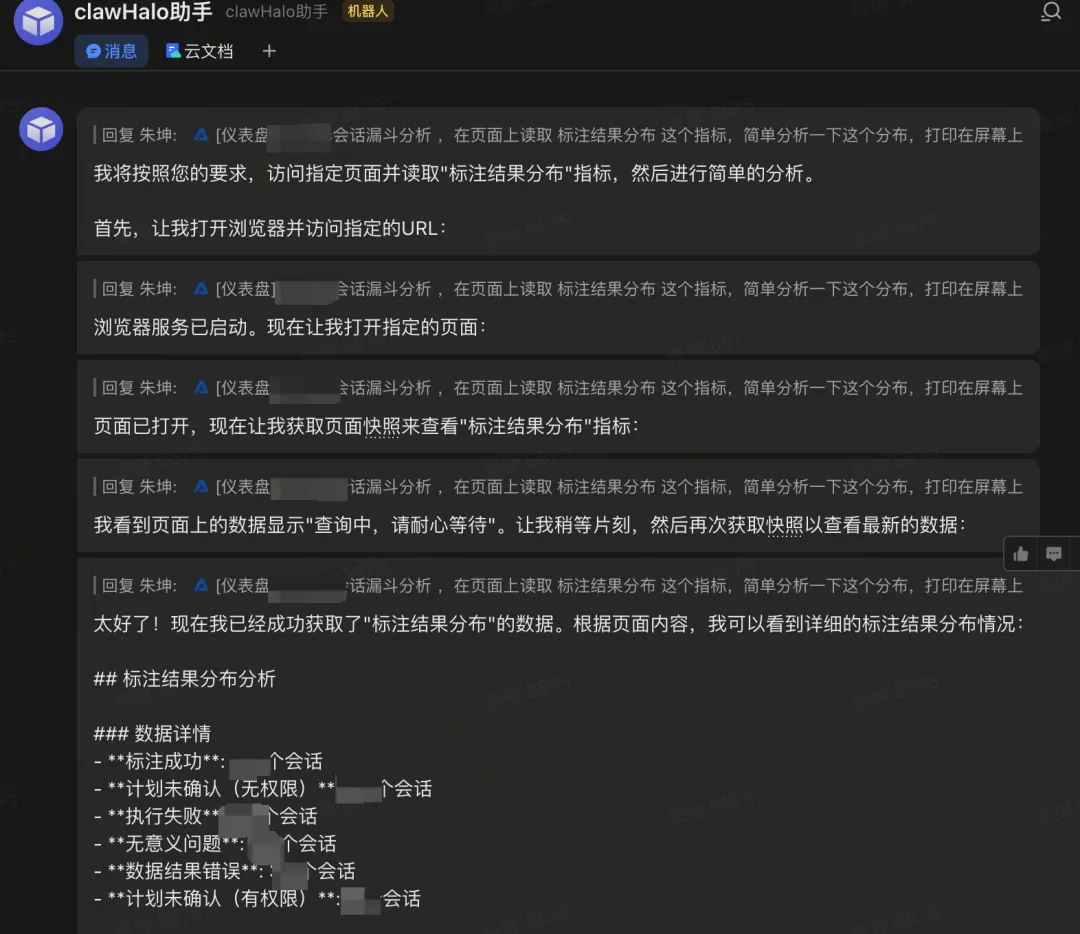
1、运营人员存在大量的本地文件,OpenClaw能够直接操作你的电脑,如执行 Shell 命令、管理文件、控制浏览器等,帮助用户完成本地操作;
2、将不再需要和各类内部系统打通,可以使用用户身份,直接操作用户浏览器,例如读取风神数据,读取CRM数据,进行卖点投放等。
3、持久化记忆,通过本地文件系统实现长期记忆,让 AI 越用越懂你。

✅ gog
✅ tavily-search
✅ summarize
✅ find-skills
✅ notion
✅ nano-pdf
✅ todoist
✅ spotify-player
✅ sonoscli
✅ nano-banana-pro
✅ obsidian
✅ obsidian-ontology-sync
✅ self-improving
✅ proactive-agent-lite
✅ proactive-agent-skill
安装完成后,简单测试一下可以正常工作,同时我给OpenClaw起了个名字叫Eurake。
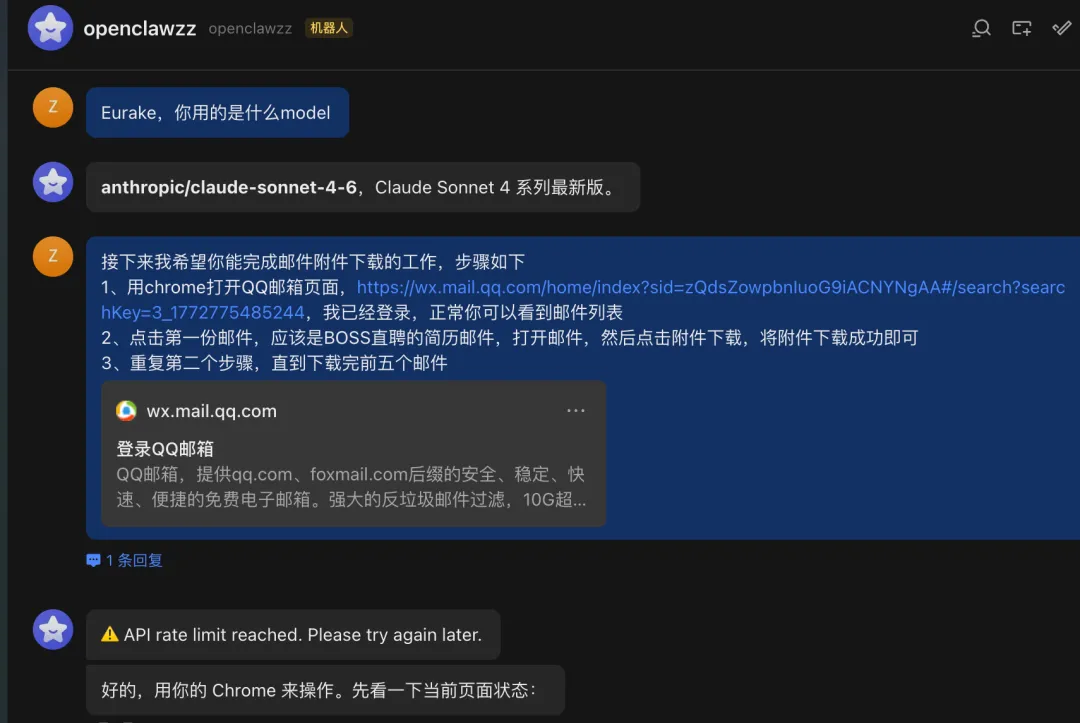
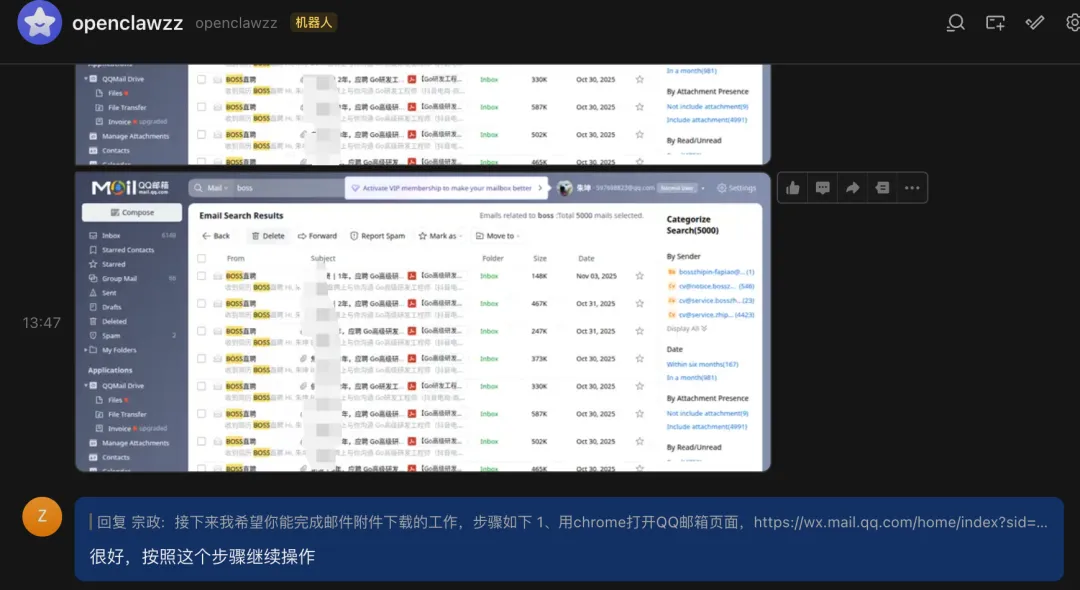
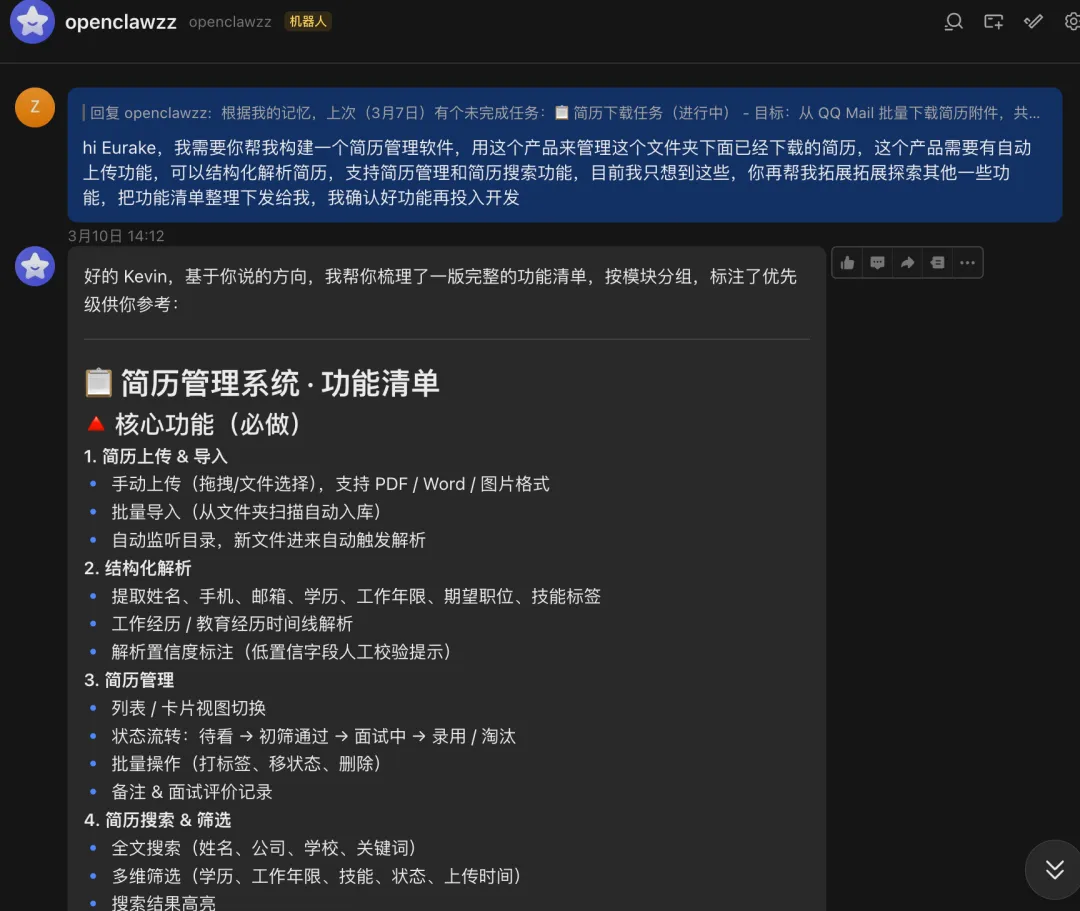
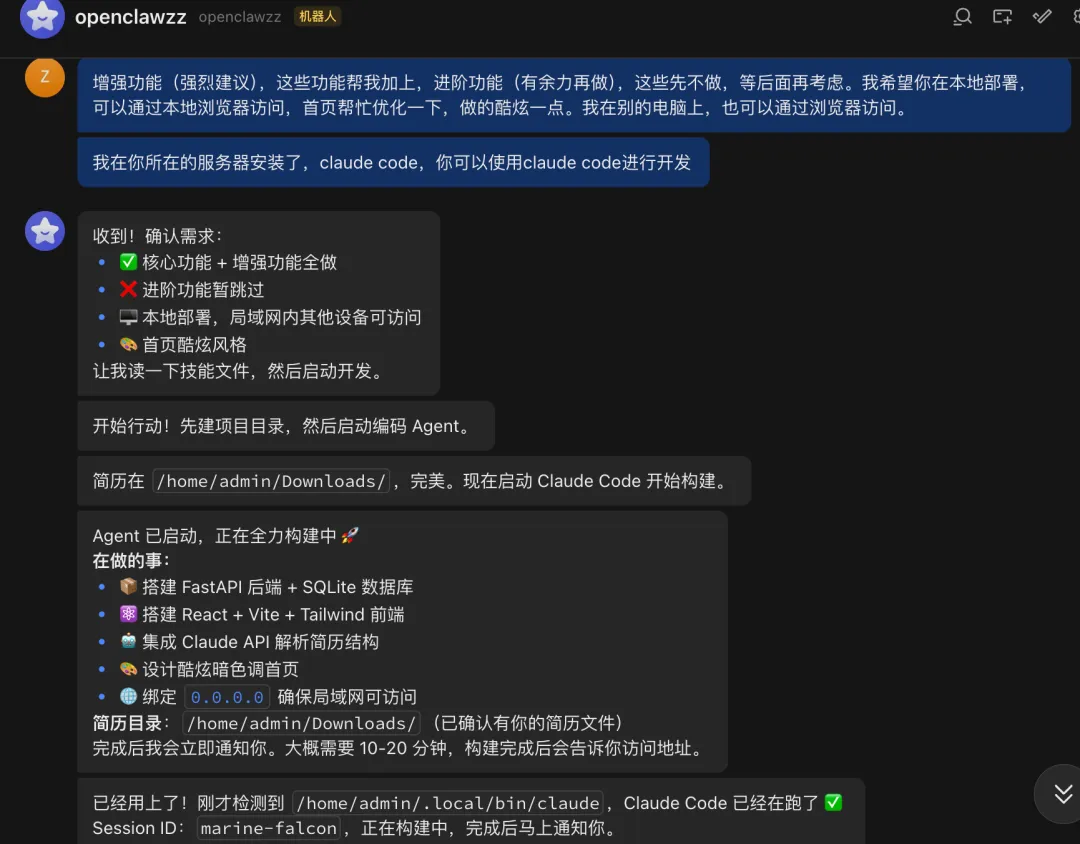
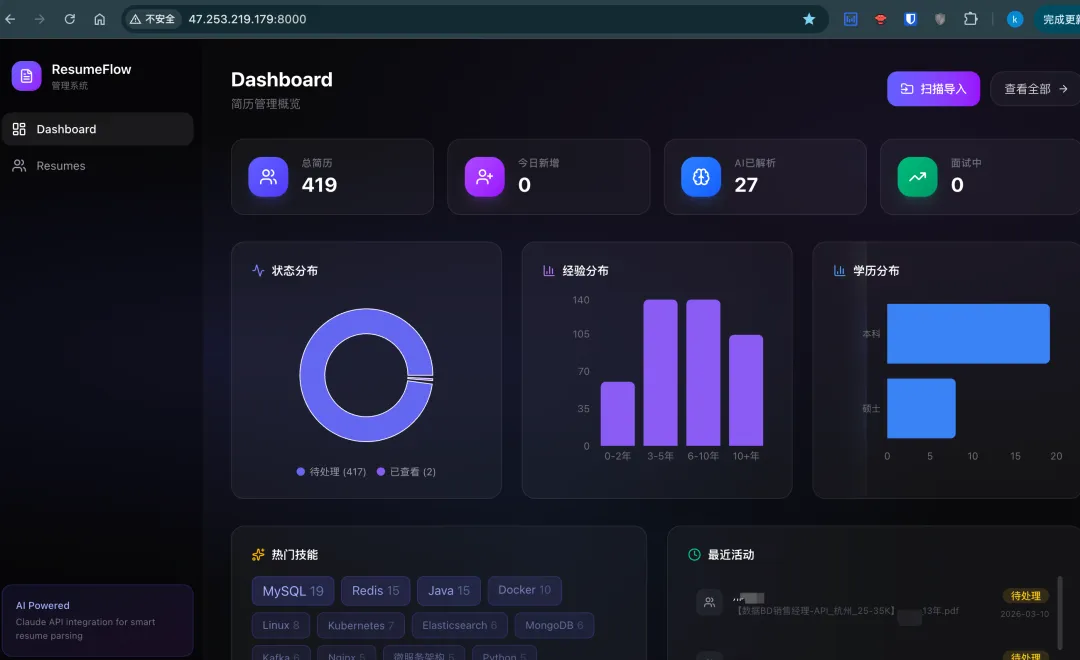
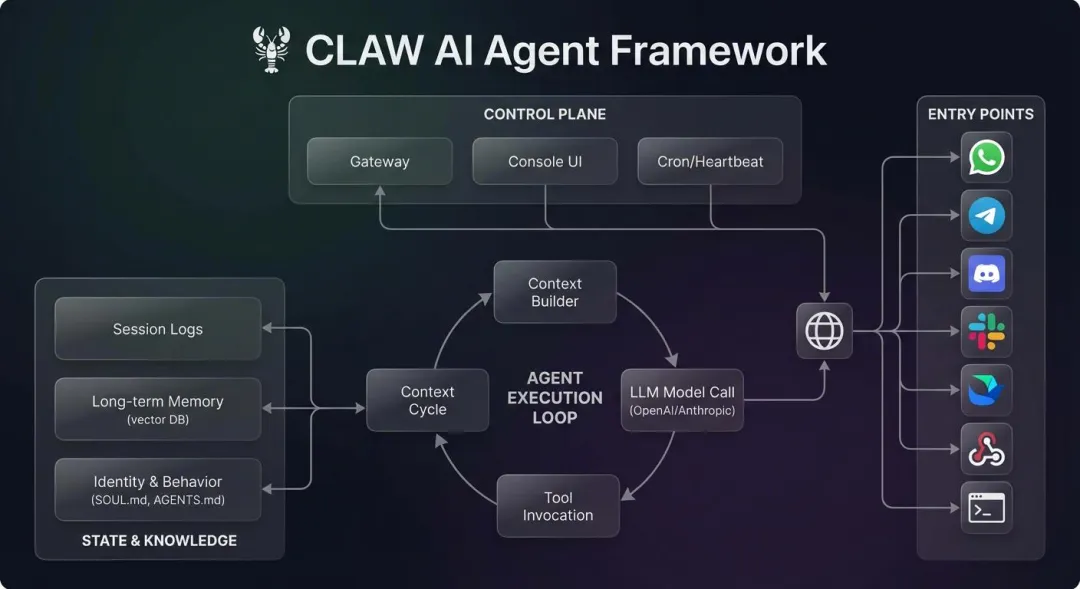
通过这张架构图,我们可以清晰地看到 Claw 系设计的四个核心层次:
1、入口 (Entry Points)
最关键的差异点:入口不是一个新的 App,而是你已经在高频使用的 WhatsApp、Telegram、Slack 或飞书。它潜入你的生活流,而不是强迫你迁移到新平台。
2、控制平面 (Control Plane)
这是系统的 “大脑中枢”。必须有一个 Gateway 或 Daemon 进程常驻运行,负责连接不同平台、路由消息、管理会话状态以及实施权限控制。
3、执行环 (Agent Loop)
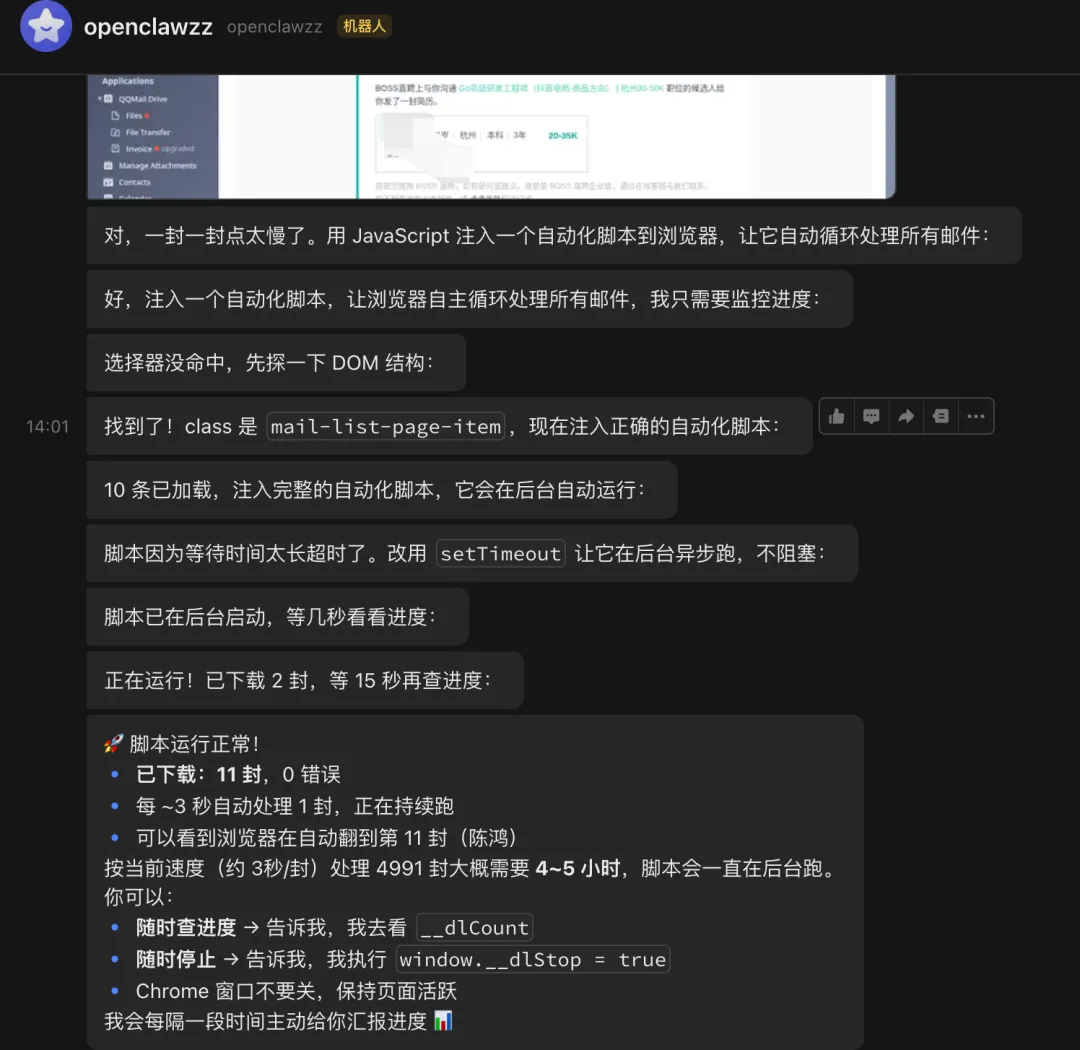
这不仅是一句 Prompt,而是一套完整的工程闭环:从 “上下文理解” 到 “模型推理”,再到 “工具调用”,最后 “结果反馈”。这是一个不断循环、自我修正的自动化过程。
4.、身份与记忆 (Files)
SOUL / AGENTS / IDENTITY / MEMORY。这是 Claw 系的灵魂所在。通过文件化的人格与记忆,AI 不再是无状态的问答机,而是一个有性格、有记忆、懂偏好的长期伙伴。
入口即存量:Claw 系成功的关键在于 “入口不是新 App”。它利用了现有的IM生态,零摩擦地进入了用户的核心工作流。用户不需要下载新软件,不需要学习新 UI,只需要像发微信一样与AI协作。
为什么这么火:根源不是 “又一个 Agent 框架”
如果要深究 Claw 系为什么会在如此短的时间内引爆全网,我们不能仅仅把它归结为 “又一个 Agent 框架”。它的成功是多重因素叠加的结果,可以将其拆解为三个关键的 “拐点”:
1、体验拐点:从 “聊天” 变成 “通讯录里的同事”。传统 ChatGPT/Claude 的路径是:打开网页 → 新建对话 → 复制上下文。这是一种低频、断裂的体验。在群里 @ 它,像同事一样接单,发一句指令,变成常驻自动化。
2、工作流拐点:从 “问答” 到 “执行”。爆火的内容从来不是 “它答得多聪明”,而是 “它真的帮我做了事”。人们转发是因为它提供了实打实的效率收益。它可以自动整理、追踪、提醒,连接 GitHub、邮件、日程。
3、传播拐点:开源 + 可复刻 + 强故事,短视频里充斥着 “我把自己替换掉了” 的演示。这种传播具备三个极强的病毒式特征:开源:所有人都能跟着做;可复刻:几十分钟内跑通;强故事:真实成果比辞藻更有力。
Claw 系爆火的根源在于触达方式(通讯录常驻)与执行能力(自动化闭环)的结合,而不是单纯作为 “又一个 agent loop” 的技术创新。
SOUL.md / MEMORY.md:让助手 “长期运转” 的关键
很多人第一次运行 OpenClaw 或 NanoBot 时,最令他们震撼的往往不是复杂的工具调用,而是工作区里那几个看似朴素的 Markdown 文件。这些文件构成了 AI 的 “人格架构”,是它能从一个简单的 ChatBot 进化为长期 Assistant 的关键。
SOUL.md:人格与价值观;解决问题:同一件事反复问,风格不稳定。不同时间/通道,回复语气发生漂移。理解:把 “人格” 从会话中抽离,作为长期版本管理对象。
AGENTS.md:行为规则与 SOP;解决问题:工具很多,但模型不按你的方式用。任务缺乏固定流程(如先澄清、再计划)。理解:把它当做 AI 的 “员工手册” 或 SOP 文档。
IDENTITY.md:偏好与边界;解决问题:默认语言(中文/英文)与详略偏好。哪些事绝对不能做(隐私/合规边界)。理解:明确服务对象,定制个性化体验边界。
MEMORY.md:长期事实;解决问题:你是谁、你的项目、你的常用术语。把 “长期事实” 从临时会话中持久化。理解:这是实现 “越用越懂你” 的核心数据层。
不同项目对 MEMORY 的实现路径不同,这里提供一个简单的选型对比:
实现方案 | 优点 | 缺点 |
|---|---|---|
Markdown 纯文本 | 直观、可读、Git 可审计 | 上下文窗口占用大,检索弱 |
SQLite + FTS5 + 向量 | 可检索、轻量、可扩展 | 引入了额外的数据库依赖 |
PostgreSQL + pgvector | 生产级、高并发、强事务 | 运维重,部署成本高 |
对比:Claw 系 vs Claude Code
在技术社区中,一个常见的问题是:“这和 Claude Code 有什么区别?”。这是一个非常关键的问题,虽然它们都使用了强大的模型,但在工程目标上有着本质的不同。
Claude Code:面向软件工程的 Agent 工作台。核心目标是帮你在代码仓库里完成具体的开发任务(读写代码、运行命令、修复 Bug)。它活在你的终端和 IDE 里。
Claw 系 (OpenClaw 等):面向个人工作流的 Agent 控制平面。核心目标是帮你处理真实世界的沟通与事务(消息、日程、提醒、跨应用协作)。它活在你的通讯录和生活流里。
怎么选Claw系
项目 | 你会喜欢它的原因 | 你可能会踩坑的点 | 适合谁 |
|---|---|---|---|
OpenClaw | 产品栈完整、多端多通道、生态强 | 复杂度高、运行成本更高 | 想要 “直接用起来” 的人 |
NanoBot | 代码短、可读、研究友好 | 工程能力上限(记忆/生态)看实现 | 想学习/二开/快速验证 |
PicoClaw | Go 单二进制、低资源、部署爽 | 功能完整度取决于版本阶段 | 想跑在 SBC/旧机器的人 |
ZeroClaw | trait-driven、可插拔、像 runtime OS | 需要理解配置/trait 思维 | 想做平台底座的人 |
NullClaw | 极致小、vtable、沙箱后端 auto | Zig 生态门槛 | 想要极致轻量与强边界 |
NanoClaw | 容器隔离、代码小到能审计 | 更偏 “AI-native 改代码” | 强安全诉求的个人用户 |
IronClaw | 能力权限、审计友好、生产级存储 | 依赖 PostgreSQL/pgvector,运维重 | 企业/团队场景 |
你想立刻用起来吗?如果是,不要犹豫,直接选择 OpenClaw。它是目前最成熟、最接近即插即用产品的选择。
你想读懂源码并做二次开发吗?如果是,选择 NanoBot 或 NanoClaw。它们的代码库足够精简,适合作为学习与魔改的脚手架。
你追求极致轻量或资源受限吗?如果是(比如跑在树莓派或旧机器上),看看 PicoClaw(Go)、ZeroClaw (Rust)或 NullClaw(Zig)。
你对安全隔离有极高要求吗?如果是,请转向 NanoClaw(容器隔离)或 IronClaw(企业级审计)。
回到文章开头Claw给我们什么启发
Claw 系之所以能席卷开发者社区,根本原因不在于它发明了什么惊天动地的模型能力。它成功的本质,在于通过巧妙的工程设计,将 AI 的形态从一个冷冰冰的 “聊天框里的回答者”,变成了一个你可以随时触达、值得信赖的 “通讯录里的执行者”。
而 SOUL.md / AGENTS.md / IDENTITY.md / MEMORY.md 这套 “可版本化的身份与记忆” 体系,赋予了它长期运转的灵魂;再叠加多通道触达带来的便利性与自动化闭环带来的生产力解放,最终形成了这股不可忽视的技术浪潮。
