 夜雨聆风
夜雨聆风
要点
- 普林斯顿大学的研究人员开发了 OpenClaw-RL,这是一个框架,它将正在进行的对话、终端命令和工具调用中的反馈重新用作人工智能代理的直接训练材料——这些数据通常会被丢弃。
- 该系统由四个独立的并行模块构成,具有两个互补的学习过程:一个以二元“是”或“否”的方式评估行为,而另一个则从反馈中提取具体的改进建议,所有这些都不需要单独的教师模型或预先收集的训练数据。
- 经过几十次交互,人工智能代理就学会了摒弃那些听起来很生硬的短语,并生成更自然的语言。代码已发布在 GitHub 上。
OpenClaw-RL框架将每次交互过程中产生的信号视为实时训练源。个人对话、终端命令和GUI操作都会输入到同一个训练循环中。
每次人工智能代理与用户或环境交互时,都会生成后续信号:用户响应、工具结果、终端或屏幕上的状态变化。此前,系统仅将这些信息用作下一步操作的上下文,然后便将其丢弃。
普林斯顿大学的研究人员认为,这相当于系统性浪费。他们提出的新框架 OpenClaw-RL 旨在利用这些信号作为实时训练资源。该框架并非将个人对话、命令行命令、图形用户界面交互、软件工程任务和工具调用视为独立的训练问题,而是将它们全部输入到同一次运行中,以改进同一个模型。
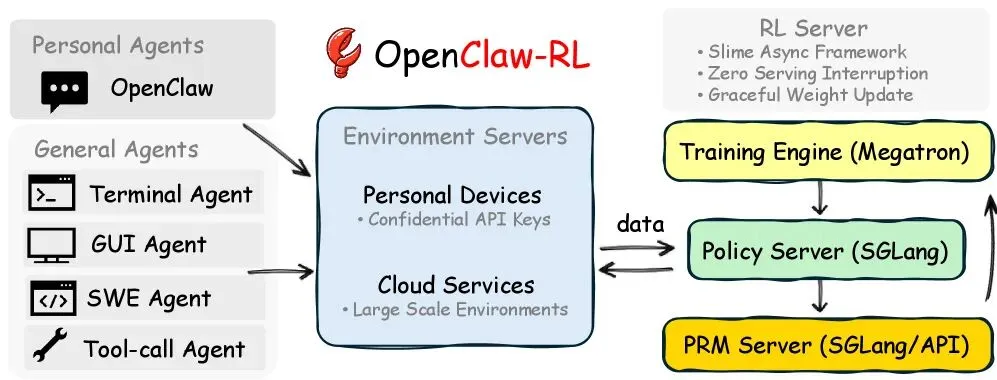
OpenClaw-RL 通过环境服务器将个人代理和通用代理连接到 RL 服务器,该服务器的四个组件异步工作,互不阻塞。| 图片:Wang 等人
后续信号既包含评估,也包含方向性指示。
研究人员指出,这些后续信号编码了两种此前未被利用的信息。第一种是评价信号。如果用户再次提出相同的问题,则表明其不满意。如果自动化测试通过,则表明操作成功。这些信号无需人工标注,即可对每个步骤进行自然的质量评估。以往的训练方法充其量只能事后利用这些信号,从预先收集的数据中提取信息。
第二种类型是方向性信号。当用户评论“你应该先检查一下文件”时,这种反馈会具体指出应该如何改进,而不仅仅是指出哪里出了问题。强化学习中的标准奖励系统会将这类反馈压缩成一个数字,从而丢失了内容层面的方向性信息。
四个解耦组件确保训练在实际使用过程中持续进行。
OpenClaw-RL 的架构分为四个解耦的组件:一个组件负责处理查询,一个组件管理环境,一个组件评估响应质量,一个组件负责实际的训练。各个组件之间互不干扰——模型在响应下一个用户请求的同时,评估模型会对之前的响应进行评分,而训练组件则会并行运行权重更新。
对于个人代理,用户设备通过保密API连接到训练服务器。体重更新无缝进行,不会中断正在进行的使用。对于通用代理,系统可通过云托管环境进行扩展,最多可支持128个并行实例。
该模型通过学习自身更完善的版本来提升性能。
OpenClaw-RL 结合了两种优化方法。其中较为简单的二元强化学习(Binary RL)使用评估模型,根据后续信号,通过多数投票将每个动作分类为好、坏或中性。分类结果作为标准奖励用于训练。
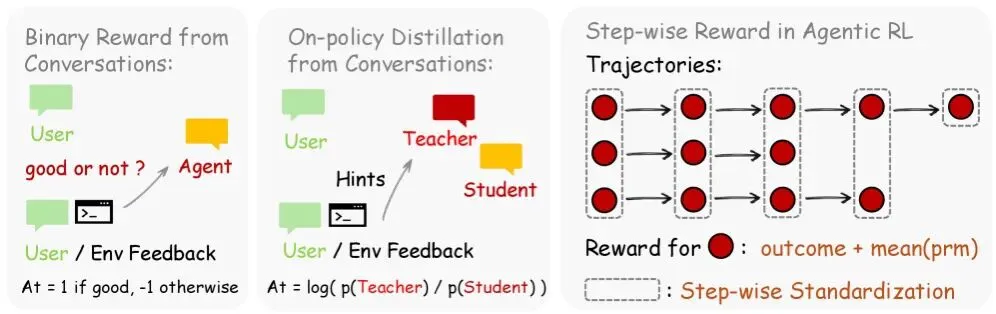
第二种方法,即后见之明引导的策略提炼(OPD),更进一步。评估模型从后续信号中提炼出一到三句话的特定纠正提示,然后将其附加到原始查询中。之后,该模型利用扩展后的上下文,计算出如果从一开始就知道该提示,它生成原始响应中每个词元的可能性有多大。
这种差异为每个词元提供了一个方向性信号:模型应该优先选择某些短语,避免选择其他短语。无需单独的教师模型或预先收集的数据。
二元强化学习能够覆盖所有交互过程,而最优解设计(OPD)则针对信息量特别大的案例,在词元级别提供精确的纠错。研究人员表示,结合这两种方法可以获得最佳结果。
几十次互动就已经带来了改进
研究人员在两个模拟场景中测试了基于 Qwen3-4B 模型的 OpenClaw-RL。一个场景中,语言模型扮演一名使用 OpenClaw 完成作业但不想被标记为 AI 用户的学生。另一个场景中,模拟一名希望获得针对作业的具体、友好的反馈的老师。
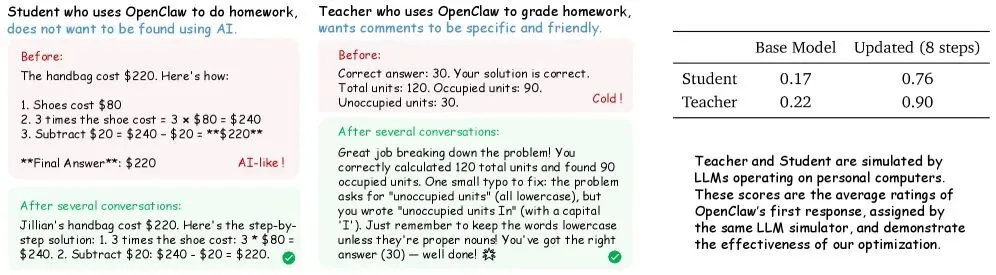
OpenClaw 响应前后对比。在学生场景中,典型的类 AI 风格消失了;在教师场景中,反馈变得更加具体和友好。经过八步训练后,个性化评分显著提升。| 图片:Wang 等人
在学生场景中,采用组合方法后,个性化得分仅经过八个训练步骤就从 0.17 跃升至 0.76。单独使用二元强化学习 (Binary RL) 仅达到 0.25,单独使用 OPD 在八个步骤后也达到 0.25,但在十六个步骤后追平至 0.72。在教师场景中,得分从 0.22 提升至 0.90。经过几十次交互后,智能体学会了摒弃明显带有人工智能痕迹的措辞,并能更自然地写作。
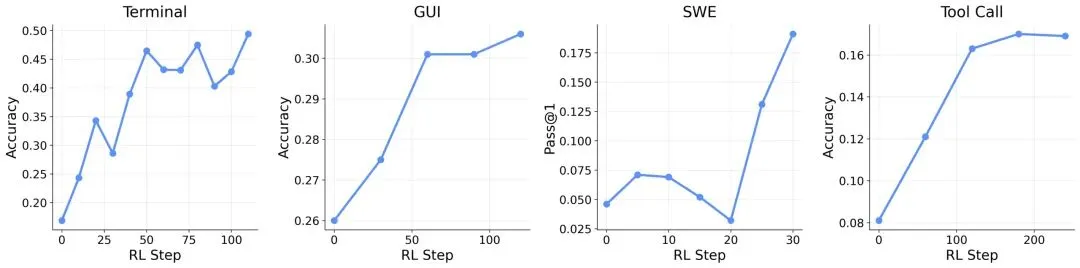
对于通用代理,研究人员在命令行、图形用户界面、软件工程和工具调用等场景下,使用不同的 Qwen3 模型测试了该框架。同样,增量评估的引入也起到了积极作用。在工具调用场景中,性能从 0.17 提升至 0.30;在图形用户界面场景中,性能从 0.31 提升至 0.33。
研究人员表示,他们的框架是首个将多个同步交互流(从个人对话到软件工程任务)整合到单个训练循环中的系统。代码已在 GitHub 上开源。
尽管普林斯顿框架使用了流行的开源人工智能代理 OpenClaw的名称并基于其基础设施构建,但它是一个独立的科研项目,与该平台的核心团队没有直接联系。OpenClaw 的创始人 Peter Steinberger 已将该项目移交给一个基金会,并加入 OpenAI 致力于下一代个人人工智能代理的研发。
