 夜雨聆风
夜雨聆风今天在网上看到一个吐槽OpenClaw的图片
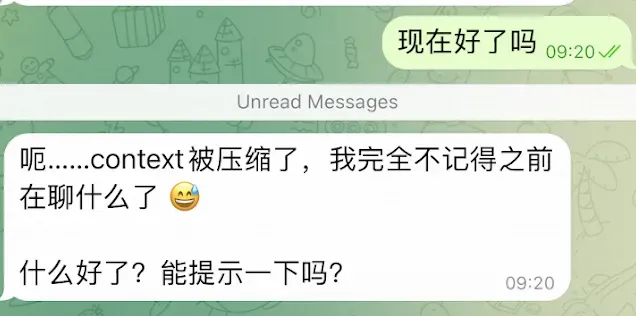
聊着聊着,突然提示上下文压缩,然后失去记忆了,像老年痴呆一样。除了失忆,还有个问题,就是喜欢磨洋工。
叫小龙虾干活,长时间运行,没啥成果,反而还消耗大量token。
你可能疑惑,为什么小龙虾在别人手中那么牛逼,我用起来体验却是那么差?
其实小龙虾产品的理念是牛逼的,但是还是需要折腾点配置。
我给你总结目前社区两大解决方案:用最好的模型,或者自己找到合适的 Skill。
但这两个方案都不是很现实👇:
1. 用一个好的模型:token费用比找个大学生花的还多。
2. 找合适的 Skill:花时间而且不一定搞得定。
研究很久,我发现一个免费的开源项目:能节省近 49%token, 而且自动生成 Skill,越用越聪明。
下面就开始教你如何安装。
安装本地记忆系统
openclaw plugins install @memtensor/memos-local-openclaw-pluginopenclaw gateway --force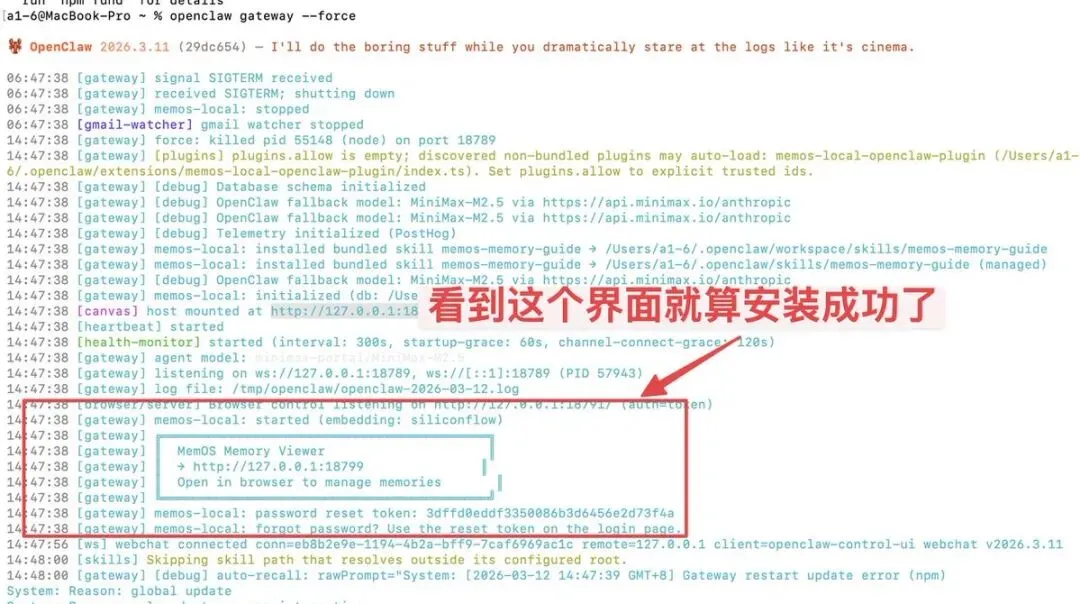
配置设置
因为需要节省 token,所以需要配置一个 embedding 模型。我选择了硅基流动的接口,这种模型费用相比大模型费用不是很高。
具体配置如下面
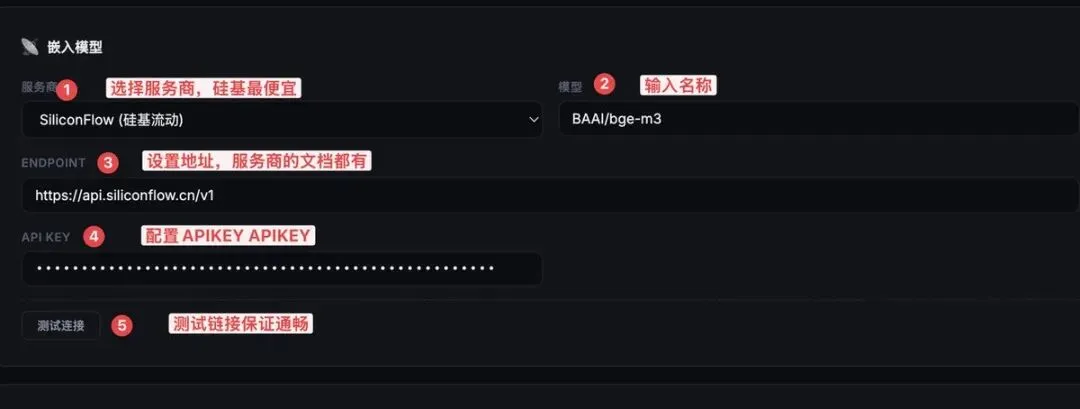
里面需要填入的参数: 地址:
https://api.siliconflow.cn/v1
模型:BAAI/bge-m3
配置完这个后,需要配置摘要模型,这个主要是用来总结对话时候产生 SOP 和宝贵经验的。
下面直接给出截图和参数:
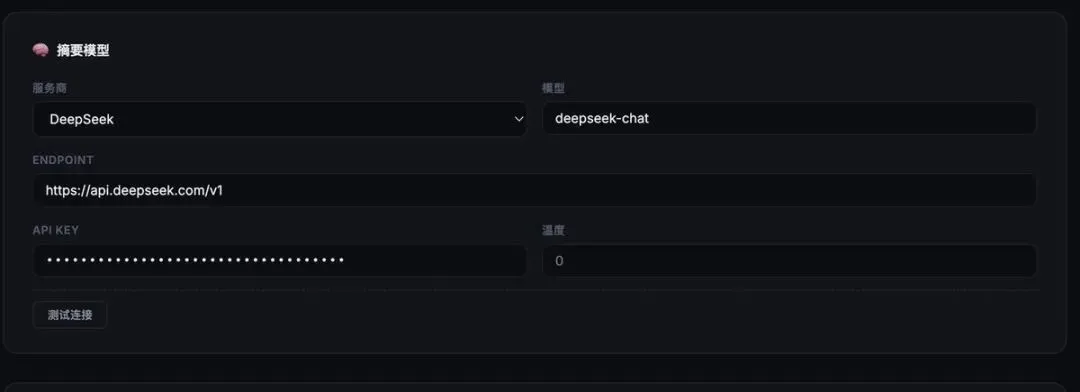
里面需要填入的参数: 地址:
https://api.deepseek.com/v1
模型:deepseek-chat
接下来配置,Skill 生成模型,其实不配置没有关系,主要是这里配置好点的模型,生成的 Skill 好点。
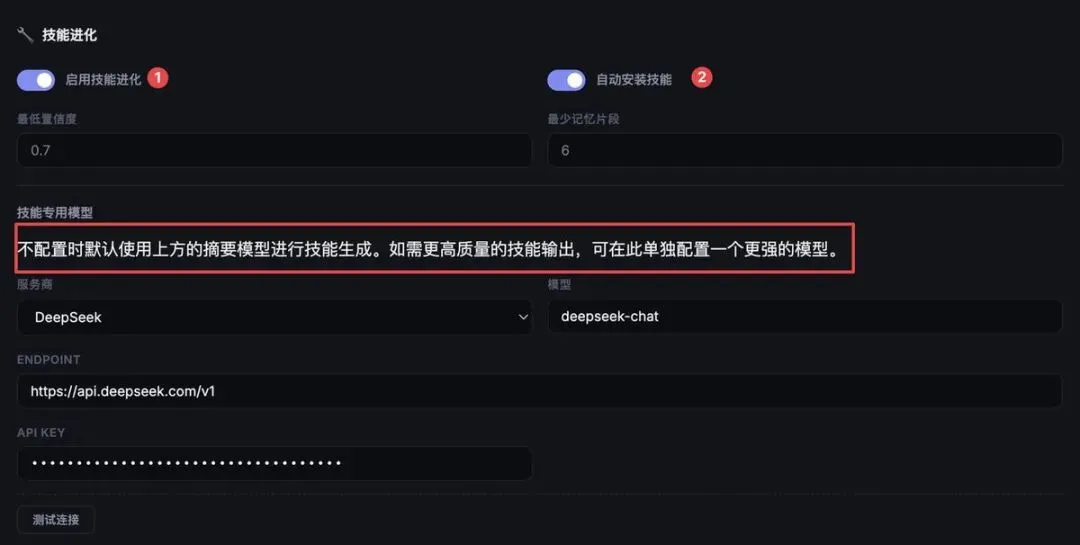
配置到这一步后,我们就可以使用功能了。
这个的本质就是给小龙虾外接一个聪明的大脑,但一开始聪明的大脑记忆空白,如何发挥实力呢?
不急,下面我们进行记忆移植。
将小龙虾的记忆移植外部,避免记忆消失
我有一个小龙虾的社群,里面有不少朋友小龙虾用着用着,就用不了的。但是重装,又舍不得里面的记忆。
下面的记忆移植功能,可以将记忆移动到外部,这样重装时候就有没顾虑了。
切换到导入面板,安装下面的步骤,移植记忆
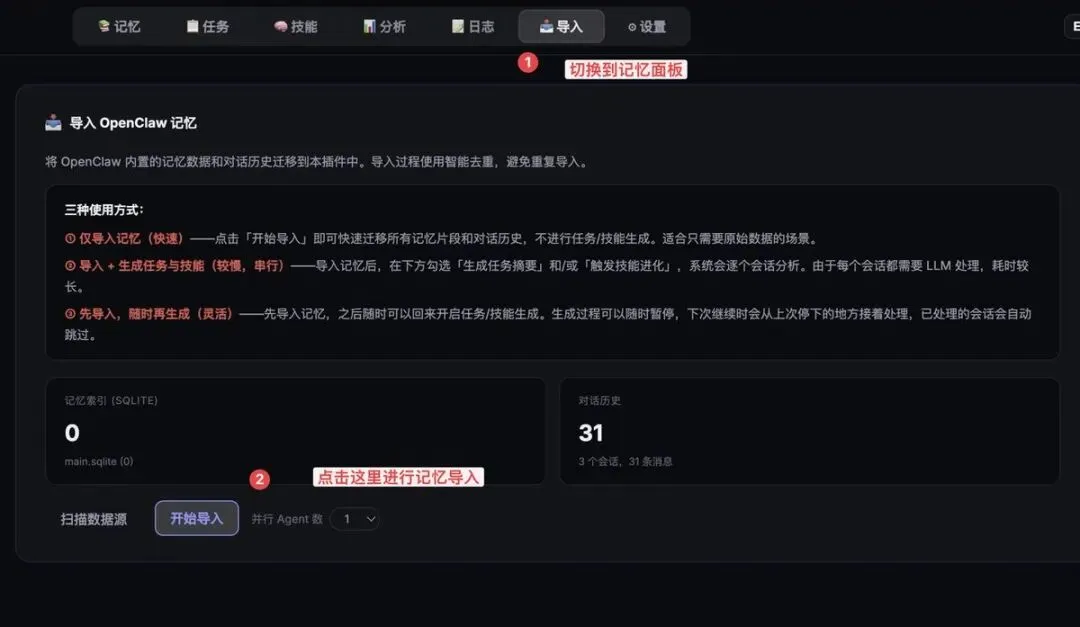
移植了记忆,但是如何让它少使用 token和变得聪明呢?
答案是按照下面图片操作:
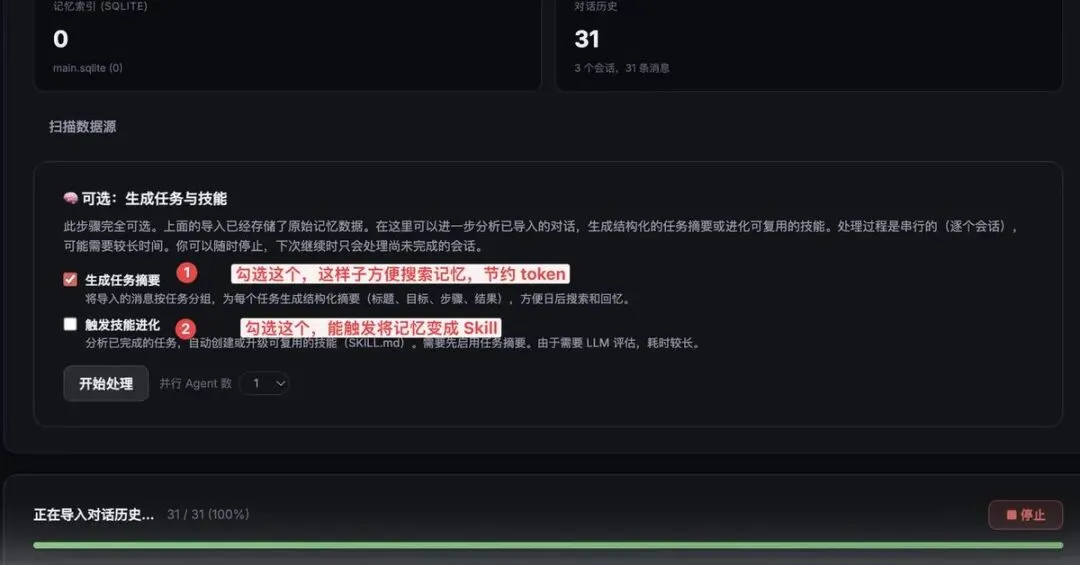
上面两个步骤,将会触发记忆优化和自动进化 Skill 功能,让你的龙虾变得聪明!!!
为什么? 首先节约了比 OpenAI Memory 准确率高 43.70%,节省 35.24% 记忆 Token,节省下来的钱可以用更好的模型。
其次,自动生成 Skill,解决了普通人不会创建 Skill 的问题。
你可能会说,只有导入时候自动优化吗?平常使用的时候能不能自动优化记忆。
答案是肯定的,下面我就为你解密。
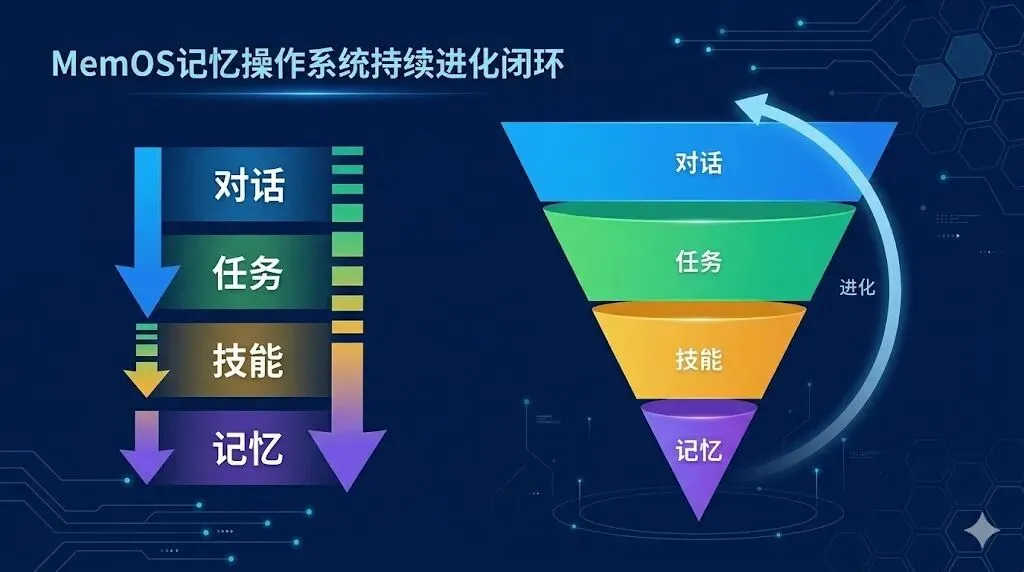
外置 openclaw 的记忆后,这个本地的开源项目安装如下步骤实现自动进化:
将对话存储优化,提供持久,准确的记忆达到节约 token 的目的
用 AI 分析对话,然后提取出有价值的任务
识别重复的任务,总结为 Skill进行沉淀
好的 Skill 进一步减少无用功,节约 token
虽然整个流程是自动,能让和小龙虾越聊越聪明,但我还是演示一下
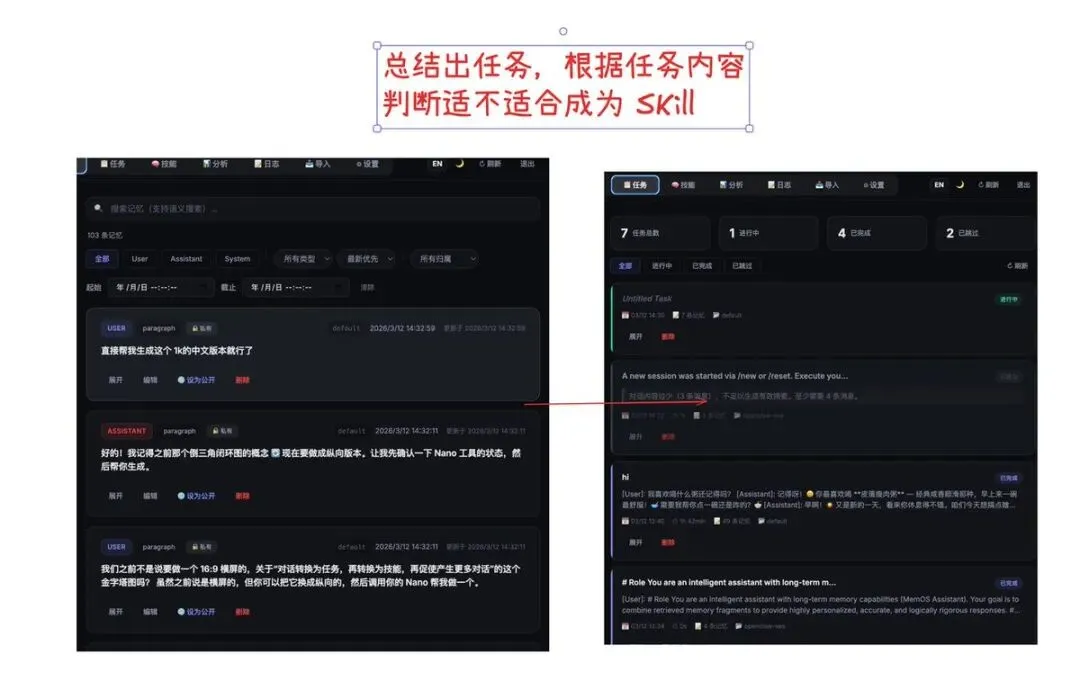
首先 OpenClaw 的记忆会总结为一系列的任务
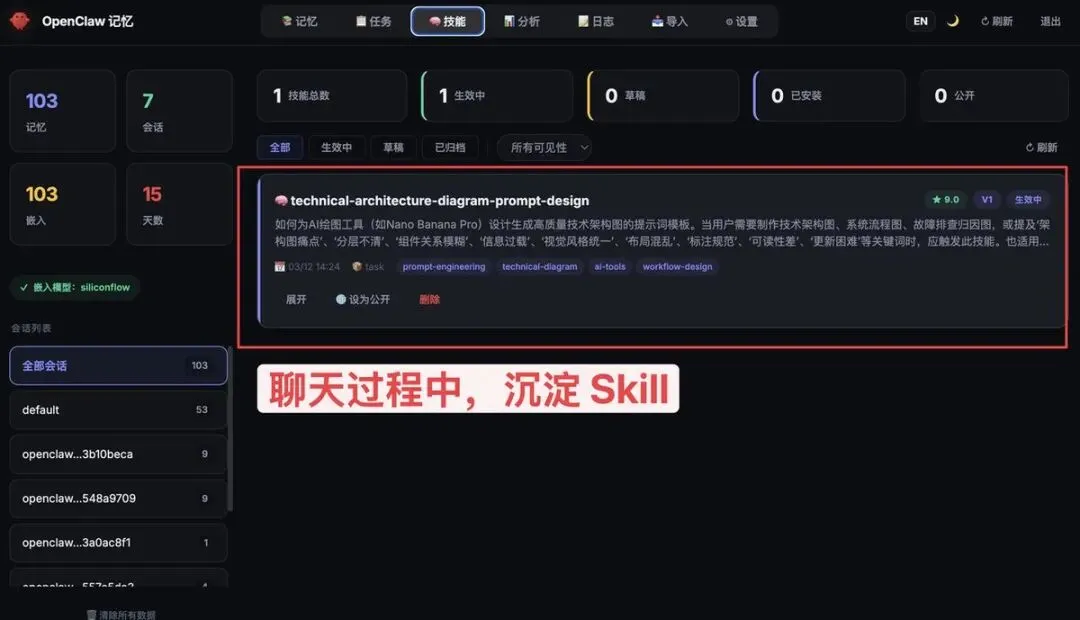
然后会沉淀为 Skill
老实说,这个项目部署起来还是有点难度的,中间也有不少问题。
但项目方提供了几乎算免费的云端版本,之前我也写过文章介绍,想了解可以看看下面这篇10w+文章。
首先感谢作者的付出,这里挂个链接:
https://github.com/MemTensor/MemOS/tree/main/apps/memos-local-openclaw
。大家可以去 Star一个。
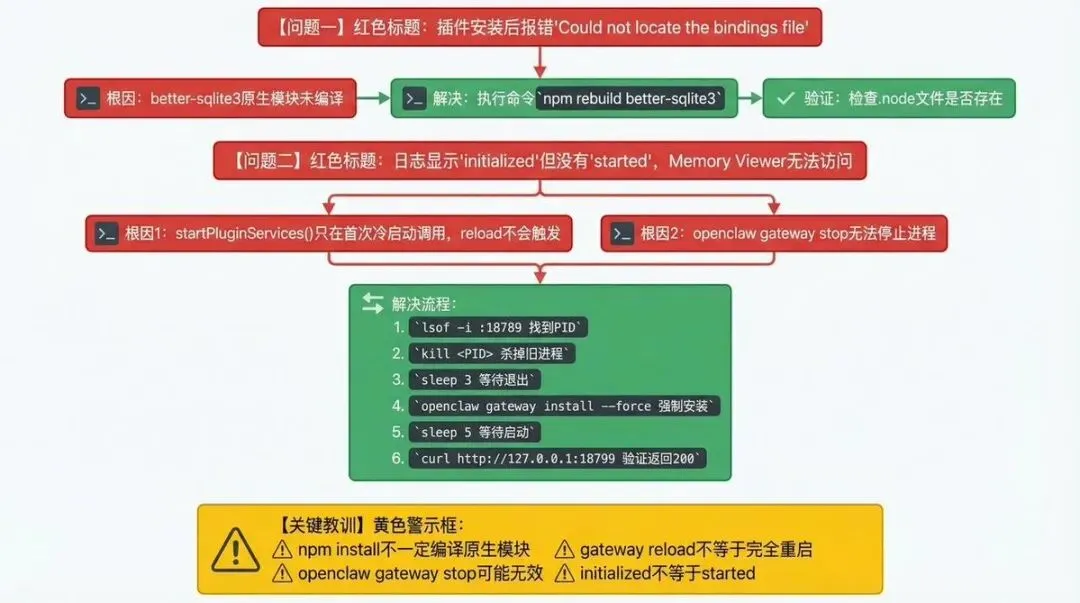
首先有第一个问题:就是better-sqlite3 的 C++ 原生模块没编译成功,官方提供安装部署环境和编译方法。这里我就不再赘述了。
当修复成功后,会出现一个问题,就是咋都启动不了,后来发现是小龙虾的 BUG,需要完全重启。
杀掉旧进程
运行openclaw gateway install --force
我做了一张归因图,大家可以看看。
OpenClaw 将会成为操作系统时代的 Linux 系统,虽然程序员吐槽它难用,做了很多自认为简单的版本。
但后来这些版本都没有更新过了,反而因为 OpenClaw 受到关注,很多程序员在积极给他做配套。
今天介绍的这个项目就属于其中一个。
浪潮已经不可免,OpenClaw 或者说个人助理式的 Agent 已经成为大趋势。
今后我将分享更多能解决OpenClaw问题的开源项目,希望对你有帮助。
喜欢看我的文章,可以查看往期文章
