 夜雨聆风
夜雨聆风你是不是也经历过这种“上线前夜最真实的噩梦”:
• 代码写完了,提示词调顺了,结果模型一限流/抽风——整套流程直接停摆 • 供应商 A 的 baseUrl、供应商 B 的apiKey、供应商 C 的模型名……每换一次就要改一遍配置甚至改代码• 真要长期跑自动化/智能体,最难的根本不是“写得多聪明”,而是:怎么稳定、怎么省钱、怎么不被单点卡死
如果你已经有一个「第三方 API 大模型中转站」(一般是 OpenAI 兼容的网关),那恭喜你:
你离“随时换模型不改代码”只差一步:把它接进 OpenClaw。
这篇文章我不讲虚的,直接给你一份能落地的完整方案:
• OpenClaw 怎么把中转站接成一个 Provider( baseUrl + apiKey)• 怎么在同一套工作流里切 gpt-5.2/gpt-5.2-codex/ 便宜跑批模型• 怎么做“主力 + 备份 + 跑批”的三层策略,稳定性直接上一个台阶 • 附:Codex(以及类 Claude Code/命令行编程助手)怎么指向你的中转站
安全提醒:本文中的 key 仅作格式示例。真实密钥不要发群聊、不要进截图、不要进仓库。怀疑泄露就立刻重置。
很多人上来第一句话是:“哪个模型便宜?”“哪家送额度?”
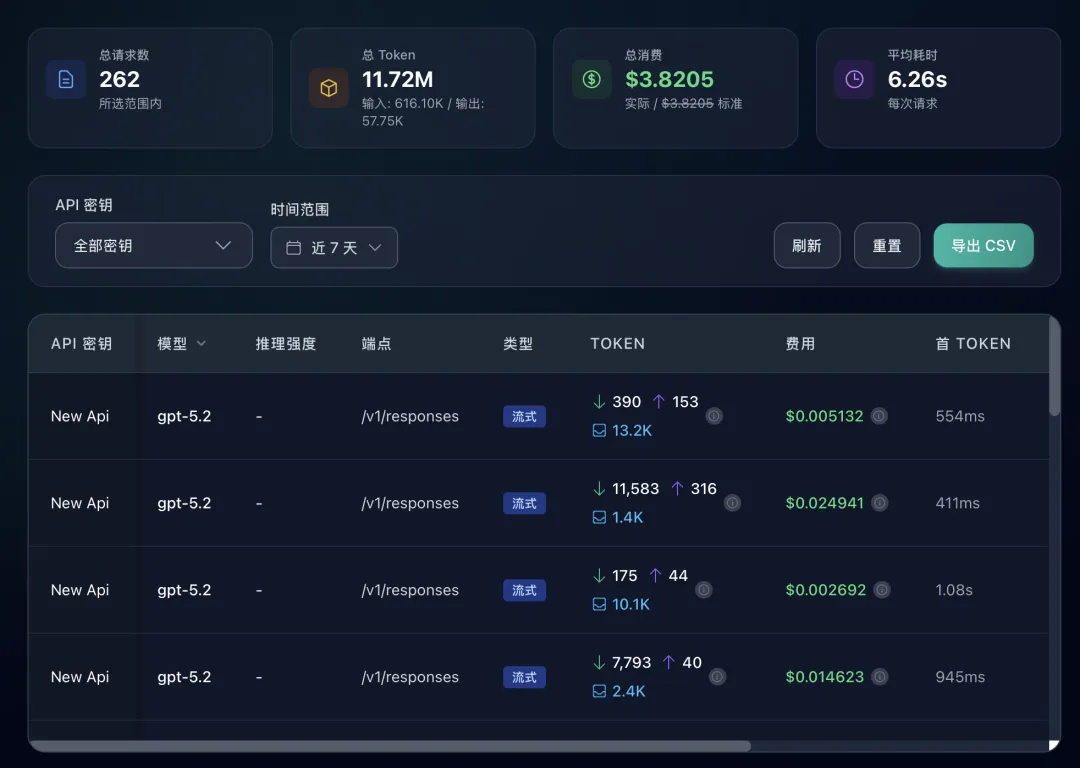
但真正在生产环境里让你省心的,是下面这三件事:
1. 统一入口:业务侧只认一个 provider;换模型不再改业务代码 2. 快速对比:同一任务一键切不同模型,质量/速度/成本一眼就明白 3. 抗波动:某家限流、抽风、掉线时,立即切到备份模型继续跑
一句话总结:
额度只是门槛;路由能力决定你能不能长期稳定用。
1)最短落地路线:把中转站当成 OpenAI 兼容 Provider
中转站的 API 入口是:
• https://sub.jlypx.de/
这类服务通常会提供:
• baseUrl:例如https://sub.jlypx.de/v1• apiKey:形如sk-xxxxxxxxxxxxxxxxxxxxxxxx• model:例如gpt-5.2/gpt-5.2-codex
OpenClaw 的核心思路:
在
~/.openclaw/openclaw.json里新增一个 provider,然后用provider/model指定默认模型。
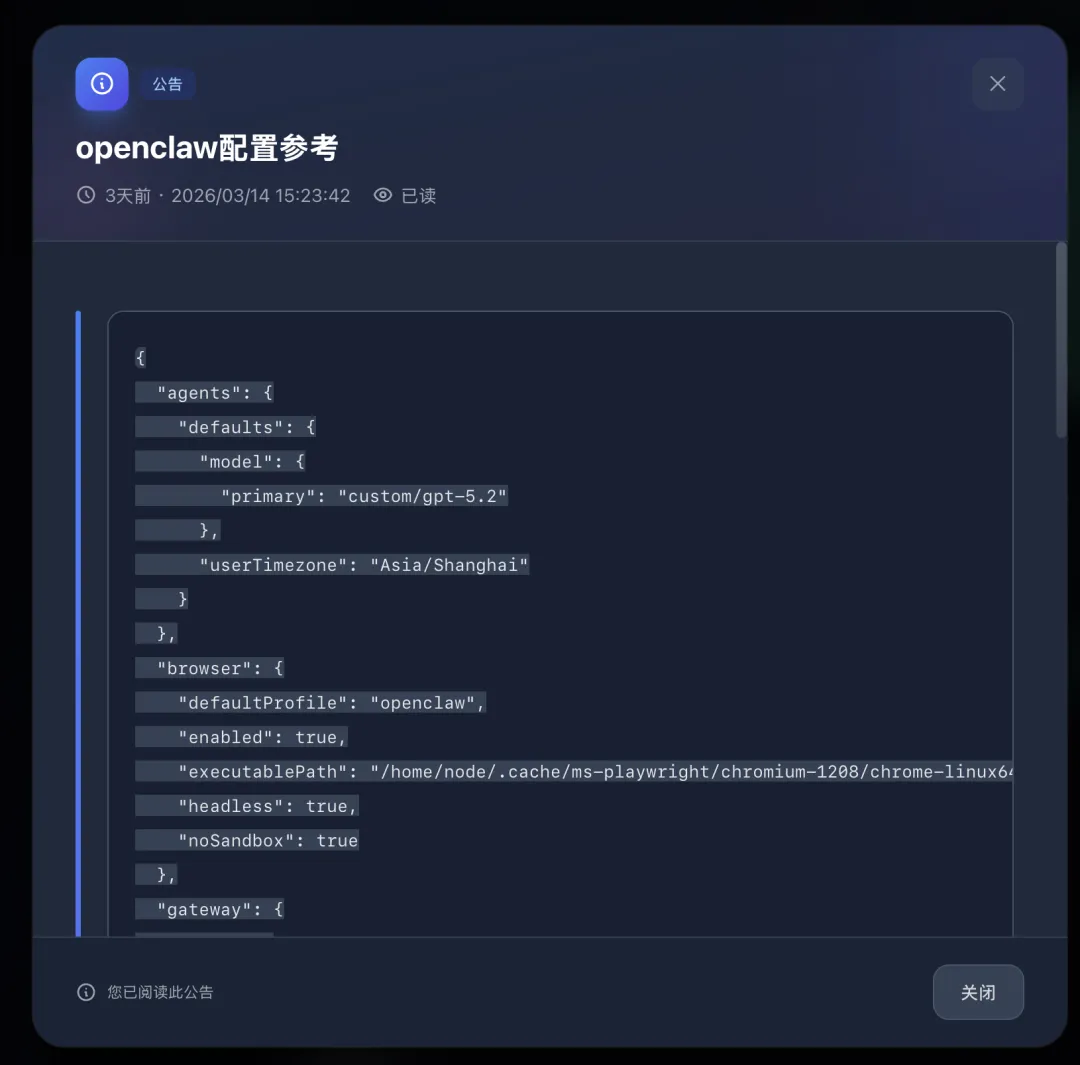
2)OpenClaw 手动配置(推荐):只“新增/合并”,不要覆盖原文件
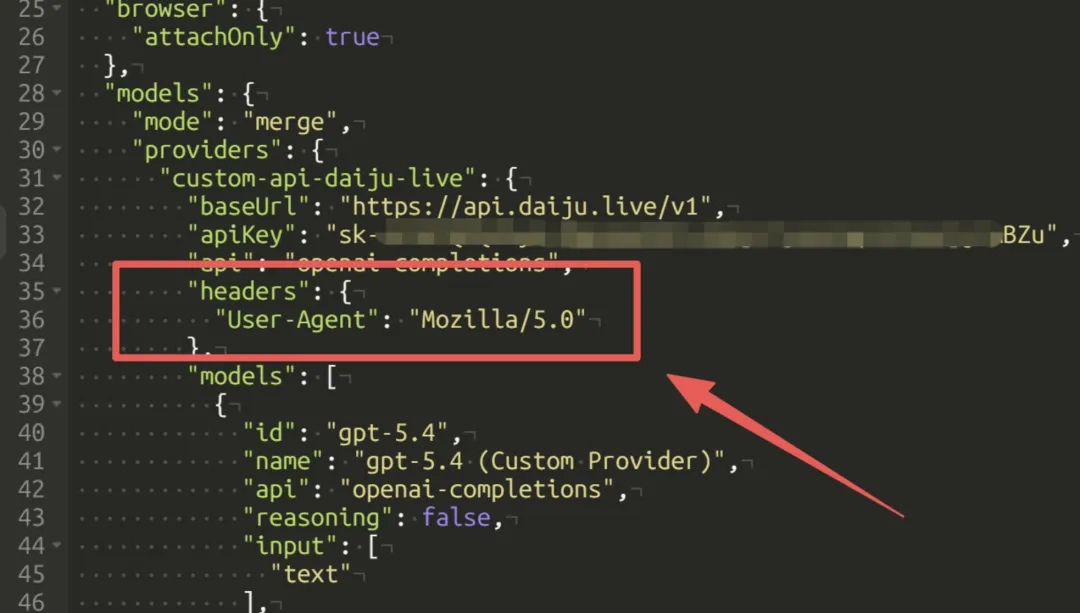
把下面这段“合并进” ~/.openclaw/openclaw.json 里即可(重点是 models.providers):
{ "models": { "providers": { "free-gpt": { "baseUrl": "https://sub.jlypx.de/v1", "apiKey": "sk-***", "api": "openai-responses", "headers":{"User-Agent":"Mozilla/5.0"} } } } }}然后把默认模型指到你想用的模型(例如先用 gpt-5.2):
{ "agents": { "defaults": { "model": { "primary": "free-gpt/gpt-5.2" } } }}2.1 这里最容易踩的 4 个坑
• 不要整段覆盖:只“新增/合并字段”。否则你之前其他 provider 配置会被抹掉 • baseUrl是否需要/v1:多数 OpenAI 兼容网关需要(你给的就是/v1)• 模型引用格式固定: provider/model(只按第一个/切分)• key 不要硬编码进公开仓库:最好用本机私有配置文件或环境变量注入
3)三步自检:确认你真的接通了(不是“配了但没生效”)
配置完,按这三步验证:
openclaw models statusopenclaw models listopenclaw models set free-gpt/gpt-5.2你要看到的现象是:
• status能正常返回 provider 状态• list能列出你中转站提供的模型• set切换后,后续任务确实走你指定的模型
如果这三步都 OK,说明你已经把“换模型”从改代码,变成了改配置。
4)模型怎么用得又稳又省:三层策略(主力/备份/跑批)
我建议你不要只选一个“最强模型”,而是按任务分层:
4.1 主力模型:写作、方案、长文质量优先
• free-gpt/gpt-5.2
适合:
• 结构化写作(标题/摘要/正文) • 观点梳理、逻辑链、对比分析 • 长文一致性
4.2 备份模型:代码、脚本、工具调用更顺手
• free-gpt/gpt-5.2-codex
适合:
• 写脚本、改配置、排错 • 需要更强“工程味”的任务
4.3 跑批模型:便宜量大
中转站还提供 gpt-5-gpt-5.2 等模型:
• 用来跑批(大量摘要、批量改写、批量生成)更划算
一句话原则:
默认用主力;遇到限流/抽风立刻切备份;需要量大就上跑批。
5)把“切模型”写进日常动作:你会越用越爽
很多人接了中转站之后还是“不会用”,原因是:
• 只把它当成“换了一个接口” • 没把切换动作变成习惯
你可以给自己定一个简单 SOP:
• 写稿、出方案: gpt-5.2• 写代码、修 bug: gpt-5.2-codex• 批量任务:低成本模型
当你把它变成条件反射,就等于把生产力“稳定地加成”了。
6)Codex(以及类似命令行编程助手)怎么指向你的中转站
你给的“Codex 配置片段”在群里已经被拼接得很乱,我这里给一份干净、可理解的通用思路:
本质就是:把 provider 设成 custom,并把
base_url指向你的https://sub.jlypx.de/v1,再填api_key。
不同工具的配置文件路径/字段名不完全一样,但关键字段通常只有三个:
• provider = custom• base_url = https://sub.jlypx.de/v1• api_key = sk-...
如果你告诉我你用的是:
• OpenAI Codex CLI / Claude Code / Gemini CLI / 还是你自研的客户端
直接使用Agent把配置文件的正确路径 + 完整示例给你补齐(并提醒哪些字段千万别进仓库)。

7)避坑清单(这段建议你直接收藏)
1. 密钥泄露是最常见事故:群聊、截图、录屏、Pastebin 都算高风险 2. 别宣传“永久免费/无限免费”:很容易引发误解或风控 3. 上线前至少准备一个备份模型:单点是灾难的开始 4. 把模型切换变成配置,不要写死在业务里:这就是你接中转站的意义
8)一页结论(给忙人)
• 中转站的价值,不是“额度”,而是让你“随时换模型不改代码” • OpenClaw 接入关键就两步:新增 provider + 用 provider/model指定默认模型• 真正能跑长期的玩法:主力 + 备份 + 跑批 三层策略
