 夜雨聆风
夜雨聆风
推荐阅读:
扔份PDF进去,直接变出一个自带老师和同学的沉浸式课堂!清华开源多智能体神器OpenMAIC,联动爆火“小龙虾”OpenClaw绝了
高斯溅射移动端落地:手机跑 3DGS 不卡了?4.6MB 模型干到 127 帧,Mobile-GS 直接封神!
仅0.9B参数!智谱联合清华开源GLM-OCR:退回“两阶段”反杀端到端,吞吐提速50%成RAG文档解析天花板
实时渲染3D空间,InSpatio-WorldFM开源!一个“能玩”的“实时帧”世界模型,4090单卡7FPS
小红书又双叒叕出手!工业级“四合一”语音系统 FireRedASR2S 炸场,100多种语言和20多种方言+唱歌都能精准拿捏!
真正的情感自由!开源 TTS 卷出新高度:Fish Audio S2 炸场,像写剧本一样“导演”情绪,100ms极速开嗓!
从OpenClaw的野蛮生长到Agent接管一切:港大开源CLI-Anything,让全网软件一夜变身“原生工具”!
颠覆视觉大模型底层逻辑!腾讯开源“端侧小钢炮” Penguin-VL:抛弃 CLIP,让纯文本大模型直接看懂世界!
SoulX-FlashHead 开源:单张 4090 跑出 96FPS,1.3B 参数实现无限流高保真数字人,comfyui已支持
北大字节联合开源 Helios:14B 参数19.5FPS 实时生成长视频 + 分钟级零漂,迎来原生架构革命
微软 Phi-4 多模态开源了:用 2000 亿 Tokens,做出 Pareto 最优的 15B 推理模型,按需思考,将推理成本砍到脚脖子
小红书开源新王炸FireRed-OCR ,2B 小模型登顶 SOTA,告别 Markdown 表格散架,表格公式再也不崩了
基于 OpenClaw 的移动端重构:ClawMobile 来了,跨 App 复杂任务 100% 搞定,让手机 Agent 彻底本地跑起来
CVPR2026开源的 3D 重建神器,手机拍的照片就能用。Adobe开源新作 tttLRM:打破 Transformer 瓶颈,线性复杂度实现大场景 3D 重建
端侧 AI 的王炸!Mobile-O 正式开源:不卷云端大参数,1.6B 实现理解生成一体化,手机 3 秒出图
浙大开源Fuse3D!多图生 3D,20 秒出精准模型:多图融合 + 自动对齐,把 “局部编辑” 做到极致
42k小时数据+零样本!SoulX-Singer开源:中英粤三语自由切换,歌词随意改,音色随便换,AI歌声合成’准’到离谱”
9B小钢炮!面壁MiniCPM-o 4.5焕新升级:能在Mac跑的全模态AI,边看视频边聊天,还能克隆声音
资源导航:
• 论文链接:https://arxiv.org/abs/2603.10165 • 项目主页:https://yinjjiew.github.io/projects/openclawrl1 • GitHub Repo:https://github.com/Gen-Verse/OpenClaw-RL* • 发布机构:Princeton University(普林斯顿大学)等联合团队 • 发布日期:2026年3月10日(技术报告发布),核心代码持续更新至2026年3月中旬 • 开源协议:Apache 2.0 License
最近这段时间,科技圈有两条主线热度最高。一条是 DeepSeek-R1 证明了纯强化学习(RL)在推理模型上的 Scaling Law,让整个开源社区对使用 GRPO 和 PPO 优化大模型陷入了狂热;而另一条主线,则是以一只红色小龙虾为标志的开源智能体框架——OpenClaw 的彻底爆火。大家都在疯狂“养龙虾”,把它接入自己的电脑当本地助理,帮着处理日常工作、执行 GUI 操作或者充当 SWE Agent 敲代码。
但当你真正想把这两条主线结合起来时,会发现一个极度现实的痛点:你想用最前沿的 RL 技术,去让手头最实用的 OpenClaw 变得更聪明,现有的强化学习基建却显得非常笨重且难用。
为什么难用?因为传统的 RL 系统(哪怕是大家常用的主流框架)基本上都是“离线-批处理”模式的。也就是说,当你的 OpenClaw 助手在真实环境里写错了一段代码,或者点错了一个按钮,你顺手在聊天框里纠正了它(“不对,这里应该用 pandas 处理”),这个极其宝贵的“纠错数据”在对话结束后就随风飘散了。你想让它长记性,必须把数据收集起来,把模型服务停掉,跑一波训练,然后再重新部署。
如果想让一个与真实环境交互的 Agent 在“真实的使用过程中,边聊边学、边错边改”,在以前的框架下几乎是做不到的。
直到最近,普林斯顿大学等联合团队直接打通了这个闭环,开源了一个名为 OpenClaw-RL 的项目。

简单总结一下,这是一个全异步的强化学习框架。它的核心愿景只有一句话:Train Any Agent Simply by Talking(仅仅通过对话,就能训练任何智能体)。
这个项目与我们之前介绍过的开源个人 AI 助手 OpenClaw 是深度绑定的。如果你一直在用 OpenClaw 作为你的本地大模型客户端,那么接入 OpenClaw-RL 之后,你的这个本地助手就不再是一个“永远记不住教训”的静态模型了。你在聊天中纠正它的每一次错误,都会被转化为强化学习的梯度,让它在后台默默进化,变得越来越懂你的偏好。
不仅如此,除了个人助手,它还提供了一整套支持大规模环境并行的通用 Agent RL 基建,涵盖了终端(Terminal)、图形界面(GUI)、软件工程(SWE)和工具调用(Tool-call)等硬核真实场景。
老规矩,咱们先深挖它的底层技术细节(基于论文和源码),再看实测表现,最后讲讲普通开发者怎么在本地或者云端把它跑起来。
要理解 OpenClaw-RL 到底解决了什么问题,我们要先看看当前大模型交互中的“数据浪费”现象。
在我们日常使用大模型(比如让它写一段 Python 脚本)时,如果它写错了,环境会抛出一个报错(比如 SyntaxError),或者你会回复一句:“不对,这里应该用 pandas 处理而不是原生的 dict,重写一下。”
在现有的系统中,这个报错信息或者你的回复,仅仅被当作了下一轮对话的“上下文(Context)”。当这次会话结束后,这些数据就被丢弃了。
论文中一针见血地指出,这些紧跟在模型动作之后的信号(称为 Next-state signals)实际上包含了极其珍贵的两种信息:

1. 评估性信号(Evaluative signals):这代表了模型刚才那步做得好不好。比如测试用例通过了,或者用户直接结束了对话,说明做得好;报错了,说明做得差。这其实就是最天然的过程奖励(Process Reward)。 2. 指导性信号(Directive signals):这比单纯的打分更进一步。当用户说“你应该先检查文件是否存在”时,不仅说明上一步做错了,还明确指出了Token级别的修正方向。
OpenClaw-RL 的核心贡献,就是构建了一套机制,把这两类被浪费的信号实时拦截下来,转化为强化学习的训练养料。
要实现“边用边学”,最大的工程拦路虎是阻塞问题(Blocking)。
试想一下,如果模型在服务你的同时还要跑 RL 训练,一旦它开始计算梯度,你的聊天界面可能就会卡死几十秒;或者如果是一个 SWE Agent 正在后台跑长达几十分钟的编译测试,整个 RL 训练流就会被迫停下来等它。
1. Infra 层:四组件全异步解耦
为了解决这个问题,OpenClaw-RL 基于清华开源的 slime(一个专门针对 LLM 后训练的 RL 框架)构建了全解耦的异步架构。

根据论文的 Figure 1,整个系统被拆分成了四个完全独立的循环:
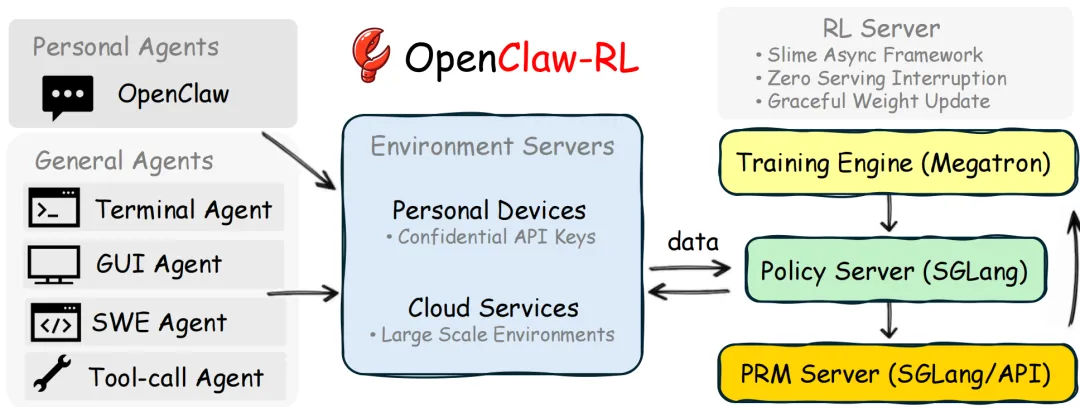
• 策略服务(Policy Serving / SGLang):专门负责响应前端的推理请求,和用户或环境进行交互。 • 环境/Rollout(Environment):负责托管用户设备(Confidential API)或云端的执行环境(沙盒)。 • 奖励裁判(Reward Judging / SGLang):在后台默默读取上一步的动作和环境反馈,运行过程奖励模型(PRM)进行打分。 • 策略训练(Policy Training / Megatron):独立在后台跑 PPO/GRPO 的梯度更新。
这四个组件之间没有任何阻塞依赖。模型在前面正常和你聊天,PRM 在后面给你上一轮的回答打分,Trainer 在更后面用打完分的数据更新权重。当权重更新完成后,再通过“平滑权重更新(Graceful Weight Update)”机制热加载到推理引擎中,真正实现了零服务中断(Zero Serving Interruption)。
2. 算法层:榨干 Next-State 信号的三套拳法
基建搭好了,数据怎么用?这就回到了我们前面提到的那两类被浪费的信号。OpenClaw-RL 提供了三种优化范式:

方法一:二进制强化学习(Binary RL) 这主要是针对“评估性信号”。 当系统收到环境的隐式反馈(比如执行报错、退出码非零,或是用户重新问了一个类似的问题表达不满)时,后台的 PRM 会给出 +1(好)、-1(坏)或 0(中立)的标量分数。 论文中采用了类似 GRPO/PPO 的替代损失函数(Surrogate Loss)来优化。虽然信号比较粗糙(只有一个标量),但它的优势是覆盖面广(Density High),只要有交互就能打分。
方法二:事后引导的同策略蒸馏(Hindsight-Guided OPD) 这可以说是这篇论文在算法上最出彩的地方,专门用来吸收“指导性信号”。 当你给出了明确的文本纠正时(比如:“别用循环,用矩阵乘法”),只给一个 -1 分太浪费了。OPD 是怎么做的呢?
1. 提取 Hint:先用一个 Judge 模型从你的回复中提取出一句凝练的指导(Hint),比如 [HINT_START] 使用矩阵乘法替代循环 [HINT_END]。2. 构建增强版 Teacher:把这个 Hint 偷偷塞进大模型的历史上下文里,当作它已经“提前预知”了正确答案。此时,模型在拥有 Hint 的情况下生成的 Token 分布,就被视为完美的 Teacher 分布。 3. Token 级对齐:计算当前 Student 模型(没有 Hint 的状态)和 Teacher 模型在每一个 Token 上的概率差(Log-probability gap)。这个差值就是一个精确的、方向性的优势信号(Advantage),直接指导模型在生成这句话时,哪些词该加权重,哪些词该减权重。
方法三:混合强化学习(Combination Method) 成年人不做选择。论文在实验中发现,Binary RL 信号密集但粗糙,OPD 信号稀疏但极其精准(只有用户给出长回复时才触发)。因此,最好的方法是将两者的损失函数加权融合。
我们用 Markdown 表格还原一下论文中关于这几种方法的客观对比(参考论文 Table 2):
| 信号类型 | |||
| 优势函数 (Advantage) | |||
| 密度 (Density) | |||
| 反馈类型 | |||
| 信号丰富度 |
讲完了偏硬核的算法,我们来看看它到底“有什么用”。OpenClaw-RL 在设计上直接切分了两条赛道。

Track 1:个人智能体的极致个性化 (Personal Agent Track)
在这个场景下,环境就是你自己的电脑(Personal Devices),通过 Confidential API 与后端的 RL 服务器通信。
论文做了一个非常有趣的模拟实验(见 Appendix B): 设定 A(学生视角):一个学生用 OpenClaw 做数学作业(GSM8K),但他不想被老师发现自己用了 AI。 设定 B(老师视角):老师用 OpenClaw 批改作业,希望 AI 的评语具体且友好。
如果用普通的预训练模型(如 Qwen3-4B),它的初始回答往往是典型的“AI 味”:满篇的加粗 **,死板的“步骤一、步骤二、结论是”。 但在接入 OpenClaw-RL 的 Combined 方法 后,发生了什么?
根据论文提供的数据和图表: 仅仅经过 36 次 做题交互(学生场景)和 24 次 批改交互(老师场景),模型的风格就发生了肉眼可见的蜕变。

在 36 步迭代后,模型学会了彻底摒弃 ** 加粗,去掉了机械的步骤前缀,甚至会用更口语化、人类更习惯的换行方式来输出数学公式。而在老师场景下,它学会了主动添加 [emoji] 和极具情绪价值的鼓励语。
客观数据(参考论文 Table 3):
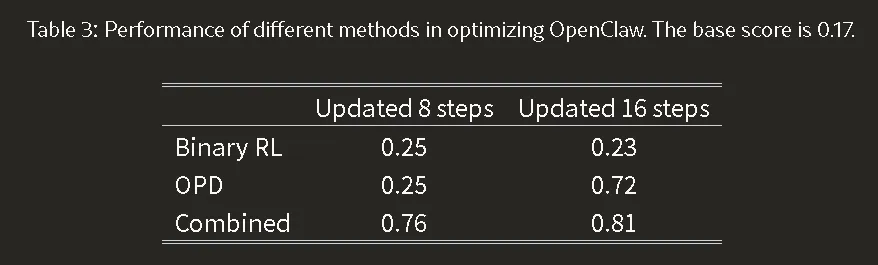
基础个性化得分是 0.17。 更新 16 步后:
• 纯 Binary RL 得分:0.23 (提升微弱) • 纯 OPD 得分:0.72 (提升明显,但起效较慢,因为提取 Hint 的轮次较少) • Combined 混合方法得分:0.81 (收敛极快,效果最好)
这种“只需要自己用一用,模型就长成了我想要的样子”的体验,是静态 SFT 微调完全无法比拟的。

Track 2:真实世界通用智能体的规模化 RL (General Agents)
除了聊天,OpenClaw-RL 还提供了四种硬核环境的 RL 基建:
1. 终端智能体(Terminal Agent):在沙盒里执行 Shell 命令。奖励信号来自于 stdout/stderr和退出码。2. 图形界面智能体(GUI Agent):操作电脑屏幕。基于屏幕状态差异和可访问性树(Accessibility tree)进行视觉反馈。 3. 软件工程智能体(SWE Agent):解决 GitHub 上的 Issue。基于代码差异(Diff)、Lint 输出和测试套件(Test suite)进行奖惩。 4. 工具调用智能体(Tool-call Agent):执行 API 函数。
在这些长视野(Long-horizon)任务中,最大的痛点是稀疏奖励。如果一个修 Bug 的 Agent 做了 20 步才发现失败,你只在最后给它个 -1,它是学不到东西的。
OpenClaw-RL 的解决方式是集成过程奖励(Step-wise Reward)。它在底层引入了类似 RLAnything 的机制,由后台的 PRM 对中间的每一个动作进行打分。
客观数据(参考论文 Table 4):

在 Tool-call 和 GUI 场景下,加入过程奖励(Integrated)对比仅用最终结果奖励(Outcome only):
• Tool-call 成功率:0.30 vs 0.17 • GUI 成功率:0.33 vs 0.31
这证明了,密集的过程监督对于长线 Agent 任务来说是续命级别的存在。
聊了这么多,这套系统要怎么跑起来?官方在 GitHub Repo 中给出了非常详细的指引,而且充分考虑了不同财力玩家的需求。

1. 硬件配置与方案选择
如果你要在本地部署,目前官方主要以 Qwen3-4B、Qwen3-8B 及对应的视觉模型(Qwen3VL)作为基座。
• 土豪/实验室玩法(8张 GPU):
官方默认配置推荐使用 8 张卡(分别分配给 Actor, Rollout, PRM 等进程),环境要求 CUDA 12.9 + Python 3.12。直接通过 slime 框架拉起全量参数微调。
• 平民玩家(单/双卡 LoRA 训练):
好消息是,官方在 2026年3月12日刚刚更新了 LoRA 训练支持!这意味着你不需要 8 张 A100,用少量的消费级显卡也能跑通这个异步循环。
• 白嫖玩家(Zero GPU 方案:Tinker 云端部署):
如果你本地连一张显卡都没有,官方还接入了 Tinker API 平台。在本地只需要跑环境端脚本,模型的推理和训练全部放在云端运行。
2. 一键启动命令(以最推荐的 Combined 方法为例)
假设你已经配置好了环境库,想要启动个人助手优化服务(使用 LoRA):
cd slimebash ../openclaw-combine/run_qwen3_4b_openclaw_combine_lora.sh如果你用的是云端 Tinker 方案:
cd openclaw-tinkerpython run.py --method combine --model-name Qwen/Qwen3-8B --batch-size 16 --prm-m 1 --w-opd 1.0 --w-rl 1.0启动之后,你的服务器会在 30000 端口暴露出一个与 OpenAI 格式完全兼容的 API 接口(比如 http://:30000/v1)。
3. 联动 OpenClaw 客户端
RL 服务器跑起来了,怎么让它接管你日常的聊天? 你需要去部署 OpenClaw 的桌面端。打开配置文件 openclaw.json,在 providers 里面添加一个新的模型节点,把 baseUrl 指向你刚才启动的 RL 服务器 IP 和端口。
{"models": {"providers": {"openclaw-rl": {"baseUrl": "http://<你的服务器IP>:30000/v1","apiKey": "你的SGLANG_API_KEY",...}}}}配置完保存,剩下的你就不用管了。在 OpenClaw 里像往常一样和它聊天、让它写代码、纠正它的错误。底层的 RL 引擎会自动在后台收集数据(Trajectories)、打分(PRM)、并更新策略权重。你的 Agent 就会在你的每一次吐槽中变得越来越好。
为了更客观地看待 OpenClaw-RL 的位置,我们把它和现阶段主流的技术方案做个简单对比:

1. 对比传统 RLHF 框架(如 OpenRLHF, TRL):
传统的 RLHF 框架非常成熟,但它们通常是同步的(Synchronous)。训练时没法推理,推理时没法训练,且必须依赖事先标注好的静态数据集。OpenClaw-RL 最大的差异化价值在于全异步(Async)和在线流式学习(Live Online Learning),这在工程实现上是一次巨大的飞跃。
1. 对比通用 Agent RL(如 DigiRL, WebRL):
DigiRL 等项目主要针对单一的垂直领域(比如纯做设备控制)。而 OpenClaw-RL 试图做大一统,通过底层抽象,把 Terminal、GUI、SWE 等环境的回调都统一成了 Next-state signal。这种架构的好处是扩展性极强。
1. 对比 DeepSeek-R1 采用的纯 GRPO:
GRPO 在有绝对正确答案的数学、代码领域(可以通过规则写死 Reward)大杀四方。但个人聊天助手的偏好、或者复杂的软件工程调试,往往没有非黑即白的 Reward。OpenClaw-RL 引入了自动 PRM 和文本级的 OPD 蒸馏,补足了 GRPO 在开放域和主观偏好场景下奖励信号稀疏的短板。
说实话,存在哪些局限性?(客观痛点分析)
虽然论文展现的前景很美好,但在实际工程落地中,我们也要实事求是地看到它目前面临的挑战:
• 对 PRM(裁判模型)的能力要求极高:因为数据没有任何人工介入,完全靠后台的 Judge 模型来打分和提取 Hint。如果你的基座模型(作为裁判时)很蠢,把错误的代码打成了高分,那么整个策略模型就会陷入“毒责自身”的恶性循环(Reward Hacking 的一种变体)。这也解释了为什么复杂环境下(如 GUI)官方要用 m=3的多数投票机制来保证裁判的准确率。• 全异步架构的调试地狱:解耦成四个独立的循环,意味着在开发和部署时,出现 Bug 极难排查。显存溢出(OOM)、进程死锁等问题在本地多卡部署时对普通开发者依然有一定门槛。 • 硬件开销依然不低:哪怕支持了 LoRA,要同时在显存里驻留 Actor(生成)、Critic/PRM(打分)和 Trainer(训练优化)的模型权重,对于显存的压力依然是普通消费级机器难以承受的。大部分人可能还是得依赖 Tinker 这样的云端方案。
OpenClaw-RL 的出现,代表了 Agentic AI 进化路线上的一个重要分支:从“离线的大规模预训练/微调”,走向了“在线的、千人千面的持续进化”。
它把我们日常使用大模型时敲下的那些抱怨、纠正、报错日志,从“数据废料”变成了“数字黄金”。对于研究多智能体、强化学习,或者只是想给自己打造一个“越用越趁手”的赛博助理的极客玩家来说,这绝对是一个值得深入研究(以及去 GitHub 贡献 Star 和代码)的标杆级开源项目。
毕竟,谁不想拥有一个真正属于自己的、伴随你一同成长的 AI 呢?
(以上信息基于 2026年3月 最新开源资料整理,具体配置指令请以 GitHub 仓库最新 Readme 为准。)
