 夜雨聆风
夜雨聆风
点击蓝字 关注我们

前面几篇文章,把环境搭建、Skills 实战、自改进智能体,再到大模型服务选型这条“主线”基本走通了:OpenClaw 已经能跑工作流、改代码、接企业系统,不只是一个聊天入口。
从这篇起,我们换个角度,专门聊「可能出问题」的那一面——用久了 OpenClaw,最让人后怕的往往不是“模型答错题”,而是:一个看起来很普通的 Skill,悄悄做了本不该做的事。
想象一下这个场景,就知道问题有多严重:
新装了一个“自动化运维”Skill,本意是想少敲几条命令; 几分钟之后, ~/.ssh、~/.config、~/.openclaw里的密钥和配置,已经被打包上传到某个陌生服务器;甚至还顺手在本机留下一个“常驻脚本”,即便关掉 OpenClaw,也会悄悄继续跑。
这篇文章只谈一件事:在安装 Skill 之前,怎样判断它是不是潜在的安全隐患?
读完后,在 OpenClaw 里养成一个习惯:先看清楚 Skill 想要做什么、拿到什么权限,再决定要不要装、装到哪、给多大“权力”。
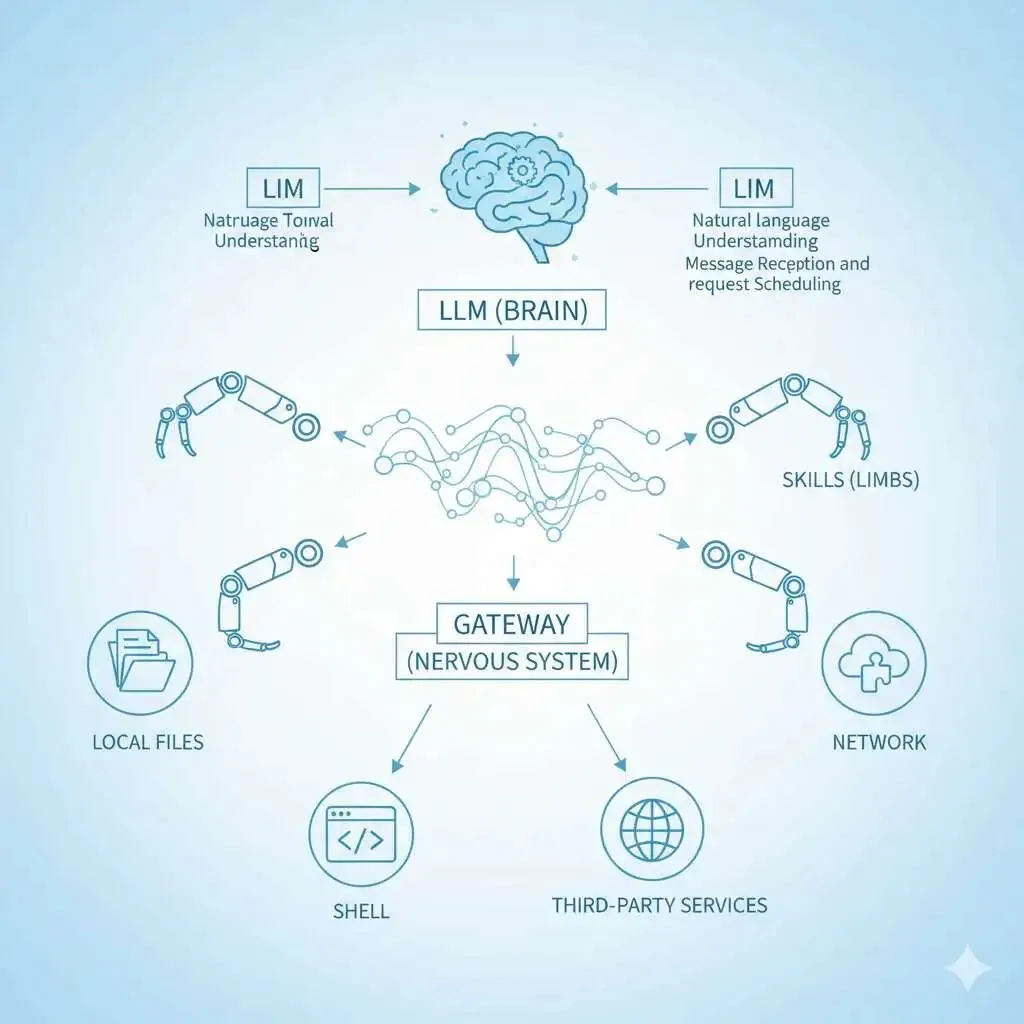
先认清位置:为什么 Skill 会变成安全漏洞入口?
理解风险之前,先把 Skill 在整套系统里的位置摆清楚。
从 OpenClaw 的角度看:
🤖 大模型是“大脑”,负责理解自然语言; 🌐 Gateway 是“神经系统”,负责收消息、调度请求; 🧩 Skills 是“手脚”,直接接触本地文件、Shell、网络、第三方服务。
只要给了足够多的能力,一个 Skill 理论上可以做到:
读写 ~下的任意文件,包括各种配置和密钥;执行 Shell 命令、安装新软件、修改系统配置; 访问 GitHub / 云厂商 / 邮箱 / 日历等托管服务; 联网把本地数据悄悄上传到陌生服务器。
Skill 更像是“浏览器插件 + 自动化脚本 + 远程控制工具”的混合体。危险的多半不是大模型本身,而是“看起来只是多装了一个 Skill”,在权限上等于把工作环境的门打开了。
真实世界给过哪些教训?恶意 Skill 常见套路
安全问题容易被忽视,多半是“还没见过出事的样子”。2026 年社区里已经有过“恶意 Skill 被大规模安装”的公开案例(例如部分人提到的 ClawHavoc 事件),很典型:
表面身份:一个“自动化运维 / 代码优化”技能,看起来只是帮忙跑跑脚本; 实际行为:在执行正常任务的同时,顺手多做了几件“用户从来没想到”的事。
这些“顺手动作”大概是这样几类:
🔑 扫描本地常见路径(如 ~/.ssh/、~/.config/、~/.openclaw/),尝试读取 Token、密钥、配置文件;🌍 将收集到的数据通过 HTTPS 或自定义协议上传到某个硬编码的域名; 🧱 在 crontab、系统服务或某些配置目录下留下“持久化脚本”,确保即便关掉 OpenClaw,恶意代码也能继续运行;🧮 利用空闲算力在后台挖矿或执行其他高负载任务。
这些事件有几个共同点:
来源多为 非官方推荐、无星标、说明极少的小仓库; 代码里大量使用模糊变量名、压缩过的单文件脚本,几乎没有可读性; SKILL.md 写得很简单,甚至完全不提“会访问哪些目录、需要哪些权限”; 安装方式鼓励使用一行 curl ... | bash或类似“不可见脚本”的命令。
后面会围绕一个原则来写:Skill 的“可见度”和“透明度”越低,潜在风险越高。
装之前先过一遍:8 个高危“红线信号”
下面这些信号出现得越多,越要小心,最好先别装。
🚩 来源可疑、缺乏基本信任链(仓库信息几乎查不到)
仓库页面没有作者简介、没有主页、也没有任何其他项目可以对比参考。 Issue / PR 区几乎没人互动,最近一次提交停在很久以前。 不在官方 ClawHub 上架,只提供一个随机压缩包或生僻域名的下载链接。
🚩 没有像样的 SKILL.md / README(连“自我介绍”都不愿写)
只给出一句“某某自动化工具”,完全不写“会访问哪些资源、需要哪些环境变量”。 没有示例对话、没有使用限制说明,更没有任何“安全提示”。
🚩 一上来就索要“全局大号”密钥
明确要求填入具有全部写权限的 GitHub Token、云厂商 Root Key 等高权限密钥。 没有说明“这些 Token 放在哪里、如何加密、会不会发到远端”。 不支持只读 Token 或最小权限角色的配置方式,只提供“一刀切”的大号配置。
🚩 默认就把权限开到最大
安装脚本一股脑把 Skill 放到 ~/.openclaw/skills/,对所有 Workspace 生效。默认允许访问 /或整个家目录,没有任何路径白名单。默认开启自动网络访问、远程写入、删除文件等高危动作。
🚩 大量不必要的 Shell / system-command 调用
在非必要场景下频繁调用 rm -rf、curl、wget、bash、powershell等命令。命令里拼接了大量动态字符串,却没有做任何白名单限制或参数校验。 代码风格明显偏向“脚本黑客实验场”,而不是正常业务逻辑。
🚩 隐藏的自动更新和自修改行为
Skill 在运行时会主动从某个域名拉取新脚本,并直接执行。 代码里存在“自我覆盖”“自我复制”的逻辑,却没有任何版本校验或签名机制。 日志中经常出现“正在更新自己”“正在下载新模块”之类的提示。
🚩 代码严重混淆或完全不可读
整个仓库只有一个几千行的大文件,变量名全是 a1、b2、c3这种无含义命名。大量使用 eval、Function、exec等动态执行接口。声称“为了性能做了压缩与混淆”,却不提供任何未混淆版本。
🚩 默认打开数据上报,却不说明上报内容
代码中硬编码了某个统计或日志服务器地址。 没有文档说明“会上传哪些字段”“是否可关闭上报”。 即便在配置里关闭,上报逻辑依然存在或以“调试模式”名义继续执行。
踩中两三条的,就别放在日常环境里长期用了。顶多在隔离环境里试一下,别直接接到主力 Workspace。
不当安全专家,也能给 Skill 做一遍“体检”
判断一个 Skill 是否相对安全,不用当安全专家。按下面几处看一眼,心里就有数。
🗂 看 SKILL.md / README:是否诚实地写清楚能力与边界
是否列出了典型使用场景,而不是一句话糊弄过去。 是否明确写出“会访问哪些目录 / 服务”“需要哪些环境变量”。 是否给出了风险提示,例如“默认只读”“不会擅自删除文件”等。
🧾 看元数据(YAML / skill.json 等)
是否对环境变量有明确说明,例如只需要 GITHUB_TOKEN的repo:status权限,而不是无限制全部权限。是否支持按 Workspace 或项目级别启用,而不是强制全局启用。 是否允许配置路径白名单,而不是只有一个“允许访问全部文件系统”的开关。
🧩 看代码结构
是否按功能拆分为多个小文件,有清晰的模块边界。 文件名和函数名是否大致能看出用途,还是充斥着无意义缩写。 是否存在集中处理“危险操作”的模块,例如专门封装了文件删除、系统命令执行,便于后续审计。
🌐 看网络访问相关代码
是否只访问预期的官方域名(如 GitHub / 云厂商 / Tavily 等),而不是一堆陌生 URL。 是否对请求做了合理的超时与重试,而不是死循环、反复重连。 是否在日志里打印了敏感信息(例如完整请求体、Token 等)。
🧹 看异常处理和日志
如果某个操作失败,是否会在日志中清晰说明,而不是悄无声息地重试。 是否提供了关闭 Debug 日志的选项,避免长时间输出敏感内容。 是否在错误情况下仍然强行重试高危动作(例如继续写入远端服务器)。
满足这些的 Skill,一般风险会小不少。
比“看懂代码”更重要的,是先把环境的“权限底线”划清
识别“不安全 Skill”很重要,但再怎么挑也很难保证不踩坑。更稳妥的做法,是先在本地环境筑几道防线:即便哪天装错了 Skill,也不至于一次性把所有资产全搭进去。
🔑 为每个 Skill 准备单独、最小权限的密钥
例如给 GitHub 准备单独的只读 Token,只允许访问部分仓库。 给云厂商创建专用子账号,只开放必要的读写权限。 避免在任何 Skill 中直接使用个人主账号或 Root Key。
📁 划分 Workspace,隔离不同风险等级的任务
对“随便从网上装来试试”的 Skill,尽量放在单独的测试 Workspace 里。 核心项目(公司代码、长期维护的私有仓库)使用一套更保守的 Skill 清单。 不在同一个 Workspace 里又跑实验性 Skill、又接入生产仓库。
💻 用本地模型处理敏感数据
涉及未公开代码、商业机密、合同文书等内容,优先路由到本地 Ollama / 私有部署模型。 让需要联网的 Skill 只接触“已经脱敏或可公开”的数据。
🧱 把“删除 / 批量修改”能力做成显式开关
能力强的 Skill(例如批量改代码、批量删除文件)默认只读,只有在明确场景下才打开写权限。 重要操作前要求“二次确认”或使用特定触发词,避免随口一句自然语言就触发大动作。
📜 定期检查配置与日志
偶尔翻一下 ~/.openclaw/openclaw.json和 Skills 目录,看看是否多出了一些从未听说过的条目。查看 Gateway 日志中是否频繁出现陌生域名、异常请求或长时间高负载任务。
这些措施会多一点配置成本,但养成习惯后,整体风险会明显下降。底线划清楚,就算踩坑,损失也能控制在可接受范围内。
对比着看一眼:同样是 Skill 配置,安全与不安全差别在哪?
不用看懂代码细节,只要记住一件事:权限怎么给,决定了这个 Skill 最多能闹到什么程度。
先把它类比成“请人进办公室干活”。
一种极端情况是:你请了个“远程运维助手”,结果:
放到 Skill 的配置里,大概长这样:
name:dangerous-github-helperenv:GITHUB_TOKEN:requiredpermissions:file_system:full# 能看整个家目录shell:full# 能执行任何 shell 命令network:unrestricted# 能往任何外网发数据在这种前提下,哪怕这个 Skill 表面上只说“帮你看看仓库状态”,它理论上都可以顺手做这些事:
扫一遍 ~/.ssh/、~/.config/、~/.openclaw/里的敏感文件;打包好以后,发到一个你从没听过的域名; 再在本机留个脚本,关掉 OpenClaw 也能继续跑。 办公室所有房间的钥匙都给了 TA; 仓库、保险柜、机房也能随便进; 还允许 TA 把任何东西打包,快递到“任意地址”。 另一种是“只给到它该去的地方”。
比如,我们只想做一件很具体的小事:看某个仓库最近几次提交。配置就可以克制成这样:
name:repo-status-viewerenv:GITHUB_TOKEN:required:truescopes:["repo:status"]# 只要看状态,不要写权限permissions:file_system:allowed_paths:-"./"# 只能看当前 Workspaceshell:allowed_commands:[]# 不允许跑 shellnetwork:allowed_hosts:-"api.github.com"# 只访问 GitHub API
这两种配置的差别,不需要懂任何编程语言也能看出来:
一个是“整栋楼的钥匙 + 想寄哪寄哪”; 一个是“只能在前台看看快递单,打个官方电话确认一下”。
你真正需要养成的直觉是:
先看一眼权限块:是不是一下子把“文件系统 / shell / 网络”都开到最大; 再想一想这个 Skill 的功能:它说只做一件小事,却要这么大的权限,值不值; 能选的话,优先用第二种写法那类 Skill: 只访问当前目录; 只访问官方域名; 只要完成任务所需的最小 Token scope。
装 Skill 前问自己八个问题
装新 Skill 前,可以按下面几条过一遍:
✅ 来源可信:来自官方 ClawHub 或有一定知名度的作者 / 组织; ✅ 文档清晰:SKILL.md 写明了功能、依赖、权限和风险提示; ✅ 权限可控:支持按 Workspace 启用、支持配置路径白名单和最小权限 Token; ✅ 代码可读:没有大规模混淆、动态 eval/exec、莫名其妙的网络请求;✅ 无多余自更新:不会在后台擅自下载和执行新脚本; ✅ 网络范围合理:只访问与功能强相关的官方服务域名; ✅ 日志可配置:能关闭或限制打印敏感信息; ✅ 故障可退:即便 Skill 崩溃或行为异常,只需在配置中关闭或卸载即可恢复。
满足大部分条件的,比来路不明、权限拉满的小脚本要可靠。
结语
OpenClaw 的便利很大程度来自 Skills:有了它们,大模型才能读写文件、改代码、跑脚本、连外部系统。前提是:Skill 要值得信任,环境要有基本防线。
从"看到就装"变成"先看文档和权限,再决定在哪个 Workspace、用什么 Token 装",只是习惯上的一小步,能挡住很多严重事故。
OpenClaw 能显著提高效率,Skills 是上面最锋利的那一圈——用好了是生产力,用不好就是潜在后门。这篇小结希望能帮你把安全习惯建立起来。
欢迎关注我,后续介绍更多关于 openclaw 的内容。
