 夜雨聆风
夜雨聆风
最难的不是安装 OpenClaw。
难的是我们面对一堆的模型提供方、渠道、技能的配置,不知所措。难的是怎么让 OpenClaw 更好地完成任务。
OpenClaw 支持市面上所有的大模型提供商,写脚本、查资料、整理邮件,几乎都能做。
但是,做得好不好,哪个模型更加适合呢?
评测来了。
PinchBench 做了件很好的事。用一套公开的 OpenClaw 任务去跑不同模型,看谁更容易把事做完。
https://pinchbench.com/
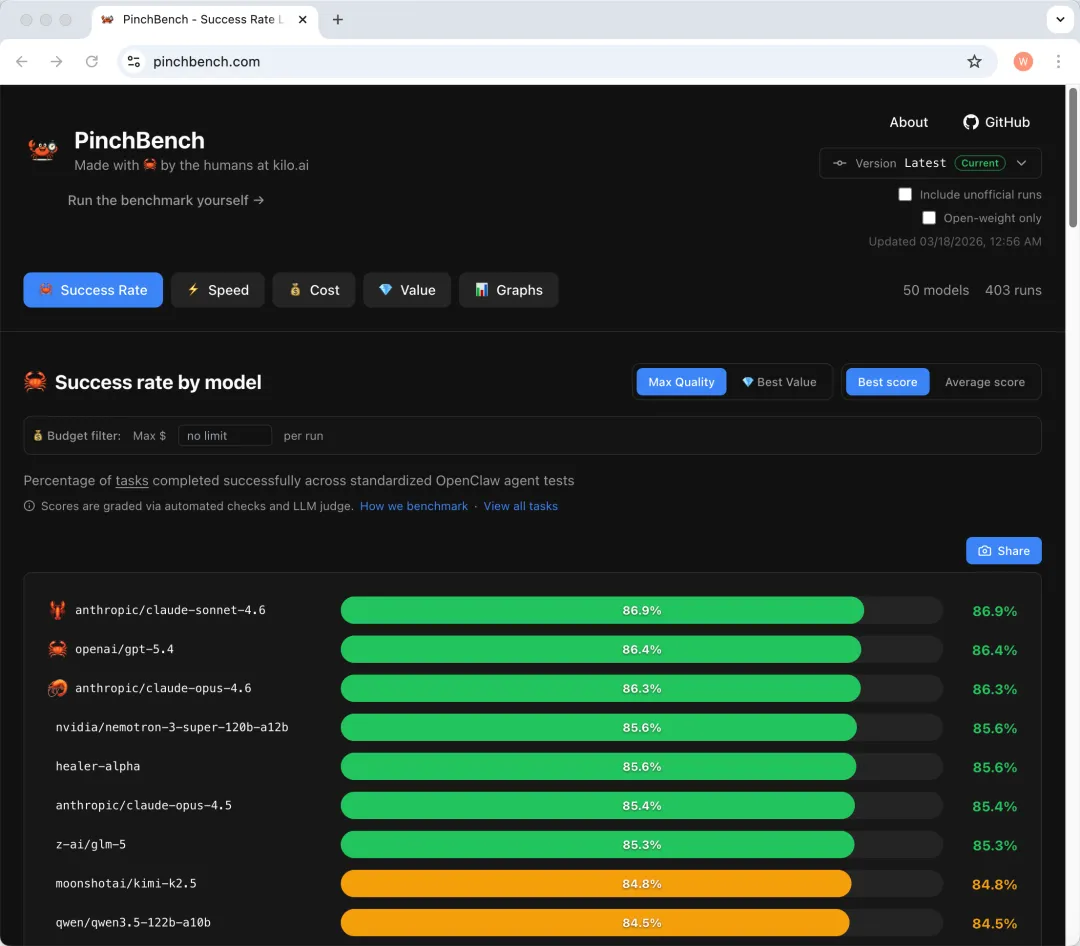
PART 01|先看看评测结果
在 PinchBench 的 Success Rate 排行里,当前第一名是 anthropic/claude-sonnet-4.6,成功率 86.9%。第二名 openai/gpt-5.4,86.4%。第三名 anthropic/claude-opus-4.6,86.3%(榜单更新时间 2026-03-16)。
完整榜单在此。
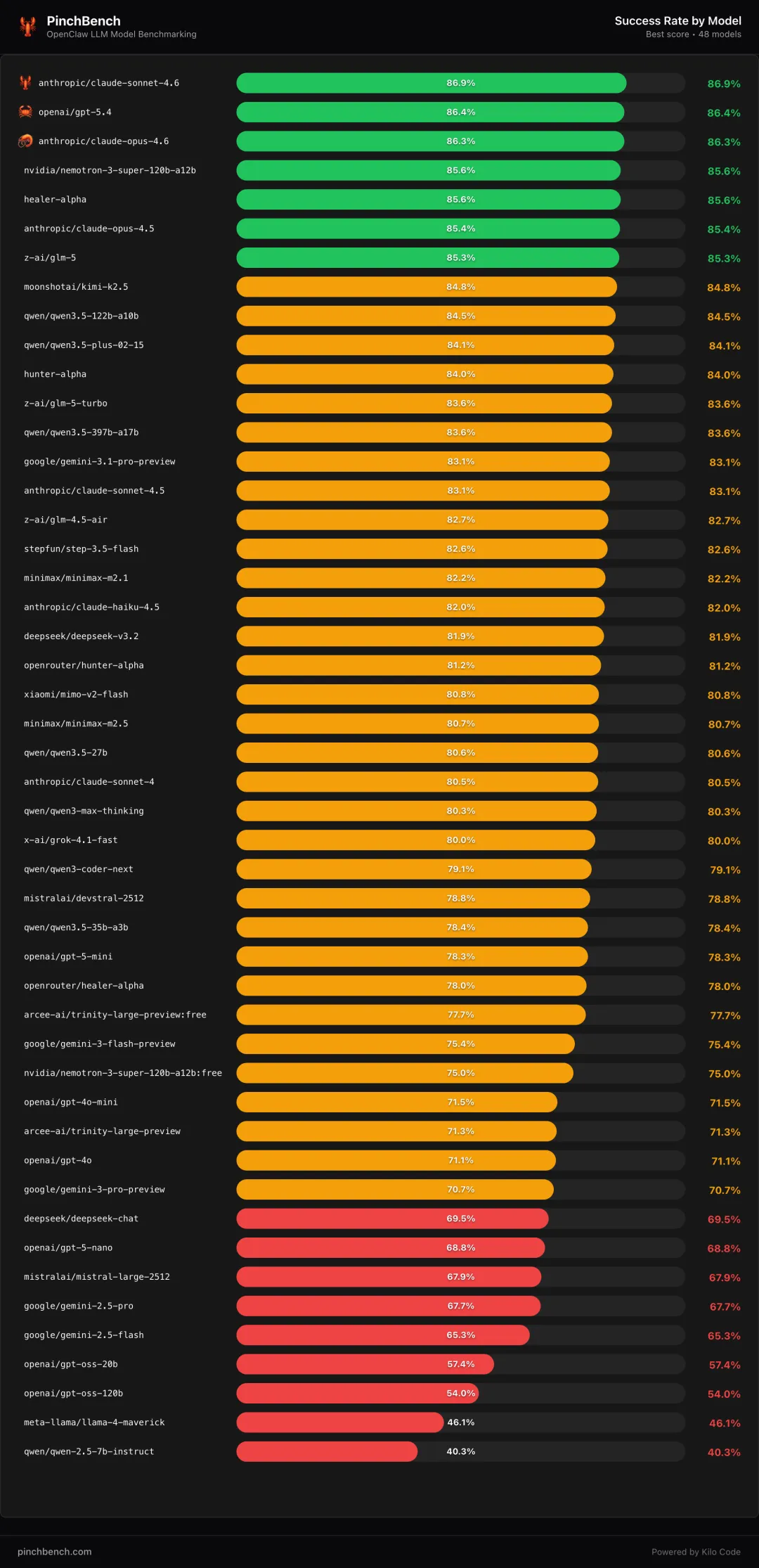
所以,按照这个评测,如果你要在 OpenClaw 里要追求更稳的闭环成功率,先选 Sonnet 4.6。想要几乎同级别的成功率,同时更贴近 OpenAI 生态,就选 GPT-5.4。
PART 02|评测是怎么做出来的
PinchBench 的思路是把大模型放到 OpenClaw 里当大脑,让它去做真实任务,然后按统一规则打分。它不是在测聊天,而是在测交付。
我把它拆成四块,你就容易读懂这张榜。
1)任务怎么来
任务以 markdown 文件定义,带 YAML 元信息。每个任务会写清 prompt、期望行为、可核查的评分清单。

当前基准包含 23 个任务,覆盖日程、研究、写作、编码、文档与表格分析、邮件、记忆、技能安装等类别。
2)评测维度测什么
官方把重点写得很直接。
工具使用能力,能不能选对工具、参数对不对。
多步推理与编排能力,能不能把动作串起来跑完一条链。
真实世界的脏数据与不完整指令,能不能扛住模糊与缺口。
实际结果,文件有没有真的生成,邮件和日程有没有按要求落地。
3)用哪些指标
榜单核心指标是 Success Rate,也就是在标准任务集里完成成功的比例。网站同时提供速度与成本等维度的对比图,方便你按预算和时延做取舍。
4)用什么技术打分
PinchBench 把评分分成三类。
自动化检查,用 Python 函数根据工作区文件和执行过程来判定。
LLM Judge,用一个固定的判卷模型按 rubric 给定性项打分,仓库默认是 Claude Opus 4.5。
混合,把能自动验的交给程序,把难以程序化的交给判卷模型。
PART 03|国产模型在榜单上到底什么水平
我最关心的一点是,国产模型能不能打。PinchBench 这张榜给了一个很清晰的回答。
第一,头部差距已经很小。
当前国产最好成绩是 moonshotai/kimi-k2.5,84.8%。紧随其后是 qwen/qwen3.5-122b-a10b(84.5%),以及 qwen/qwen3.5-plus-02-15、z-ai/glm-5(都为 84.1%)。和榜首 86.9% 的差距在 2 个点多一点。
第二,国产在中高位的“密度”更高。
你会看到一串 80% 左右的国产模型:
stepfun/step-3.5-flash(82.6%)
minimax/minimax-m2.1(82.2%)
deepseek/deepseek-v3.2(81.9%)
xiaomi/mimo-v2-flash(80.8%)
minimax/minimax-m2.5(80.5%)
qwen/qwen3.5-27b(80.4%)
qwen/qwen3-max-thinking(80.3%)
qwen/qwen3-coder-next(79.1%)
qwen/qwen3.5-35b-a3b(78.4%)
第三,选型时要盯“同一家不同档位”的落差。
比如 deepseek/deepseek-chat 是 69.5%,但 deepseek-v3.2 能到 81.9%。这类差距意味着你在 OpenClaw 里如果要跑长链路任务,优先挑“更偏 agent/coder、更新、更大档位”的那一档。
PART 04|我会怎么选
1)只看最稳
主力用 Claude Sonnet 4.6。它在这套任务里拿了最高成功率,适合你把 OpenClaw 当工作台用。
2)要一个接近满配的备胎
给 OpenClaw 配一个 GPT-5.4 作为 fallback。头部差距不到 1%,很多时候决定体验的不是智商,而是你那条任务链里最容易翻车的环节。
3)预算敏感或偏国产生态
榜单前 10 里,Kimi K2.5、Qwen3.5、GLM-5 都在 84% 左右。先用它们跑通高频任务,再把少数关键任务切到头部模型,成本和体验更容易平衡。
实际上,不要迷信差 0.5% 的排名。真正影响你每天用不用 OpenClaw 的,是失败后能不能复盘、能不能切换、能不能把高风险动作收住。
建议你把本文提到的最适合的模型都配上,不同的任务跑一跑,从中选取跑你的任务最稳的模型。
