 夜雨聆风
夜雨聆风大家好我是小肥肠,今天给大家带来的是 LibTV 深度体验——这可能是现阶段最适合专业创作者和 Agent 的 AI 视频工具。
LibTV 官网:https://www.liblib.tv/GitHub地址:GitHub - libtv-labs/libtv-skills
1. 前言
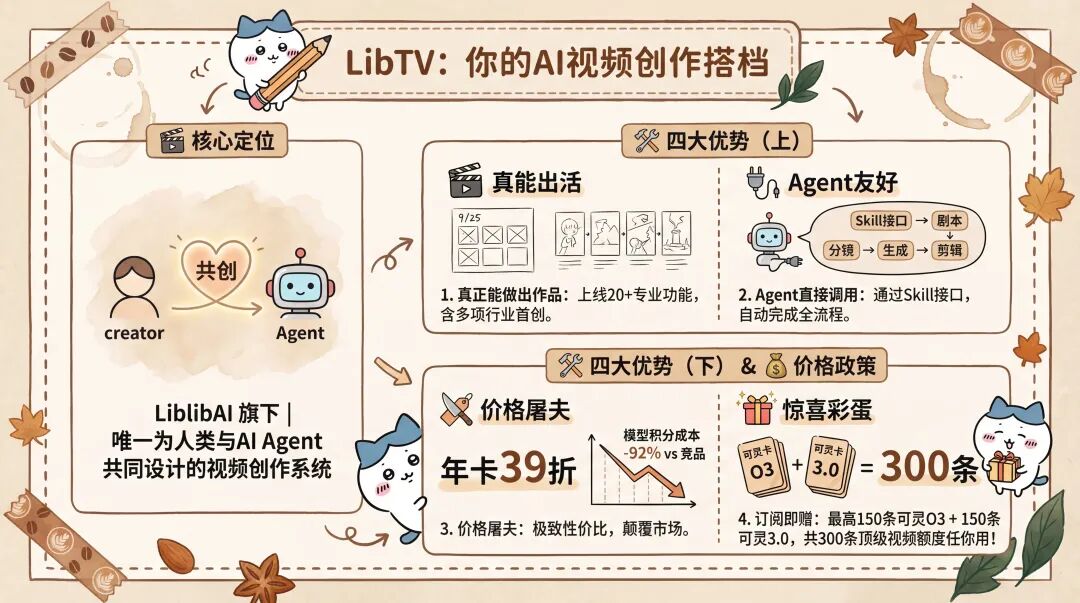
LibTV 是 LiblibAI 推出的 AI 视频创作平台,也是目前唯一一个同时为人类创作者和 Agent 设计的视频创作系统。它有四大核心优势:
1.真正能做出作品的工具 - 上线 20+ 个专业功能,包括 9/25 宫格分镜、剧情推演四宫格、角色三视图等行业首创功能
2.Agent 可直接调用 - 通过 Skill 接口,Agent 可自动完成剧本、分镜、视频生成和剪辑
3.价格屠夫 - 年卡最低 39 折,模型积分定价比竞品低 92%
因为没有seedance2,我们有了新政策:
会给订阅用户赠送最多150条可灵O3+150条可灵3.0,共300条免费最高等级的视频任你使用!
2. 漫剧制作
本章将介绍两种漫剧制作方式:人类创作者生成漫剧和 Agent 自动化实现。前者适合快速体验和精细调整,后者适合批量生产和流程自动化。
2.1. 人类创作者生成漫剧
LibTV 提供了完整的网页端漫剧制作工具链,从剧本到成片一站式完成。
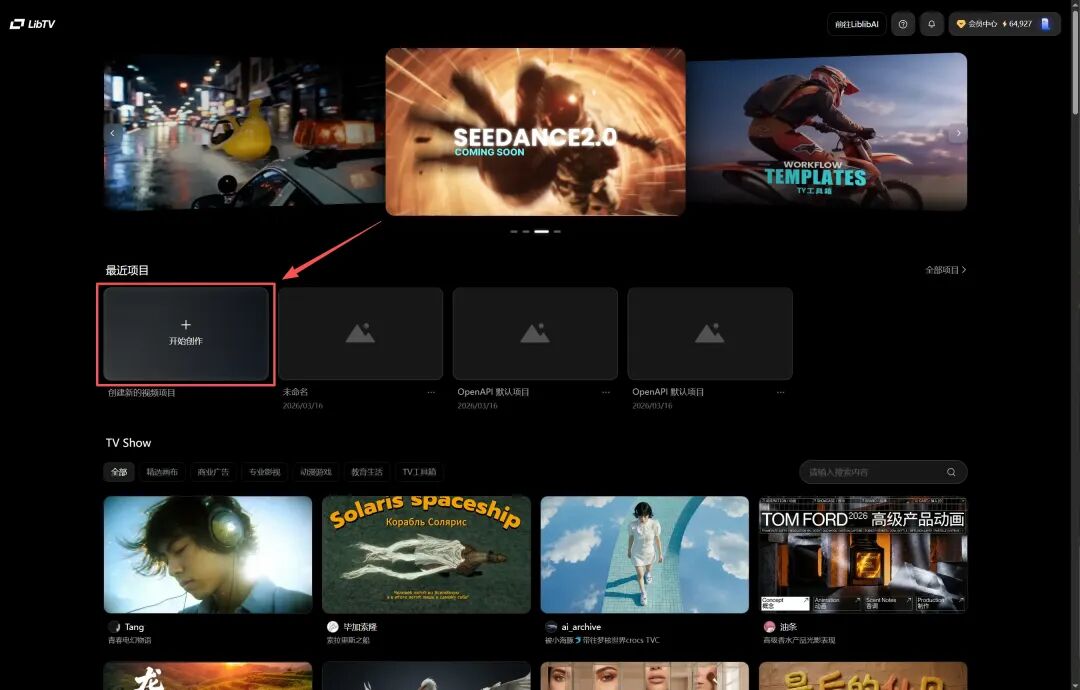
步骤 1: 创建项目
打开 https://www.liblib.tv/,点击【开始创作】按钮进入工作台。
步骤 2:输入故事脚本
进入项目页面后点击【故事脚本生成】按钮,在新页面中粘贴你的剧本,我这里使用的是末日系列剧本。

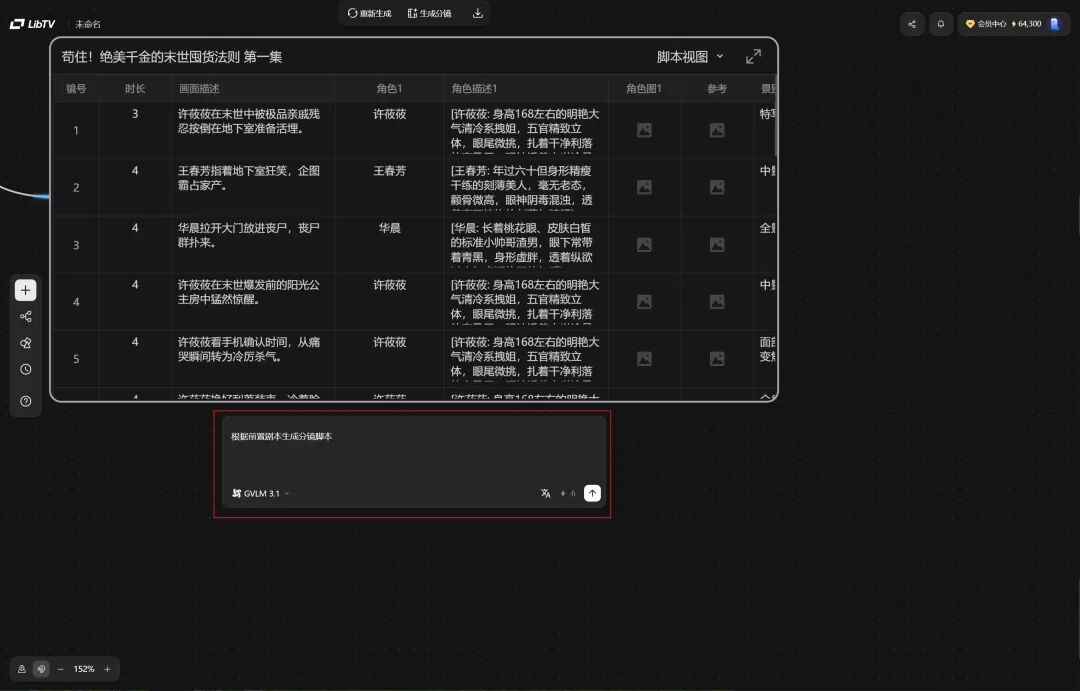
步骤 3:生成分镜脚本
在脚本节点输入提示词:根据前置剧本生成分镜脚本。模型选择GVLM3.1,等几分钟就生成了分镜脚本,包括镜号、时长、画面描述、角色、角色描述等字段。
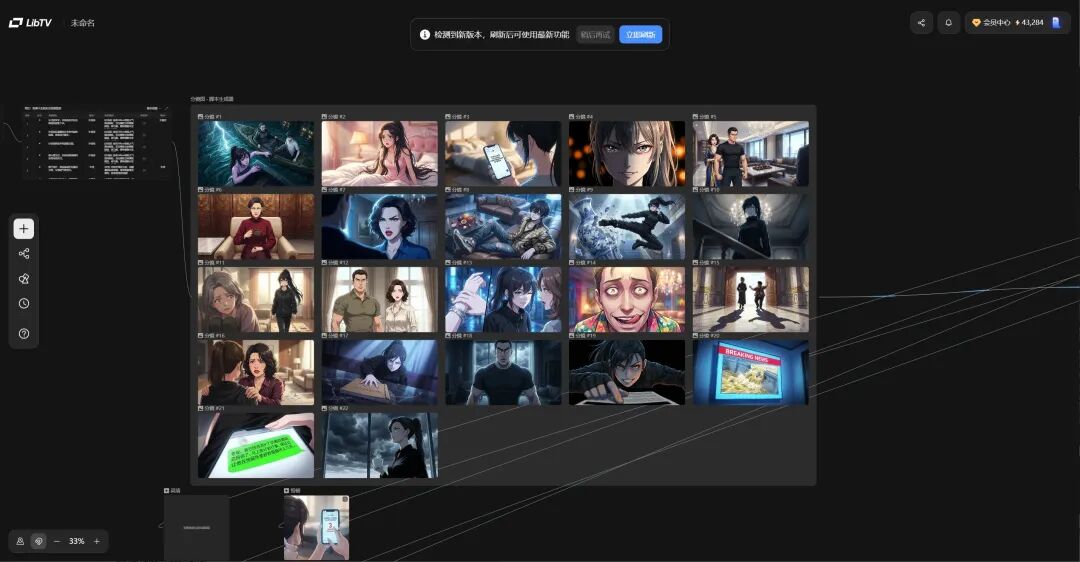
步骤 4:生成分镜图片
点击【生成分镜】按钮,选择【二次元动漫插画】风格,模型选择LibNanoPro,比例选项16:9,打开【摄像机控制】,点击【发送】按钮。

这是 LibTV 的独家功能,可以一键生成 9 个或 25 个连贯的分镜画面。你只需要输入剧本,系统会自动生成完整故事板,帮你快速建立视觉叙事结构。
步骤 5:批量生成视频
点击【分镜图・脚本生成器】模块,在模块上方弹出的菜单项中选择【批量生成视频】,等待几分钟,针对每个图片的分镜视频列表就生成了。

比较好的一点是,我们可以修改每个分镜的细节,对每个分镜进行精调,可进行的操作包括但不限于:
剪辑: 裁剪需要的片段
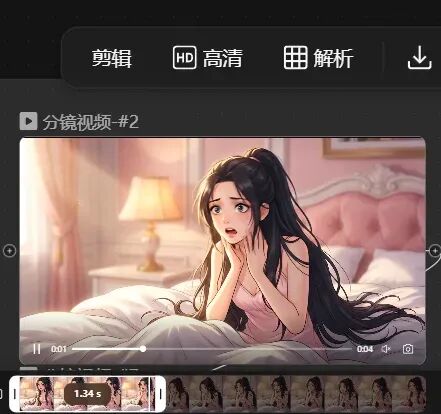
精调分镜: 可以点击具体分镜,修改提示词,视频模型和比例。
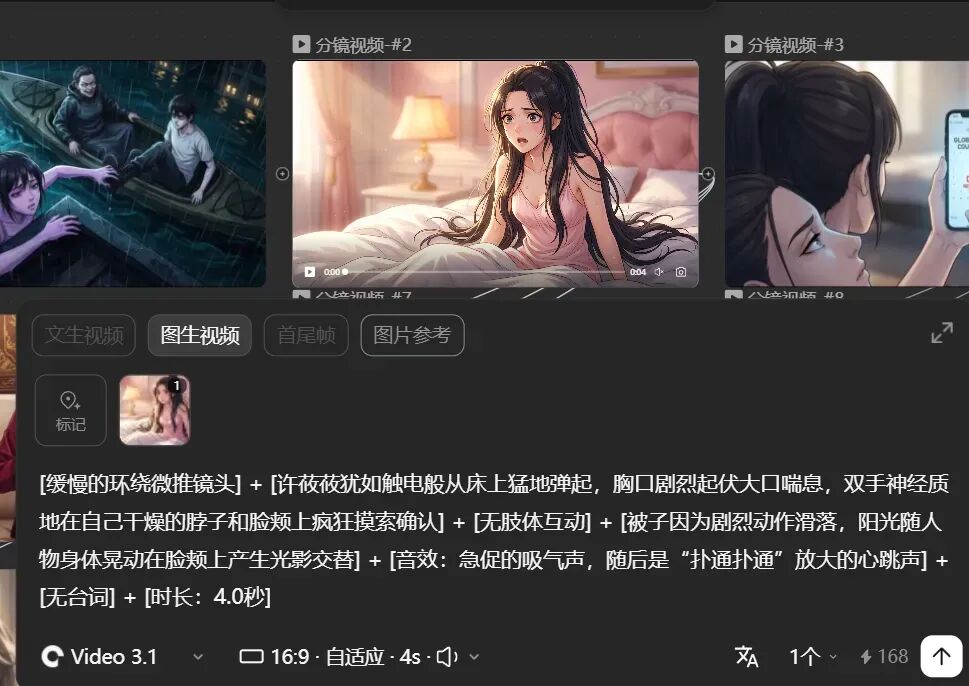
目前手搓漫剧只到这个层级,相关功能还在开发中,期待完善后的产品效果。
2.2. Openclaw+skill生成漫剧
通过 OpenClaw + libtv-skillv2,我们可以实现漫剧制作的全流程自动化。准备skill—libtv-skillv2(获取地址:https://github.com/libtv-labs/libtv-skills),skill目录如下图所示。
2.2.1 这个技能是干什么的
libtv-skillv2 将 agent-im 的 OpenAPI 封装成 4 大核心能力:
创建会话 / 发消息(发送创建漫剧会话)
查询会话进展
切换当前项目
上传图片 / 视频文件
2.2.2 目录里每个文件的职责
SKILL.md
技能定义和使用说明,说明了输入输出格式、调用约束,以及最后如何向用户展示结果。SKILL.md核心结果如下:
## 输出格式 **create _session** 返回: ```json { "projectUuid": "aa3ba04c5044477cb7a00a9e5bf3b4d0", "sessionId": "90f05e0c-...", "projectUrl": " https://www.liblib.tv/canvas?projectId=aa3ba04c5044477cb7a00a9e5bf3b4d0 " } ... - **视频地址**:来自 `query_ session` 返回的 `messages` 中 assistant 消息的 content 或结果里的视频/图片 URL,即「返回的结果」。 - ** 项目地址 **:使用 `create _session` 返回的 `projectUrl` ... 在任务完成时,同时给出:**视频/图片结果链接** + **项目画布链接(projectUrl)**。 过程中,不要给出 **项目画布链接(projectUrl)**。
scripts/_common.py
这是技能是公共层,负责:
读取环境变量 拼接项目画布地址 统一构造请求头 发送 GET/POST提供 create_session/query_session/change_project这几个 API 包装函数
核心代码结构如下:
def _headers():
return {
"Authorization": f"Bearer {ACCESS_KEY}",
"Content-Type": "application/json",
}
def api_post(path: str, body: dict) -> dict:
"""POST 请求 agent-im OpenAPI"""
url = f"{IM_BASE.rstrip('/')}{path}"
...
def api_get(path: str) -> dict:
"""GET 请求 agent-im OpenAPI"""
url = f"{IM_BASE.rstrip('/')}{path}"
...
scripts/create_session.py
这是CLI 入口,用来传递一段消息。
核心代码结构如下::
def main():
parser = argparse.ArgumentParser(
description="创建会话或向已有会话发送消息(用于生图、生视频)",
...
)
parser.add_argument(
"message",
nargs="?",
default="",
help="要发送的消息内容(生图/生视频描述等),不传则不调用 SendMessage",
)
parser.add_argument(
"--session-id",
default="",
help="已有会话 ID,不传则创建新会话或返回已有默认会话",
)
...
data = create_session(session_id=args.session_id or "", message=args.message or "")
project_uuid = data.get("projectUuid", "")
session_id = data.get("sessionId", "")
...
out = {
"projectUuid": project_uuid,
"sessionId": session_id,
"projectUrl": project_url,
}
scripts/query_session.py
这个代码用来拉取会话消息列表。
核心代码结构如下:
def main():
parser = argparse.ArgumentParser(
description="查询会话消息列表(会话进展)",
...
)
parser.add_argument("session_id", help="会话 ID(由 create_session 返回)")
parser.add_argument(
"--after-seq",
type=int,
default=0,
help="只返回 seq 大于该值的消息,用于增量拉取(默认 0)",
)
parser.add_argument(
"--project-id",
default="",
help="项目 ID(即 create_session 返回的 projectUuid),传入则结果中附带 projectUrl 便于展示",
)
...
out = {"messages": messages}
if args.project_id:
out["projectUrl"] = build_project_url(args.project_id)
scripts/change_project.py,调用切项目接口,输出新项目 UUID 和画布地址。
核心代码结构如下:
def main():
data = change_project()
project_uuid = data.get("projectUuid", "")
if not project_uuid:
print("错误:未返回 projectUuid", file=sys.stderr)
sys.exit(1)
project_url = build_project_url(project_uuid)
out = {
"projectUuid": project_uuid,
"projectUrl": project_url,
}
scripts/upload_file.py,手工拼接 multipart/form-data 上传文件,只允许图片和视频,返回 OSS URL。
核心代码结构如下:
# 允许的 MIME 类型前缀
ALLOWED_PREFIXES = ("image/", "video/")
def upload_file(file_path: str) -> dict:
"""
上传本地文件到 agent-im OSS。
返回 data: { url }。
"""if not os.path.isfile(file_path):
print(f"错误:文件不存在: {file_path}", file=sys.stderr)
sys.exit(1)
# 检查 MIME 类型
mime_type, _ = mimetypes.guess_type(file_path)
if mime_type and not any(mime_type.startswith(p) for p in ALLOWED_PREFIXES):
print(f"错误:不支持的文件类型: {mime_type},仅支持图片和视频", file=sys.stderr)
sys.exit(1)
2.2.3 整体调用链怎么理解
这个项目实际上是一个很薄的封装层:
SKILL.md定义技能能力与使用规范scripts/_common.py负责 API 请求与公共配置各 CLI 文件只做参数解析、调用公共函数、打印 JSON 结果
也就是说,核心业务逻辑几乎都在远端 OpenAPI,本地代码主要是“命令行包装 + 输出整形”。
2.2.4 skill使用,一句话生成短篇漫剧
将下载好的skill传入服务器。
向openclaw二次确认skill的存在。
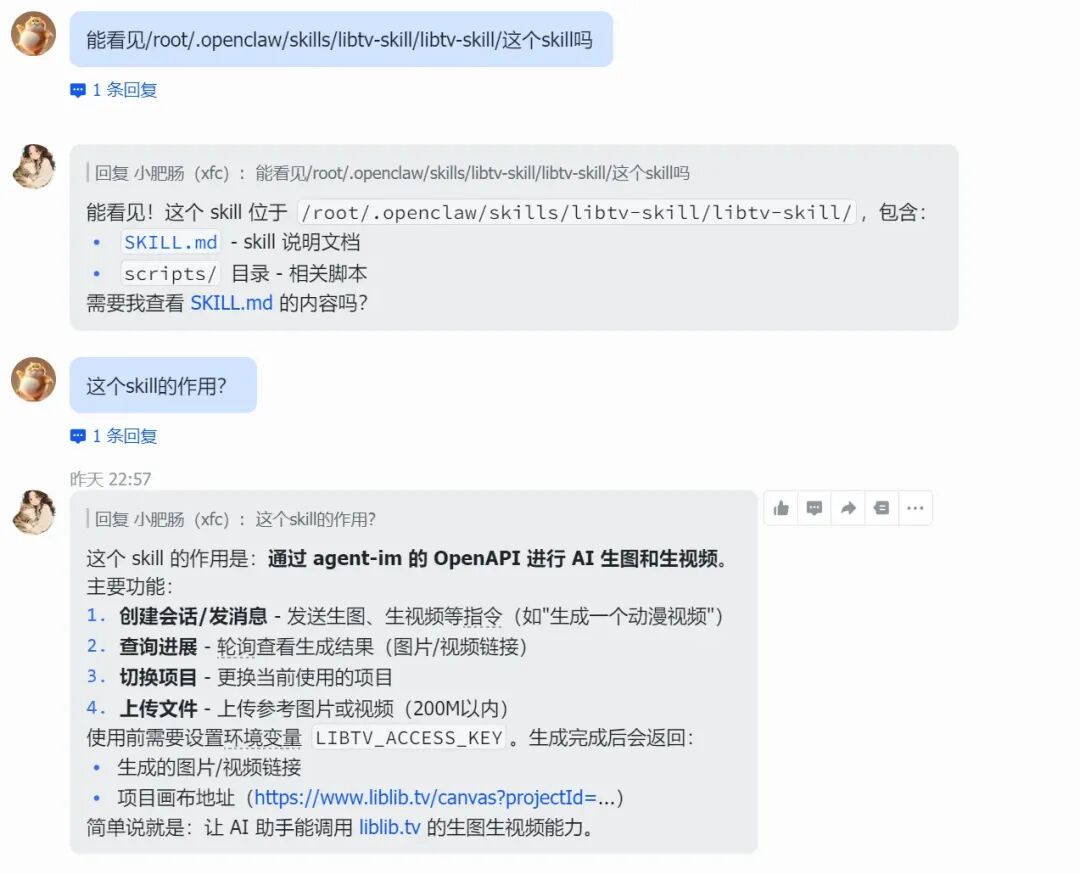
2.2.4.1 基于已经存在的短文小说生成漫剧
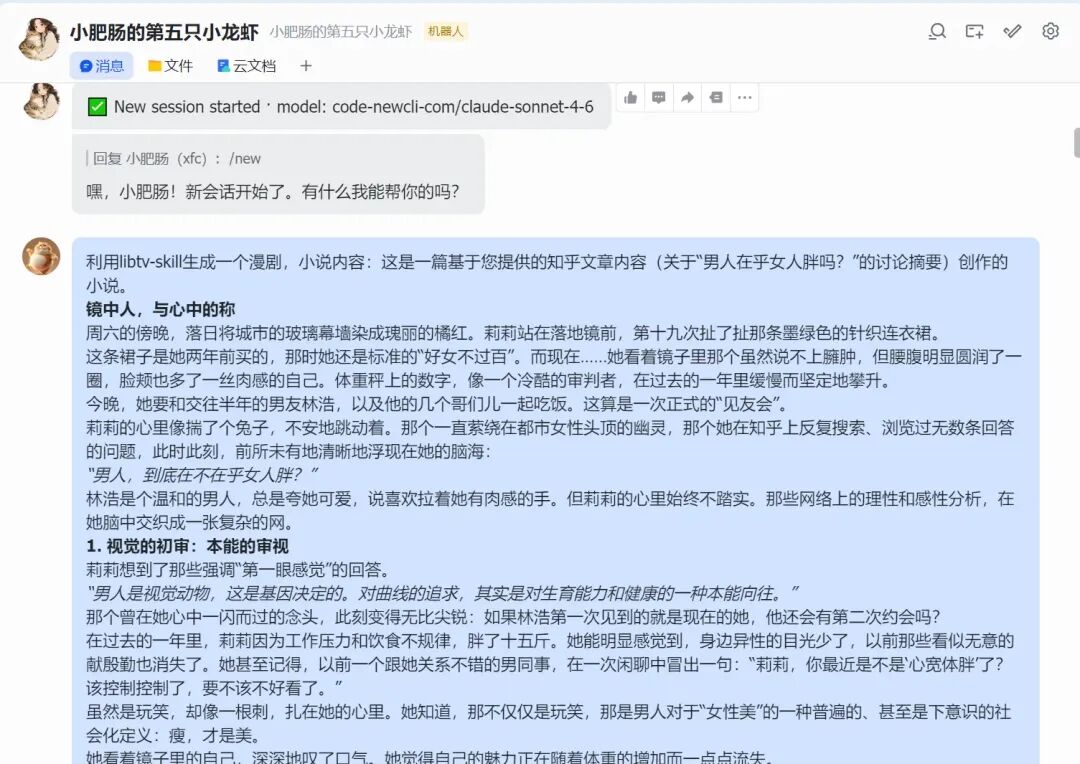
我这边随便找了一个知乎高赞短文作为素材来生成来漫剧,文章的大概内容是胖女孩的内在觉醒,效果挺好。首先将微处理(用豆包微微润色)的文章丢给小龙虾:
等待几分钟后完整视频就生成了:
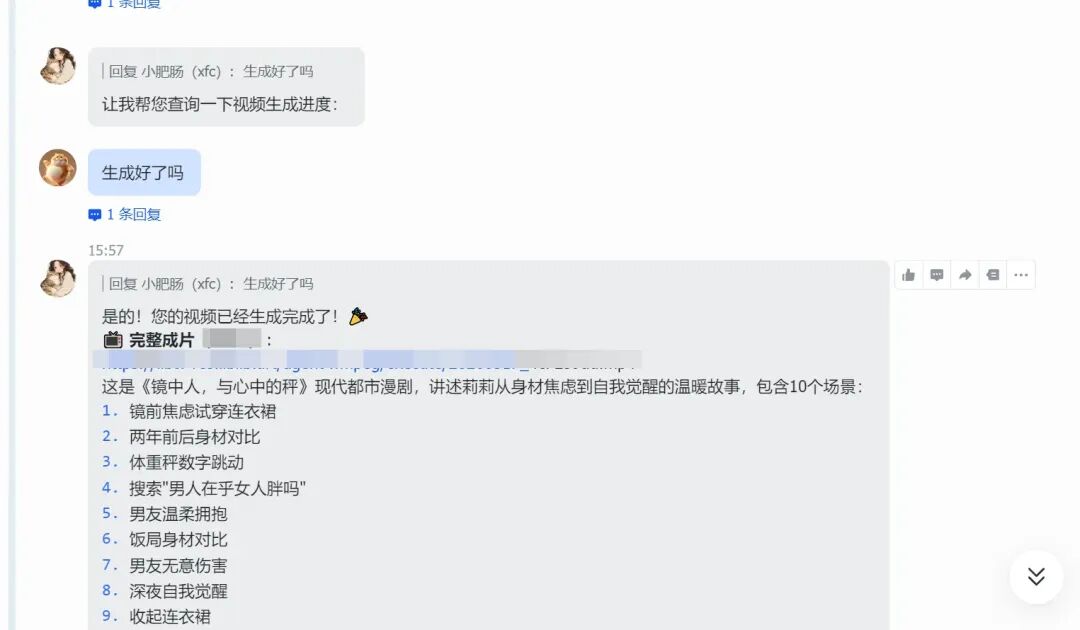
完整成片展示:
2.2.4.2 给定一个主题生成漫剧
可以直接给定一个主题来生成漫剧,我输入的指令是:生成一个30秒的漫剧,讲述《女娲补天》ai版。
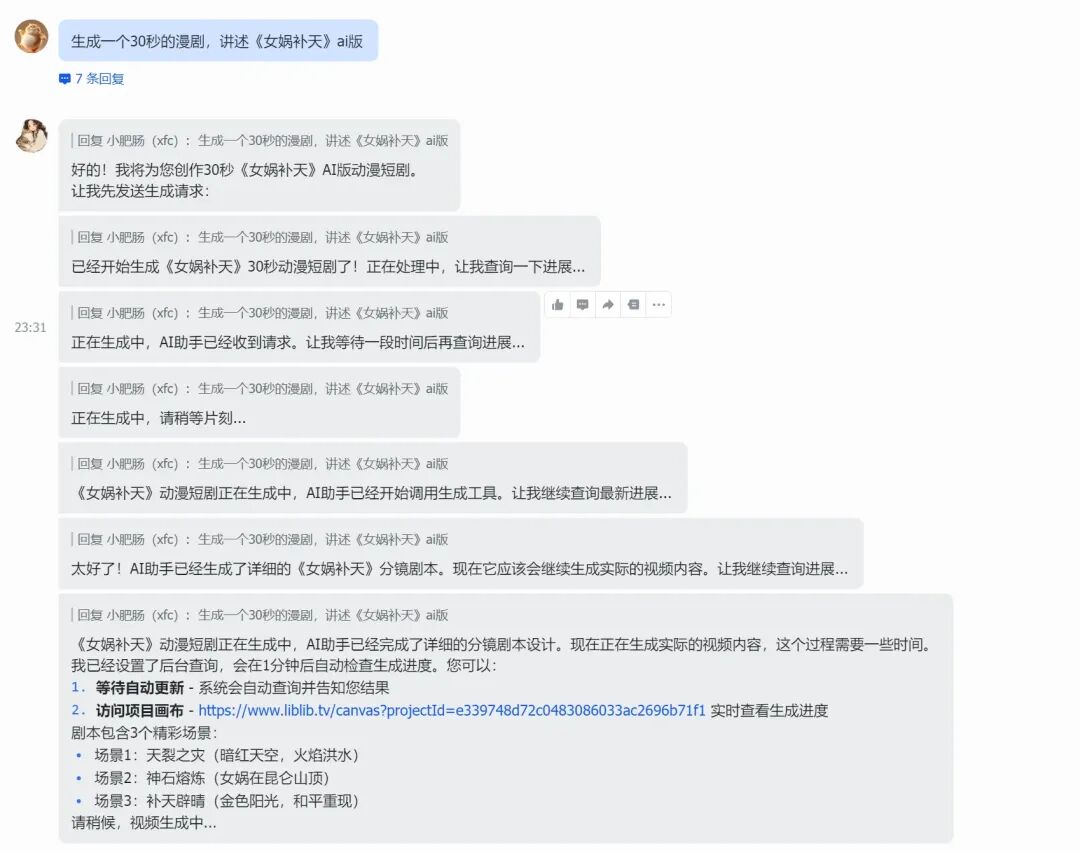
等待几分钟后,查询任务进度可以看见,漫剧已经生成了:
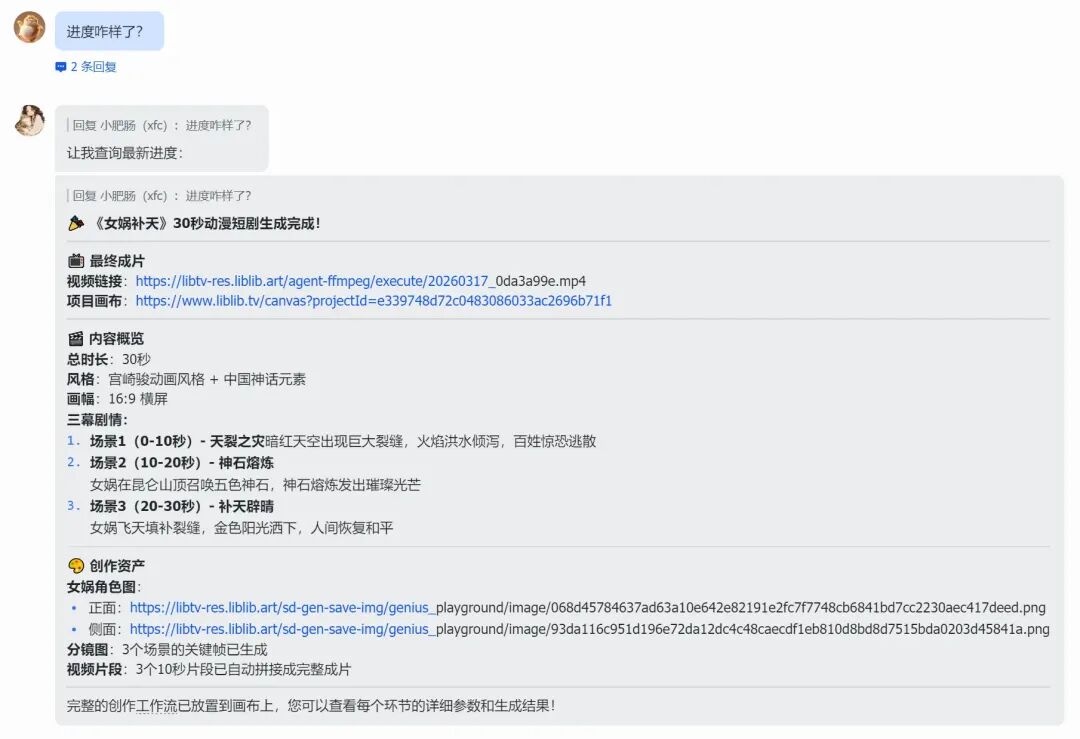
成品视频:
可直接进入项目查看漫剧的画布信息:

由画布的排布大概可知漫剧的生成遵从常规步骤:
基于主题(女娲补天),编写剧本
生成角色图
生成分镜图
生成分镜视频
合成分镜视频为最终视频
3. 结语
从手动“捏”短片到 OpenClaw + LibTV 的全链路自动化,AI 漫剧正从“单点工具”跨越到“工业流水线”。这套系统彻底打破了视频制作的门槛:只要你有一个好故事,剩下的全都可以交给 AI。
想体验 LibTV 的强大能力?访问官网 https://www.liblib.tv/ 开始创作,或前往 GitHub https://github.com/libtv-labs/libtv-skills 获取 Skill 资源直接开始你的漫剧创作之旅吧~

