 夜雨聆风
夜雨聆风
产业落地,卡在最后一公里
2025年,海外机器人开始密集出现在真实的生产场景里——Figure 02在宝马工厂一干就是11个月,累计完成9万次零部件搬运。与此同时,波士顿动力的Atlas也走进了现代汽车的生产线。产业叙事的重心,已经悄悄从"能不能落地"移向了"怎么大规模部署"。国内机器人的演示水准并不逊色,舞台上的跑跳抓握流畅自如。一旦搬进真实工厂,工件位置偏了几厘米、指令换了个说法,同一台机器人就可能陷入茫然——动作能做到,任务做不完,这个落差,才是国内具身智能真实处境的写照。
差距的根源指向同一个地方:机器人不缺灵活的"小脑",缺的是能理解情境、做出判断的"大脑"。而大脑的能力上限,由训练数据的质量和覆盖范围决定。
壁垒不在技术,在数据从未被打通
仿真数据可以快速铺量,但进入精细微调和真实部署阶段后,就难以被替代。真实场景中的接触力、随机扰动、多模态信号的对齐,是仿真难以完整还原的——就像在室内搭了一套仿真驾驶舱,油门刹车都能练,但路面的湿滑和突然蹿出的行人,只有真正上路才会遇见。各家数据格式与标注标准不统一,跨机构复用几乎无法实现,加之数据长期被视为核心竞争资产,开放意愿普遍不足。结果是有资源的团队重复造轮子,没有资源的团队被挡在门槛之外。
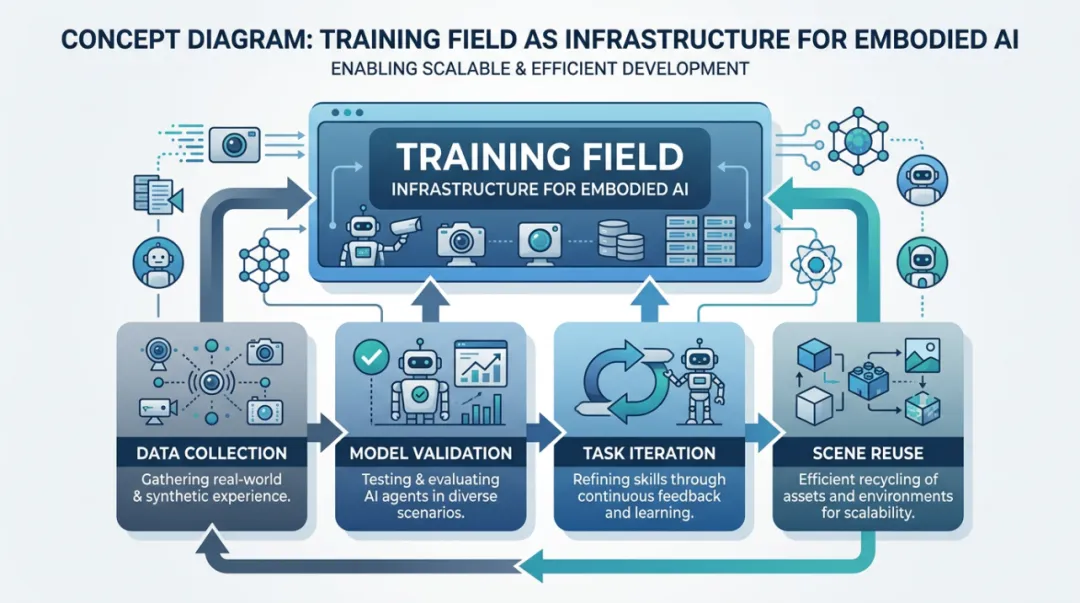
从"各自攒"到"一起建"
在工信部指导下,开放原子开源基金会联合多方共同发起建设的具身智能开源数据集社区正式落地,成为国内首个在国家层面推动的同类社区。它要解决的,不只是数据有没有的问题,而是数据能不能流通、不同机构之间愿不愿协作的结构性问题。
乐聚机器人作为牵头方,承担社区的核心建设工作。在真机采集、训练场搭建和数据开源上的积累,使其具备了组织这类协作的基础条件。围绕这一核心,参与方按照各自的能力边界形成分工:信通院承担标准与治理,上海人工智能实验室、百度等提供技术与场景支撑,哈工大、同济、上交等高校负责算法验证。
分工确定之后,协作能否真正运转,还取决于有没有共同语言。社区同期发起的工作组,正在着手制定数据格式、标注规范与质量评估标准,目的是让不同来源的数据能够在同一套规则下流通和复用,而不是各自开源、各自孤岛。

从单一维度到全链路对齐
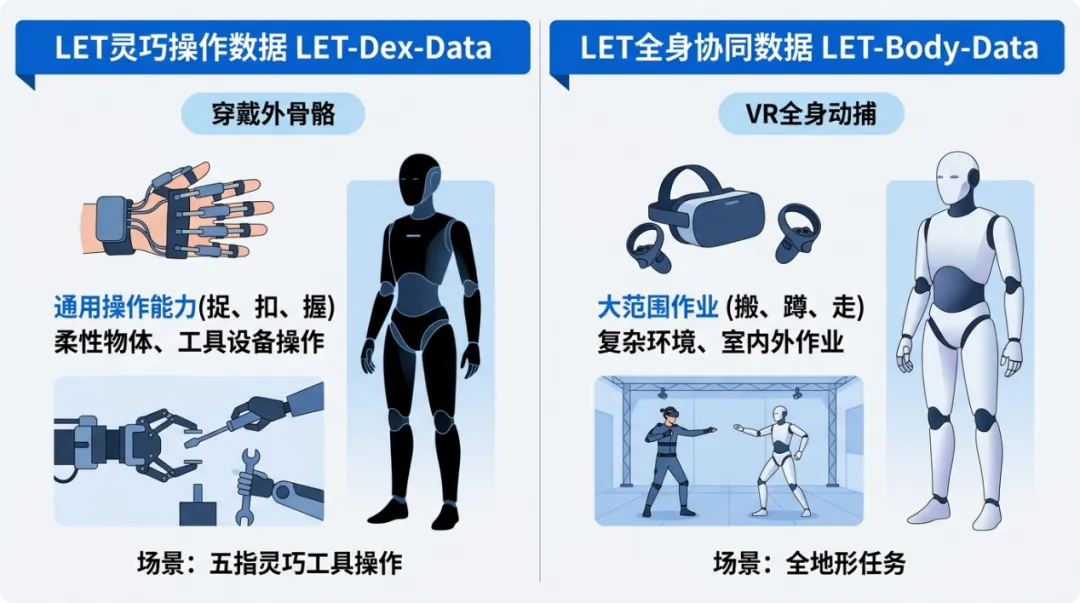
乐聚同期全球首发的OpenLET“触觉灵巧操作+全身运动”数据集,提供了一个具体参照。现有数据集普遍只覆盖单一能力维度,视觉、手部操作、全身运动分开处理,有点像只练过投篮却没跑过全场的球员,单项亮眼,真正上场漏洞百出。OpenLET尝试将触觉阵列、六维力、RGB-D、动作标注与语义信息整合进同一套采集框架,判断是:具身数据从采集阶段起,就应当面向真实任务的复杂性,而非分开积累、事后拼接。数据集目前覆盖117种原子技能,累计开源超60000分钟,全平台下载突破100万次,多城市训练场每年产出约2500万条真机数据,并有约20000小时数据进入实际产业交付。

结语
硬件差距在收窄,模型架构趋于同质,2026年具身智能的竞争很可能真正转向数据规模与质量。谁先把采集、验证、迭代、跨场景复用这套能力跑通,谁就更接近下一阶段的入场门槛。国家级社区的入场,说明具身智能的数据,可以被持续采集、规模化开源,并逐步进入产业使用。
-END-

