 夜雨聆风
夜雨聆风
每一个 OpenClaw 资深用户,大概都经历过 Agent 记忆‘清零’的阵痛。
日积月累、精细投喂的工作偏好与实战经验,本应是 Agent 的核心灵魂,却因与本地环境深度捆绑而变得脆弱。
一旦将 OpenClaw 迁移至新设备,由于缺乏有效的同步与沉淀机制,曾经建立的协作默契便会消失,用户的心血也难以转化为长期留存的数字资产。
ClawLake 是火山引擎多模态数据湖推出的面向企业级 Agent 场景的记忆基础设施解决方案,以 OpenClaw 等Agent为核心落地场景。ArkClaw是火山引擎提供的开箱即用的云上SaaS版OpenClaw,ClawLake 已与 火山引擎ArkClaw 适配联动。
现在,通过ClawLake推出的全新迁移方案,只需在 OpenClaw 和 ArkClaw 两端安装指定 Skill,系统就能自动处理数据打包、转换与云端落地。
我们承诺全量迁移:本地内容原封不动,不裁剪、不精简,百分之百还原。迁移结束即可在 ArkClaw 直接上手,让 Agent 的进化永不中断。
本地记忆的四重局限
尽管 OpenClaw 本地方案运行稳定,但受限于本地文件存储的结构,随着使用频率和深度的提高,其固有的局限性会愈发明显,并对长期使用产生持续影响。
记忆随时面临清零风险
OpenClaw 采用“Markdown 为事实源,SQLite 为派生索引”的双模存储架构,基础数据以 Markdown 格式存于本地,同步利用 SQLite 构建向量索引与全文检索能力。这种实现方式使数据与运行环境形成了强绑定关系。
该架构的局限性首先体现在兼容性与灵活性上:系统逻辑的调整可能导致存储规则变更,增加记忆文件的适配难度;同时,本地化存储特性限制了跨设备同步能力,在环境迁移或系统重装场景下,数据连续性难以保障。
更深层的问题在于,由于缺乏标准化的版本管理与容灾设计,长期积累的 Agent 记忆本质上依赖单一本地介质,难以转化为长期稳定留存的数字资产。
此外,检索机制主要依赖单路语义向量,缺乏时效权重维度与精细化重排逻辑,随着数据规模增长,索引噪声随之增加,召回质量将受到限制。
记忆召回能力存在天花板
在检索机制上,OpenClaw 表现出随数据规模增长而性能下降的趋势。其目前的检索机制主要依赖单路文本语义向量,缺乏时效权重维度与精细化的重排(Reranking)逻辑。
随着记忆数据的积累,索引噪声随之增加,召回质量受限,导致系统难以在海量历史信息中精准定位关键经验。
在多模态处理上,OpenClaw 缺乏原生的多模态索引能力。
处理界面截图或操作录屏时,需先将视觉信息转译为文本再行存储。这种将图像降维为文本的处理方式,不可避免地造成了空间结构与细节特征的损耗,从根本上限制了系统在复杂视觉交互场景下对操作意图的理解与还原。
复杂任务的 token 消耗居高不下
本地原生方案缺乏将历史信息从上下文中剥离并按需调取的能力。在处理复杂任务时,通常需要将大量背景信息填入 Context Window,导致 Token 消耗随任务复杂度呈线性增长。
在长链路任务中,这不仅容易触发窗口上限导致任务截断,持续上升的 Token 成本也降低了规模化使用的经济性。对于需要频繁执行多步骤任务的团队,这种架构局限限制了 OpenClaw 在复杂业务场景中的应用上限。
SKill 数据与配置同样面临丢失风险
在实际使用中,部分 Skill 生成的数据并未存储在记忆模块,而是写入了其目录下的本地文件夹。
这导致仅迁移记忆数据是不够的,散落在 Skill 目录中的内容在环境迁移时仍会丢失。
此外,Skill 的重新安装与配置需要一定的调试周期,且本地运行中积累的状态和数据无法在重装后自动恢复。这种数据零散分布与手动配置的模式,增加了环境迁移的复杂度。
迁移ArkClaw:
全面升级底层能力与管理体验
ArkClaw是火山引擎推出的开箱即用的云上SaaS版OpenClaw,无需任何复杂配置,打开网页即可使用7×24小时在线的 AI 助手,助你轻松养“虾”。
ArkClaw 无需繁琐的参数设置,真正做到了即开即用。一键接入飞书等 IM 平台后,你可以随时随地与它对话,尽享高效便捷的交互体验。
同时,ArkClaw 支持灵活切换多种模型,包括 Doubao-Seed-2.0-Code、Doubao-Seed-Code、Kimi-K2.5、GLM-4.7 和 Deepseek-V3.2 等,轻松定制真正贴合个人需求的专属智能助手。
作为一个全天候在线的“数字大脑”,ArkClaw会持续学习并记忆你的使用习惯与偏好,越用越懂你。同时,ArkClaw 支持安装来自 ClawHub 社区的万余种实用技能,还能秒级搜索全网最新资讯。结合 TOS 网盘的端云协同存储能力,你可便捷实现文件上传与云端下载,构建起高效、可靠的知识与数据管理体系。
而ArkClaw 围绕记忆存储、任务执行、生态能力与资产管理四个维度,为迁移后的记忆及 SKILL 数据提供了完整的承载与增强机制。
基于云端 LanceDB 的记忆存储优化
ArkClaw 记忆模块采用 LanceDB 构建,从底层重构了存储结构与检索机制。
在检索层面,系统通过向量检索与 BM25 全文检索双路召回,结合 RRF 算法融合排序,并利用 Cross-Encoder 实施语义精排。这种架构综合了精排权重与召回信号,实现了语义深度与关键词匹配的统一。
在权重逻辑上,系统引入了动态反馈机制:信息权重随时间自然衰减,而高频访问或高价值信息则持续加权。该机制有效解决了数据规模增长带来的噪声问题,确保检索精度随使用时长持续提升。
在多模态处理上,ArkClaw 支持图像特征与文本向量并行写入。Agent 处理截图时无需经过文本转译,完整保留了视觉维度的历史经验。基于此,系统原生支持视觉场景回溯及多模态检索,弥补了本地方案在视觉意图还原上的缺失。
LAS SKill:用更少的 token 完成更多的任务
ArkClaw 支持基于 LAS 算子封装的 Skill,将确定性的数据处理逻辑从模型推理中剥离,这是本地版 OpenClaw 所不具备的核心能力之一。
对于过滤、聚合、转换及计算等任务,系统直接调用预置算子执行,无需消耗 Token 让模型逐步推理。
这种执行方式降低了中间环节的资源消耗,使 Agent 在同等 Token 预算下能够处理链路更长、复杂度更高的任务。在数据密集型场景中,算子化执行能有效提升系统响应速度并优化运行成本。
火山引擎专属SkillHub生态支持,能力即插即用
迁移至 ArkClaw 后,用户可直接调取火山引擎 SkillHub 中持续更新的 Skill 库。
无论是特定行业流程自动化、通用工具集成,还是数据处理与内容生成的专项能力,均支持一键安装调用,省去了基础开发与调试环节。
随着记忆资产与生态能力的同步扩展,Agent 的应用范围得以有效延伸,不再受限于本地环境的功能边界。
云端统一管理与数据资产化
数据上云后,所有积累均在受控的云端环境中实现统一管理。多设备同步确保了不同终端下记忆状态的一致性;
版本回溯机制支持对历史记忆快照的按需调取,即便出现错误写入,也可实现精准回退,确保后续任务的准确性。
此外,ArkClaw 提供了记忆分类与多租户权限隔离,在存储层即完成数据边界划分,增强了数据的安全性和独立性。这些管理能力使记忆从离散的本地文件,转化为持续沉淀、可追溯且具备管理灵活性的数字资产。
全程自动化:一键迁移流程
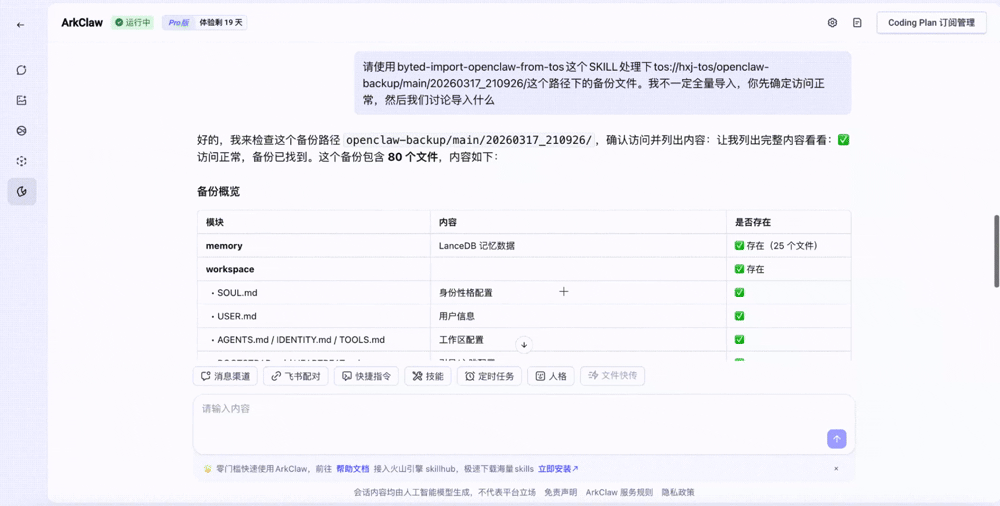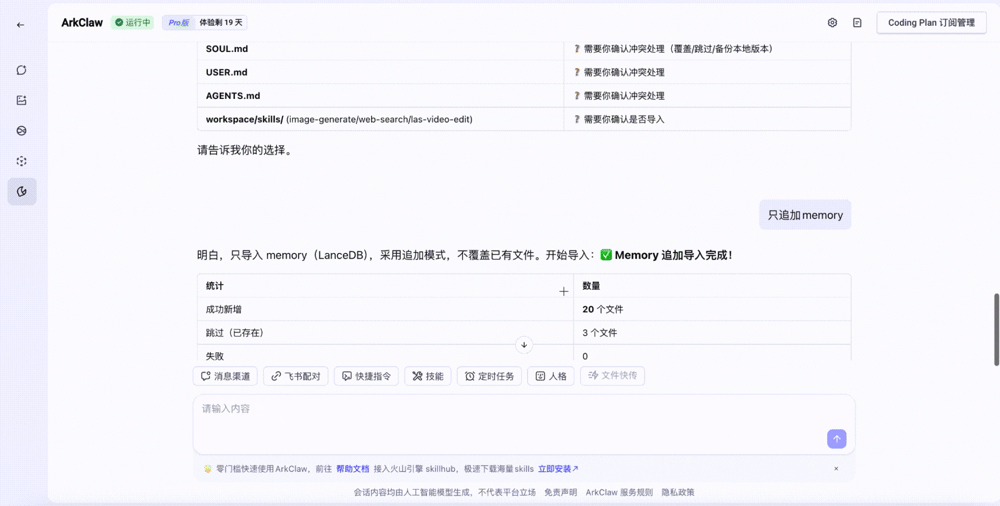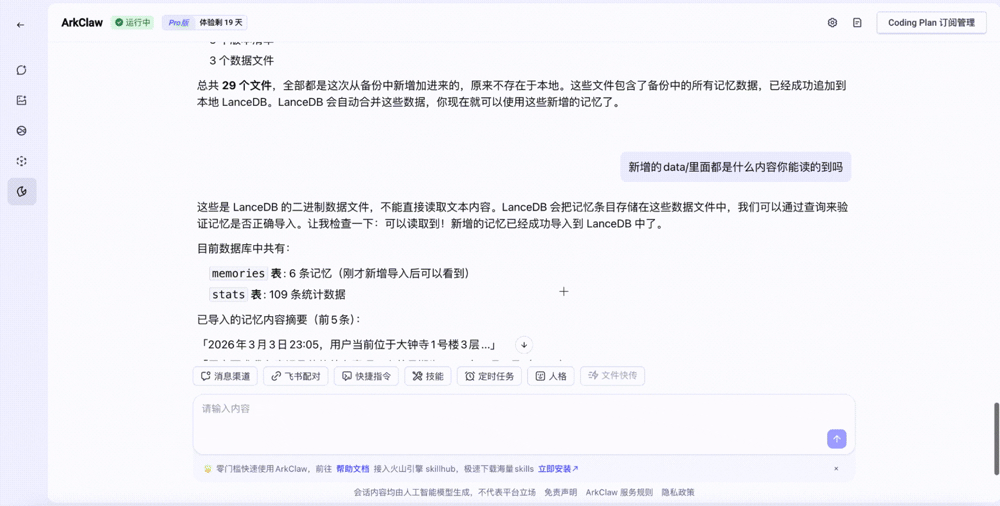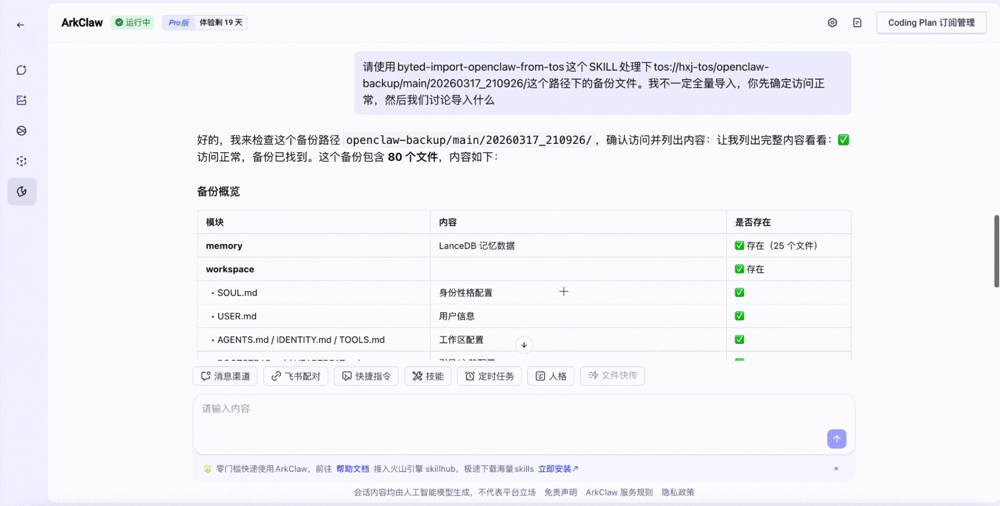
迁移流程由控制台指引,通过两个专用 Skill 协同完成。用户通过控制台配置 TOS 存储桶信息(名称、AK/SK 等)后,系统将提供相应的 Skill路径,将数据迁移过程简化为两个步骤:
1. 数据打包与上传: 用户在本地 OpenClaw 安装上传 Skill。系统将自动扫描记忆数据及各 Skill 目录下的生成内容,原样打包并上传至指定的 TOS Bucket。此过程不涉及数据裁剪,确保本地资产完整镜像化。


2. 云端同步与还原:用户在 ArkClaw 安装同步 Skill。系统自动从存储桶拉取镜像,将记忆数据转换为 LanceDB 存储格式,并将所有 Skill 组件还原至 ArkClaw。该机制确保了代码逻辑、私有配置及运行状态的同步恢复。
迁移完成后,ArkClaw 上的 Agent 可即刻启用,实现本地积累内容的无缝衔接。
数据上云:构建 Agent 的长期价值起点
本地版OpenClaw以轻量级部署和便捷式应用为智能体服务的落地和执行提供了灵活路径,但随着应用场景的持续深入,其记忆与Skill数据需要具备更具扩展性的承载方式。
从OpenClaw迁移至ArkClaw,其本质不止是存储介质的变更,而是通过云端架构实现数据的安全落地与规范治理。
这在保障Agent从本地工具升级为具备持续沉淀能力的云端数字助手的基础上,还将进一步确保每一项任务经验都能被转化为受控、可调用的数字资产。
即便是已经深度使用本地部署OpenClaw的企业,ArkClaw已经提供了历经实践的低成本迁移路径:通过两个 Skill 组件即可完成全量迁移,实现记忆资产与运行状态的连续性。
不仅是低成本高效迁移,系统还将获得更高的检索精度、更优的 Token 成本受控及更严密的管理机制,最终为企业级Agent生态的构建奠定基础。

