 夜雨聆风
夜雨聆风【边界层 · 技术架构】
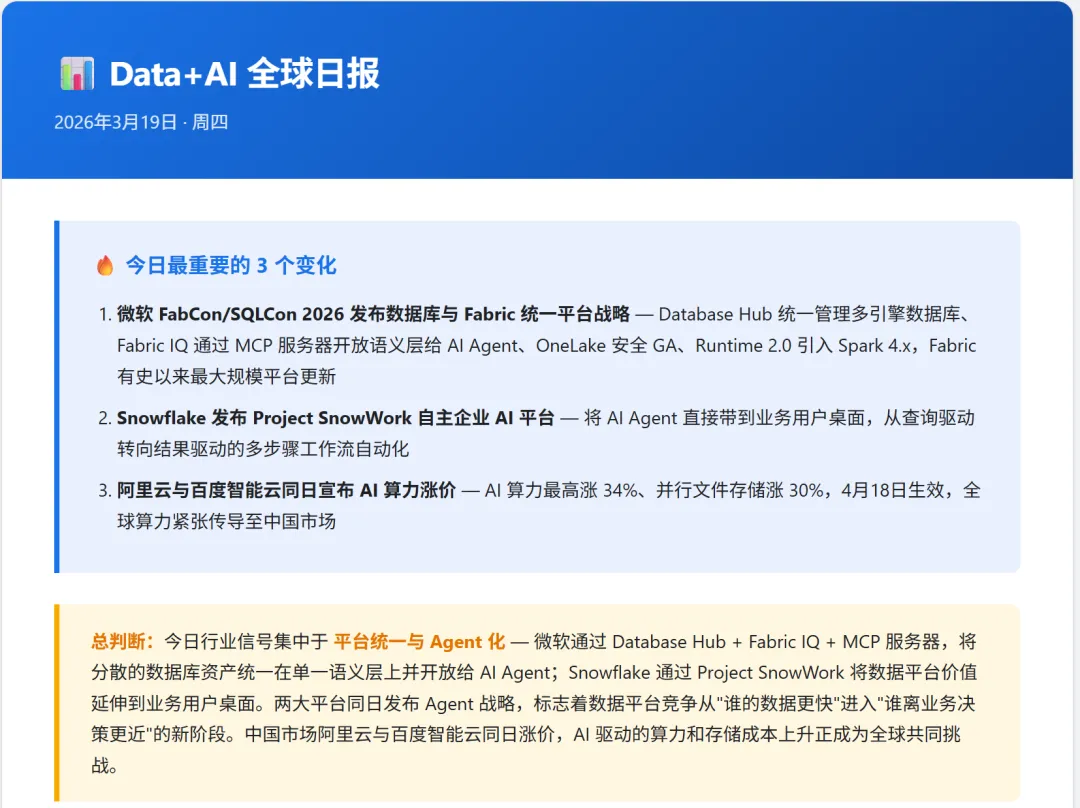
上周,我做了一个openclaw自动化日报项目来追踪 Data+AI 领域的行业动态。
今天,看到几家大厂密集发布的新动作,却在不约而同地回答另一个更底层的架构命题:企业里的 Agent,到底该站在什么样的数据基础设施之上?
我们先看这几条集中出现的信号:
微软(Fabric/FabCon):发布 Database Hub 和 Fabric IQ,其核心动作是通过 MCP(模型上下文协议)服务器将数据语义层开放给 AI Agent,并宣布 OneLake 的行列级安全机制即将全面可用(GA)。 Snowflake(Project SnowWork):宣布将自主 AI Agent 部署到业务用户的桌面,将系统的核心定位从“查询驱动”转向“结果驱动的多步骤工作流自动化”。 Databricks:持续推进“Data Intelligence Platform(数据智能平台)”战略,并提出将 Data Work 全面 Agent 化的愿景。 Gartner:在近期的多份报告中,愈发明确地将“语义层(Semantic Layer)”判定为 Agent 就绪数据的关键枢纽。
这些发布看似都在做 AI Agent,实际上它们在争夺的是数据平台的新职责。当以 OpenClaw 为代表的高阶 Agent 在应用层大杀四方时,它们的触手已经不可逆地穿透了应用边界,直接向企业的数据湖和数据仓库等底层延伸。
为什么 CEO 们不再关心查询速度,而开始谈论“业务工作流”?
过去十年,数据平台的竞争极易陷入底层指标的内卷(湖仓一体、存算分离、亚秒级查询)。我们在技术指标上取得了长足进步,但在业务交付的“最后一公里”却遇到了瓶颈。
当前的现状是:底层算得再快,业务侧依然面临着严重的“分析师积压(Analyst Backlog)”。
典型的业务链路是:提需求 等待排期 在 Dashboard 上过滤十几个条件 离开数据系统,回到业务系统去执行操作。
在这个长链路中,数据平台只提供了“查询支撑”,并没有交付“业务结果”。
高阶 Agent 的进场,打破了这个僵局。Snowflake 的 Outcome-Driven(结果驱动)叙事,以及 Databricks 把 Data Work Agent 化的表达,都在把数据平台的价值锚点往“工作完成度”移动。未来的核心竞争指标变成了:“业务用户能否在可信边界内,自主把一件事做完?”
当竞争维度发生转移,如果底层架构依然固守“被动响应 SQL”的定位,就面临着被剥离核心业务流、沦为外围“哑管道”的风险。
被打破的边界:Agent 接管数据栈带来的三大架构重构
当数据平台的用户,从“人类分析师”变成了“高并发、高执行力的机器(Agent)”时,原有的基础设施设计理念必须随之重构。目前来看,主要体现在以下三个硬核方向:
1. 语义层(Semantic Layer)成为核心网关,治理能力前台化
大模型无法准确理解企业底层杂乱的 t_biz_ord_f_0319 宽表。如果直接让 Agent 接入物理表,极易产生灾难性的数据幻觉。 过去,很多平台把语义和血缘当成后台支撑系统;但只要 Agent 开始调用、执行多步流程,语义层就变成了最核心的前台产品能力。这也是微软 Fabric IQ 重点强调“共享语义框架”的原因,没有这层“翻译官”,智能就无从谈起。
2. MCP 协议:AI 时代的“ODBC”
微软原生支持 MCP 服务器,释放了一个极其关键的架构信号。就像当年的 ODBC 让所有软件都能连上关系型数据库一样,现在的 MCP 就是让所有 AI Agent 都能无缝读懂企业数据的超级插头。数据平台正在从一个供人查看的“目的地”,转变为一个支持标准协议的“引擎”。无论企业使用开源 Agent 框架,还是商业化的 AI 助手,都能通过统一标准调取受控的数据资产,彻底打破内部的系统孤岛。
3. 安全防御前置:从应用层下沉到存储层的行列级控制当 Agent 取代人去高频下发复杂 Query 时,传统的依赖于应用层(如 BI 看板)的权限拦截已完全失效。防人易,防高并发的智能机器难。底层的权限模型必须更加统一且坚固。微软此次强调 OneLake Security 的统一模型和即将 GA 的行列级安全,以及 Databricks 强调 Unity Catalog 里的 Governance,都是在响应同一个方向:数据安全和控制的边界,正在加速向计算和存储的底层下沉。
数据团队的角色将被重新“切一刀”
在旧范式下,很多数据团队的需求止步于“帮业务出个数、做个看板、写个 SQL”。接下来,随着平台厂商都在试图缩短“数据到决策、数据到动作”的距离,这套运转模式将被彻底重构。
这绝不是说分析师没价值了,而是意味着数据团队的重心,会越来越多地转向定义语义、设定治理边界、构建可复用的业务上下文,而不是去反复响应低价值的取数工单。这也正是 Snowflake CEO 提出“消除 Analyst Backlog”叙事的弦外之音。
结语与冷思考
方向已经很清楚,数据平台正在进化为 AI Agent 生态中最核心的“数据供应引擎与知识枢纽”。
但作为架构师和从业者,我们在看清趋势的同时,也需要有一个冷静的判断:落地的工程难点,并没有被这些华丽的发布真正解决。
比如,微软这次发布的很多关键能力,仍在 Early Access、Preview 或即将 GA 阶段;Snowflake 的 SnowWork 目前也是 Research Preview 状态;Databricks 的 Genie Code 同样处在新范式建立的早期。大语言模型本身的幻觉问题,以及 Agent 在复杂企业数据环境下的安全性与稳定性,依然是摆在所有人面前的硬骨头。
但这并不妨碍潮水的方向。当业务团队越来越习惯于在桌面上,通过与 Agent 对话来获取数据结论并自动执行后续流程时,我们现在正投入重兵开发的、有着上百个筛选条件的复杂数据大屏,还有多少继续投入的必要呢?
在这场向“数据平台新形态”演进的长跑里,认清靶心,比盲目开枪更重要。
科里(Coralyx),发表于「边界层」2026.03
